Všichni jsou teď zakleknutí v jazykových modelech a není se co divit. Nicméně vizuální věci jsou stále naprosto zásadní a to zejména ve světě lidí, kteří (kromě hmatu) mají vidění za jednoznačně nejdůležitější smysl (na nedotykové vzdálenosti). V této oblasti je jeden open source model, který je po mnoho let na špičce zejména v detekci objektů a dokáže dost kouzel. Jak dobré je YOLOv8 a jak ho použít v Azure?
Dnes se zaměříme na první část - natrénovaný model, který nebudeme nijak měnit.
Disciplíny, které YOLO zvládá
Aktuálně jde o čtyři kategorie problémů:
- Klasifikace - jaké tagy lze k obrázku přiřadit, tedy co na obrázku je? Sportovec, auto, strom, …? Jde o nejstarší soutěžní disciplínu, její využití je zejména v kategorizaci vstupů (proč místo fotky auta posíláte fotku psa, detekce lechtivého či jinak nevhodného obsahu, detekce nebezpečí nebo násilí).
- Objekty - dej mi seznam objektů, které poznáváš a k nim souřadnice čtverců, ve kterých jsou. Také dnes už dost tradiční disciplína, která dřív byla velmi náročná, protože se používala klasifikace výřezů (od prvotního dej “obvyklé” výřezy a udělej klasifikaci přes pozdější detekuj jakékoli objekty a nad nimi udělej klasifikaci). YOLO už pracuje v režimu, kdy jedním průchodem umí najít vícero objektů.
- Segmentace - které pixely patří psovi? Čtverec ve kterém objekt je může být fajn, ale pro některé přesnější aplikace (např. analýza snímků ve zdravotnictví) to je určitě nedostatečné. Potřebujete objekt přesně ohraničit. Asi nechcete, aby vám následně laser vyřezával z těla “obdelníčky” - přesné ohraničení útvaru je zásadní.
- Pozice těla - jak je člověk natočen resp. kde jsou jeho základní body na ramenou, rukou, nohou, na hlavě? K čemu je dobré něco takového? Představte si například sportovní události a fakt, že pravidla často mluví o určitých částech těla. Například v atletice je za “protnutí pásky” považována situace, kdy se trup “dotkne” čáry - nikoli ruce, nohy nebo hlava. Ve fotbale je zase pro offside počítána část těla, která “může hrát”, takže na rozdíl od atletiky se bere nejen trup, ale i nohy a hlava, ale ne ruce. Kdykoli potřebujete znát pozici těla ať už je to sport nebo bezpečnostní kamera, tohle je možné řešení.
Praktická zkouška
Pro dnešní účely budu pracovat v Jupyter notebooku, který si připojím na Azure Machine Learning compute mašinu pro začátek s pouhým CPU (výkonnostním a cenovým otázkám se budu věnovat později).
Notebook najdete zde: https://github.com/tkubica12/ai-demos/blob/main/yolo/trained_model.ipynb
Nejdřív nainstalujeme a importujeme YOLOv8.
# Install YOLOv8
%pip install ultralytics
%pip install opencv-python
# Import YOLOv8
from ultralytics import YOLO
# Import image visualization
import cv2
Následně jsem si stáhl sadu obrázků z COCO soutěže 2017.
# Download COCO dataset
!wget http://images.cocodataset.org/zips/train2017.zip
!wget http://images.cocodataset.org/zips/val2017.zip
!wget http://images.cocodataset.org/zips/test2017.zip
!wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
!wget http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
!wget http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip
# unzip
!unzip train2017.zip
!unzip val2017.zip
!unzip test2017.zip
!unzip annotations_trainval2017.zip
!unzip stuff_annotations_trainval2017.zip
!unzip panoptic_annotations_trainval2017.zip
Vybuduji si seznam názvů souborů v testovací sadě.
# Get list of files
import os
folder_path = 'test2017'
files = os.listdir(folder_path)
Následně budeme ukazovat náhodně vybraný původní obrázek a k němu scoring za detekci objektů, segmentaci a pozici těla. Použiji model velikosti L - tedy druhý největší, který dává skvělé výsledky a přitom nemusím ani na CPU dlouho čekat (nicméně do realtime to má daleko - výkonnost a nasazení v Azure budeme zkoumat v jiné části).
# Select random file
import random
random_filename = f"{folder_path}/{random.choice(files)}"
print(random_filename)
# Show original image
%matplotlib inline
from matplotlib import pyplot as plt
img = cv2.imread(random_filename)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# Select object detection pretrained model
model = YOLO('yolov8l.pt')
# Score and show results
results = model(random_filename)
res_plotted = results[0].plot()
plt.imshow(cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB))
# Select segment detection pretrained model
model = YOLO('yolov8l-seg.pt')
# Score and show results
results = model(random_filename)
res_plotted = results[0].plot()
plt.imshow(cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB))
# Select pose detection pretrained model
model = YOLO('yolov8l-pose.pt')
# Score and show results
results = model(random_filename)
res_plotted = results[0].plot()
plt.imshow(cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB))
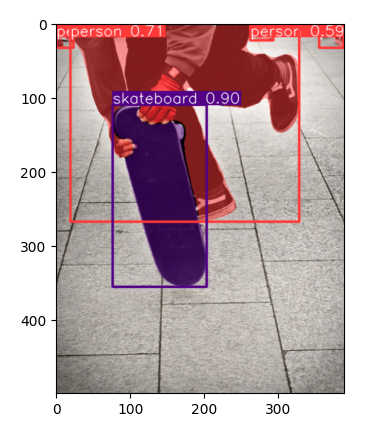
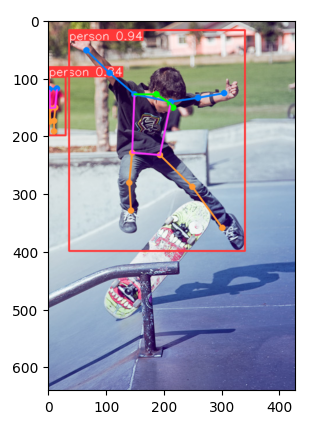
Pojďme se podívat na pár příkladů. Tady je poměrně složitá situace, kdy je člověk částečně schovaný za scateboardem. Doporučuji vaší pozornosti přesnost obou, přestože jsou v zákrytu a taky fakt, že boty v horní části jsou správně byť s nižší pravděpodobností (a to taky sedí) identifikovány jako další osoby.

Podívejme se ale na modernější kategorii - segmentace. V tomto případě červeně obarvíme pixely osob a fialově scateboard. Výsledky jsou za mě úžasné - všechny překryvy a ruce jsou prostě správně.
Na pozici tohle není ideální obrázek, přesto mám celkem rozumnou představu o detekovaných kloubech - ale není to vůbec ono, dva kotníky na jedné noze tam opravdu nejsou. Ale asi bych odpustil, navíc takový obrázek není pro zamýšlené použití detekce pozice těla nějak reprezentativní (kvůli výřezu).

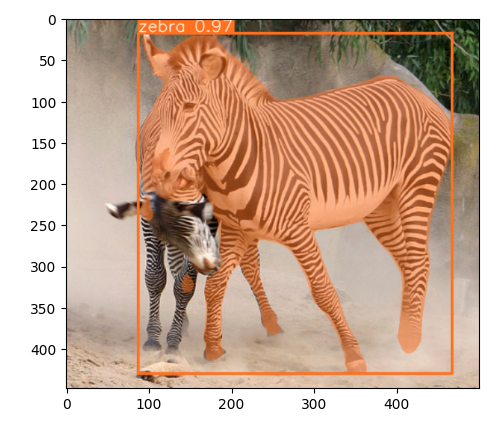
Tady je další hezký příklad segmentace.

Tady to ale AI nedalo, nicméně je to opravdu těžké. Řekl bych, že vy to dokážete kvůli tomu, že si jdete přepočítat nohy - ale z hlav byste to taky nemuseli zvládnout.
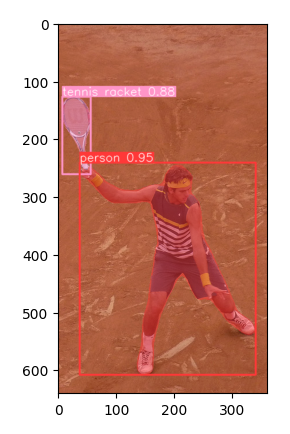
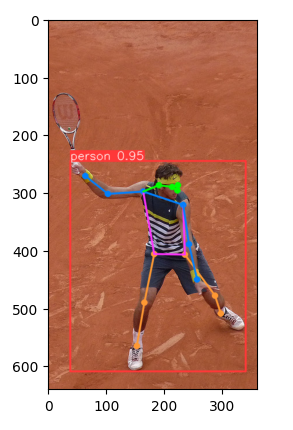
Podívejme se na příklad s tenistou a zejména jeho detekci pozice.
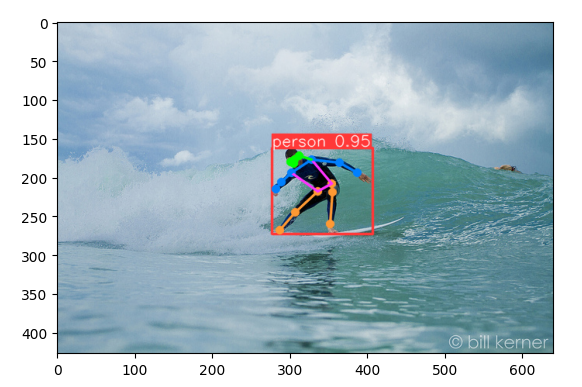
Pozice surfaře.
A scateboardisti.

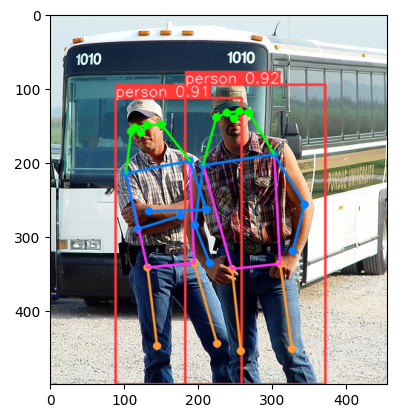
Dva týpci.
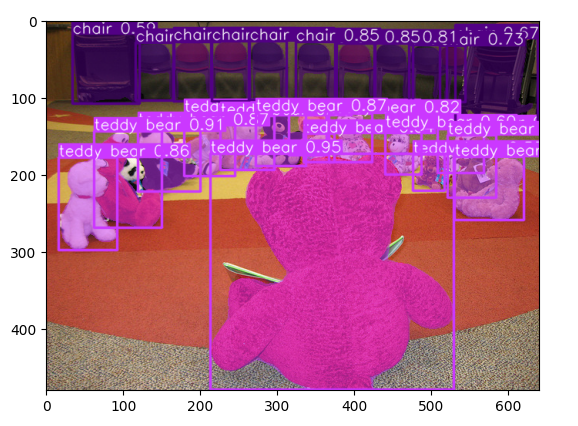
Takhle vypadá hromada plyšáků po segmentaci.
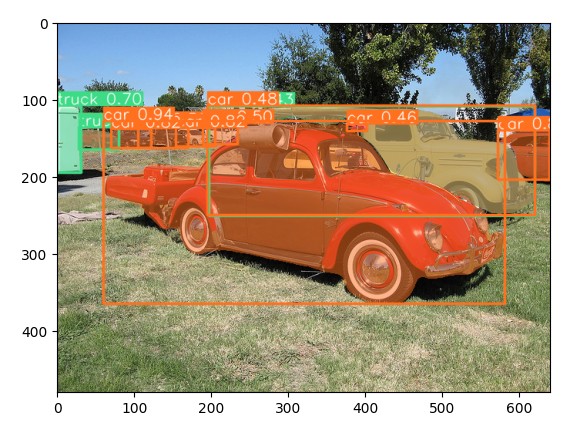
Autíčka.
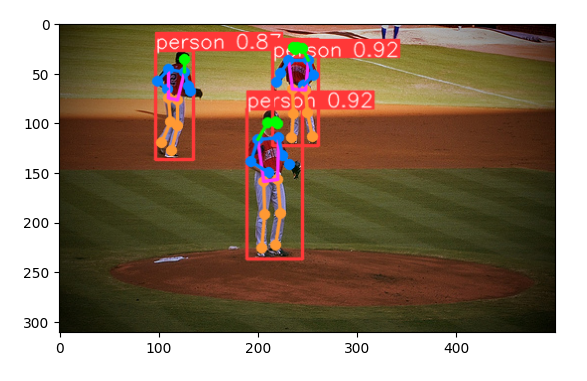
Baseball.
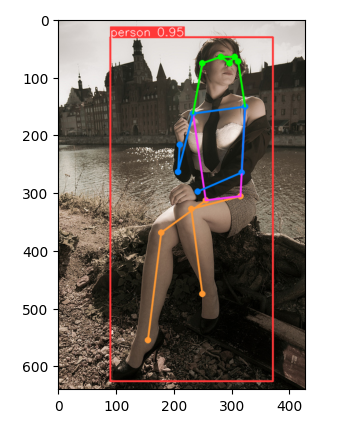
Lyžarka.

Pěkná paní.
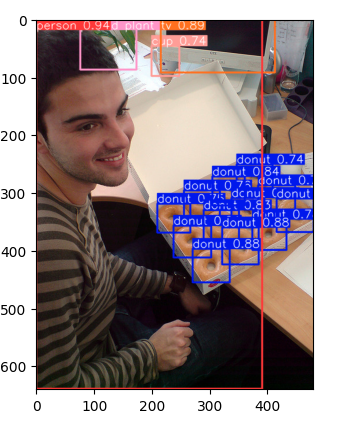
Pán s donuty.
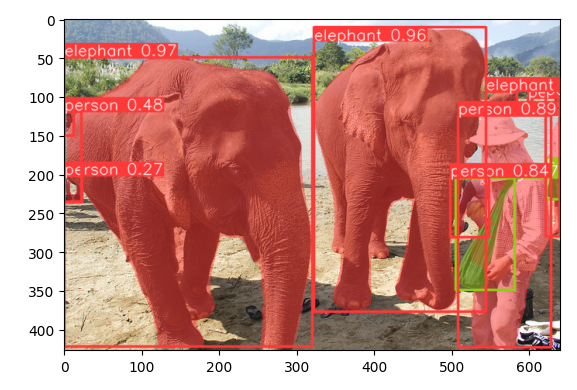
Segmentace slonů a lidí.
Ptáci a pán s batohem.

Pocitové hodnocení výsledků a co dál
Za mě musím říct, že YOLOv8 funguje opravdu skvěle a to i ve srovnání se službami typu Azure Cognitive Services. Je samozřejmě otázka co znamená starat se o model, patchování infrastruktury, dostupnost, výkon a kolik to všechno bude stát vs. hotová služba - na to se ještě mrkneme. Ale příště ještě ne - to si budeme zkoušet dotrénovat nebo vytrénovat vlastní model - někdy potřebujeme, aby AI znalo naše konkrétní objekty, třeba naše produkty, výrobní stroje nebo doménovou specializaci (kynologové si nevystačí se štítkem “pes” a lékaři asi potřebují o dost detailnější analýzu snímků, než jen prohlásit, že na fotce je “rentgen” nebo “cétéčko”). Příště tedy budeme YOLOv8 trénovat vlastními daty.