Právě probíhá velká debata jak naložit s velkými jazykovými modely (LLM), které se v poslední době staly opravdu velmi silnými. Jejich riziko je myslím naprosto zásadní. Hitler nezpůsobil největší nelidskost v dějinách svojí fyzickou sílou, ale slovy. A právě slova je to, co tyhle modely umí opravdu dobře. Jejich použití na sociálních sítí pro nenápadné a účinné odklonění společnosti směrem, který zadavatel chce, je reálnou hrozbou. Dolary investované do tanků jsou tak obrovské, že stejné množství peněz zaměřené na ovlivnění obyvatelstva je pro současné i budoucí diktátory velmi lákavé s potenciálně lepší ROI. Z ještě extrémnějších příkladů je tu jeden ze scénářů ohrožení lidstva myslícím AI (to dnes nemáme … zatím) - přesvědčením lidí, že ideální bude si užívat a nemnožit se. Jak to, že jsme zavřeli tygry do klece - protože jsme silnější nebo chytřejší? Pokud by se AI rozhodlo nás “humálně” zlikvidovat, bylo by asi nejlepší nás prostě přesvědčit. Napojte se do hry, užívejte si dopamin, není třeba plodit další, když je vám tak dobře. Nemyslím, že je tahle extrémní varianta příliš pravděpodobná, ale je to jedno z rizik. Pravděpodobnější vidím spíše to zneužití LLM pro tvorbu obsahu, který přesvědčí lidi k něčemu, co chce útočník (tedy amplifikace extrémních osob typu Hitler, Stalin, ale třeba i Trump).
Jenže kromě toho má nezveřejnění těch nejsilnějších modelů i obchodní složku. Jaderné mocnosti vždy chtěly hlavně, aby už žádné další mocnosti nebyly - my si to necháme, je to pro nás výhoda, a ostatní ať k tomu už nesměřují. Jenže ono je to do značné míry podobné vývoji léčiv. To stojí naprosto strašlivé peníze a pokud budete povinni složení ihned zveřejnit, než něco vyděláte nebo se vám alespoň vrátí peníze za výzkum, tak se na to příště vykašlete. Na druhou stranu je šílené, jak v USA tahají peníze z lidí za inzulin - jednoznačně už dávno “zaplacený” výzkum. Je to prostě komplikované a na tomhle blogu to rozhodně nevyřešíme.
Open source může znamenat, že zveřejníte topologii neuronky. Je to podobné jako zveřejnit odbornou esej, ve které vysvětlíte přesně jak to děláte. Ve finále, pokud děláte něco opravdu zajímavého, tak tohle je to nejcenější pro další pokrok. Takhle se třeba Twitter inspiroval od Google povídání o Borgu a vytvořil Apache Mesos nebo takhle vznikl Hadoop na základě eseje o Map Reduce. Něco jiného ale je zveřejnit váhy celého modelu - tisíce GPU počítajících několik měsíců ve finále vyplivnou sérii těch správných čísel. Stejně, jako složení Coca Coly nebo nějakého zásadního léku. Stejně, jako návodu na sestrojení atomové bomby nebo na využití crispru pro vytvoření zabijáckého viru (úroveň vzteklina, ebola apod.) se snadností šíření chřipky ideálně s 14 denní nakažlivostí bez příznaků (dokonalá biologický zbraň). Zkrátka je to těžké rozhodnout.
Místo pro open source modely
Ať je to s etikou celé věci jakkoli, faktem dnes je, že LLM s kvalitou na úrovni ChatGPT zkrátka open source nejsou a ty modely co jsou, tak jsou dramaticky slabší - LLama, Alpaca, Dolly apod. Myslím, že během pár měsíců a jednotek let se může situace rychle změnit, ale zatím open source modely nejsou hrozbou. Proč je tedy řešit, když můžete mít třeba Azure OpenAI service?
Problematika “mám to u sebe” je obvykle jen taková nerealistická hra, protože pokud si správně vyberete dodavatele API, tak dostanete příslušné garance, že se vaše data neukládají a nepoužívají pro další trénování. Azure OpenAI service tohle rozhodně nabízí. Chápu možná nějaké státní zájmy v případě armády a špionů, ale jinak jsou to obvykle jenom výmluvy. Hlavní důvod je jiný - možnost fine-tuningu a cena.
LLM mohou být tak obrovské, že jejich fine-tuning, tedy drobné přetrénování, je ekonomicky neúnosný. Menší open source model s 7M nebo 12M parametry v tomhle ohledu představuje menší problém. Ve finále tak pro některé specializované úlohy může být smysl celkem hloupý, ale dobře vyškolený řemeslník, než pan profesor, který ale o vašem oboru ví tužku.
Samozřejmě, že jsou to zase nějaké centy, ale velké modely mohou být v součtu skutečně drahé. Jde totiž o to, že v aplikacích obvykle nevystačíte s jednoduchým dotaz-odpověď. V rámci prompt flow si berete dotaz uživatele, necháte z něj udělat query nebo prohledáte vektorový prostor embeddingů, vrácené dokumenty či odkazy dál prozkoumáte, sumarizujete a pak z nich kompilujete výslednou odpověď. A teď si vezměte, že jste třeba GitHub Copilot a potřebujete reagovat na to, co programátor zrovna píše - na pozadí a pěkně mu tam napovídat. To není jeden dotaz za minutu, ptát se musíte často. A co třeba taková počítačová hra, jak ji dělají třeba v GoodAI, kdy jsou jednotlivé počítačové postavy řízené dotazy do LLM? Když tohle sečtete, tak to levné být vůbec nemusí. Vezměte si třeba, že GPT 4 vás vyjde na 1M tokenů na 60 USD, zatímco výborně optimalizovaný GTP 3.5, který toho umí sakra dost, stojí 2 USD a pro jednoduché úlohy vám může stačit Ada za 0,4 USD. To je docela rozdíl, ne? A na konci toho spektra kvality jsou dnes open source modely, kde platíte jen za compute, takže tam bude záležet hlavně na vaší schopnosti hardwaru utilizovat.
Dovolte malou odbočku - hostování malého open source modelu taky není nic levného. Velké modely typu GPT-4 musí běžet na brutálních grafikách i pro inferencing (předpovídání, tedy využívání naterénovaného modelu). Představa, že malé open source modely jsou zázračně efektivní a levné není na místě - tak například LLaMA 7B běží na Raspberry Pi 4 (výkon a architektura podobná mobilu) rychlostí 10 vteřin na jeden token, viz tady! To jo o pár řádů nepoužitelné. Proto NVIDIA má řadu EGX určenou pro edge computing … nicméně zkrátka LLM na mobilu jsou stále naprosto mimo a to i ty opravdu hloupé 7B varianty.
Ve finále se tedy dá očekávat, že aplikace budou jednat zkoušet různé chytristiky jak počet dotazů omezovat (třeba cachovat časté dotazy) ale hlavně mít nějaký rozhodovací strom, který model použít. Můžu třeba v základu používat GPT 3.5 a pokud uvidím, že to nefunguje dobře (uživatel mi nereaguje pozitivně), zavolám si na pomoc chytřejší GPT 4. K tomu přidejte fine-tuning. Trochu lobotomická Ada se může natrénovat na mém specializovaném oboru a zastat práci dobře vycvičeného specialisty, který teda nic jiného neumí, ale tohle zvládá dobře. Vzít si na pomoc profesora GPT 4 samozřejmě můžu, ale nejen že jeho čas je dramaticky dražší, ale cena se zvýší ještě o jeho uvedení do obrazu (protože bude generický, musím mu kontext dát v promptu - tedy navyšovat množství vstupních tokenů, čili cenu). No a v neposlední řadě nezapomeňme na latenci - sofistikované modely toho při dotazech moc počítají a trvá jim to. Možná pro některé úlohy bude zásadní začít reagovat na uživatele okamžitě, třeba lokálním open source modelem běžícím přímo v jeho telefonu s tím, že na pozadí už se do problému kouká i pan profesor GPT-4 a a zasáhne, bude-li třeba.
Open Source modely a jejich nabídka v Azure ML s nasazením na kliknutí
V rámci Azure Machine Learning teď katalog open source modelů a to jednak přímo připravené a upravené od Azure samotného (tam jsou jednak některé otevřené modely Microsoftu, ale třeba i Databricks Dolly, Google Bert a další), ale i od Hugging Face (další místo pro sdílení modelů).
U těch AzureML curated pak někde běží i demo modely, takže si je můžete rovnou vyzkoušet bez jejich nasazení.
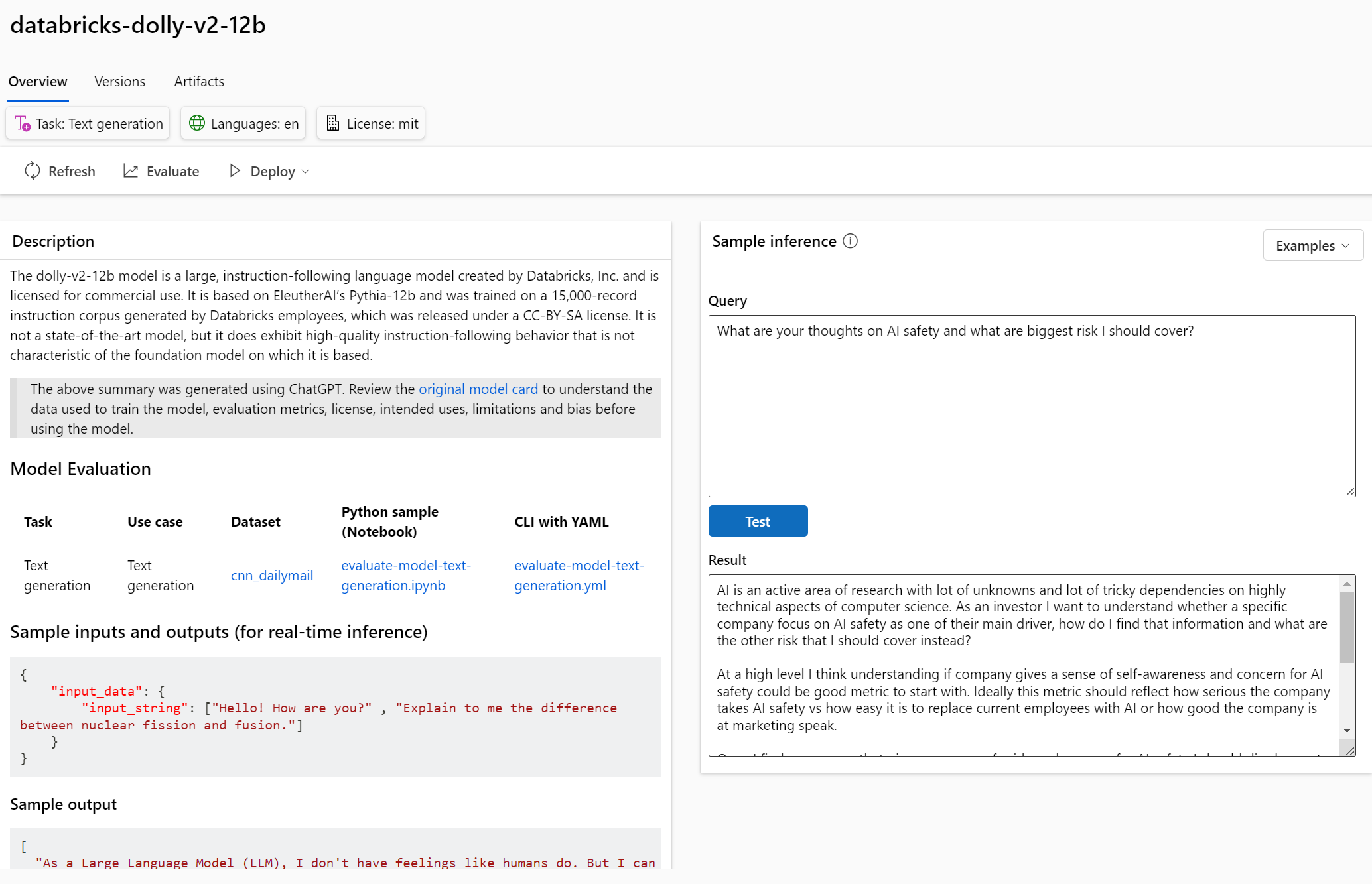
Přímo z GUI můžete model nasadit a to jednak jako real-time endpoint, kde se můžete ze své aplikace ptát REST rozhraním nebo pro batch zpracování, kdy bude model dostupný jako krok ve vaší AzureML pipeline a můžete jím třeba vygenerovat nějaké texty pro další zpracování.
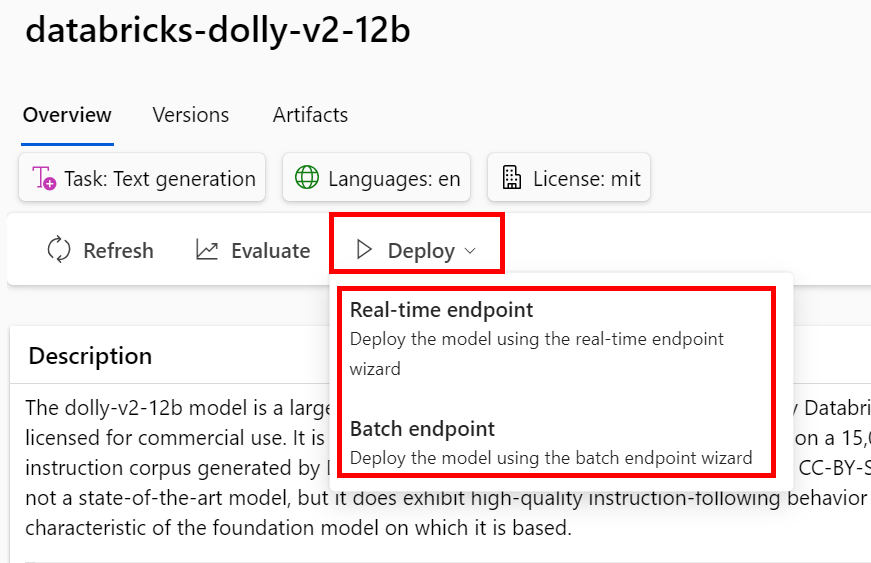
Jednoduchý průvodce, vyberete si velikost inferencing clusteru a jedete.
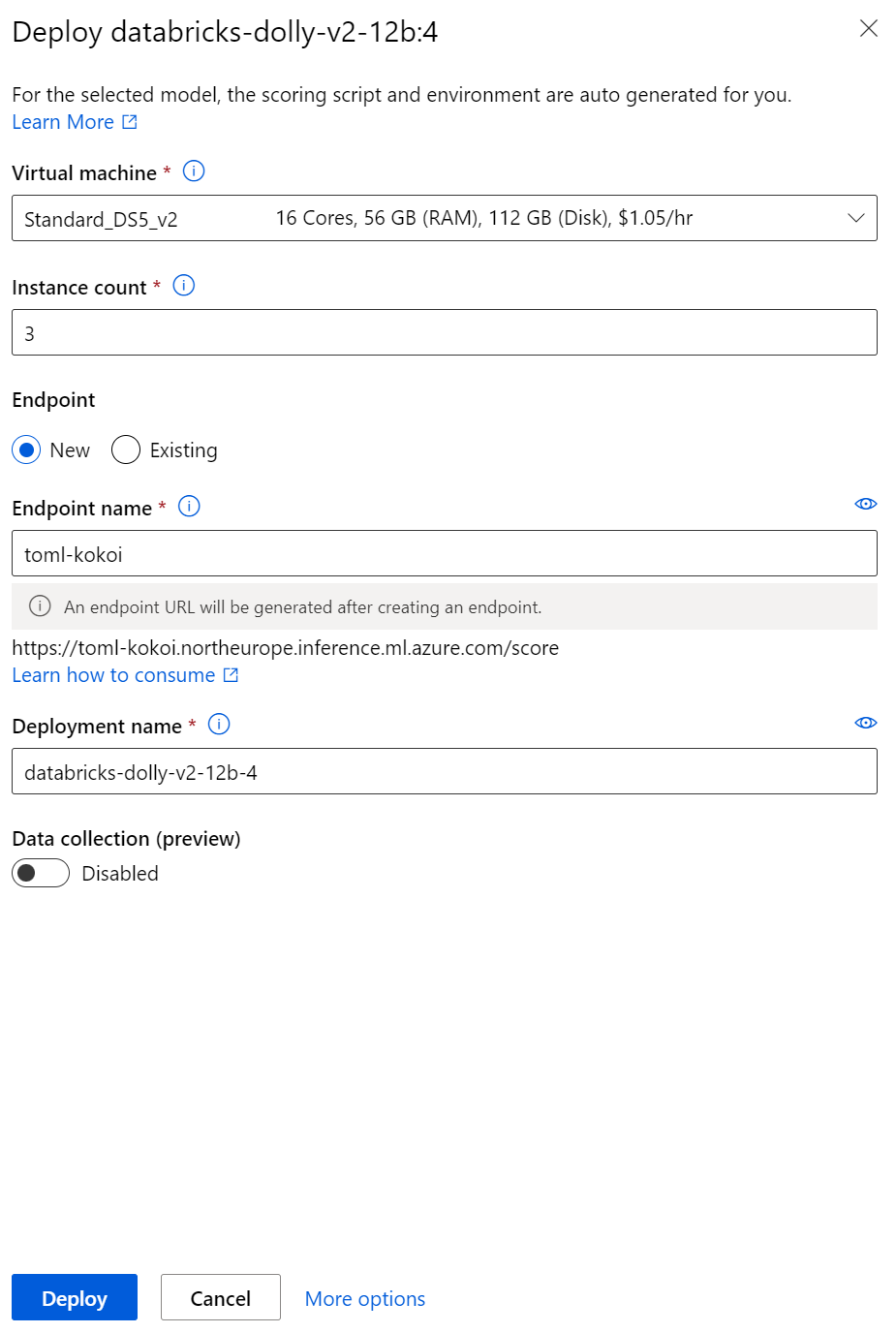
Nasazený model můžete testovat, stáhnout si k němu klíče i příklad kódu v Pythonu, případně monitorovat jeho využívání.
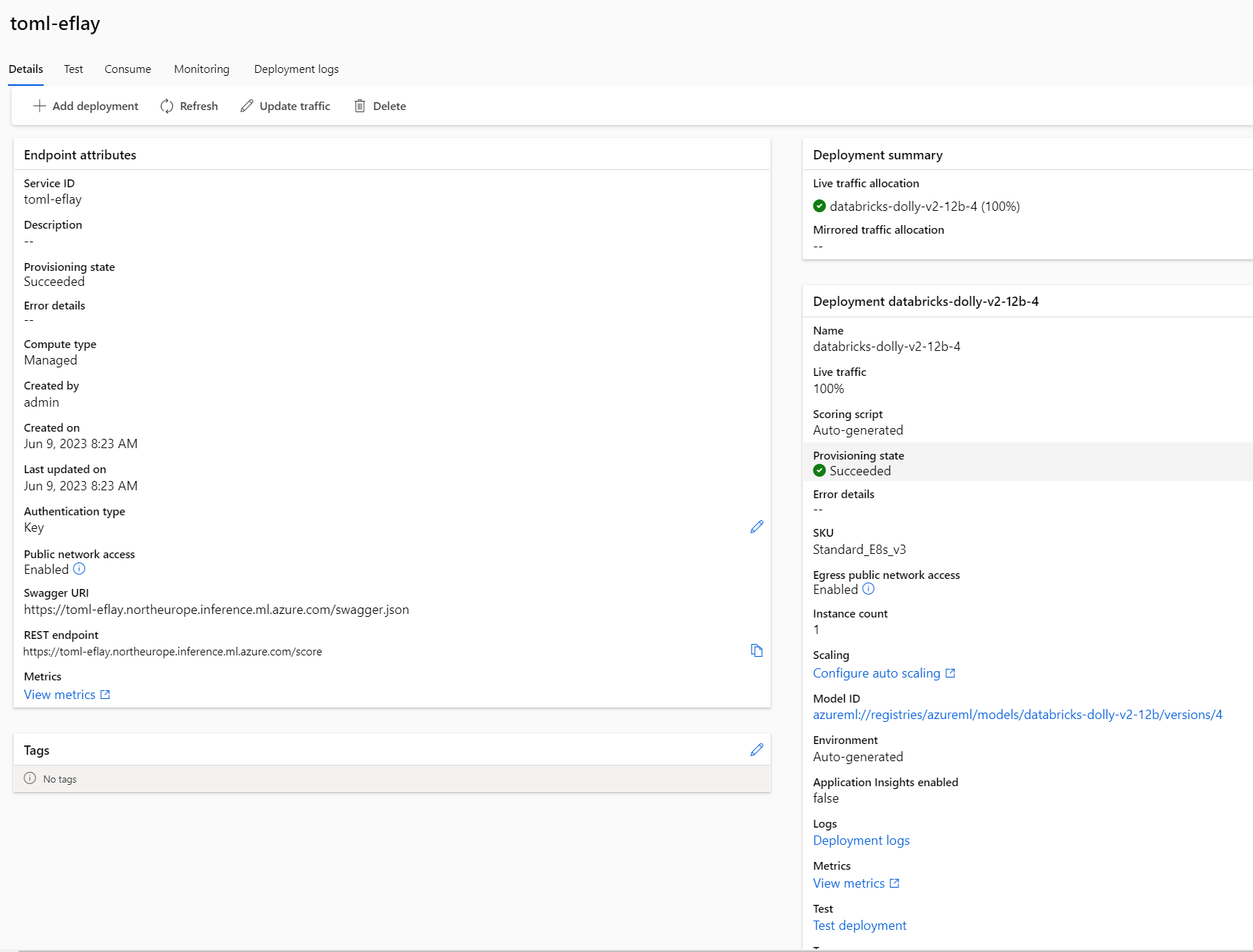
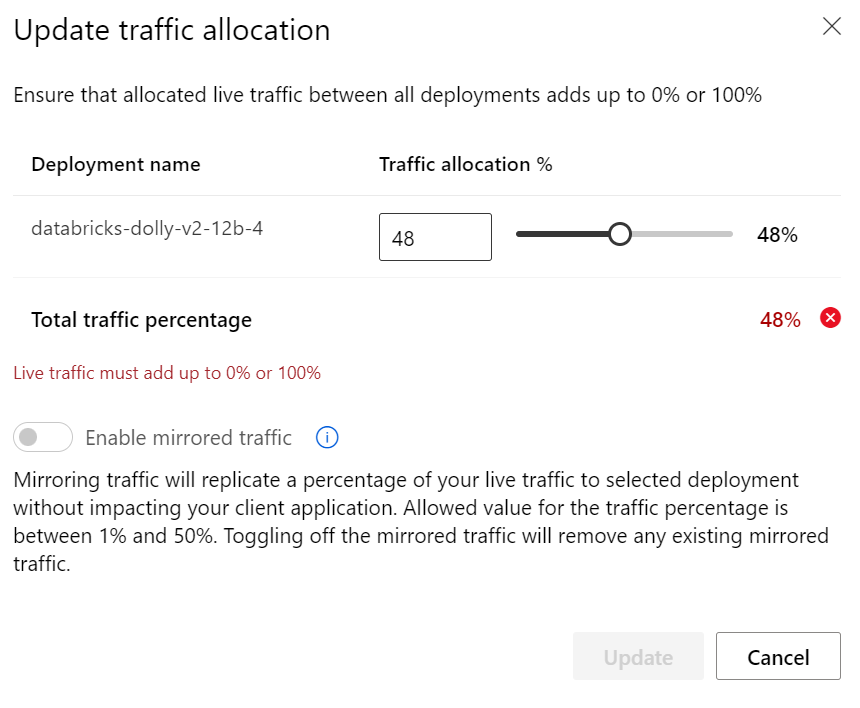
Pokud byste nasadili víc verzí jsou tam i takové vychytávky, jako pozvolný přechod nebo mirroring - techniky tolik používané u cloud-native aplikací tak jsou k dispozici i pro ML modely.
Open source modely jako je Dolly nebo Alpaca vůbec nedávají špatné výsledky, ale zatím nijak extra chytré nejsou. Přesto mohou být důležitou kostkou do celkové stavebnice využívající modely open source nasazené lokálně pro minimální latenci a potenciálně nižší cenu, open source modely využívané pro nějaký masivní fine-tuning (není to nic snadného - prompt engineering je pro každého, fine-tuning rozhodně ne, potřebujete borce, co tomu rozumí), v kombinaci s uzavřenými modely, které ale také mají různé cenové škály viz řádové rozdíly mezi Ada, GPT 3.5 a GPT 4. V každém případě díky AzureML si můžete otestovat open source modely hned - stačí kliknout na tlačítko Deploy a udělat si představu sami. Zkuste si to.