Kontejnery v Kubernetes jsou naprosto ideální pro stateless služby. Pokud potřebujete držet state, použijte plně spravované služby Azure jako jsou databáze, fronty nebo objektová storage. Přesto někdy můžete mít potřebu ukládat data v kontejnerech tak, že pod tím bude perzistentní storage. Tak jak si ve storage vytvoříte Volume pro připojení k VM, víte že je spolehlivý, redundantní a po odstranění VM tam data stále jsou, tak můžete chtít používat storage v kontejnerech. Jak na to?
Perzistence a stav v kontejnerech v Kubernetes
První moje doporučení je v co nejvíc službách to jde žádný state nemít. Pokud to vaše byznys logika umožňuje, tak ať jsou to bezestavové idempotentní funkce. Něco se jich zeptáte, ony se třeba někam podívají nebo budou něco počítat a vyplivnou výsledek. Mezi jejich voláním netřeba držet žádný state. U některých funkcí je to přirozený způsob, například webový frontend, který má za úkol vygenerovat stránku a veškerý state je buď v backendu nebo naopak na straně klienta.
Pokud potřebujete držet nějaký stav mezi voláními navrhuji jako druhou cestu co do preference tento stav externalizovat. Můžete třeba místo držení stavu jako takového zapisovat změny stavu (události) třeba do Azure Event Hub a implementovat tak Event Sourcing pattern. Možná je state jednoduchý a dočasný, třeba obsah nákupního košíku, a pak použijte Azure Redis. Dlouhodobější stav držte v Azure Cosmos DB (s možností MongoDB, SQL, Gremlin či Cassandra API), Azure Database fo MySQL, PostgreSQL, MariaDB nebo Azure SQL. Provázání komponent či událostně řízené systémy krásně rozjedete s Azure Queue, Azure Service Bus, Azure Event Grid a tak podobně. Statický obsah webu můžete servírovat rovnou z Azure Blob Storage případně v kombinaci s Azure CDN. Zkráta proč se trápit se stavem v Kubernetes, když jsou krásné hotové služby s SLA běžně na úrovni 99,99% a je to bez práce a přemýšlení.
Ani jedno neberete? Například máte aplikaci postavenou na databázi, která v Azure jako plně spravovaná služba zatím není? Či se váš distribuovaný systém neobejde bez koordinace v Etcd či Consul? Nebo potřebujete perzistenci a máte masivní požadavky na propustnost a latenci? V takový okamžik je rozhodně na místě použít perzistentní storage v Kubernetes.
V dnešním díle se budeme věnovat jen a pouze perzistentní storage. Z pohledu Compute je klasický Deployment v Kubernetes vhodný pro stateless služby, ne pro ty stavové. Často totiž potřebujete trochu jemnější chování ke stavové aplikaci (nepříklad nesestřelovat náhodně mastera databáze, nepřejmenovávat uzly a tak podobně). O tom a konceptu StatefulSetů někdy příště.
Disková storage s Azure Disk
V Kubernetes můžete mapovat existující storage staticky ke kontejneru, ale to není moc praktické. Lepší je nechat Kubernetes přímo vytvářet storage prostředky v podvozku (tedy v Azure) a ty pak přiřazovat kontejnerům. K tomu používá koncept StorageClass, což berte jako jakýsi driver do IaaS vrstvy. Podívám-li se do svého AKS clusteru jsou už tam pro mne dva drivery připraveny:
kubectl get storageclasses NAME PROVISIONER AGE default (default) kubernetes.io/azure-disk 4d managed-premium kubernetes.io/azure-disk 4d
Je to impementace postavená na Azure Disk, tedy datové disky tak, jak je znáte v IaaS (tedy disky pro VM) s tím, že driver na nich sám vytvoří Linuxový souborový systém. Výchozí třída je Azure Disk ve variantě Standard (HDD) a druhá možnost je managed-premium, což je dražší verze s SSD. Disky implementovaná storage má určité výhody a nevýhody, ale k tomu později.
Tahle vypadá YAML předpis pro vytvoření nového disku přímo z Kubernetes.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-azure-disk
annotations:
volume.beta.kubernetes.io/storage-class: managed-premium
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
Uložím si jak volumeDisk.yaml a aplikuji. Hned si vypíšu objekty PresistentVolumeClaim:
kubectl apply -f volumeDisk.yaml persistentvolumeclaim "my-azure-disk" created kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-azure-disk Pending managed-premium 15s
Výborně, pracuje se na tom. Po chvilce se v mé AKS resource group (té s vlastními zdroji, která se vytvořila při deploymentu AKS - začíná písmeny MC) objeví nový Azure Disk.
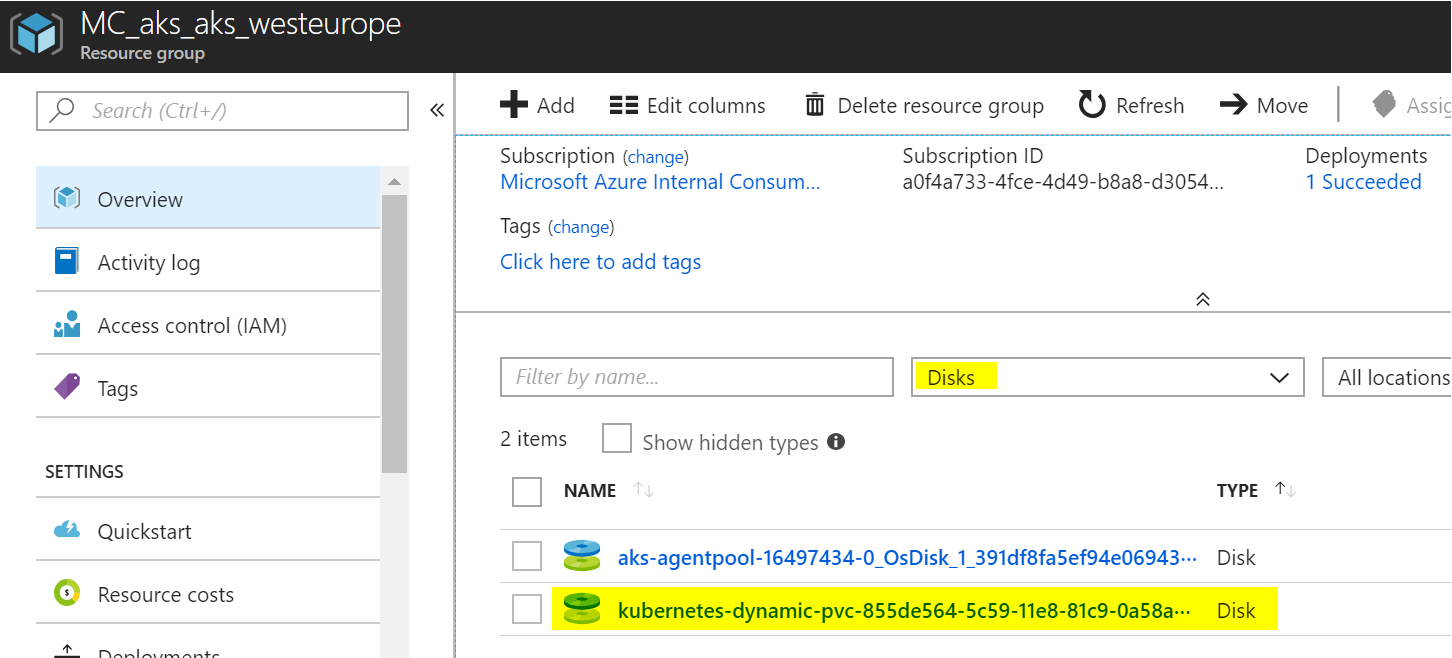
A skutečně - vidět to je i v Kubernetes.
kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-azure-disk Bound pvc-855de564-5c59-11e8-81c9-0a58ac1f101d 5Gi RWO managed-premium 1m
Tohoto disku teď využít a namapovat k Podu. Takhle bude vypadat ten můj:
kind: Pod
apiVersion: v1
metadata:
name: ubuntu
spec:
containers:
- name: ubuntu
image: tutum/curl
command: ["tail"]
args: ["-f", "/dev/null"]
volumeMounts:
- mountPath: "/mnt/azure"
name: volume
volumes:
- name: volume
persistentVolumeClaim:
claimName: my-azure-disk
Uložím jako soubor podVolumeDisk.yaml a aplikuji:
kubectl apply -f podVolumeDisk.yaml
Jakmile mi kontejner naběhne, v cestě /mnt/azure bych měl psát ve skutečnosti do perzistentního Azure Disk. Vytvořím tam tedy soubor a rovnou si ověřím, že ho můžu přečíst.
kubectl exec ubuntu -- bash -c 'echo Tohle jsou moje data > /mnt/azure/soubor.txt' kubectl exec ubuntu -- cat /mnt/azure/soubor.txt Tohle jsou moje data
Výborně. Teď pojďme Pod zlikvidovat.
kubectl delete -f podVolumeDisk.yaml
Ou. Pokud bychom nepoužívali žádný Volume nebo použili nějaký neperzistentní (tedy ne ze storage, ale z lokálního file systému), měli bychom problém (buď jsme rovnou naprosto bez dat nebo zůstávají zapomenuté někde ve file systému hostitele, kde je budeme složitě hledat a s havárií hostitele jsou nenávratně pryč). Naštěstí jsme ale psali do Azure Disk. Vytvořme tedy Pod znovu a podívejme se, že na přimapovaném disku data stále jsou.
kubectl apply -f podVolumeDisk.yaml kubectl exec ubuntu -- cat /mnt/azure/soubor.txt Tohle jsou moje data
Je to tak! Pokud chcete, vyzkoušejte si ještě možnost změnit u souboru oprávnění (chmod). Uvidíte, že to půjde a nastavení zůstane uchováno přímo ve storage.
Tím se dostáváme k zásadním výhodám a nevýhodám implementace přes Azure Disk.
Výhody jsou dvě hlavní - máte možnost použít SSD, které je velmi rychlé a za druhé systém plně podporuje Linux permissions ve vší flexibilitě.
Nevýhody? Trvá nějakou dobu, než se disky vytvoří a/nebo připojí (nic hrozného, ale desítky vteřin to být mohout). Platíte za disk bez ohledu na to, jak ho reálně používáte - sazby jsou zaokrouhleny na velikosti typu 32, 64, 128, 256, 512, 1TB, 2TB, 4TB). Třetí nevýhodou je fakt, že disk může být současně připojen jen do jednoho Podu. Není tedy vhodný na sdílení nějakých perzistentních dat (u DB budete nějakou synchronizaci v clusteru dělat na úrovni DB, takže sdílet nic stejně nechcete, ale třeba u statického obsahu vaší webovky by to smysl docela dávalo).
Bude tedy dobré vyzkoušet si i druhou možnost - použít Azure Files jako perzistentní storage pro Kubernetes.
Souborová storage s Azure Files
Druhou alternativou pro perzistentní storage je použití Azure Files. Nejprve si vytvoříme storage account v resource group, ve které jsou zdroje našeho clusteru (AKS vytvořilo RG s názvem něco jako MC_vášcluster_vášcluster_location).
az storage account create -g MC_aks_aks_westeurope \ -n mujaksshare \ --sku Standard_LRS
Příslušná storage class není v AKS vytvořena "od výroby", tak ji jednoduše založíme:
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: managed-files provisioner: kubernetes.io/azure-file parameters: storageAccount: mujaksshare
Soubor uložím jako storageClass.yaml a aplikuji.
kubectl apply -f storageClass.yaml
Máme připraveno.
kubectl get storageclasses NAME PROVISIONER AGE default (default) kubernetes.io/azure-disk 4d managed-files kubernetes.io/azure-file 13s managed-premium kubernetes.io/azure-disk 4d
Vytvořme tedy takový Volume použitím PersistentVolumeClaim. Abychom viděli rozdíl, zvolíme AccessMode podporující připojení do vícero Podů.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: muj-share
spec:
accessModes:
- ReadWriteMany
storageClassName: managed-files
resources:
requests:
storage: 5Gi
Uložíme jako volumeFiles.yaml a pošleme do Kubernetes.
kubectl apply -f volumeFiles.yaml
Vypišme si teď tohle PVC:
kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE muj-share Bound pvc-90eea1d9-5cab-11e8-81c9-0a58ac1f101d 5Gi RWX managed-files 7s
Všimněte si, že se v naší storage založil nový share.
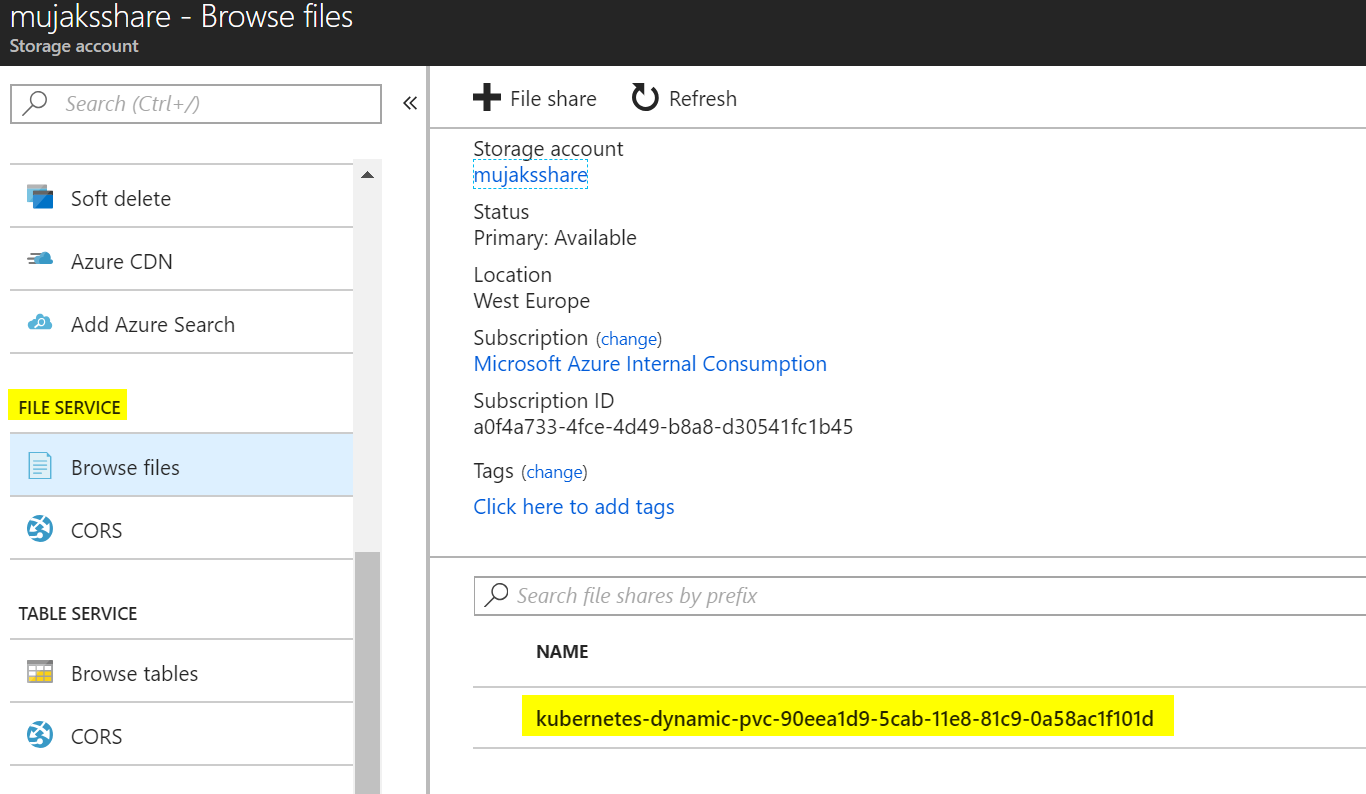
Vytvoříme si teď dva Pody, které budou oba mít namapovaný náš share.
kind: Pod
apiVersion: v1
metadata:
name: ubuntu1
spec:
containers:
- name: ubuntu
image: tutum/curl
command: ["tail"]
args: ["-f", "/dev/null"]
volumeMounts:
- mountPath: "/mnt/azure"
name: volume
volumes:
- name: volume
persistentVolumeClaim:
claimName: muj-share
---
kind: Pod
apiVersion: v1
metadata:
name: ubuntu2
spec:
containers:
- name: ubuntu
image: tutum/curl
command: ["tail"]
args: ["-f", "/dev/null"]
volumeMounts:
- mountPath: "/mnt/azure"
name: volume
volumes:
- name: volume
persistentVolumeClaim:
claimName: muj-share
Uložím jako podVolumeFiles.yaml a aplikuji.
kubectl apply -f podVolumeFiles.yaml
Vytvořme v prvním Podu soubor ve Volumu.
kubectl exec ubuntu1 -- bash -c 'echo Tohle jsou moje data > /mnt/azure/soubor.txt'
Všimněte si, že je v Azure Files vidět. To je zajímavá výhoda, protože se můžeme jednoduše připojit do stejného share i mimo Kubernetes klasicky CIFS/SMB protokolem z Linuxu i Windows!
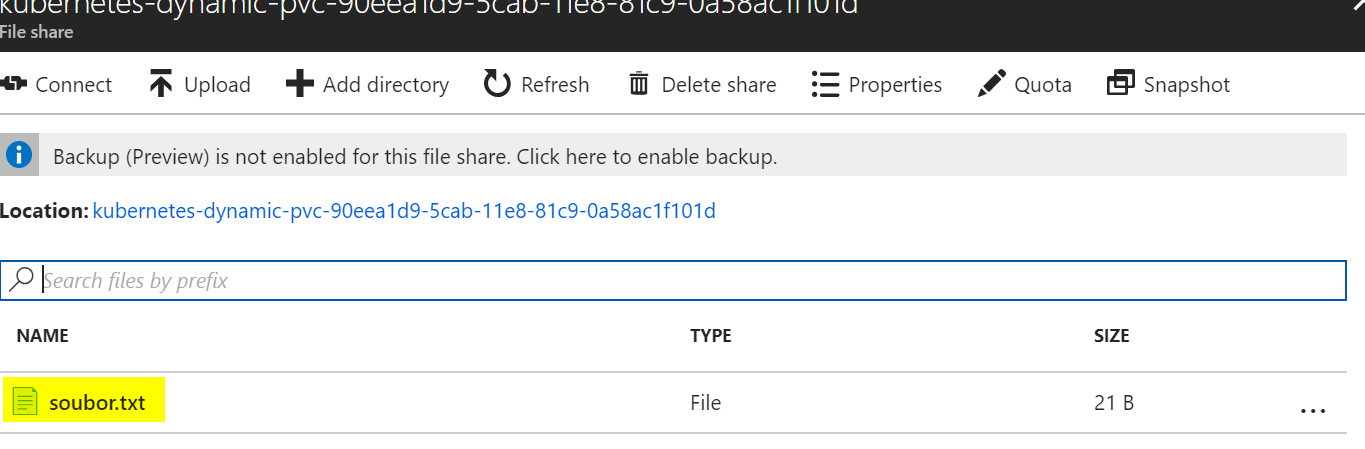
Soubor můžeme přečíst i z druhého Podu.
kubectl exec ubuntu2 -- cat /mnt/azure/soubor.txt Tohle jsou moje data
To je tedy druhá výhoda - sdílení.
Ukažme si nevýhodu - Azure Files nedokáží uchovat Linuxové permissions.
kubectl exec ubuntu1 -- chmod 500 /mnt/azure/soubor.txt kubectl exec ubuntu1 -- ls -l /mnt/azure total 1 -r-xr-xr-x 1 root root 21 May 21 04:08 soubor.txt
Kubernetes tedy má koncept perzistentní storage a AKS přichází s připravenými drivery do spodní IaaS ve formě Azure Disk a/nebo Azure Files. Někdy příště se podíváme jak toho využít pro stavové aplikace v kombinaci s compute konstruktem StatefulSet. Vyzkoušejte si AKS v Azure ještě dnes.