Dnes si změříme výkon modelu na různém železe v Azure, zabalíme si model do krabičky a začneme ho servírovat přes API. Benchmark utilitku nám dá přímo YOLOv8 a jako compute pro notebooky poslouží Azure Machine Learning service. Model pro nějakou konsolidaci vyexportujeme do ONNX a jako servírovací framework použijeme Triton Inference Server od NVIDIA (který ale funguje i na CPU). Celý inferencing umí běžet v kontejneru (takže někdy v budoucnu si třeba ukážeme jak ho efektivně provozovat v Azure Kubernetes Service), ale my použijeme managed endpoint v rámci Azure Machine Learning, ať máme pěkně pohromadě nasazení, blue/green deployment, verzování, monitoring a podobné vychytávky na kliknutí.
Celý dnešní kód je u mě na GitHubu v notebooku.
Benchmark a zamyšlení nad výkonem
Všechno co tady uvidíte v žádném případě není profesionální vyladěný benchmark, jde o vytvoření si nějaké řádové představy. Přímo YOLOv8 má ve svém API možnost provést benchmark modelu včetně různých zabalení. Vyzkoušel jsem jednak malý server (2 core 8 GB RAM), pak stroj s jednou NVIDIA A100 GPU a k tomu nějaký finanční ekvivalent v CPU, což vyšlo zhruba na D řadu s 96 core. Otestoval jsem nano a large verzi modelu. Tady jsou výsledky.
| VM Type | Time nano (ms) | Time large (ms) | VM price per hour (USD) | Price per 1M images nano (USD) | Price per 1M images large (USD) |
|---|---|---|---|---|---|
| STANDARD_D2AS_V4 | 123 | 1782 | 0.115 | 3.39 | 56.93 |
| STANDARD_NC24ADS_A100_V4 | 5 | 8 | 4.78 | 6.64 | 10.62 |
| STANDARD_D96A_V4 | 36 | 139 | 4.9 | 49 | 189.18 |
YOLOv8 je opravdu velmi výkonné a vidíte, že s GPU jste s přehledem schopni i s velkým modelem zpracovávat data v živém streamu. Pokud pojede třeba film s 24 FPS, tak každé políčko svítí asi 42 ms, takže GPU s 8ms latencí tohle bude krásně stíhat i na víc streamů současně. Co si na datech všimnout?
- Úloha je nádherně paralelizovatelná. Vidíme, že nano vs. large model způsobí v 2 core propad o dva řády, v 96 core jen o jeden a u GPU jsme stále v jednotkách ms.
- Nano model je použitelný i na CPU, pokud neřešíte stream. Třeba průmyslový počítač by měl zvládat pár snímků za vteřinu pro nějaké edge scénáře.
- GPU má naprosto zásadní vliv a vězte, že NVIDIA dělá i čipy pro edge zařízení v rodině Jetson.
- Spočítal jsem kolik bude stát 1M inferencí tak, že jednoduše zjistím jak dlouho se vyhodnocuje milion obrázků a z hodinové sazby mi vyjde kolik to bude stát. Je vidět, že D96 je finanční nesmysl ve všech případech. U nano modelu se sice 2 core mašinka nadře a trvá jí to, ale nákladově není špatná. Nicméně u pořádnějšího modelu velikosti large je efektivita GPU naprosto brutální a vychází 5x resp. 20x levněji.
Zabalení modelu do ONNX
YOLO má nativně formát PyTorch, ale je to celé trochu džungle. Některé modely třeba máte v TensorFlow, ale řeknete není problém - moje hostovací platforma umí oboje. To ta, co použijeme hned za chvilku, taky, jenže je to hugh-performance hostovací platforma. Jsou tady ale ještě situace, kdy chcete běžet uvnitř telefonu nebo jako Javascriptový kód v browseru a tak podobně.
Model tedy uložíme ve formátu ONNX, který by měl zajistit lepší přenositelnosti mezi těmito případy použití.
# Export models
model_yolov8n.export(format='onnx')
model_yolov8l.export(format='onnx')
Triton Inference Server
Jako hostovací framework jsem zvolil Tritor Inference Server (evoluce TensoRT Inference Server) od NVIDIA, který je podle všeho (logicky) výborně vyladěn pro NVIDIA čipy jak v cloudu na na edge platformách, ale umí běžet i na CPU (což pro úsporu použiji na test já). Úžasné je, že tohle celá se dá sehnat jako hotová Docker kontejner nvcr.io/nvidia/tritonserver:23.05-py3. Dokonce pro servívání modelů nemusíte nic buildovat! Žádný Dockerfile, registry a podobně věci, které lidi od dat mohou děsit (což je teda trochu škoda, protože tenhle svět je pro ML podle mě hodně zajímavý - Vulcano, Kubeflow, …).
Jediné co potřebujete do kontejneru dostat, je adresářová struktura s konfiguračním souborem a samotným modelem - ve formátu ONNX (můj případ), ale může to být třeba PyTorch nebo TensorFlow. V adresáři models mám adresář pro každý model a uvnitř je konfigurační soubor config.pbtxt. Dále jsou uvnitř adresáře pro každou verzi modelu. To je skvělé, protože můžeme brát modely jako immutable artefakty, které jednoduše nahrajeme do adresáře a Triton si je načte a všechny servíruje. Není tak problém mít několik modelů v jednom endpointu a u každého modelu mít i víc verzí, ať mohou uživatelé přecházet postupně.
models
├── yolov8l
│ ├── 1
│ │ └── model.onnx
│ └── config.pbtxt
└── yolov8n
├── 1
│ └── model.onnx
└── config.pbtxt
Stačí tedy kontejner spustit na lokálním počítači, v Azure Kubernetes Service (CPU nebo GPU), Azure Container Instance (ta umí také GPU), Azure Container App (jen CPU) nebo Azure App Service (jen CPU). Jediné co jí musíte doručit je tenhle adresář a to krásně zajistíte jako mount z Azure Files. Ale to si zkusíme někdy jindy - dnes cílíme na plně spravovaný endpoint v Azure Machine Learning. Jak výsledné API vypadá uvidíte za chvilku.
Nahodíme tedy snadno:
docker run -it --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ./models:/models nvcr.io/nvidia/tritonserver:23.05-py3 tritonserver --model-repository=/models
Na portu 8000 nám hnedle běží HTTP API, na portu 8001 gRPC API (rychlejší, efektivnější varianta) a na portu 8002 statistiky pro monitoring s Prometheus/Grafana. Takže pokud jste taky Kuberneťáci, tak hnedle vidíte, že je to ideální dortíček do Kubernetu -> jen tomu namountovat volume, škálovat s HPA/KEDA, dát mu Ingress, napojit na monitoring a je to celé tak standardní jak jen běžná aplikace může být. Žádné ty datařské Sparkové tajemnosti.
Servírování v Azure Machine Learning
Použijeme v2 verzi služby, která v preview podporuje Triton, a protože jedu z notebooku, tak půjde přes Python SDK (druhá varianta je CLI v2 - tedy připravit si YAML s popisem, což je také velmi příjemné). Nalogujeme se, vytvoříme endpoint, do něj nasadíme model (u toho určíme compute infrastrukturu - já pro dnešek půjdu do malého CPU stroje) a na tuhle verzi (říkám jí blue) pošleme všechny uživatele.
# Login
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id,
resource_group,
workspace_name,
)
# Create endpoint and deployment
from azure.ai.ml.entities import ManagedOnlineEndpoint
# Create endpoint
endpoint = ManagedOnlineEndpoint(name=endpoint_name, auth_mode="key")
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
# Create deployment
from azure.ai.ml.entities import ManagedOnlineDeployment, Model
deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=Model(path="./models", type="triton_model"),
instance_type="Standard_D2as_v4",
instance_count=1,
)
ml_client.online_deployments.begin_create_or_update(deployment).result()
# Update traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Tou verzí se teď nenechte zmást. Je to vymyšlené pro situaci, že servírujete klasicky model jeden po druhém a tady umíte překlápět verze online modelů mezi sebou. Triton na to jde trochu jinak a má vícero modelů i verzování přímo v sobě. Nicméně i Triton samotný má verze a navíc můžete přidávat modely apod., takže by šlo teoreticky použít na verzování modelu oboje. Já osobně bych byl pro naplno využít vlastností Tritonu, protože ten umí verzování, “latest”, scheduling, prioritizaci fronty, automatické batchování se zpožděním (např. řeknete, že chcete scorovat v dávkách 8 kousků a jste ochotni čekat 500ms jestli vám do stávajího vozíku nepřistoupí ještě další request). Zkrátka je to celé dost vychytané a funguje to pak stejně ve všech způsobech nasazení.
Od managed endpointu už tedy věci kolem verzování nějak moc nepotřebuji, kromě verzí samotného Tritonu, ale co se mi rozhodně může hodit je, že nemusím nahazovat stroje, řešit jak je rozjet redundantně, zajistit jejich škálování podle zátěže, vznik nějakého endpointu, klíče na přístup, certifikátu, monitoringu, logování.

Autoškálování je u managed endpointu opravdu mocné.
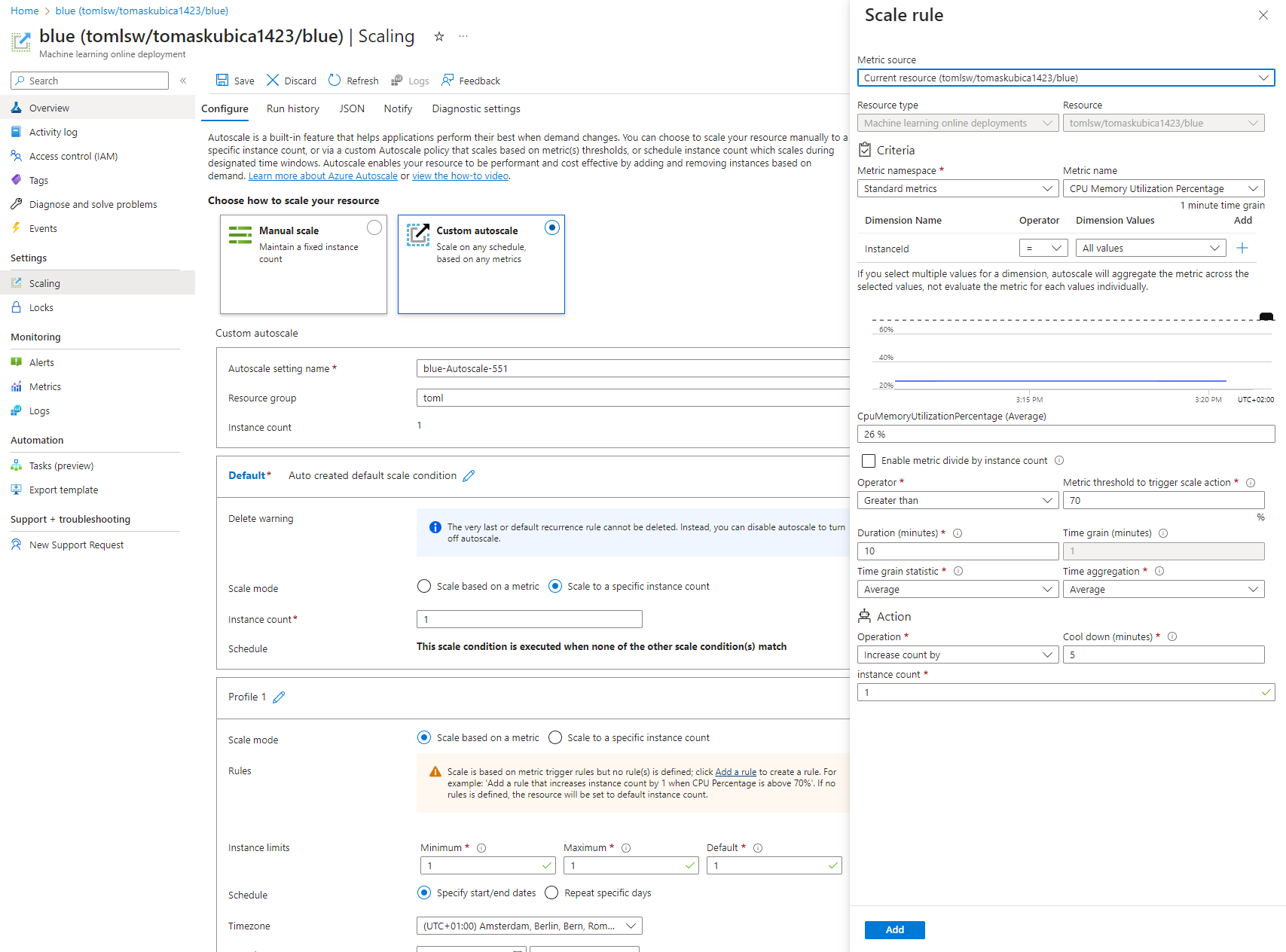
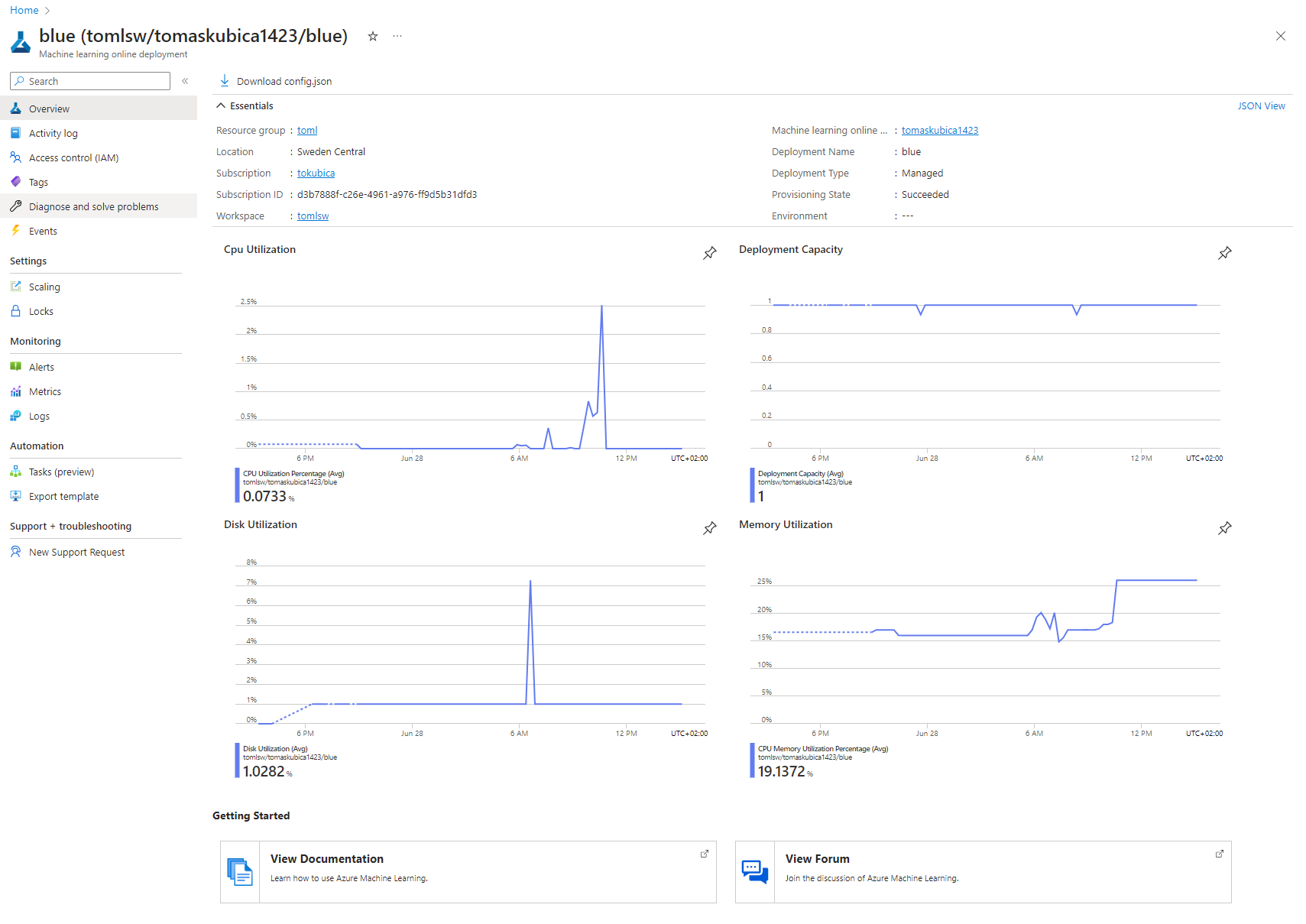
K dispozici jsou metriky a logy.
Přístup na API je zabezpečen přes klíč, takže tuhle starost stejně jako FQDN a platný certifikát pro vás managed endpoint zařídí.
Ve finále tedy:
- Triton zařídí nalíznutí a zprovoznění modelů včetně verzování, standardizovaného HTTP a gRPC API, batchování, scheduling a podobné věci
- Platforma musí zajistit infrastrukturu, autoškálování, vystavěný endpoint co do FQDN, certifikátu a klíče, monitoring a logování - a tohle dokáže Azure Machine Learning managed endpoint nebo si to můžete zařídit sami třeba v AKS (zejména pokud potřebujete následně třeba API monetizovat přes Azure API Management a tak podobně … tak jak to dělají třeba kognitivní služby Azure)
Klient pro Triton API
Na výběr je dobře čitelné HTTP API, kde si vystačí s cURL i Postmanem, ale i binární efektivnější gRPC API, které umožní vyšší výkon a jednoduché generování skeletonu apod. Zabezpečení endpointu zajišťuje Azure Machine Learning služba, takže si zjistím URL svého endpointu, klíč a připravím si příslušný header.
# Imports
import tritonclient.http as tritonhttpclient
import gevent.ssl
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Get scoring URI and key
endpoint = ml_client.online_endpoints.get(endpoint_name)
scoring_uri = endpoint.scoring_uri
keys = ml_client.online_endpoints.get_keys(endpoint_name)
auth_key = keys.primary_key
# We remove the scheme from the url
url = scoring_uri[8:]
# Initialize client handler
triton_client = tritonhttpclient.InferenceServerClient(
url=url,
ssl=True,
ssl_context_factory=gevent.ssl._create_default_https_context,
)
# Create headers
headers = {}
headers["Authorization"] = f"Bearer {auth_key}"
# Check Triton server is ready
health_ctx = triton_client.is_server_ready(headers=headers)
print("Is server ready - {}".format(health_ctx))
Server odpovídá. Jaké mám modely k dispozici?
# List models on Triton server
triton_client.get_model_repository_index(headers=headers)
[
{
"name":"yolov8l",
"version":"1",
"state":"READY"
},
{
"name":"yolov8n",
"version":"1",
"state":"READY"
}
]
Načtu si příkladový obrázek, převedu na 640x640 a pošachuju s dimenzema, aby to odpovídalo očekávání modelu. Pošleme to tam a zpátky dostanu odpověď ve tvaru matice (1 x 84 x 8400). To je trochu zvláštní, ale takhle YOLO funguje. První dimenzi odříznu, protože ji nepotřebuji (neděláme batch vícero obrázků). Druhá dimenze má 84 hodnot s tím, že první 4 jsou souřadnicové a pak jsou pravděpodobnosti pro 80 tříd COCO datové sady, na kterou bylo YOLO trénované (pokud by to byl Oslik a Ovecka, tak budou dvě). Třetí dimenze je 8400 obdelníků. V rámci zpracování dimenze prohodíme, ať máme řádky pro každý box a k nim souřadnice a pravděpodobnost (score) pro jednotlivé kategirie.
# Load image file
img = cv2.imread('test.jpg')
# Store original image size
image_width, image_height = img.shape[:2]
# Preprocess image
img = cv2.resize(img, (640, 640))
img = img.astype(np.float32) / 255.0
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, axis=0)
# Create inference request
input = tritonhttpclient.InferInput('images', img.shape, 'FP32')
input.set_data_from_numpy(img)
# Send inference request
outputs = [tritonhttpclient.InferRequestedOutput('output0')]
response = triton_client.infer('yolov8l', inputs=[input], outputs=outputs, headers=headers)
# Get rid of first dimension (we have just one image)
output_data = response.as_numpy('output0')[0]
# Transpose to get 8400x84
output_data = output_data.transpose()
# Now each row is one bounding box
# First 4 numbers are bounding box coordinates, next 80 are probabilities for different classes
print(f"Row 0: x_center: {output_data[0][0]} y_center: {output_data[0][1]} width: {output_data[0][2]} height: {output_data[0][3]}")
print(f"Classes probabilities: {output_data[0][4:]}")
Row 0: x_center: 10.970717430114746 y_center: 4.042498588562012 width: 23.763792037963867 height: 10.321962356567383
Classes probabilities: [1.9371510e-06 2.0861626e-07 4.4703484e-07 1.4901161e-07 5.0663948e-07
1.1920929e-07 5.9604645e-08 2.3841858e-07 4.7683716e-07 8.0466270e-07
1.1920929e-07 4.1723251e-07 1.4901161e-07 3.5762787e-07 2.4437904e-06
2.0861626e-07 2.3841858e-07 4.1723251e-07 5.3644180e-07 4.7683716e-07
2.9802322e-07 2.6822090e-07 4.7683716e-07 5.0663948e-07 1.1920929e-07
1.1026859e-06 2.0861626e-07 2.9802322e-07 5.9604645e-08 2.6822090e-07
3.2782555e-07 2.3841858e-07 5.0663948e-07 1.6391277e-06 1.4901161e-07
1.4901161e-07 2.0861626e-07 4.7683716e-07 3.8743019e-07 3.5762787e-07
3.5762787e-07 2.6822090e-07 1.7881393e-07 2.3841858e-07 1.7881393e-07
2.3841858e-07 4.7683716e-07 4.1723251e-07 1.7881393e-07 6.8545341e-07
2.0861626e-07 2.9802322e-07 1.4901161e-07 1.7881393e-07 2.3841858e-07
1.4901161e-07 8.0466270e-07 1.7881393e-07 6.8545341e-07 2.3841858e-07
3.5762787e-07 2.6822090e-07 2.6822090e-07 1.4901161e-07 1.4901161e-07
2.6822090e-07 1.7881393e-07 1.7881393e-07 1.7881393e-07 1.1920929e-07
1.1920929e-07 4.4703484e-07 2.3841858e-07 6.8545341e-07 6.2584877e-07
2.3841858e-07 1.4901161e-07 3.2782555e-07 1.7881393e-07 1.7881393e-07]
Třídy si převedeme na názvy přes jejich index a podíváme se v řádku na třídu s nejvyšším score.
# Find bounding box with highest probability and print class id
yolo_classes = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat",
"traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse",
"sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie",
"suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut",
"cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse",
"remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book",
"clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"
]
prob = output_data[0][4:].max()
class_id = output_data[0][4:].argmax()
print(f"Label: {yolo_classes[class_id]} with probability: {prob}")
Label: bird with probability: 2.4437904357910156e-06
Obdelníků je samozřejmě hrozně moc a většina z nich má téměř nulové pravděpodobnosti. Vyberme jen ty nad 0.5 a uložíme si souřadnice. To uděláme tak, že je jednak přeškálujeme na původní velikost obrázku a spočítáme se x1, x2, y1, y2 (model nám vrátil v prvních dvou číslech střed a pak šířku a výšku - právě aby se to dalo dobře přeškálovat na původní velikost obrázku).
# Cycle through all bounding boxes and print those with probability higher than 0.5
boxes = []
for i, row in enumerate(output_data):
prob = row[4:].max()
class_id = row[4:].argmax()
if prob > 0.5:
x_center, y_center, width, height = row[:4]
x = int((x_center - (width / 2)) / 640 * image_width)
y = int((y_center - (height / 2)) / 640 * image_height)
w = int(width / 640 * image_width)
h = int(height / 640 * image_height)
x2 = x + w
y2 = y + h
print(f"Row: {i} Label: {yolo_classes[class_id]} Probability: {prob} Coordinates: {x, y, x2, y2}")
boxes.append({"label":yolo_classes[class_id], "coordinates": (x, y, x2, y2)})
# Note some boxes are "duplicates" as they are having eg. just 1 pixel difference
# We should "dedpulicate" them, but in our case we will just draw all of them
Row: 1464 Label: bird Probability: 0.6160368323326111 Coordinates: (172, 136, 222, 169)
Row: 1465 Label: bird Probability: 0.6021742224693298 Coordinates: (173, 136, 222, 168)
Row: 1466 Label: bird Probability: 0.5969414710998535 Coordinates: (174, 136, 223, 168)
Row: 1543 Label: bird Probability: 0.6512818336486816 Coordinates: (173, 136, 222, 168)
Row: 1544 Label: bird Probability: 0.605888307094574 Coordinates: (173, 136, 222, 169)
Row: 1545 Label: bird Probability: 0.6010562777519226 Coordinates: (173, 136, 222, 169)
Row: 1546 Label: bird Probability: 0.6660826206207275 Coordinates: (174, 136, 222, 169)
Row: 1624 Label: bird Probability: 0.5813634395599365 Coordinates: (173, 136, 222, 169)
Row: 1625 Label: bird Probability: 0.5755418539047241 Coordinates: (174, 136, 223, 169)
Row: 1626 Label: bird Probability: 0.5425906181335449 Coordinates: (174, 136, 222, 169)
Row: 4224 Label: person Probability: 0.6522736549377441 Coordinates: (506, 410, 528, 458)
Row: 4225 Label: person Probability: 0.6930487155914307 Coordinates: (506, 410, 528, 458)
Row: 4226 Label: person Probability: 0.649591326713562 Coordinates: (528, 409, 547, 459)
Row: 4227 Label: person Probability: 0.6896713972091675 Coordinates: (528, 409, 547, 459)
Row: 4297 Label: person Probability: 0.5141710042953491 Coordinates: (450, 426, 474, 459)
Row: 4304 Label: person Probability: 0.6453979015350342 Coordinates: (506, 410, 528, 459)
Row: 4305 Label: person Probability: 0.6543363928794861 Coordinates: (506, 411, 528, 459)
Row: 4306 Label: person Probability: 0.6686833500862122 Coordinates: (528, 409, 547, 459)
Row: 4307 Label: person Probability: 0.670250654220581 Coordinates: (528, 409, 547, 459)
Row: 4377 Label: person Probability: 0.6253103017807007 Coordinates: (450, 426, 474, 459)
Row: 4378 Label: person Probability: 0.6047794222831726 Coordinates: (450, 426, 474, 459)
Row: 4384 Label: person Probability: 0.6403813362121582 Coordinates: (506, 410, 528, 459)
Row: 4385 Label: person Probability: 0.6593260169029236 Coordinates: (506, 411, 528, 459)
Row: 4386 Label: person Probability: 0.6783121824264526 Coordinates: (528, 409, 547, 459)
Row: 4387 Label: person Probability: 0.6697359681129456 Coordinates: (528, 409, 547, 459)
Row: 4457 Label: person Probability: 0.5939190983772278 Coordinates: (450, 426, 474, 459)
Row: 4458 Label: person Probability: 0.6158614158630371 Coordinates: (450, 426, 474, 459)
Row: 4464 Label: person Probability: 0.6724660396575928 Coordinates: (506, 410, 528, 459)
Row: 4465 Label: person Probability: 0.6691636443138123 Coordinates: (507, 411, 529, 459)
Row: 4466 Label: person Probability: 0.6635993123054504 Coordinates: (528, 409, 547, 459)
Row: 4467 Label: person Probability: 0.6709198355674744 Coordinates: (528, 409, 547, 459)
Row: 4537 Label: person Probability: 0.6160084009170532 Coordinates: (450, 426, 474, 459)
Row: 4538 Label: person Probability: 0.6102625131607056 Coordinates: (450, 426, 474, 459)
Row: 4544 Label: person Probability: 0.6642736196517944 Coordinates: (506, 410, 528, 459)
Row: 4545 Label: person Probability: 0.6493443250656128 Coordinates: (507, 410, 529, 458)
Row: 4546 Label: person Probability: 0.6440086364746094 Coordinates: (527, 409, 546, 459)
Row: 4547 Label: person Probability: 0.6871405243873596 Coordinates: (528, 409, 547, 459)
Row: 5121 Label: person Probability: 0.5096266269683838 Coordinates: (0, 489, 26, 566)
Row: 5200 Label: person Probability: 0.5972477793693542 Coordinates: (0, 489, 26, 566)
Row: 5201 Label: person Probability: 0.6127698421478271 Coordinates: (0, 489, 26, 566)
Row: 5280 Label: person Probability: 0.6291350722312927 Coordinates: (0, 489, 26, 566)
Row: 5281 Label: person Probability: 0.6749528646469116 Coordinates: (0, 489, 26, 565)
Row: 5286 Label: person Probability: 0.7652390599250793 Coordinates: (32, 505, 85, 567)
Row: 5287 Label: person Probability: 0.7516335248947144 Coordinates: (31, 505, 84, 567)
Row: 5294 Label: person Probability: 0.7526721954345703 Coordinates: (94, 518, 136, 568)
Row: 5360 Label: person Probability: 0.5917220711708069 Coordinates: (0, 489, 25, 565)
Row: 5361 Label: person Probability: 0.6364521980285645 Coordinates: (0, 489, 25, 566)
Row: 5366 Label: person Probability: 0.7760496735572815 Coordinates: (32, 505, 85, 567)
Row: 5367 Label: person Probability: 0.7628909945487976 Coordinates: (32, 505, 85, 567)
Row: 5368 Label: person Probability: 0.7380048632621765 Coordinates: (32, 505, 85, 567)
Row: 5373 Label: person Probability: 0.7580685615539551 Coordinates: (94, 518, 136, 569)
Row: 5374 Label: person Probability: 0.7388852834701538 Coordinates: (94, 517, 136, 568)
Row: 5375 Label: person Probability: 0.7215502858161926 Coordinates: (94, 518, 136, 569)
Row: 5446 Label: person Probability: 0.7717000246047974 Coordinates: (32, 505, 85, 567)
Row: 5447 Label: person Probability: 0.7657181024551392 Coordinates: (32, 505, 85, 567)
Row: 5448 Label: person Probability: 0.7473055720329285 Coordinates: (32, 505, 85, 567)
Row: 5453 Label: person Probability: 0.7478396892547607 Coordinates: (94, 518, 136, 569)
Row: 5454 Label: person Probability: 0.7133488059043884 Coordinates: (94, 517, 136, 568)
Row: 5455 Label: person Probability: 0.7043735384941101 Coordinates: (94, 517, 136, 568)
Row: 5468 Label: person Probability: 0.5442545413970947 Coordinates: (198, 511, 265, 579)
Row: 5469 Label: person Probability: 0.6227067112922668 Coordinates: (197, 511, 266, 584)
Row: 5470 Label: person Probability: 0.5938160419464111 Coordinates: (198, 511, 265, 584)
Row: 5526 Label: person Probability: 0.7778306603431702 Coordinates: (32, 505, 85, 567)
Row: 5527 Label: person Probability: 0.7625938653945923 Coordinates: (32, 505, 85, 567)
Row: 5533 Label: person Probability: 0.757384717464447 Coordinates: (94, 517, 136, 568)
Row: 5534 Label: person Probability: 0.7053558826446533 Coordinates: (94, 517, 136, 568)
Row: 5535 Label: person Probability: 0.7191171050071716 Coordinates: (94, 517, 136, 568)
Row: 5549 Label: person Probability: 0.6110237836837769 Coordinates: (198, 511, 266, 583)
Row: 5550 Label: person Probability: 0.5887100696563721 Coordinates: (198, 511, 265, 584)
Row: 6044 Label: skateboard Probability: 0.7509363889694214 Coordinates: (321, 594, 410, 620)
Row: 6045 Label: skateboard Probability: 0.7747182846069336 Coordinates: (321, 594, 410, 620)
Row: 6046 Label: skateboard Probability: 0.7707618474960327 Coordinates: (321, 594, 410, 620)
Row: 6124 Label: skateboard Probability: 0.7176411151885986 Coordinates: (321, 594, 411, 620)
Row: 6125 Label: skateboard Probability: 0.7304677367210388 Coordinates: (321, 594, 411, 620)
Row: 6126 Label: skateboard Probability: 0.7161608338356018 Coordinates: (321, 594, 411, 620)
Row: 6915 Label: skateboard Probability: 0.8558311462402344 Coordinates: (513, 176, 596, 266)
Row: 6954 Label: skateboard Probability: 0.8744772672653198 Coordinates: (513, 176, 596, 266)
Row: 6955 Label: skateboard Probability: 0.8591122031211853 Coordinates: (513, 176, 596, 266)
Row: 6956 Label: skateboard Probability: 0.8619626760482788 Coordinates: (513, 176, 596, 266)
Row: 6994 Label: skateboard Probability: 0.8528130054473877 Coordinates: (513, 176, 596, 266)
Row: 6995 Label: skateboard Probability: 0.8457393646240234 Coordinates: (513, 176, 596, 266)
Row: 6996 Label: skateboard Probability: 0.8386139273643494 Coordinates: (513, 176, 596, 266)
Row: 7034 Label: skateboard Probability: 0.8465473651885986 Coordinates: (513, 176, 596, 266)
Row: 7035 Label: skateboard Probability: 0.8342673778533936 Coordinates: (513, 176, 596, 266)
Row: 7036 Label: skateboard Probability: 0.8553557395935059 Coordinates: (513, 176, 596, 266)
Row: 7396 Label: person Probability: 0.9032446146011353 Coordinates: (567, 350, 624, 476)
Row: 7397 Label: person Probability: 0.8893184661865234 Coordinates: (567, 350, 624, 476)
Row: 7436 Label: person Probability: 0.8869150876998901 Coordinates: (567, 350, 624, 476)
Row: 7437 Label: person Probability: 0.8817752599716187 Coordinates: (567, 350, 624, 476)
Row: 7438 Label: person Probability: 0.8791399002075195 Coordinates: (567, 350, 624, 476)
Row: 7476 Label: person Probability: 0.8888946771621704 Coordinates: (567, 350, 624, 476)
Row: 7477 Label: person Probability: 0.8816529512405396 Coordinates: (567, 350, 624, 476)
Row: 7478 Label: person Probability: 0.8753525018692017 Coordinates: (567, 350, 624, 476)
Row: 7516 Label: person Probability: 0.8823326230049133 Coordinates: (567, 350, 624, 476)
Row: 7517 Label: person Probability: 0.8748416900634766 Coordinates: (567, 350, 624, 476)
Row: 7583 Label: person Probability: 0.8930309414863586 Coordinates: (317, 383, 430, 607)
Row: 7584 Label: person Probability: 0.8898133635520935 Coordinates: (317, 383, 430, 607)
Row: 7622 Label: person Probability: 0.8976937532424927 Coordinates: (317, 383, 430, 606)
Row: 7623 Label: person Probability: 0.892180860042572 Coordinates: (317, 383, 430, 607)
Row: 7624 Label: person Probability: 0.8762005567550659 Coordinates: (317, 383, 430, 607)
Row: 7650 Label: person Probability: 0.8702741861343384 Coordinates: (125, 433, 221, 612)
Row: 7651 Label: person Probability: 0.863052248954773 Coordinates: (125, 433, 221, 613)
Row: 7652 Label: person Probability: 0.8755483627319336 Coordinates: (125, 433, 221, 612)
Row: 7662 Label: person Probability: 0.8904131650924683 Coordinates: (317, 384, 430, 608)
Row: 7663 Label: person Probability: 0.8913979530334473 Coordinates: (317, 383, 430, 607)
Row: 7664 Label: person Probability: 0.8908348679542542 Coordinates: (317, 383, 430, 607)
Row: 7690 Label: person Probability: 0.8786476850509644 Coordinates: (125, 433, 221, 613)
Row: 7691 Label: person Probability: 0.8823875188827515 Coordinates: (125, 433, 221, 613)
Row: 7692 Label: person Probability: 0.8871062994003296 Coordinates: (124, 433, 220, 613)
Row: 7703 Label: person Probability: 0.8727951049804688 Coordinates: (317, 383, 430, 607)
Row: 7704 Label: person Probability: 0.8882538676261902 Coordinates: (317, 384, 430, 608)
Row: 7730 Label: person Probability: 0.8640760779380798 Coordinates: (125, 433, 221, 613)
Row: 7731 Label: person Probability: 0.8735520839691162 Coordinates: (124, 433, 220, 612)
Row: 7732 Label: person Probability: 0.8693354725837708 Coordinates: (124, 433, 220, 613)
Row: 7734 Label: person Probability: 0.73056960105896 Coordinates: (197, 511, 265, 584)
Row: 7771 Label: person Probability: 0.8833094835281372 Coordinates: (125, 433, 221, 612)
Row: 7774 Label: person Probability: 0.6753095388412476 Coordinates: (197, 511, 266, 584)
Row: 7775 Label: person Probability: 0.6801181435585022 Coordinates: (198, 511, 266, 584)
Row: 7889 Label: skateboard Probability: 0.552667498588562 Coordinates: (124, 580, 209, 637)
Row: 7890 Label: skateboard Probability: 0.53212571144104 Coordinates: (124, 580, 209, 635)
Row: 7902 Label: skateboard Probability: 0.8670096397399902 Coordinates: (321, 594, 412, 620)
Row: 7931 Label: skateboard Probability: 0.500882625579834 Coordinates: (125, 580, 208, 637)
Row: 7942 Label: skateboard Probability: 0.7937256097793579 Coordinates: (321, 594, 412, 620)
Row: 8054 Label: person Probability: 0.9370934963226318 Coordinates: (351, 24, 589, 255)
Row: 8073 Label: person Probability: 0.9352823495864868 Coordinates: (352, 25, 590, 256)
Row: 8074 Label: person Probability: 0.9121582508087158 Coordinates: (351, 25, 590, 256)
Row: 8075 Label: person Probability: 0.9136118292808533 Coordinates: (351, 25, 590, 255)
Row: 8093 Label: person Probability: 0.9387980699539185 Coordinates: (352, 25, 590, 256)
Row: 8094 Label: person Probability: 0.9149622917175293 Coordinates: (351, 25, 589, 256)
Row: 8095 Label: person Probability: 0.9190929532051086 Coordinates: (351, 25, 590, 255)
Row: 8113 Label: person Probability: 0.9341064691543579 Coordinates: (351, 25, 589, 256)
Row: 8114 Label: person Probability: 0.9218436479568481 Coordinates: (351, 25, 589, 256)
Row: 8115 Label: person Probability: 0.9284915924072266 Coordinates: (351, 25, 589, 256)
Je evidentní, že některé jsou “duplicitní”, protože jsou takřka stejné až na jeden pixel. To by se mělo odstranit, ale nám pro teď bude stačit je prostě všechny nakreslit. Nejdřív si pro každou třédu vygeneruji náhodně RGB barvu a přes cv2 knihovnu začneme zakreslovat obdelníky. Výsledek je velmi dobrý - model servírovaný přes Triton API nám opravdu funguje.
# Generate random color for each class
colors = {}
for class_id in range(80):
colors[class_id] = (np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255))
# Show boxes
imgresult = cv2.imread("test.jpg")
for box in boxes:
cv2.rectangle(
imgresult,
(box["coordinates"][0], box["coordinates"][1]),
(box["coordinates"][2], box["coordinates"][3]),
colors[yolo_classes.index(box["label"])],
2,
)
plt.imshow(cv2.cvtColor(imgresult, cv2.COLOR_BGR2RGB))
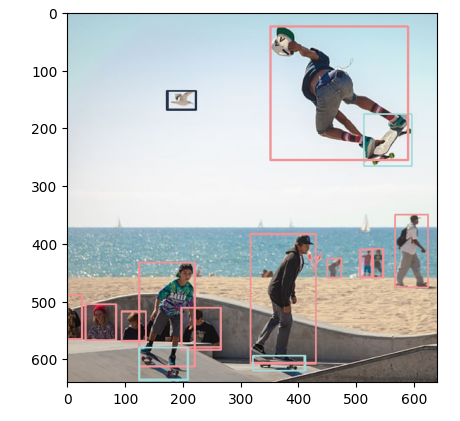
Tolik tedy k dnešní poslední části. Zkusili jsme výkonnostní charakteristiky různých strojů v Azure, zabalili modely, použili servírovací řešení Triton a to celé zasadili do příjemného managed endpointu v Azure Machine Learning. Tím sérii computer vision s open source projektem YOLO ukončím, ale pokud vás to zajímá, tak bychom se mohli společně podívat i na servírování takovýchto modelů ve větší škále jako kdyby to byla vaše živnost. Kouknout, jak by se na to dalo jít v Kubernetu, balancovat globálně přes víc clusterů nebo vyřešit věci jako rate limit a klíče per zákazník (asi by to hrálo na API Management). Jestli by vás něco takového zajímalo, pinkněte mi zprávičku na LinkedIn.