Do služby Azure Machine Learning jsem si přidal compute s NVIDIA A100 kartičkou, což je celkem dělo a pustil se do trénování YOLOv8. Jaké máte možnosti přidat svoje data, kudy do toho a jak to funguje? Tyhle hrátky by nám zase znovu měly pomoci pochopit rámcově co se děje při trénování a k čemu je transfer learning.
Budu si hrát se svojí oblíbenou sadou, která je nesmírně primitivní - dva plyšáci, 23 fotek na trénování, 3 na validaci, 2 na test. To je samozřejmě strašně málo a měli byste mít vždy daleko víc, ale pro základní představu tohle stačí (ostatně už tyhle fotky používám asi šest let na rychlé vyzkoušení). Těch pár let co uplynulo od pořízení těch fotek dramaticky snížilo jejich oblíbenost díky nástupu puberty jejich majitele, tak snad mají radost, že jejich machine learning hodnota zůstala zatím zachována.
Jako obvykle data najdete na mém GitHubu a dnes se budeme pohybovat v tomhle notebooku YOLO formát pro popis obdelníků pro objekty používá txt soubor ke každému obrázkovému souboru a v něm jednoduše ID objektu a čtyři souřadnicová čísla (resp dvě souřadnice středu + šířka a délka rámečku) - co objekt to řádek. Pokud jste označování objektů udělali jako projekt v Azure, tak to podporuje výstup jen v COCO formátu, takže pak musíte převádět (nebo použijte CVAT, Label Studio nebo třeba Roboflow). Zkrátka AML labelování je ideální, pokud data budete dál zpracovávat v AML, protože vyplivne rovnou MLtable formát, který je vstupem třeba do AutoML. Nicméně to zatím nemá yolov8 (jen yolov5), ale i když bude mít, tak zatím chci zůstat v notebooku, abychom si to osahali.
Samozřejmě - tohle je strašně málo, dělat validaci na třech fotkách je samozřejmě mimo … nicméně principy nám odhalí i to.
Transfer learning - vlastní obrázky, rychlé a dobré výsledky
Moje úloha má docela blízko ke generickým objektům tak jak jsou třeba v COCO sadě, která byla použita pro natrénování YOLOv8. Celá finta je, že si do modelu načtu předtrénovaný yolo model, například ve variantě object detection velikosti nano - stejně jako jsme to dělali minule. Tedy topologii, vypočítané váhy, všechno.
model = YOLO('yolov8n.pt')
Minule jsme mu předali obrázek a už to frčelo. Teď ale uděláme něco jiného - připravíme si data (popíšeme jejich strukturu v YAMLu) a rozjedeme trénování. Borci model natrénovali na velkém množství dat a výsledkem toho všeho jsou vlastně jen váhy, tedy hodnoty, které dosadíme za neznámé do vzorců. My teď tyhle hodnoty (váhy) vezmeme a na našich datech je budeme brát jako výchozí a budeme ladit dál. Nějaké dvě stovky vrstev a mraky parametrů už umí rozpoznávat tvary, přechody, hrany, textury, ale i ouška, nosy a nepotřebujeme první vrstvy moc měnit (rozpoznávají typicky hodně nízkoúrovňové věci typu hrany), ale ty pozdější už trochu ano a zejména na konci ty klasifikační vrstvy zcela (to, kde se z detekovaných vlastností určí jaká je to kategorie odstřihneme a dodáme svoje třídy a vrstvy). YOLOv8 to udělá, stačí zapnout trénink.
train = model.train(data='./datasets/2plysaci.yaml', epochs=100, imgsz=1024)
Malý model
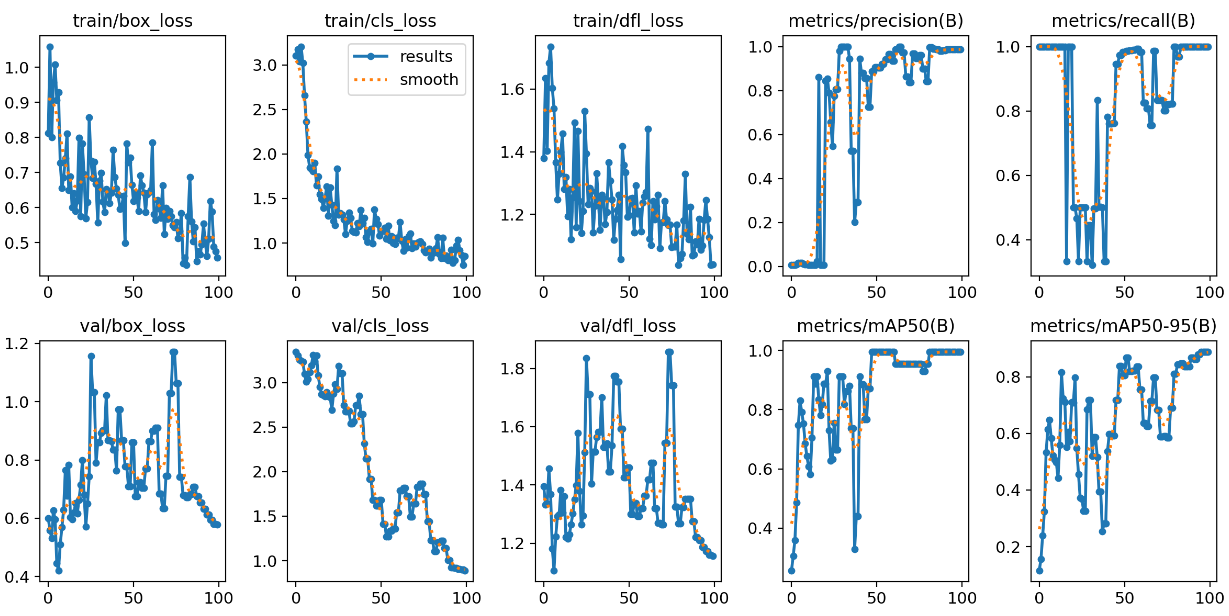
Vzal jsem tedy nejmenší model a rozjel 100 epoch. Z grafů se zdálo, že model se ještě chvilku zlepšoval, ale výsledky na test sadě nebyly dobré, takže 100 epoch evidentně na můj scénář stačilo. Vidím, že moje A100 se moc nezapotila a do dvou minut to měla zmáknuté.
100 epochs completed in 0.028 hours.
Optimizer stripped from runs/detect/train13/weights/last.pt, 6.3MB
Optimizer stripped from runs/detect/train13/weights/best.pt, 6.3MB
Validating runs/detect/train13/weights/best.pt...
Ultralytics YOLOv8.0.120 🚀 Python-3.8.5 torch-1.12.0 CUDA:0 (NVIDIA A100 80GB PCIe, 80995MiB)
Model summary (fused): 168 layers, 3006038 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 44.20it/s]
all 3 6 0.987 1 0.995 0.888
oslik 3 3 0.986 1 0.995 0.929
ovecka 3 3 0.988 1 0.995 0.847
Speed: 0.1ms preprocess, 2.7ms inference, 0.0ms loss, 0.9ms postprocess per image
Máme tady model s 3M parametry a všimněte si, že soubor s jeho výsledky má asi 6MB (samozřejmě stejně jako původní model -> k žádné významné změně velikosti nedošlo, jen jsme trochu jinak udělali váhy a tak). Na testovací fotce to vyšlo opravdu pěkně.

Když koukneme na metriky, tak je vidět, že model se krásně učil a mAP50-95 se vyšplhalo příjemně vysoko (jak jsem psal - validační i trénovací sada je směšně malá, takže to trochu lítá, ale trend tam je).
Pro jistotu si ještě ukážeme nějaký jiný obrázek. Očekáváme, že na něm neuvidí model oslíka nebo ovečku, ale taky bohužel nepozná člověka (klasifikaci původního modelu jsme nahradili plyšáky).

Větší modely a problém overfittingu
Skvělé. A100 mám nažhavenou, dáme větší model s 11M parametry. Jenže moje množství dat je opravdu směšně malé a nezdá se, že by nano model nebyl dostatečně komplexní na to, aby moje plyšáky pochopil. Nejen, že možná zaplatím zbytečně, ale větší model bude mít tendenci se přetrénovat a vidět pak oslíky úplně ve všem.
100 epochs completed in 0.093 hours.
Optimizer stripped from runs/detect/train12/weights/last.pt, 22.6MB
Optimizer stripped from runs/detect/train12/weights/best.pt, 22.6MB
Validating runs/detect/train12/weights/best.pt...
Ultralytics YOLOv8.0.120 🚀 Python-3.8.5 torch-1.12.0 CUDA:0 (NVIDIA A100 80GB PCIe, 80995MiB)
Model summary (fused): 168 layers, 11126358 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 45.54it/s]
all 3 6 0.973 1 0.995 0.941
oslik 3 3 0.992 1 0.995 0.93
ovecka 3 3 0.954 1 0.995 0.952
Speed: 0.2ms preprocess, 2.6ms inference, 0.0ms loss, 0.6ms postprocess per image
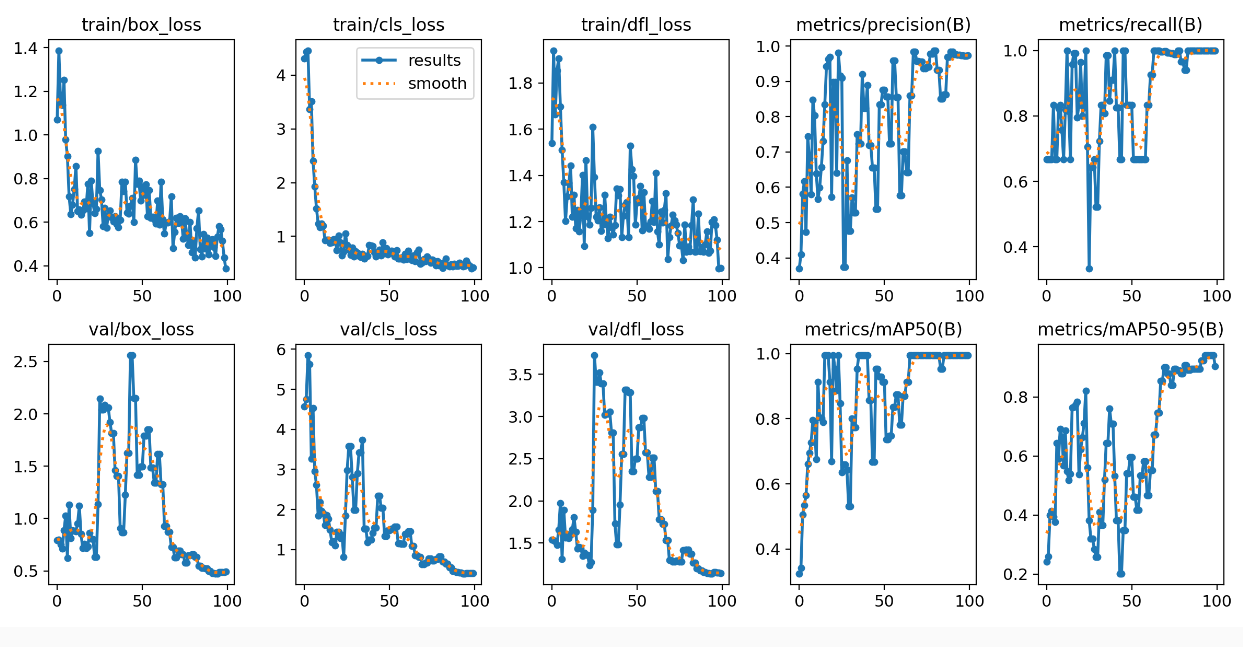
Za nějakých 6 minut to je hotové a výsledky, asi dle očekávání, nejsou nějak lepší.

Výsledek v pořádku, byť s nižší jistotou.
Pro zajímavost pojďme přitočit - dejme model s 43M parametry.
57 epochs completed in 0.072 hours.
Optimizer stripped from runs/detect/train11/weights/last.pt, 87.7MB
Optimizer stripped from runs/detect/train11/weights/best.pt, 87.7MB
Validating runs/detect/train11/weights/best.pt...
Ultralytics YOLOv8.0.120 🚀 Python-3.8.5 torch-1.12.0 CUDA:0 (NVIDIA A100 80GB PCIe, 80995MiB)
Model summary (fused): 268 layers, 43608150 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 18.79it/s]
all 3 6 0.5 0.833 0.602 0.475
oslik 3 3 0.5 0.667 0.474 0.319
ovecka 3 3 0.5 1 0.731 0.632
Speed: 0.1ms preprocess, 5.6ms inference, 0.0ms loss, 7.5ms postprocess per image
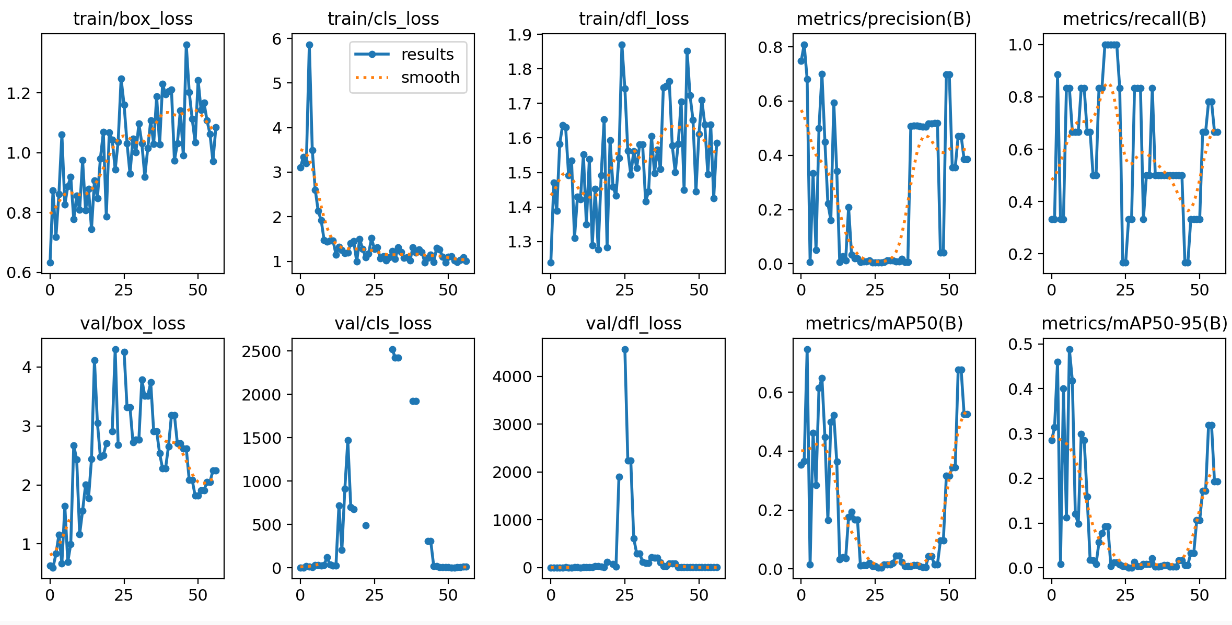
Model zastavil dřív (po 50 epoch po sobě se nezlepšil), po přepočtu na 100 epoch by to trvalo nějakých 8 minut (A100 se konečně trochu procvičí). Dejme testovací obrázek a safra - někdo nám to tady s učením přehnal.
Metriky neukazují nic dobrého - recall i precision létá tam a zpátky, mAP50-95 je tragická, validační loss funkce mají extrémní hodnoty.
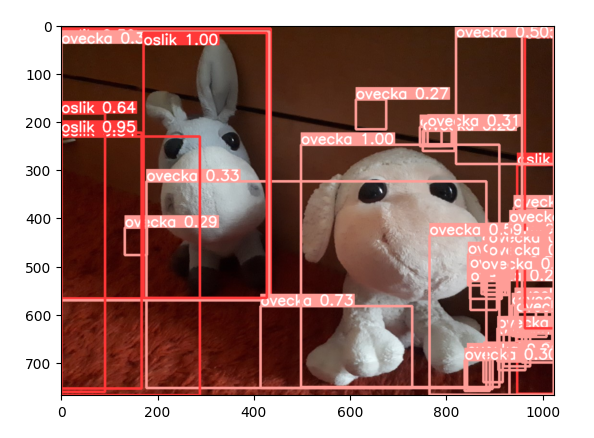
Když se podíváme znovu na fotku človíčka, model vidí všude plyšáky.
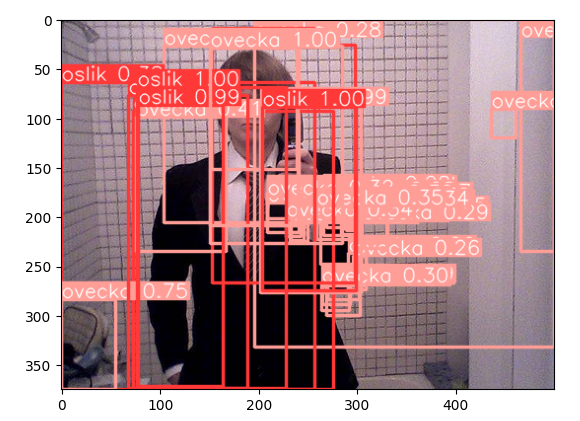
Máme tady jasný overfit. Dělat rozmáchlé modely když nemáme pořádná data evidentně nedává smysl.
Zamčené vrstvy
V předchozím scénáři jsme ovliňovali všechny vrstvy. Fine-tuning modelu se někdy dělá tak, že prvotní vrstvy modelu zamkneme - nepřipustíme jejich změnu, jejich učení, a ladíme až pozdější vrtvy, které představují už reprezentace vyšších vlastností (místo hran třeba ouška). To může snížit dobu učení (zejména pokud máme relativně hodně nových dat) a snížit overfit. Extrémní podoba pak je, že všechny vrstvy zpracování obrazu zmrazíme a přetrénujeme jen klasifikační vrstvy (computer vision obvykle funguje tak, že má poměrně dost konvolučních vrstev, tedy těch co nejsou plně, ale místně propojené, analyzují související oblasti obrazu a postupně extrahují vyšší a vyšší vlastnosti - a nad nimi jsou plně propojené vrstvy klasifikační, které interpretují výsledek zpracování obrazu). Tomu se pak říká feature extraction. Necháme model zpracovávat obrázky beze změny, ale výsledný set features budeme jinak interpretovat.
YOLOv5 mělo zamykání přímo ve svém API, ale u v8 už to není. Zdá se, že důvodem je, že rychlost trénování v8 to zas tak zásadně neovlivňuje, tak to tam nedali. Nicméně lze to udělat přes callback, kdy se na začátku trénování model předá naší funkci, která proběhne vrstvy a pár prvních zmrazí (v Pytorch nastaví requires_grad na False).
def freeze_layer(trainer):
model = trainer.model
num_freeze = 10
print(f"Freezing {num_freeze} layers")
freeze = [f'model.{x}.' for x in range(num_freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
print(f"{num_freeze} layers are freezed.")
# Uncomment to freeze layers
model.add_callback("on_train_start", freeze_layer)
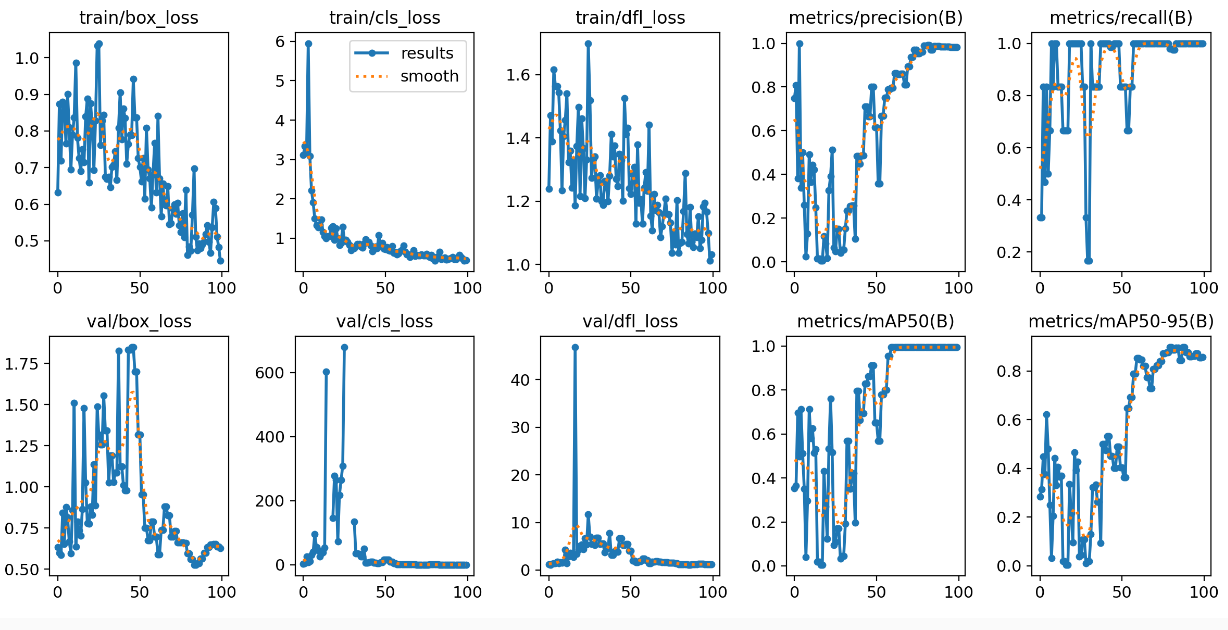
Vezměme si model velikost L. Ten jak jsme dříve viděli trpěl na našem extrémně malém vzorku dat masivním přetrénováním. Co když zamknu prvních 10 vrstev? Čas trénování počítaný na 100 epoch klesl z 8 na 6 minut na mé A100 v Azure, což není nějak velká úspora, ale u většího množství dat, kde by celé trénování bylo třeba o řád větší, už nějaký ten dolárek ušetřím. Podstatnější ale je, že zamčením iniciálních vrstev bychom měli i snížit schopnost modelu udělat rychlý overfit.
Obrázek plyšáku dopadl skutečně nadmíru dobře.

V obrázku bez plyšáků ale stále vidíme dost velký overfit, nicméně srovnejte s předchozím odstavcem - dramatické zlepšení.

Když koukneme na metriky, tak vypadají daleko příčetněji. Loss funkce při trénování klesají, vybavovací schopnost i přesnost rostou.
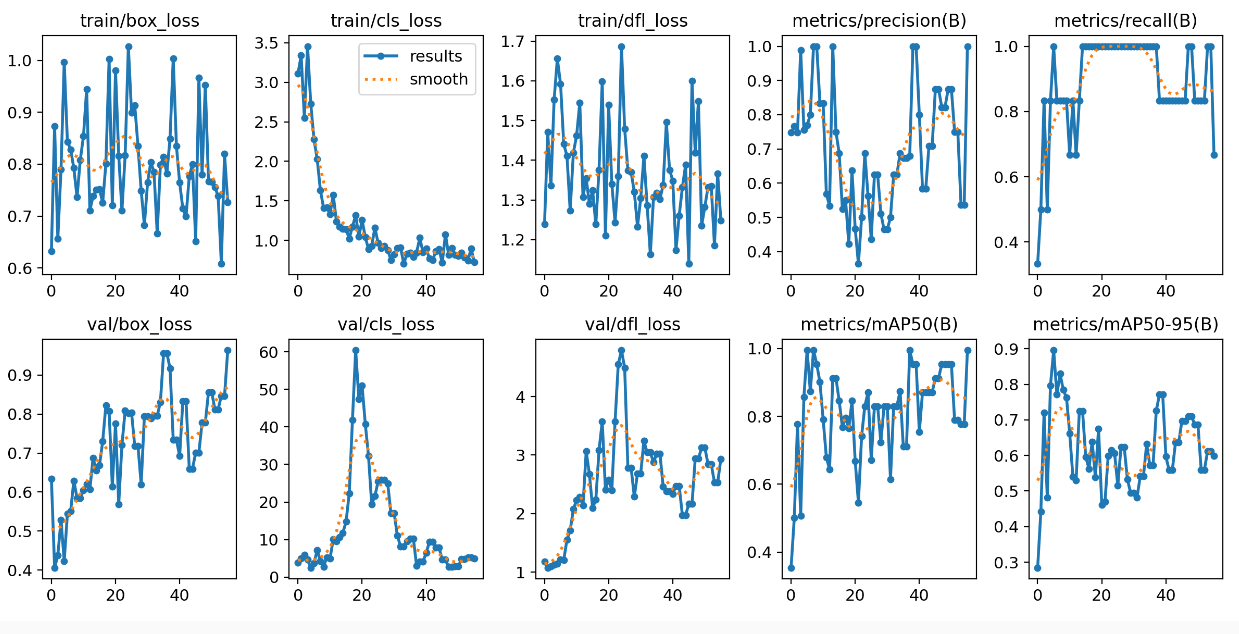
A co když mu zamknu 30 vrstev? To už je evidentně moc (u YOLOv5 se doporučovalo zkoušet zamykat něco mezi 5 a 10 vrstvami). Situace je ale pořád lepší, než u úplně původního scénáře velkého modelu.


Metriky jsou opět zběsilé - hodně skáčou, model se evidentně neučí moc dobře.
Obecně vzato zdá se, že kvalitativně je lepší provádět fine-tuning. Feature extraction může být ale dobrá volba tam, kde je nových dat strašně moc a rozdíl v nákladech na změnu modelu je zásadní. Třeba jako dočasné opatření, než uděláte plnohodnotný fine-tuning nebo dokonce svůj vlastní model (a to je námět dalšího dílu).
Dnes jsme si tedy vyzkoušeli fine-tuning modelu, transfer learning. Využili jsme výsledky někoho jiného, kdo utratil spoustu peněz za běh GPU, a nad tím rychle vytrénovali naše plyšáky. Nicméně všimněte si, že teď máme model na plyšáky a model na to ostatní - ale ne dohromady. To nemusí vadit, spojíme si to aplikačně, ale ne vždy je to výsledek co chceme.
Příště se podíváme na to, jak natrénovat úplně vlastní model, jak dělat transfer learning z vlastního modelu na nová data a srovnáme výpočetní náročnost s přetrénováním se starými i novými daty.