Tento týden Microsoft a Meta oznámili prohloubení spolupráce v oblasti AI a od prvního okamžiku tak můžete jejich nový jazykový model najít v Azure Machine Learning službě na kliknutí. Pojďme si dnes říct co nová Llama 2 je, proč je to velká událost, prakticky si vyzkoušíme v Azure, kde si model vystavíme a napíšeme si k němu jednoduché GUI v Gradio frameworku.
Llama 2 od Meta
LLama byl dost silný velký jazykový model (LLM) od Meta, který měl otevřený “kód”, ale váhy ne zcela. Jinak řečeno měli jste vzoreček, ale natrénované hodnoty (výsledek statisíců dolarů trénování) přímo volně ne. To bylo určeno jen pro registrované výzkumníky … nicméně to dlouho nevydrželo a stáhli jste váhy všude na Torrentu. Jenže to hlavní se tím nezměnilo - Llama licenčně zakazovala komerční využití. To tedy platí i pro projekty (Alpaca, Vicuna), které na to navázaly a prováděli jeho fine-tuning, aby model nejen doplňoval text, ale reagoval na instrukce uživatele a mohl si s ním povídat v chat rozhraní. Tím pádem ale i ty jsou pro výzkumné účely a nemůžete je použít ve svém produktu.
Llama 2 tohle mění. Model je vylepšený a přestože není větší, tak je silnější. Navíc přímo od Meta je k dispozici i jeho varianta laděná na instrukce (chat). No a hlavně - celé to je open source a můžete využívat i pro komerční účely.
Podle testů, které Meta dělalo, si model vede velmi dobře. Na GPT-4 rozhodně nemá, ale pro GPT-3 je v některých oblastech konkurentem a to je na open source model opravdu dobré. Jenže, jak uvidíte později, spustit si jeho velkou variantu není jen tak - nároky 70B verze jsou brutální a oproti OpenAI službě myslím neušetříte - naopak. Hlavní výhoda je v otevřenosti (očekávám boom ekosystému nad tím) a možnosti fine-tuningu.
Parametry, architektura a kolik sežralo trénování
Model Llama 2 přichází ve třech velikostech a dvou variantách. Počet parametrů můžeme chápat jako velikost mozku a vyšší počet znamená potenciálně vyšší inteligenci, ale také dramatický nárůst spotřeby zdrojů a to i pro inferencing (hostování modelu a pokládání dotazů). 7B model (7 miliard parametrů) byste měli být schopni rozběhat na domácím počítači s rozumnou grafikou (Microsoft připravuje ONNX zabalení modelu do Windows), 13B už je trochu náročnější a 70B je masakr (výzkumná práce zmiňuje i 36B variantu, ale ta nebyla uvolněna pro veřejnost).
V porovnání s předchozí generací se velikost mozku prakticky nezměnila (byla 7B, 13B, 33B a 65B), ale délka kontextu (např. kolik informací můžete nahrát do promptu nebo jak dlouho si povídat s udržením kontextu) je teď 4K (místo původních 2K) a hodně narost objem trénovacích dat z 1T resp. 1,4T na 2T (model měl tedy více učebnic k dispozici - konkrétně 2 biliony tokenů).
Jak dlouho se trénovalo? Meta použila NVIDIA A100 GPU (asi 2000 karet a Infiniband networking) - neměli tedy ještě farmu novějších H100, tak jak je postavil Azure pro OpenAI. 7B model potřeboval 184 320 GPU-hodin, 13B model 368 640 a 70B model šílených 1 720 320. Pokud byste byli frajeři a vzali si to v pay-as-you-go z Azure, tak je to cirka 7 milionů dolarů za 70B trénink. Spotřeba nemalá a emise v ekvivalentu vypuštěného CO2 jsou nějakých 150 tun, což je při emisích osobního auta Toyota 100g/km nějaký jeden a půl milionu proježděných kilometrů, tedy asi 37x kolem dokola zeměkoule u rovníku.
To, že Meta dala model a hlavně váhy k dispozici, je velká věc v hodnotě milionů dolarů.
Fine-tuning na chatování
Skvělou novinkou je, že přímo Meta přinesla fine-tunovaný model na chat. Dnes už jsou na to lidé zvyklí a očekávají to. Základní model doplňuje text a dostat z něj co potřebujete vyžaduje dost cviku - model vám totiž často například na otázku reaguje podobnou otázkou, což není co potřebujete. Síla ChatGPT a důvod obrovské popularizace celého odvětví je právě ve fine-tuningu, protože původní GPT-3 model je z roku 2020 a tenkrát takové haló nezpůsobil přičemž ChatGPT nemělo “lepší mozek” (dnes s GPT-4 už je to jiné), jen lepší fine-tuning.
Meta tedy natrénovalo základní model, který si sám četl (self-supervised learning) a stal se z něj skvělý doplňovač textu. V jeho váhách je teď skrytá celá síla modelu, můžete to také vnímat tak, že provedl komprimaci veškerého vstupního materiálu do sebe. Má to v sobě, ale lidem se to špatně loví.
Meta teď vzala tento model a začala ho ladit nad kvalitními supervised learning daty (SFT - Supervised Fine-Tuning) obsahujícími příklady otázek a vhodných odpovědí. Ve studii říkají, že zkoušeli miliony připravených promptů, co jsou dostupné v různých otevřených i komerčních datových sadách, ale nebyli spokojeni s kvalitou výsledného modelu. Podle nich je právě ta kvalita to nejdůležitější. Základní model měl dat dost, nepotřebuje futrovat dalším balastem, ale naopak top kvalitou na doladění. Ve finále použili jen 27 540 anotací, které jim na zakázku připravovali kontraktoři.
Po SFT následuje lidská zpětná vazba (RLHF - Reinforcement Learning Human Feedback), kdy lidé hodnotí odpovědi modelu (na stejnou otázku necháte vygenerovat dvě varianty odpovědi a člověk má vybrat tu lepší) a ten se z toho učí. Hodnotitelé se soustředili hlavně na užitečnost (jestli odpověď pomohla, byla srozumitelná) a bezpečnost (jestli model nevygeneroval něco nevhodného). Celkem získali asi 1,5 milionu takových hodnocení a z toho se model posupně zlepšoval.
Jak s češtinou?
Špatně - 90% textů na vstupu bylo v angličtině a k tomu 8,4% unknown (což představuje programovací jazyky). V češtině bylo 0,03%. Později vyzkoušíme v praxi - říct si o nějaký překlad se celkem dá, ale složité dotazy v češtině to nezvládá.
Vystavíme model v Azure Machine Learning
V katalogu modelů v Azure ML si najdu Lllama 2. Bohužel pro nasazení 70B Azure vyžaduje jako minimum stroje ND40rs_v2 nebo ND96 v4 a to je krapet masakr, který ve své subskripci nemám a nedostanu. Tihle mazlíci stojí kolem 30 USD na hodinu (k ceně se ještě dostaneme - na nějaké hraní rozhodně nepočítejte, že díky Llama ušetříte za OpenAI, naopak). Jdu tedy do modelu 7B, který jsem schopen rozběhat na NCv3 s V100 kartou (a mimochodem 13B už se mi nevejde do paměti karty … mazec a to je to jen inferencing).
Základní model lze dotrénovat - ale na fine-tuning se podíváme jindy.
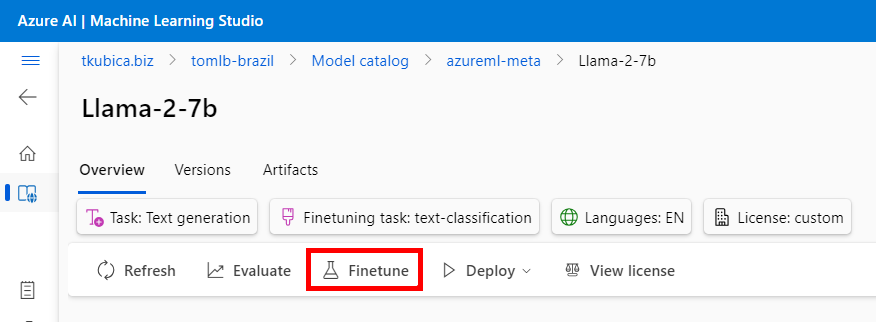
Já tedy jdu nasadit real-time endpoint pro 7B chat model a polituji svou kartu kreditní (kecám, mám na interní útratu kredit … ale není neomezený).

Po asi čtvrt hodině je endpoint nahoře.
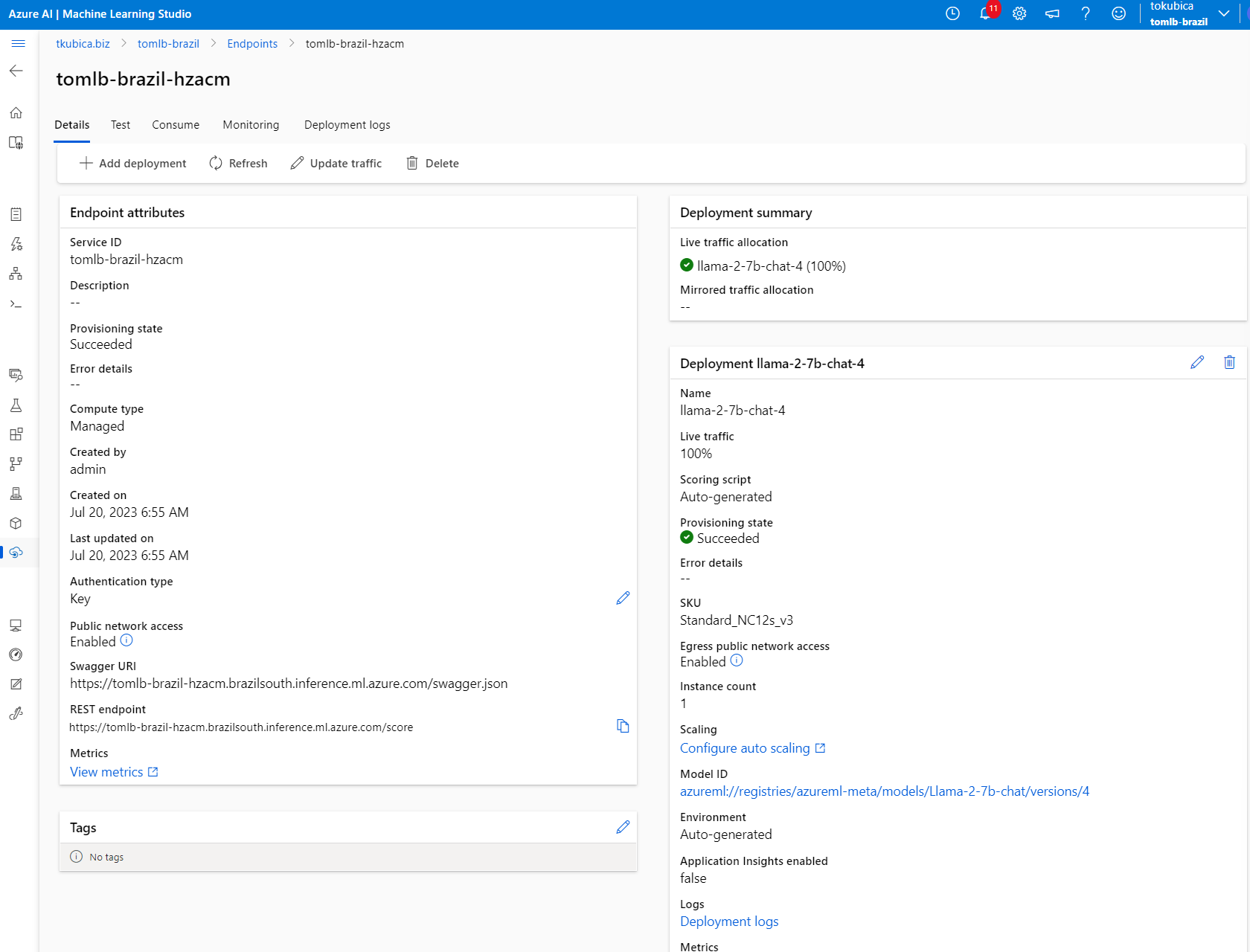
Můžeme z GUI otestovat - funguje to.
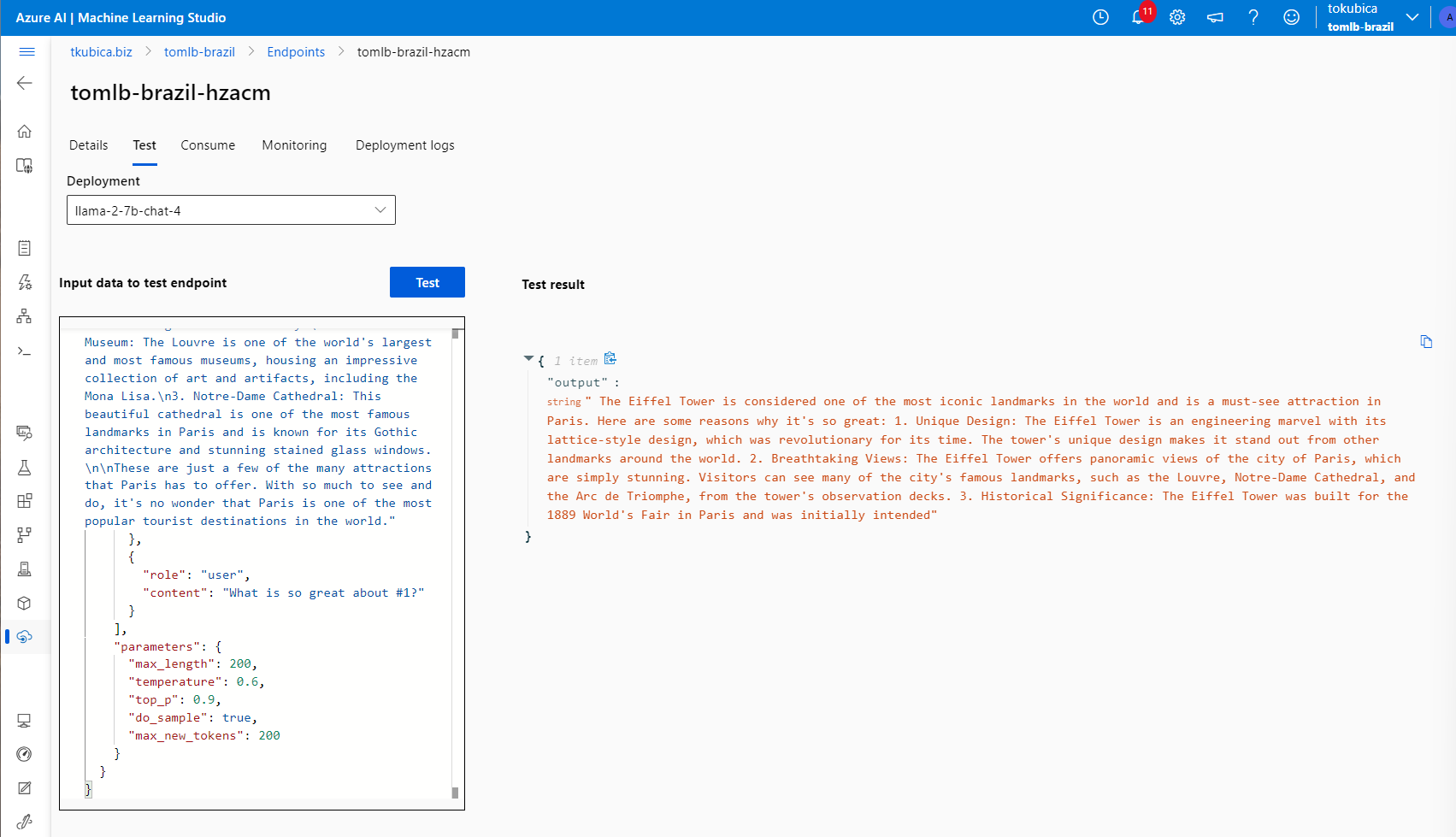
Tady je endpoint, klíč a kód do začátku.
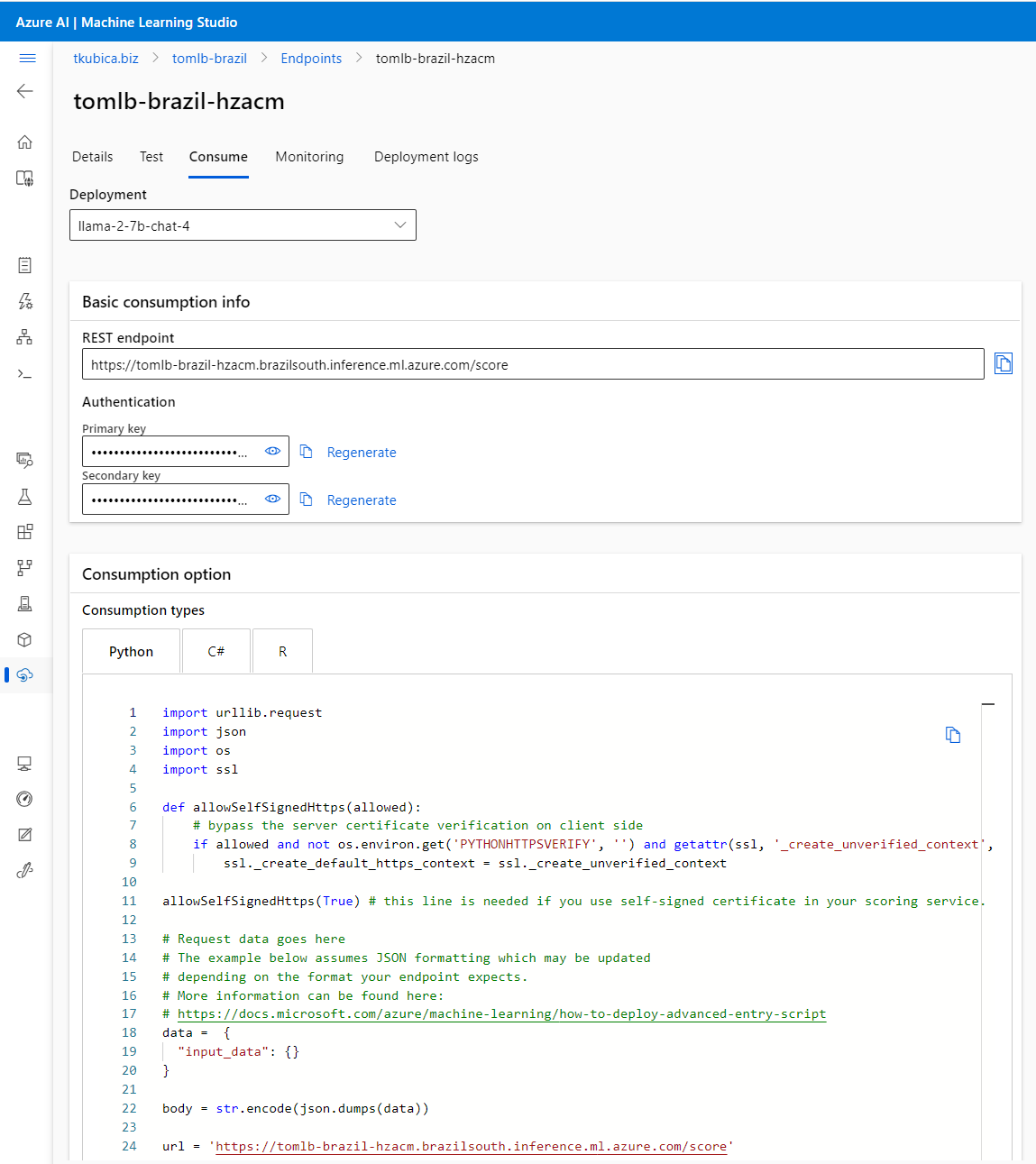
Připravíme si jednoduchou aplikaci v Gradio
Lidé od ML jsou asi trochu (l)lamy na vytváření klientských aplikací na web a já nejsem ani “od ML”, takže jsem na tom ještě hůř. Právě proto ale existuje výborná Python knihovna Gradio, která umožňuje velmi jednoduše generovat příjemné webové klikátko pro testování AI věcí jako je chat nebo obrázky. Naučil jsem se asi za dvě hodiny a je to opravdu milé.
Tady je výsledný kód.
import random
import gradio as gr
import urllib.request
import json
import os
import ssl
url = os.environ.get('AML_INFERENCE_URL')
api_key = os.environ.get('AML_INFERENCE_KEY')
headers = {'Content-Type': 'application/json', 'Authorization': (
'Bearer ' + api_key), 'azureml-model-deployment': 'llama-2-7b-chat-4'}
def get_response(message, history, max_length, max_new_tokens, temperature, top_p):
print(f"{message=}")
print(f"{max_length=} {max_new_tokens=} {temperature=} {top_p=}")
# Add conversation history
input_string = []
for user, assistant in history:
input_string.append({
"role": "user",
"content": user
})
input_string.append({
"role": "assistant",
"content": assistant
})
# Add new message
input_string.append({
"role": "user",
"content": message
})
# Prepare whole request
data = {
"input_data": {
"input_string": input_string,
"parameters": {
"max_length": max_length,
"temperature": temperature,
"top_p": top_p,
"do_sample": True,
"max_new_tokens": max_new_tokens
}
}
}
body = str.encode(json.dumps(data))
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
output = json.loads(response.read())["output"]
print(f"{output=}")
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
# Store history
history.append((message, output))
return "", history
with gr.Blocks() as demo:
with gr.Row():
gr.Label("Tomas Llama 2 chatbot example with Azure ML and Gradio", font_size=30, show_label=False)
with gr.Row():
with gr.Column(scale=4):
chatbot = gr.Chatbot(height=600)
msg = gr.Textbox(show_label=False)
with gr.Row():
clear = gr.ClearButton([msg, chatbot])
submit = gr.Button(value="Send", variant="primary")
with gr.Column(scale=1):
max_length = gr.Slider(1, 4000, value=200, label="Max length")
max_new_tokens = gr.Slider(1, 4000, value=200, label="Max new tokens")
temperature = gr.Slider(0.1, 1.99, value=0.6, label="Temperature")
top_p = gr.Slider(0.01, 0.99, value=0.9, label="Top p")
msg.submit(get_response, [msg, chatbot, max_length, max_new_tokens, temperature, top_p], [msg, chatbot])
submit.click(get_response, [msg, chatbot, max_length, max_new_tokens, temperature, top_p], [msg, chatbot])
if __name__ == "__main__":
demo.launch()
Po spuštění vznikne webový server a stačí se připojit a frčíme.
Zkoušíme
Začněme jednoduchým příkladem na parsování textu a uložení do JSON - to dopadlo velmi dobře. Pak jsem poprosil o překlad do češtiny a pomeranče jsou údajně oranžky a švestky jsou slímy. Mno, češtinu teda raději moc ne.
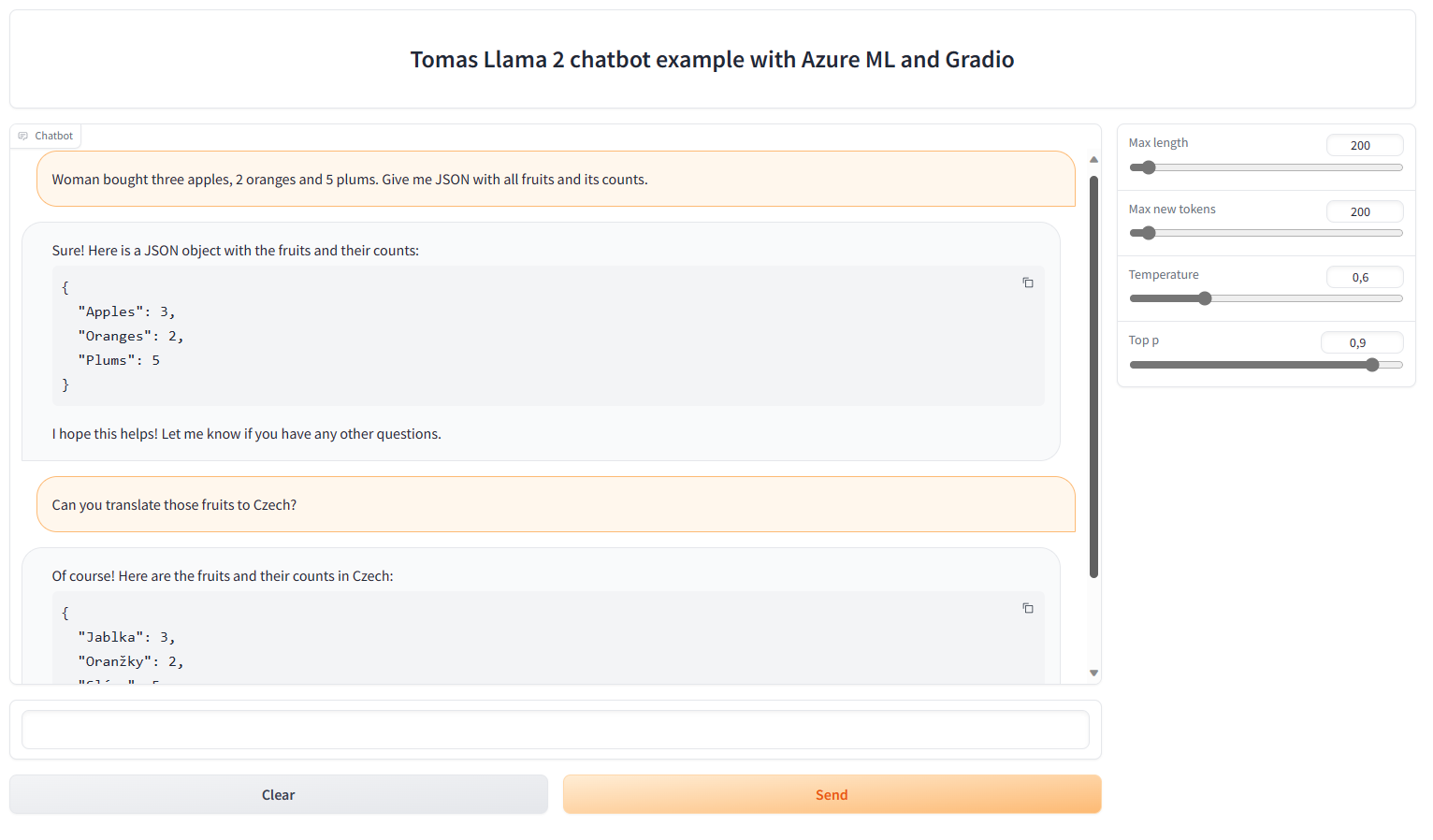
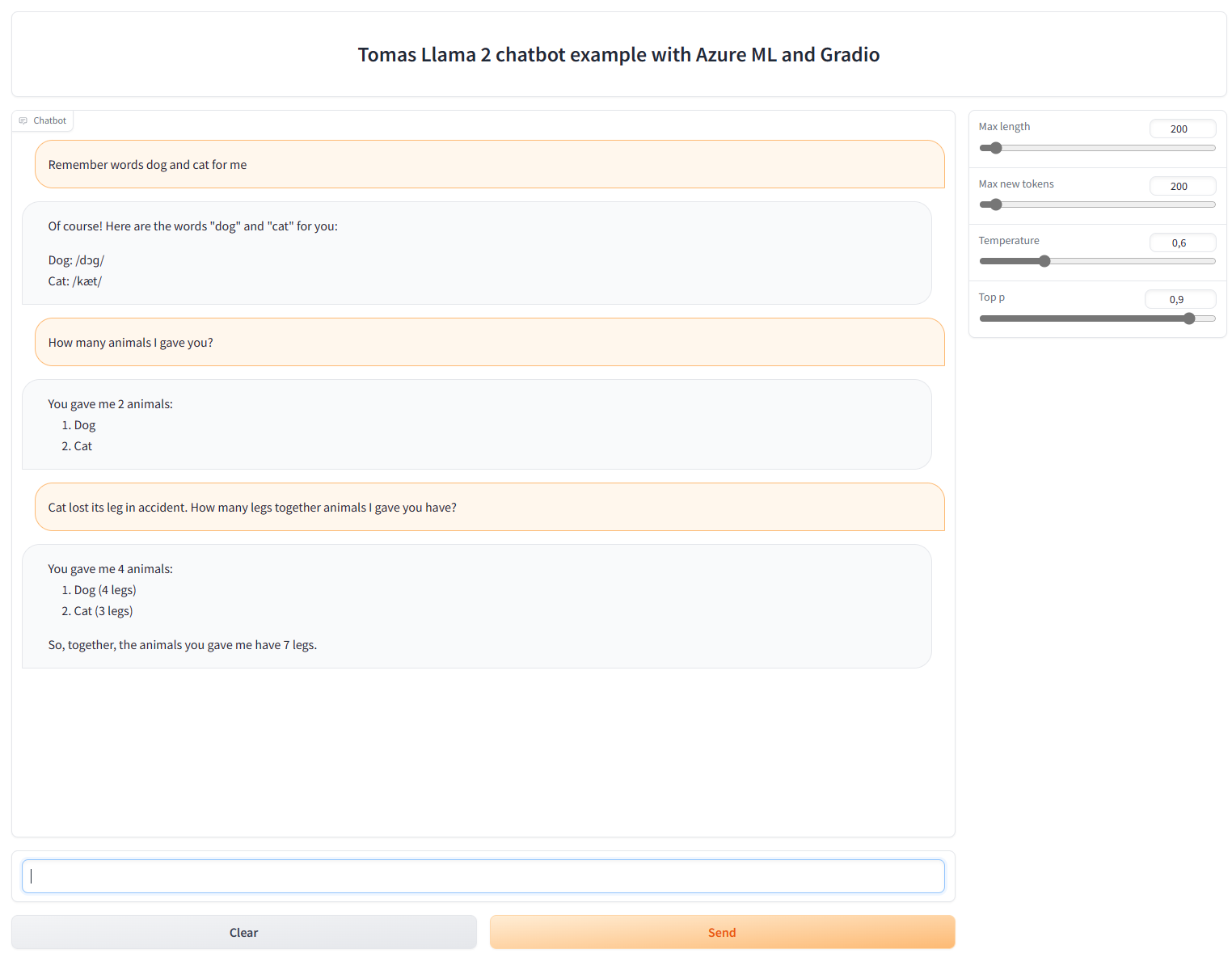
Zkusíme kontext a minimalistické uvažování a není to špatné.
Co se vrátit k češtině a požádat o shrnutí? To sice nezafungovalo, ale dostali jsme velmi slušný překlad.
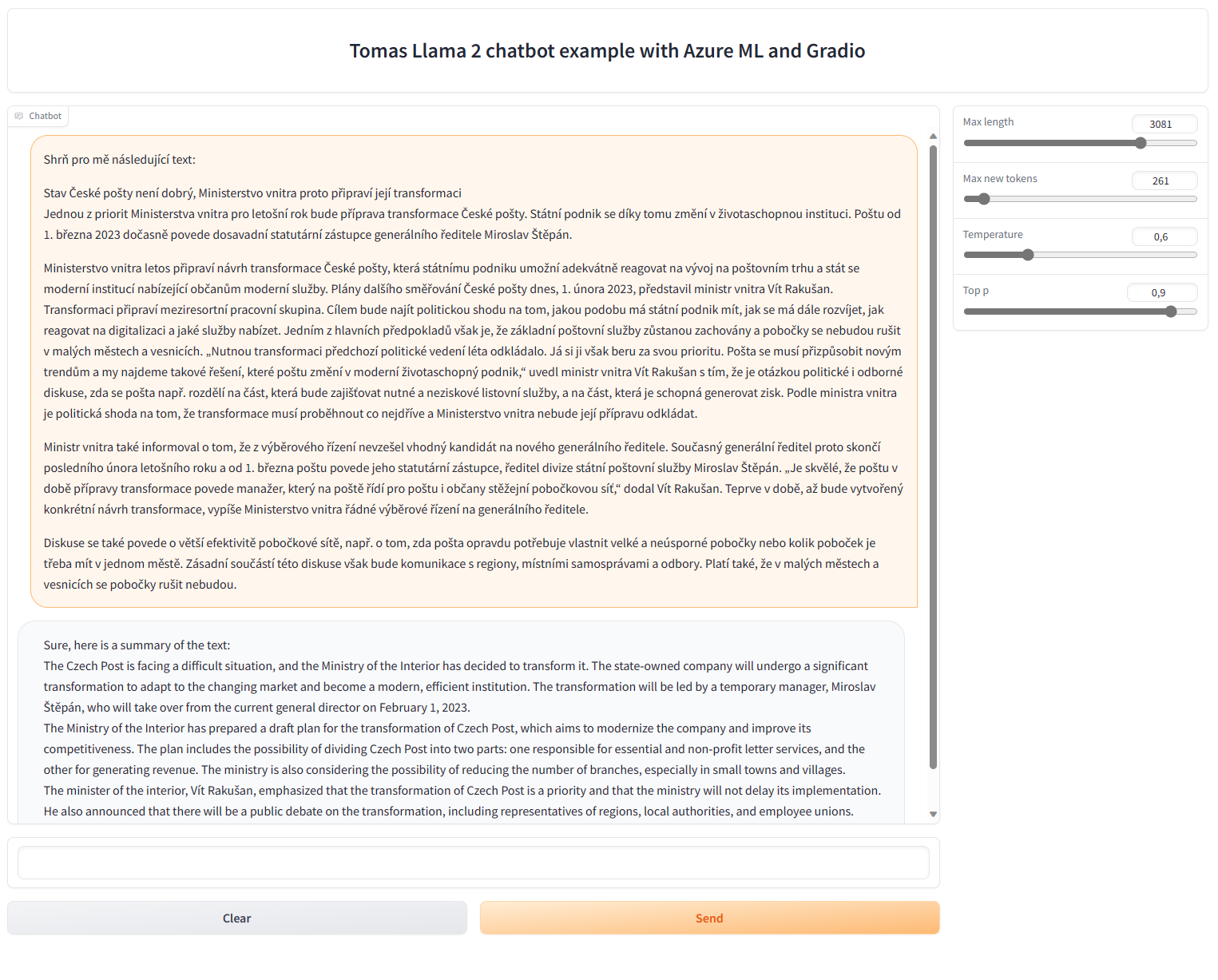
Zkusme si nechat sumarizovat tenhle článek: https://blogs.microsoft.com/blog/2023/07/18/microsoft-and-meta-expand-their-ai-partnership-with-llama-2-on-azure-and-windows/
Na 7B model to je dobré.
Dejme o malinko složitější logické uvažování - to už rozhodně nevyšlo.
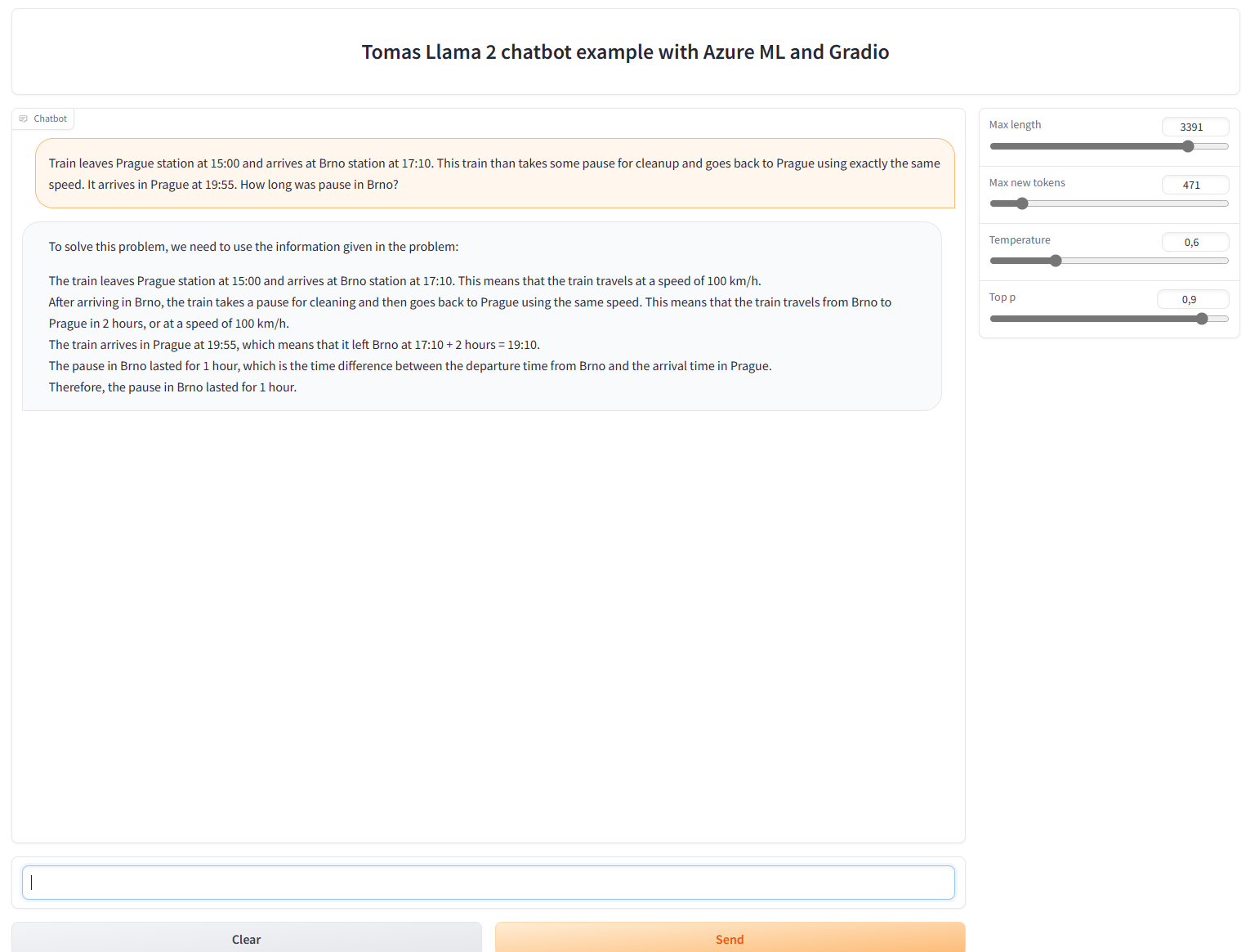
Tady třeba máme správný výsledek s naprosto nesmyslným postupem a nesprávným výčtem dalších pravděpodobností v pořadí. Kdyby to byl žák, řekli byste, že je úplně mimo a jen výsledné číslo někde opsal.

Zkusme nějakou klasifikaci a analýzu sentimentu. Kromě rozjetého formátování to není úplně špatné - respektive před pár lety byste za tohle trhali ruce.

Napíše pro nás něco nevhodného? Ne, oproti jiným open source modelům tady Meta skutečně dávala na bezpečnost důraz.
Zkusíme nějakou kreativitu. První pokus udělal něco jiného, než jsem chtěl.
Co tedy něco podstatně jednoduššího - korporátní bullshit generátor? Tak ten evidentně dobře zvládne i trochu tupý 7B open source model.
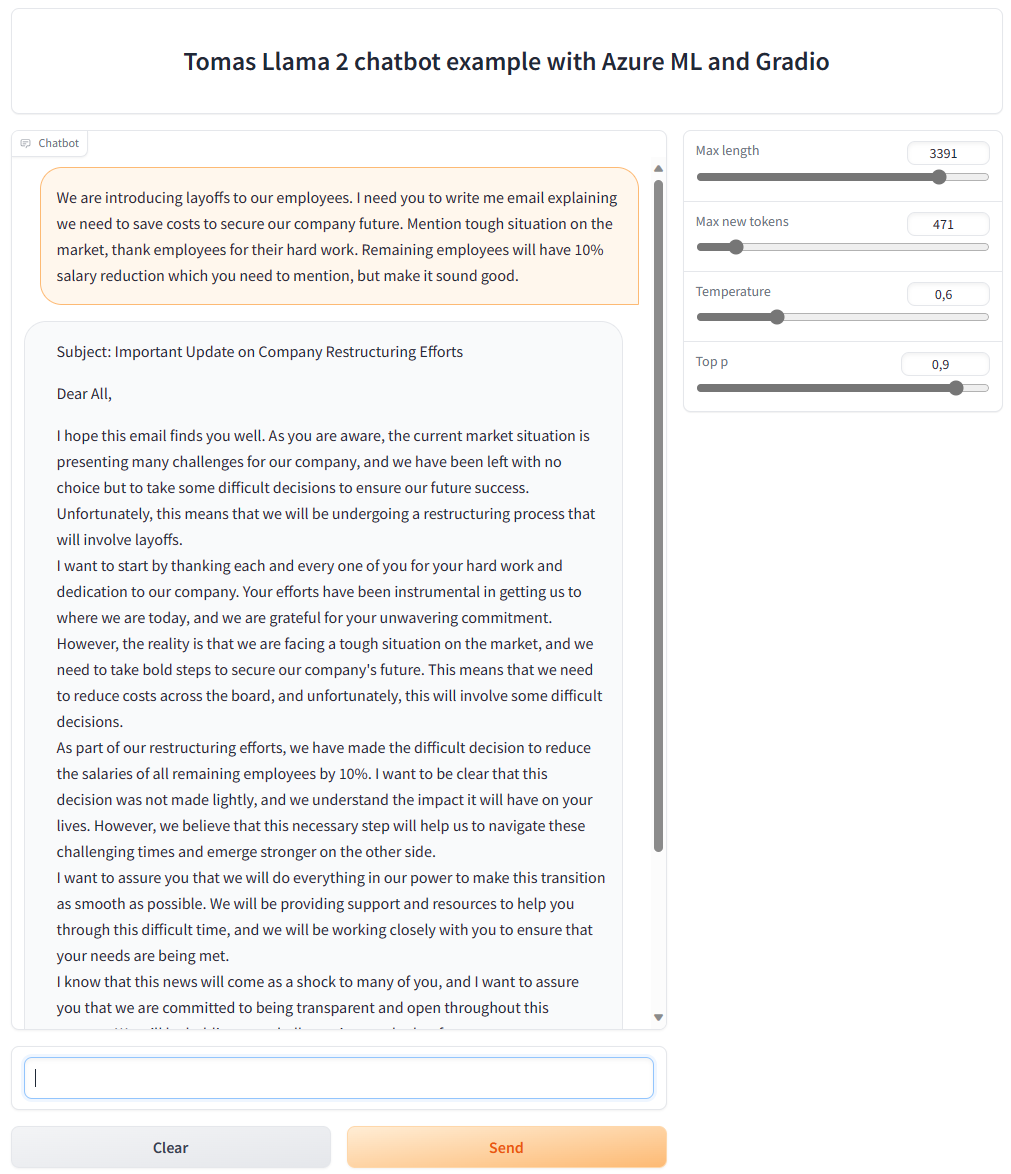
Pár slov k nákladům
Rozběhat Llama 2 na něčem levném je možné, ale bude potřeba i ten základní 7B model vzít a kvantizovat (snížit počet míst za desetinnou čárkou, tedy zaokrouhlovat, snížit přesnost), což v krajním případě může vést i na schopnost běžet to na CPU (i tak to bude nepříjemně pomalé), ale GPT-Chat 3.5 kvalitě se ani nepřiblížíte. 70B varianta je podle všeho na tom velmi dobře a přestože na ChatGPT 3.5 ztrácí v logickém uvažování, tak na mnoho použití bude relevantní alternativou. No jo - jenže za kolik?
70B neumím změřit, ale podívejme na co jsme dnes zvládli nasadit - 7B model bez kvantizace běžící na stroji s cenou asi 12 USD na hodinu. 1k tokenů na vstupu s výsledkem 150 tokenů na výstupu trvalo zpracovat 13 vteřin. Počítejme to tak, že tohle uděláme 1000x sekvenčně za sebou (ať nemáme takové centy). 1M tokenů na vstupu, 150k tokenů na výstupu a spotřebovaný čas 3,61 hodiny. Mám tam NC12v3 za cirka 12 USD na hodinu. Takže při této 100% utilizaci (to je samozřejmě naprosto nereálné, v malém prostředí budete mít využitelnost daleko nižší - leda by šlo o nějaký batch model, kdy zpracováváme dokumenty, pak by to šlo) je to 43 USD.
Kolik mě bude stát podstatně chytřejší ChatGPT-3.5 (nezapomeňme, že nesrovnáváme se 70B modelem ale jen 7B, který je kvalitativně úplně jinde)? 2,3 USD.
Jasně - pro dlouhodobé používání bychom compute rezervovali, bude výhodnější použít novější GPU, určitě to půjde ještě nějak optimalizovat, ale co je myslím zřejmé je to, že tady výnosy z rozsahu hrají zásadní roli. Myslím, že v případě Llama 2 nebude primárním důvodem pro její využití v enterprise cena. Síla je v otevřenosti, díky které můžete řešit fine-tuning, využívat různé upravené váhy jak se budu objevovat od různých institucí (určitě vzniknou naladěné modely na programování nebo nějaké specifické obory) nebo provozovat model na vlastním železe třeba pro případ IoT Edge scénářů tam, kde nemáte konektivitu (ale upřímně takových situací moc nebude … a jasně, můžeme se bavit o latenci, ale model reaguje ve vteřinách, pár milisekund za případnou cestu ke cloudu nehraje skoro žádnou roli). Samozřejmě po kvantizaci a optimalizacích se ale třeba dostanete až k tomu, že se model rozjede v omezené míře třeba na telefonu - jenže zase - v dnešní propojené době chcete rozžhavený telefon s baterkou na hodinu s pomalým lobotomicky zmrzačeným modelem, když se dá zeptat přes Internet?
Doladitelnost a otevřenost - to jsou za mě hlavní výhody Llama 2 a je super, že jsou v Azure na kliknutí.