Azure CosmosDB je celoplanetární NoSQL databáze s fantastickým škálování, multi-master replikací, výborným SLA na dostupnost (99,999% při geo nasazení) a latenci, laditelnou konzistencí od silné po eventuální, podporující více modelů práce s daty a způsobů přístupu (API). Jedním z nich je SQL interface a ten je ideální pro ty, kteří přichází z klasického relačního světa. Podívejme se dnes na tuto možnost.
O Cosmos DB už jsem psal a ještě hoooodně psát budu. Je to moje nejoblíbenější databáze na planetě. Dnes se nebudu věnovat jejím vlastnostem, spíše se zaměřím na to, jak to vypadá, když se k NoSQL přistupuje přes SQL.
Založení DB a SQL dotazy
Svoje zkoušení začneme vytvořením Cosmos DB s SQL API a následně si v něm vytvoříme svou první databázi a kolekci. Pro jednoduchost použiji něco malého - tedy fixní velikost a bez partition, protože megavýkony ani megaprostor pro dnešní díl nepotřebuji.
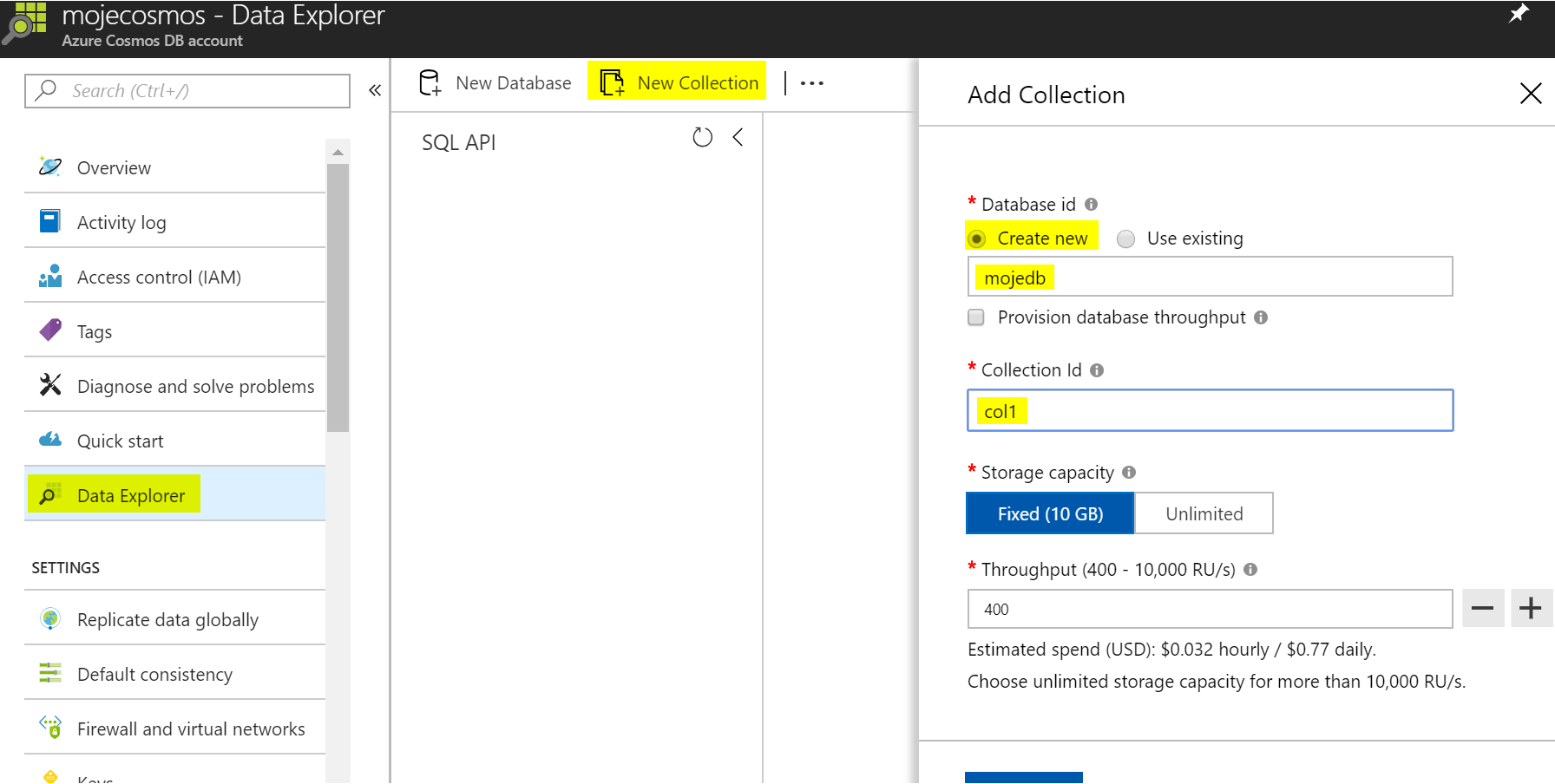
Pro malinká testovací data použiji svou databázi zvířátek, kterou jsem importoval i pro minulý díl s Mongo DB API pro Cosmos DB. Je jednoduchá a přitom ukazuje nerelační vlastnosti, tedy vnořené atributy a vnořené objekty (pole). Je uložena zde:
https://raw.githubusercontent.com/tkubica12/cosmosdb-demo/master/zviratka.json
Uploadněte ji do Cosmos DB.

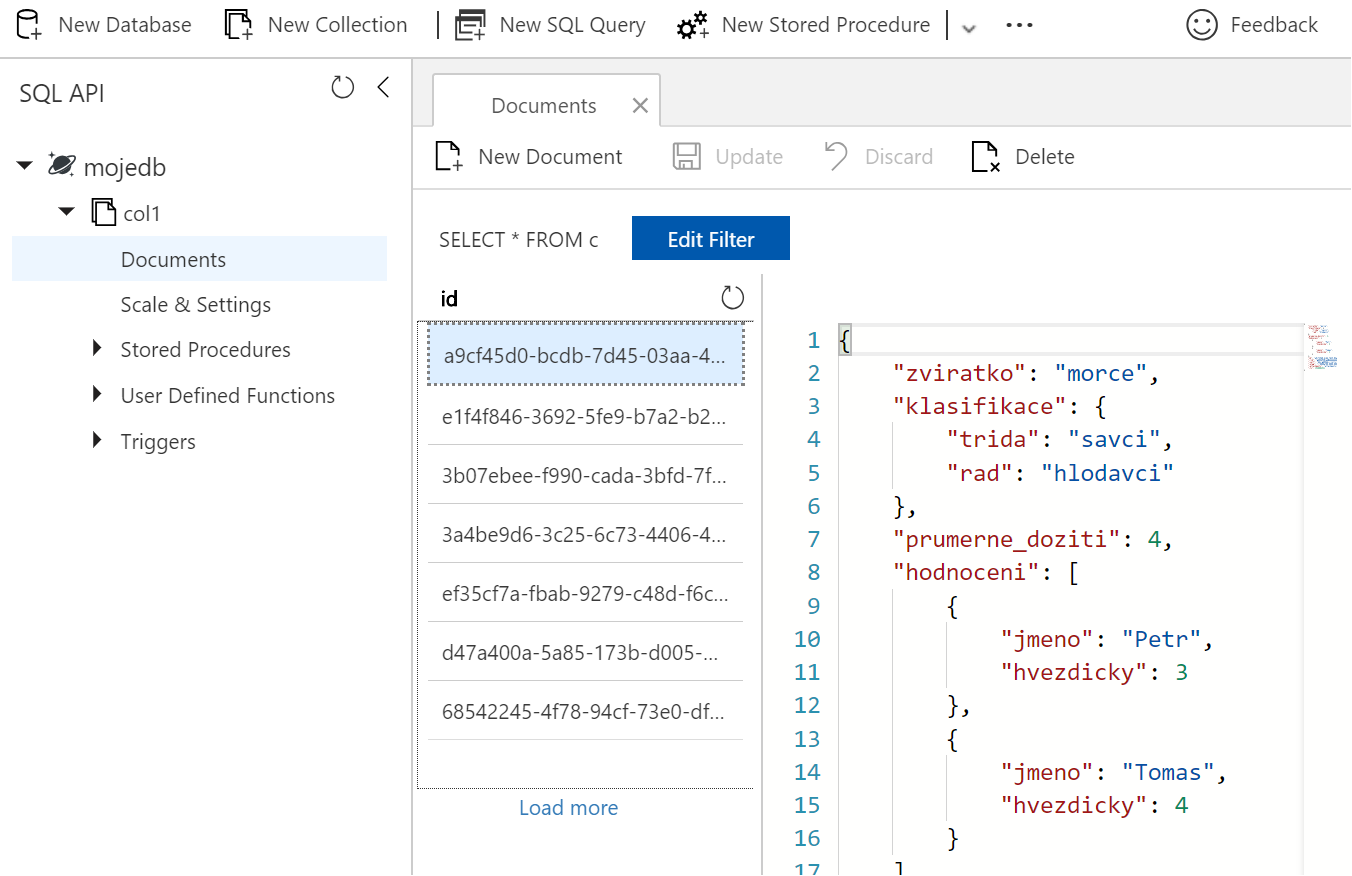
Měli bychom pár dokumentů vidět.
Můj první dotaz bude na informace o morčeti, takže použiji WHERE klauzuli. Nicméně nezajímá mě teď, jak ho lidé hodnotí ani jak dlouho žije, chci vědět jen jeho klasifikaci. V SELECT tedy vyjmenuji pouze dvě "políčka".
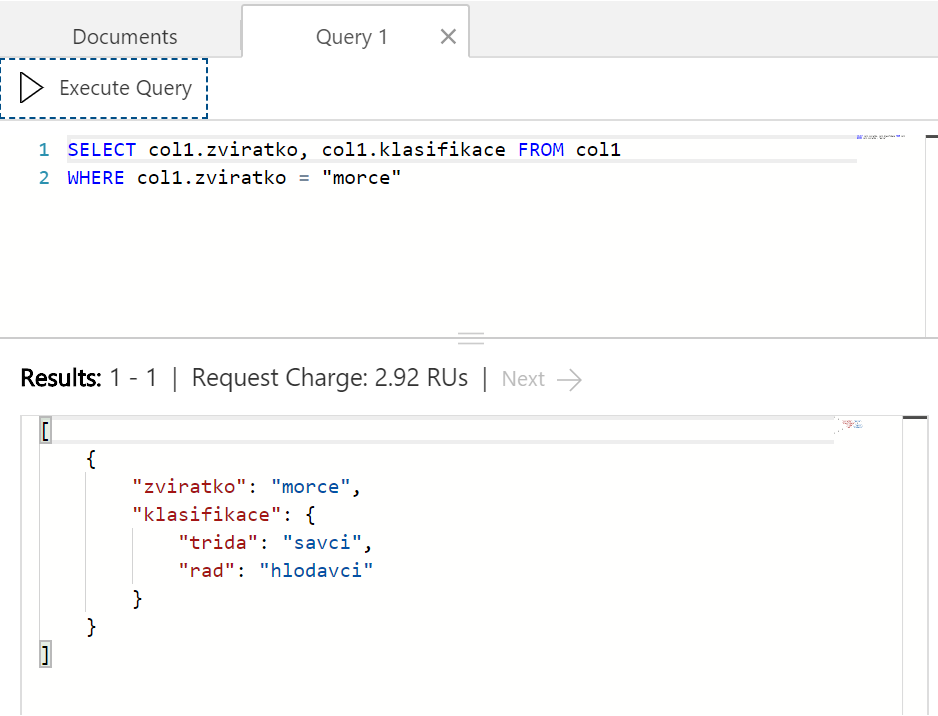
Výsledek mám zase jako JSON, ale je v něm jen co potřebuji. Všimněte si opět, že mi systém ukazuje kolik jsem spotřeboval RU jednotek na tento dotaz.
Dál si chci vypsat všechny savce. To je ale vnořený atribut trida zařazený pod klasifikace. To není problém - použijeme klasický "tečkovací" zápis do WHERE klauzule (využíváme faktu, že by default jsou všechna pole včetně vnořených indexována).
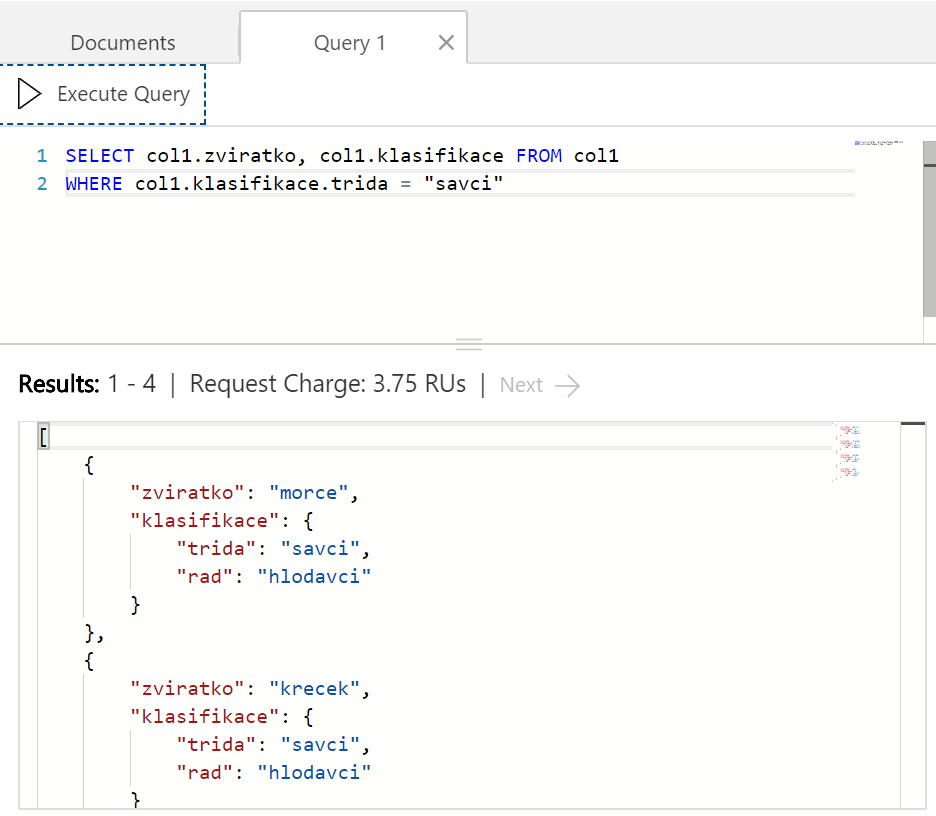
Zajímá vás, kolik se v průměru savci dožívají? Cosmos DB podporuje široký výčet agregačních funkcí, takže poměrně intuitivně můžeme položit následující dotaz.
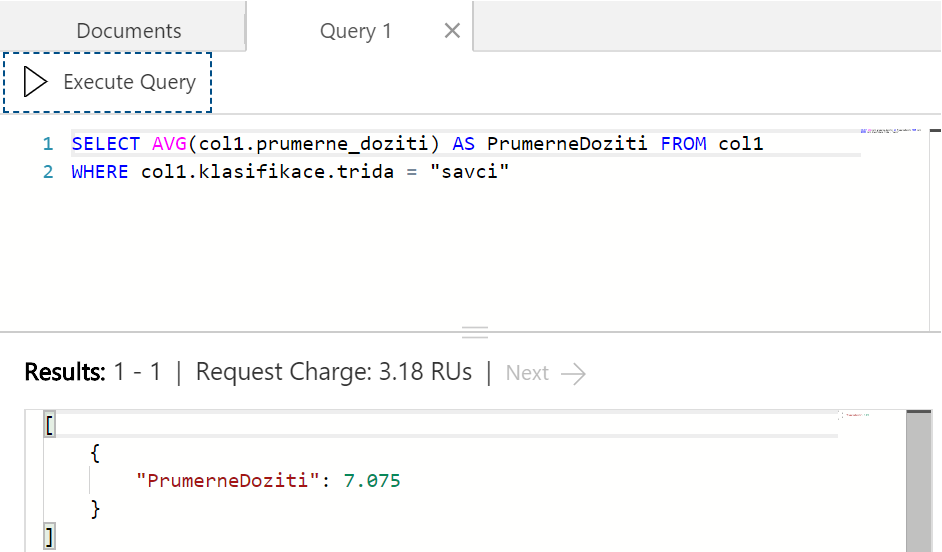
Za zmínku na tomto místě stojí, že v době psaní článku (květen 2018) SQL API nepodporuje GROUP BY. Nemůžeme tedy jedním dotazem vypsat průměrné dožití za jednotlivé třídy. Pokud něco takového nutně potřebujete jsou dnes dvě možnosti. Tou první je přejít na Mongo DB API, které už v Cosmos DB toto implementované má (přes agregační pipeline) případně napojit Cosmos DB na Spark a pokročilejší analytiku dělat tam. Nicméně z veřejných zdrojů na GitHub je dostupná informace, že Cosmos DB tým na implementaci GROUP BY pracuje, takže se v budoucnu objeví.
Pojďme dál. U každého zvířátka máme seznam (pole) jeho hodnocení uživateli. Jak ale v SQL pracovat s vnořeným polem? Abychom s tím mohli něco dál dělat potřebovali bychom to rozmontovat. Tedy vrátit "řádek" pro každé hodnocení týkající se savce, v kterém bude ale i zvířátko a třída, ať s tím můžeme dál pracovat. Takové rozmontování provedeme operací JOIN. Nejsme v relačním světě, takže nemůžeme provádět JOIN mezi různými kolekcemi, ale lze dělat JOIN sám na sebe.
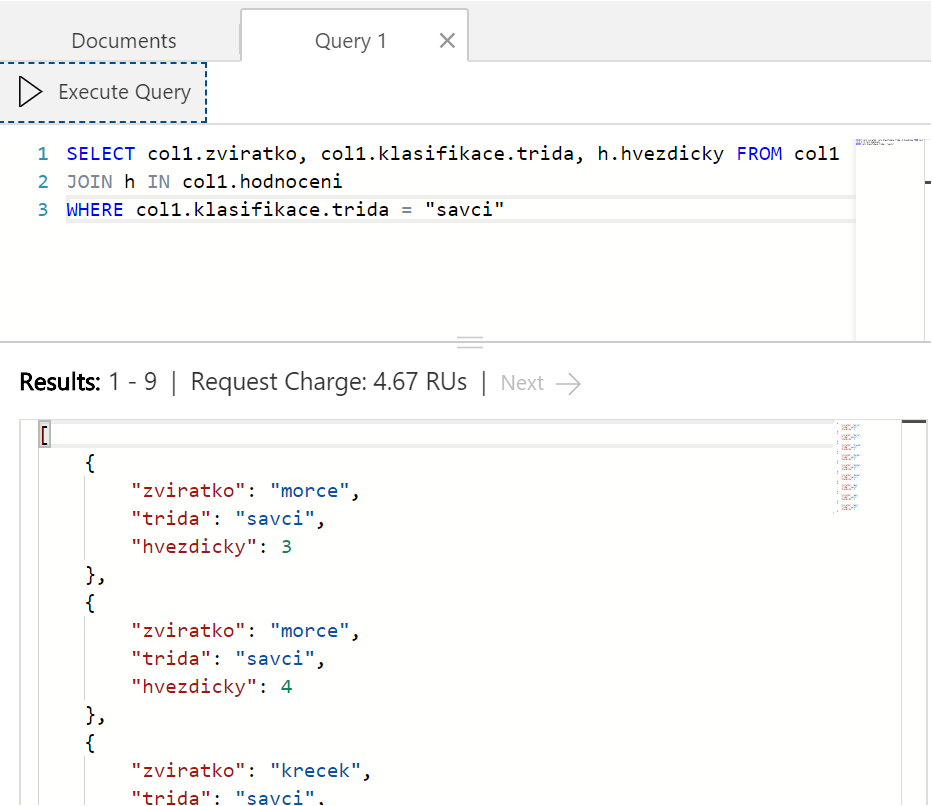
Funguje. Pokud nás tedy zajímá průměrné hodnocení všech savců dohromady, vypadalo by to nějak takhle.
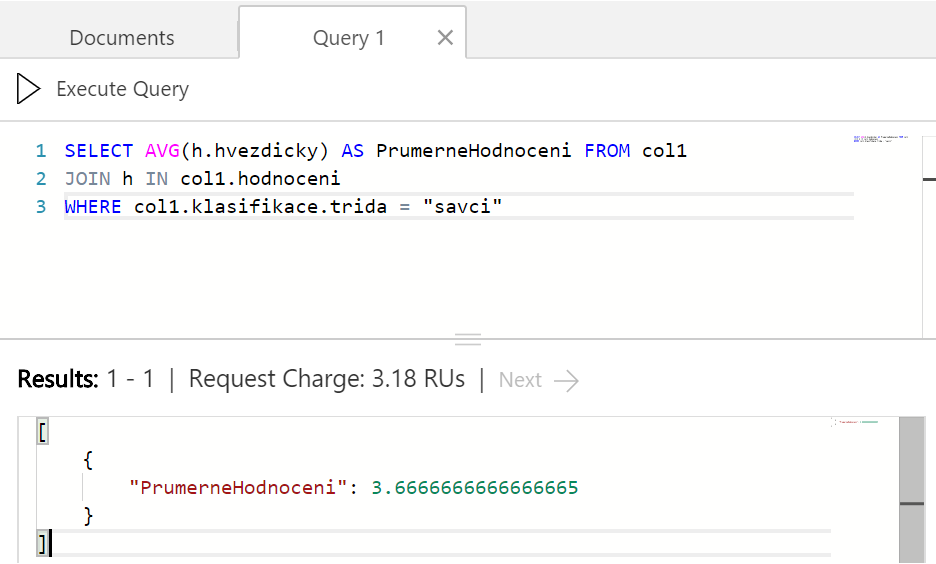
Všimněte si, že množství spotřebovaných RU není nijak výrazně vyšší, než jiné příklady v tomto článku. To ukazuje, že pro Cosmos DB takové operace nejsou nic zvláštního nebo výpočetně výrazně náročnějšího. Vnitřní struktura a indexy jsou na takové operace dělané.
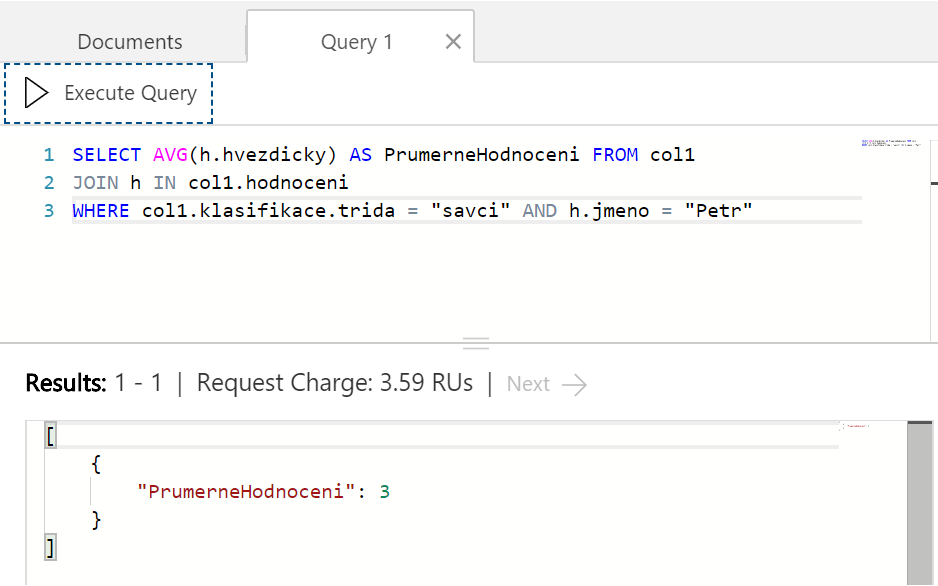
Stejně tak třeba můžu chtít vědět jaké průměrné hodnocení dal Petr savcům. Spotřeba RU opět nevybočuje.
Vypišme si zvířátka obsahující písmenko "k".
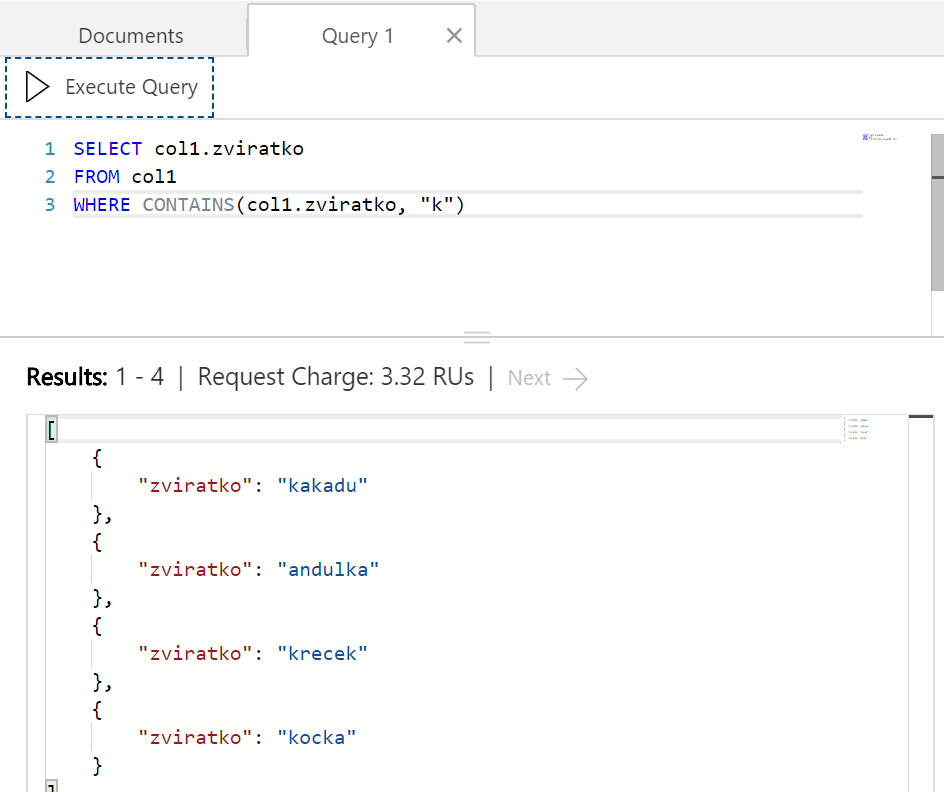
Je tam i andulka. Co když potřebujeme "k", ale pouze na začátku řetězce?
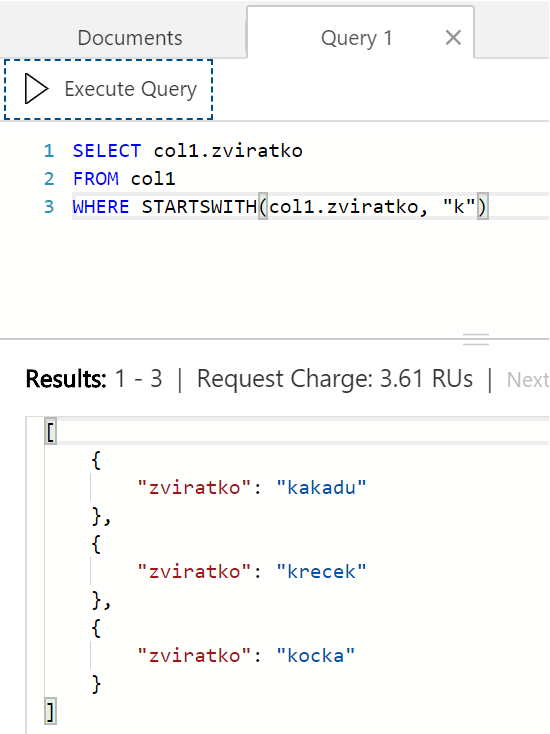
Můžeme i třídit. Co si seřadit zvířátka podle délky dožití?
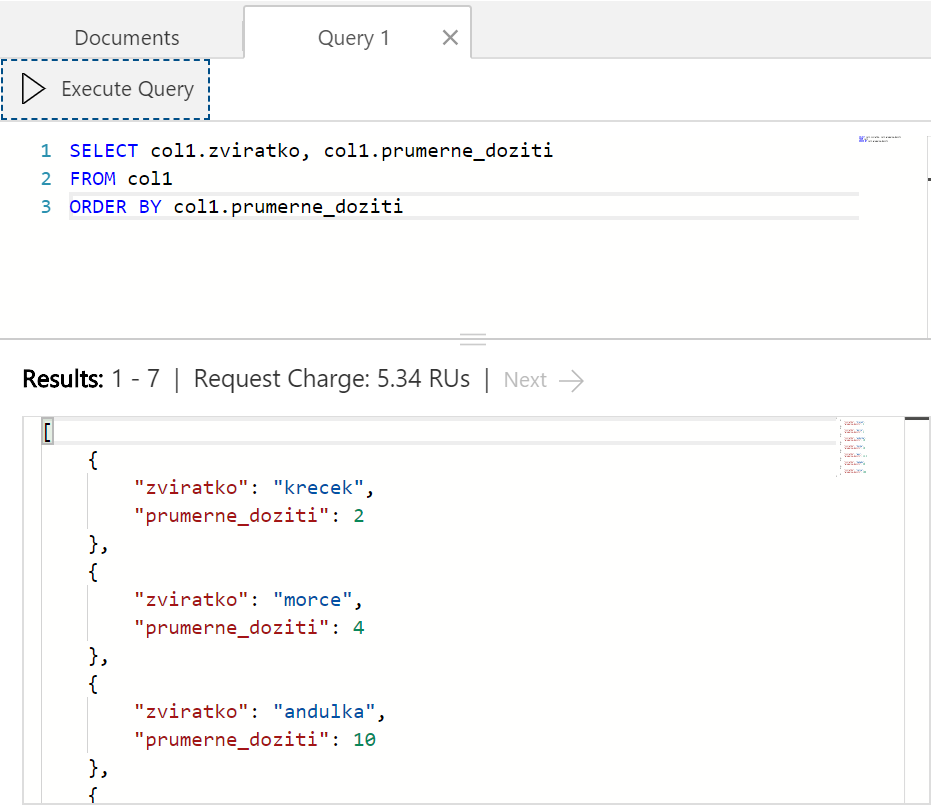
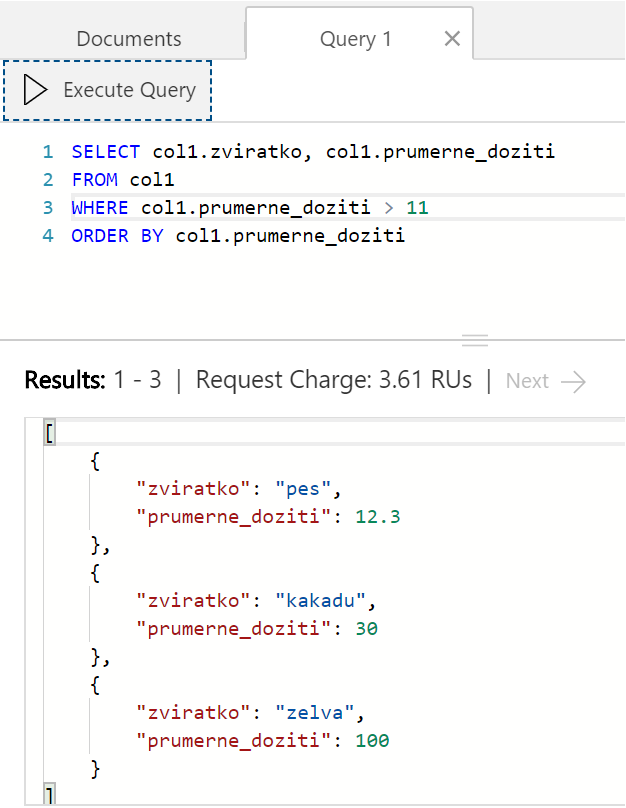
Můžeme pracovat i s range, takže si ukažme pouze zvířátka dožívající se víc jak 11 let a seřaďme je opět vzestupně. Všimněte si, že spotřeba RU bude nižší, než u předchozího příkladu. Z toho je patrné, že indexování zahrnuje nejen exact match, ale i range (takže spotřeba RU nenaroste, ale naopak sníží se, protože vracíme méně výsledků).
Zapisování a aktualizace dokumentů
Pro zapisování a aktualizaci ovšem SQL API nepoužívá klasických konstruktů typu INSERT nebo UPDATE. To už se provádí aplikačně, což považuji za velmi příjemné. Dokumenty jsou JSON struktura a v rámci programovacího jazyka je tak dokážete zapisovat přímo. Nemusíte je normalizovat do relací, ale objekt v paměti jednoduše zapíšete. U Node.js je to naprosto přirozené (datové struktury Javascriptu jsou na JSON přímo postavené), v Python se jednoduše využije dictionary (velmi podobné JSON) a v případě "velkých" jazyků typu C# nebo Java budete objekt držet v nějaké třídě s atributy a SDK vám umožní ho ukládat a načítat bez nutnosti dalších konverzí.
Takhle vypadá například drobná aplikace v Python a trochu si ji rozklíčujeme.
import pydocumentdb.documents as documents
import pydocumentdb.document_client as document_client
import pydocumentdb.errors as errors
import datetime
HOST = "https://mojecosmos.documents.azure.com:443/"
MASTER_KEY = "vas-klic=="
DATABASE_ID = "mojedb"
COLLECTION_ID = "col1"
database_link = 'dbs/' + DATABASE_ID
collection_link = database_link + '/colls/' + COLLECTION_ID
class IDisposable:
""" A context manager to automatically close an object with a close method
in a with statement. """
def __init__(self, obj):
self.obj = obj
def __enter__(self):
return self.obj # bound to target
def __exit__(self, exception_type, exception_val, trace):
# extra cleanup in here
self = None
def run():
with IDisposable(document_client.DocumentClient(HOST, {'masterKey': MASTER_KEY} )) as client:
try:
# Pripojime DB
client.ReadDatabase(database_link)
# Pripojime kolekci
client.ReadCollection(collection_link)
# Zalozime novy dokument
document = {
"zviratko": "slon",
"klasifikace": {
"trida": "savci",
"rad": "chobotnatci"
},
"prumerne_doziti": 70,
"hodnoceni": [
{
"jmeno": "Petr",
"hvezdicky": 5
},
{
"jmeno": "Tomas",
"hvezdicky": 5
}
]
}
client.CreateDocument(collection_link, document)
# Najdeme psa
query = {
"query": "SELECT * FROM col1 WHERE col1.zviratko=@zviratko",
"parameters": [ { "name":"@zviratko", "value": "pes" } ]
}
pes = list(client.QueryDocuments(collection_link, query))
pes[0]['hodnoceni'].append({'jmeno': 'Milan', 'hvezdicky': 4})
client.UpsertDocument(collection_link, pes[0])
except errors.HTTPFailure as e:
print(e.message)
if __name__ == '__main__':
run()
Nejprve se připojím do DB s využitím pydocumentdb SDK (to je Python SDK pro SQL API pro Cosmos DB). V Pythonu si založím proměnnou document, kterou vyplním v podstatě JSONovým zápisem. Následně tuto strukturu jednoduše pošlu do DB.
Následně chci přidat nové hodnocení pro psa. Protože mám ID dokumentu náhodně generované, musím ho nejdřív najít. Mravnější by asi bylo použít atribut zviratko jako ID a pak nemusím query dělat. Pro tentokrát ve svém dotazu použiji SELECT syntaxi co už známe a vrátí se mi pole výsledků, které si uložím do proměnné pes. Já ale vím, že pes tam bude jen jeden a tak dál pracuji pouze s prvním výsledkem (pes[0]). Načtený objekt si chci upravit, tedy přidat do něj nové hodnocení. Stačí se mi tedy odkázat na pes[0]['hodnoceni'] a použít append pro přidání dalšího záznamu (objektu) se jménem hodnotitele a počtem hvězdiček. Výsledek vrátím zpátky do DB.
Všimněte si jak jednoduché to je z aplikačního hlediska. Neřeším vztahy mezi tabulkami, provázanost klíčů a nejsem strukturou nijak omezen. Pokud bych chtěl do hodnocení přidat kromě jména a hvězdiček ještě datum hodnocení, klidně to můžu rovnou udělat. Databáze to uloží a zaindexuje, nebude na mě křičet, že takové políčko není ve schématu.
Takhle se tedy pracuje s SQL přístupem do Azure Cosmos DB. Příště se podíváme na další vlastnosti Cosmos DB, ale v mezičase neváhejte a vyzkoušejte si to! Nemusíte nic složitě řešit a rozcházet, během pár minut získáte cennou zkušenost se světem NoSQL.