Minule jsme využili natrénovaný model k tomu, abychom levně získali dobré předpovídání nových dat - dvou plyšáků. To se povedlo, ale musíme se zamyslet nad tímto:
- Důvod proč tak dobře a levně fungovalo je, že naše nové kategorie objektů nejsou nějak moc jiné. Je možné, že u zcela jinak vypadajících dat (letecké či rentgenové snímky, buňky pod mikroskopem) nebo nějaké masivní specializace (atlas 500 druhů brouků) to tak skvěle nedopadne.
- Co když budu později mít další data a v nich třeba novou kategorii (nového plyšáka)? Když použiji to co minule, tak budu mít dva nezávislé modely. Mám tedy přenést, ale trénovat nad všemi daty? Jaké to má dopady na ekonomiku?
Dnes tedy zkusíme:
- Natrénujeme si vlastní model od nuly -> o kolik víc výpočetního výkonu budeme potřebovat?
- Objevilo se nám prasátko a nová data -> provedeme transfer learning našeho custom modelu na prasátka (defacto tak jak minule), zafunguje?
- Uděláme jednotný model tří plyšáku -> převedeme váhy z custom modelu, ale protáhneme všechna data. Dostaneme jednotný model? Bude dobrý? O kolik víc výkonu tím spotřebujeme?
- Na závěr si uděláme opět vlastní model z nuly nad všemi daty tentokrát i s prasátkem -> bude lepší, než transfer learning ale nad všemi daty a o kolik spotřebuje víc zdrojů?
Jako obvykle data najdete na mém GitHubu a dnes se budeme pohybovat v tomhle notebooku
Vlastní model
Pojďme vzít naše data, kterých je ale strašně málo, a prohnat je stejnou topologií, kterou YOLO používá u natrénovaného modelu velikosti nano, nicméně od začátku - bez předtrénovaných vah.
# Load empty model
model = YOLO('yolov8n.yaml')
# Train the model
train = model.train(data='./datasets/2plysaci.yaml', epochs=2000, patience=0, imgsz=1024)
# 2000 epochs completed in 0.507 hours.
Tím, že model jede od začátku a máme velmi malé množství dat, bylo potřeba udělat poměrně dost epoch. Střelil jsem jich 2000 a A100 v Azure je stihla za asi 30 minut. Když se podíváme do grafů, tak loss funkce zvolna klesají, vybavovací schopnost i přesnost na validační sadě jde nahoru, vypadá to rozumně.
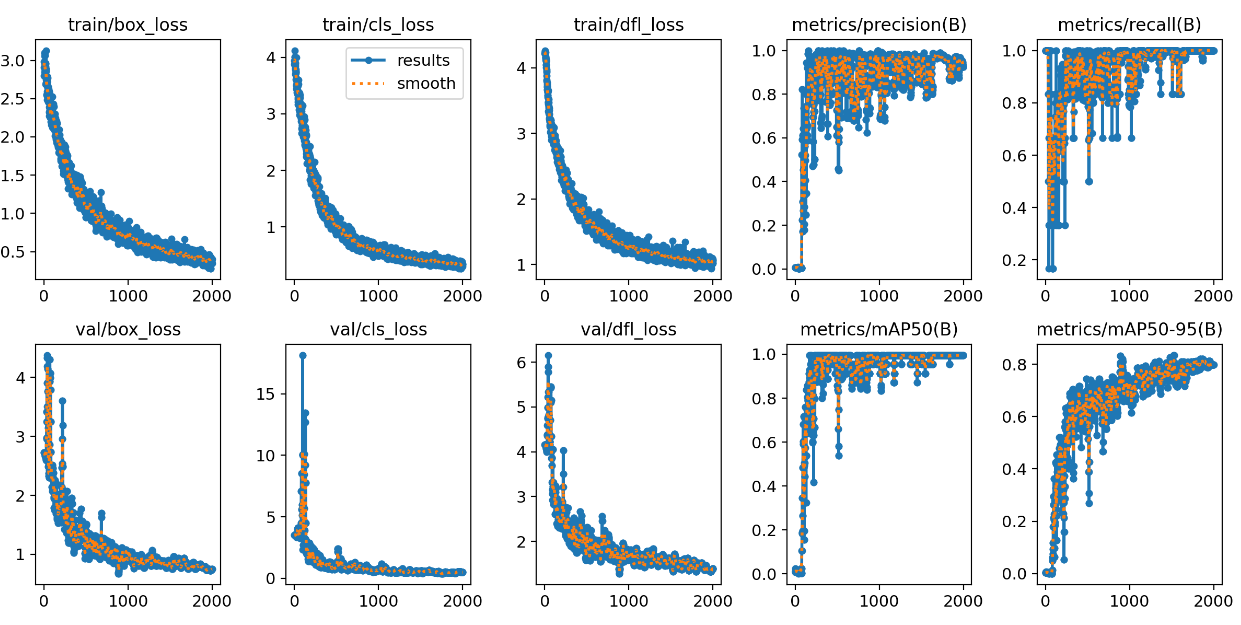
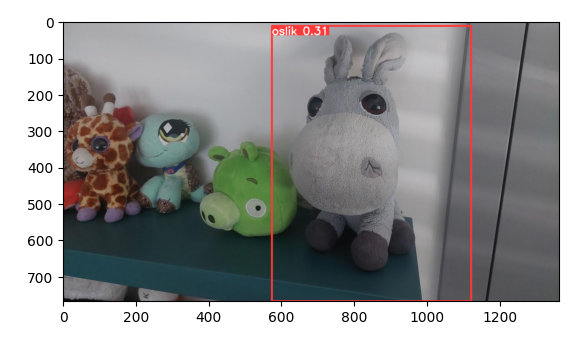
Na testovací fotce (pochází z původního období, ale není použita ani v trénovací ani validační sadě) jsou výsledky dobré.

V dnešním díle do toho přimícháme fotku z nové sady, kde je taky oslík, ale o 5 let starší. Model ho nějak poznal, byť s žádnou jistotou - je to hlavně chyba naší extrémně malé trénovací sady. Na kvalitní model vytvořený z nuly potřebujete tisíce fotek (ideálně miliony).
Výsledek:
- Model se i přes málo dat něco naučil, koncept funguje, ale samozřejmě dat je potřeba mnohem víc.
- 30 minut na jedné A100 v Azure vyjde asi na 2 USD když započítám, že to nějakou dobu startuje apod.
- Pokud budu mít miliony obrázků a nepoužijeme nejmenší topologii nano, ale třeba large, čas dramaticky naroste a bude se pravděpodobně pohybovat ve dnech. Pokud použijeme nižší stovky hodin, zaplatíme vyšší stovky dolarů. To není nic hrozného, pokud budete celý model dělat jednou za měsíc nebo párkrát do roka.
- Transfer learning v minulém díle dosáhl asi i lepšího výsledku a podstatně levněji. Je to hlavně tím, že naše úloha není principiálně jiná - to na čem se model učil lze docela dobře přenést do problematiky plyšáků.
Transfer learning vlastního modelu na prasátka
V minulém díle jsme viděli, že profesionální na pořádných datech trénovaný model nám umožnil za pár minut trénování ve 100 epochách dosáhnout asi i lepších výsledků, než náš vlastní model. My jsme si právě pracně udělali vlastní model z nuly na dva plyšáky, ale teď máme třetího. Dokážeme přenést váhy z dvouplyšákového modelu na prasátka a rychle dostat nějaký rozumný výsledek?
# Load model_2plysaci
model = YOLO('2plysaci_custom_n.pt')
# Train the model
train = model.train(data='./datasets/prasatko.yaml', epochs=100, patience=0, imgsz=1024)
# 100 epochs completed in 0.025 hours.
Pohled do grafů ukazuje, že nám loss funkce velmi rychle padají kam potřebujeme a mAP50-95 rychle vyroste. Evidentně tedy náš předtrénovaný model nemá zas tak moc práce se přizpůsobit na prasátka.
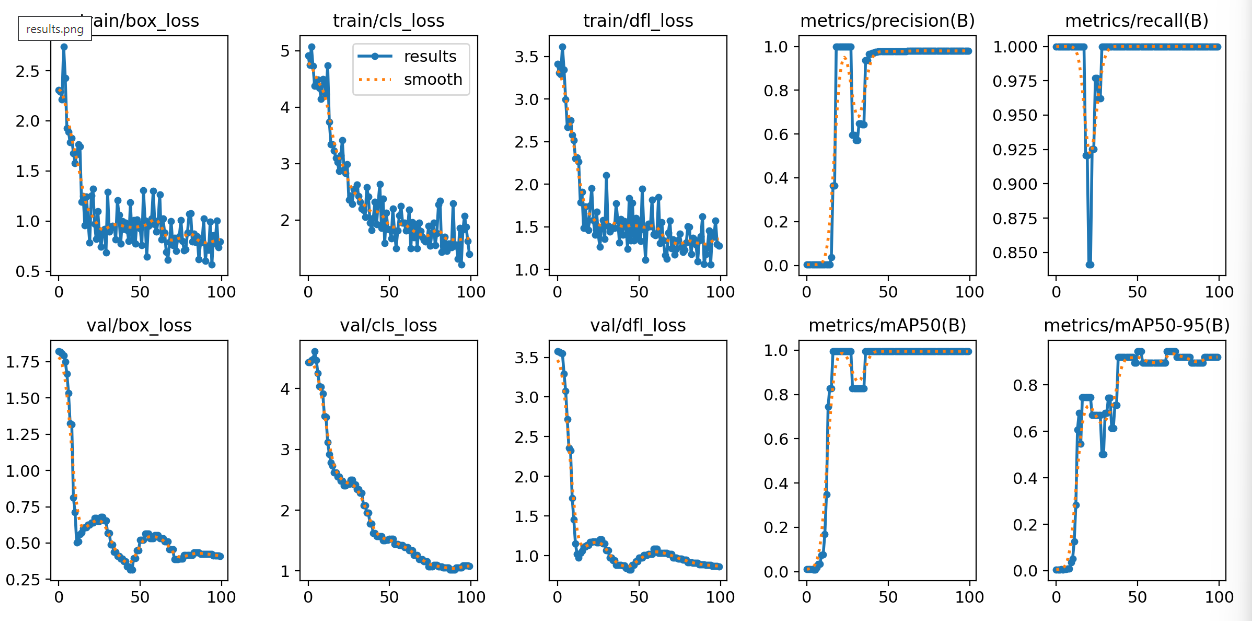
V první testovací fotce je výsledek velmi pozitivní.

Druhá už není nic moc, prasátka tam vidí dvě, ale nějak úplně mimo to taky není. Nicméně samozřejmě oslík nic - to se čekalo.

Výsledek:
- Ano, náš vlastní model toho ví o plyšácích obecně docela dost a lze jeho závěry přenést do problematiky prasátek.
- Byli jsme schopni model na prasátka natrénovat velmi rychle (= levně), 90 vteřin.
- Výsledný model ale neumí oslíky. Klasifikace původního modelu je pryč. To možná nevadí (pokud třeba oslíky už nevyrábíme - linka se teď soustředí na prasátka), ale možná potřebujeme oboje a pak musíme aplikačně využívat dvou modelů.
Transfer learning, ale s použitím všech dat
Jak se dostat k modelu, který bude umět všechny tři plyšáky, ale neutratit za kompletní trénování z nuly? Můžeme převést váhy původního modelu a trénovat ho dál nad všemi daty, nejen nad novými. V našem případě to výpočetně nebude velký rozdíl (k cirka 10 novým fotkám přidáme 25 původních), ale pokud bych chtěl model trénovaný na COCO sadě tisíců fotek rozšířit o svoje plyšáky, tak se místo v desítkách obrázků rázem budu pohybovat v desetitisících a to sežere víc výkonu. Nicméně - i tak by mělo platit, že model má skvělé startovací váhy a učí se řádově rychleji.
# Load model_2plysaci
model = YOLO('2plysaci_custom_n.pt')
# Train the model
train = model.train(data='./datasets/3plysaci.yaml', epochs=100, patience=0, imgsz=1024)
# 100 epochs completed in 0.033 hours.
Grafy vypadají dobře - loss se snižuje, přesnost a vybavování jde nahoru.
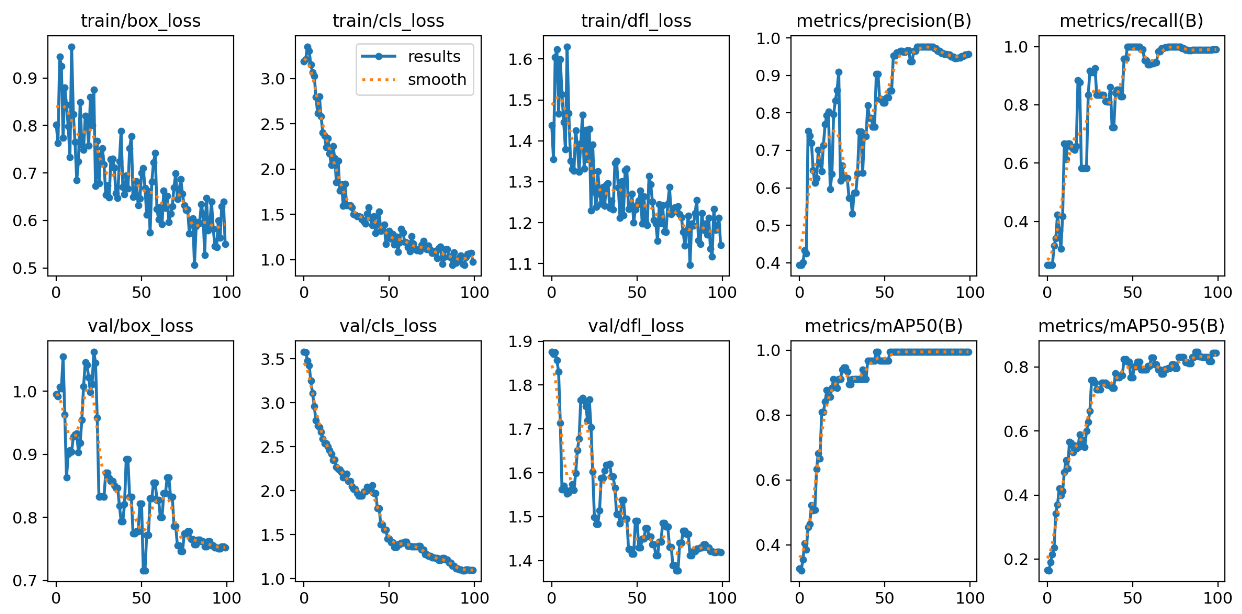
Tenhle model velmi pěkně pokrývá oslíky i prasátka dohromady.


Výsledek:
- Spotřebovali jsme víc zdrojů (119 vteřin), ale v našem případě ne o moc. Rozhodně je to daleko úspornější, než přetrénovat celý model od nuly.
- Kvalita modelu není pro všechny plyšáky úplně vyrovnaná. Máme tady potenciální problém v tom, že původní model se vydá nějakým směrem, ale nová data jiným a protože jsme přenesli váhy a dáváme tomu málo zdrojů, možná nedokážeme provést korekci. Jinak řečeno pokud budeme takhle pokračovat každý den pokaždé s přidáním dalších dat, začne nám klesat kvalita a to zejména pokud jako v našem případě jsou nová data poměrně velká oproti původním.
Vlastní model 3-plyšákový
Pojďme to teď srovnat se situací, kdy vezmeme všechna data a uděláme to co na začátku - natrénujeme model z nuly.
# Load empty model
model = YOLO('yolov8n.yaml')
# Train the model
train = model.train(data='./datasets/3plysaci.yaml', epochs=2000, patience=0, imgsz=1024)
# 2000 epochs completed in 0.556 hours.
Grafy jsou velmi podobné a jdou celkem správným směrem (byť nám v konci už model nedělá zlepšení v mAP50-95).
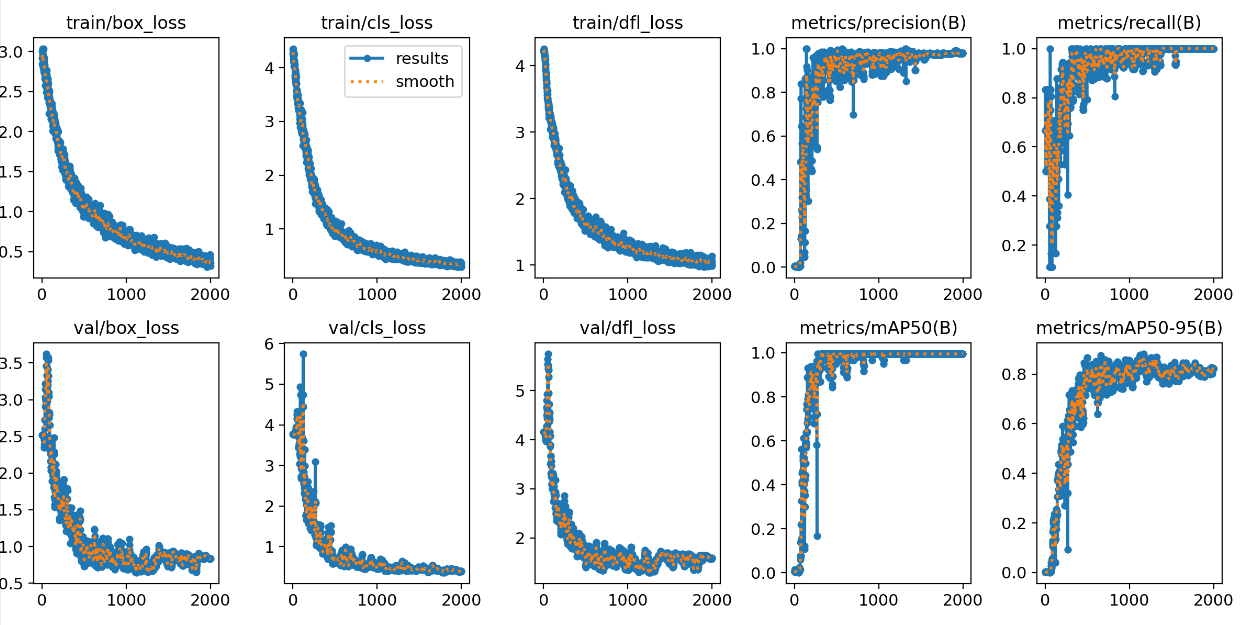
Jak to dopadne s testovací fotkou?

A co tady?

Výsledek:
- Tenhle model je hezky vyrovnaný co se týče kvality všech tří plyšáků. Je to tím, že se jim může věnovat od začátku.
- Protože máme o trochu víc dat, tak jsme museli přidat 3 minuty navíc v porovnání s trénováním z nuly na začátku článku (celkem tedy 33 minut) - pokud budeme řešit desetitisíce fotek a použijeme model large, tak jsme zase u několika dnů práce.
Já si z toho všeho dělám tyto závěry:
- Natrénovat plně vlastní model lze, ale dává to smysl hlavně tam, kde jsou data nějak specifická.
- Vlastní model z nuly stojí peníze.
- Asi bude potřeba víc ladění hyperparametrů, pokud chcete model opravdu dobrý - to jsme dnes vůbec nedělali.
- Transfer learning umožní velmi levně získat svůj model pro svoje data.
- Pokud potřebuji univerzální model co umí původní i nová data, můžu přenést váhy, ale trénovat nad celou sadou. Bude to dražší a náročnější, ale pořád o dost levější, než začít z nuly.
- Stále dokola aplikovaný transfer learning bude v průběhu času akumulovat chyby (pokud váhy přenáším z generace na generaci) nebo jeho váhy už nebudou tak pomáhat (původní model jen daty, které už dnes nejsou reprezentativní - produkty se například výrazně změnili). Pro vlastní speciální data tedy asi bude optimální kombinace, kdy jednou za čas (třeba ročně) provedeme náročné trénování a ladění vlastního modelu a v průběhu roku pak používáme transfer learning tak, jak se objevují nová data.
Zkuste si to - stačí vzít moje notebooky a napojit je na compute instance v Azure Machine Learning a frčíte. Příště zkusím prozkoumat jak z modelu udělat nějaké API a zamyslet se nad tím, kolik mě jeho provoz bude stát a jestli nebude lepší si vzít hotovou kognitivní službu.