Mongo DB se stala mezi vývojáři populární pro svou jednoduchost použití přes kterou ale stále umí nabídnout pokročilejší agregační operace. Cosmos DB ale přináší zásadní věci, které se vám určitě budou líbit - plně as a service, SLA na dostupnost, výkon, latenci i konzistenci, laditelný model konzistence, globální distribuovatelnost. Použijte fantastickou Cosmos DB v Azure, ke které ale můžete přistoupovat přes Mongo API a ani nemusíte měnit své knihovny a kód.
Založení DB a import dat
Nejprve si v Azure portálu založíme Cosmos DB s API typu Mongo.
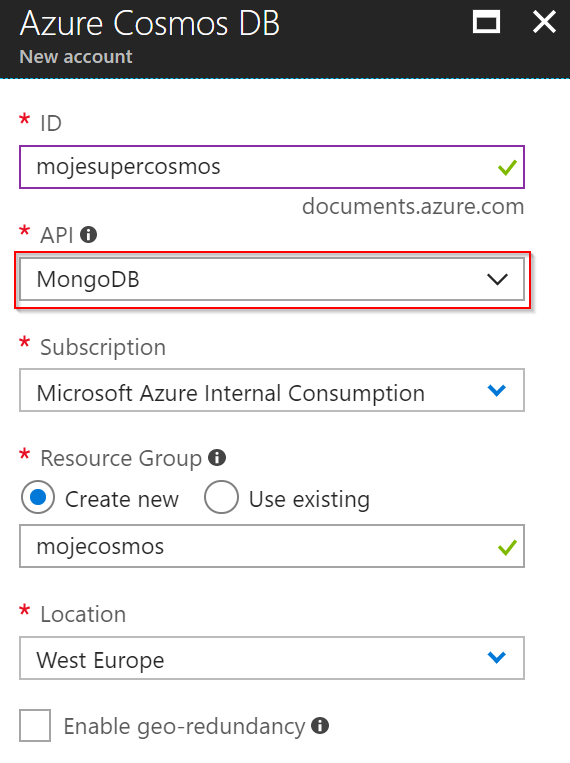
Po chvilce bude naše Cosmos DB připravena a na záložce rychlého startu se dostaneme k připojovacím parametrům a hotovým ukázkám napojení mongo CLI, .NET, Node apod.
Vytvořme si naší první kolekci.
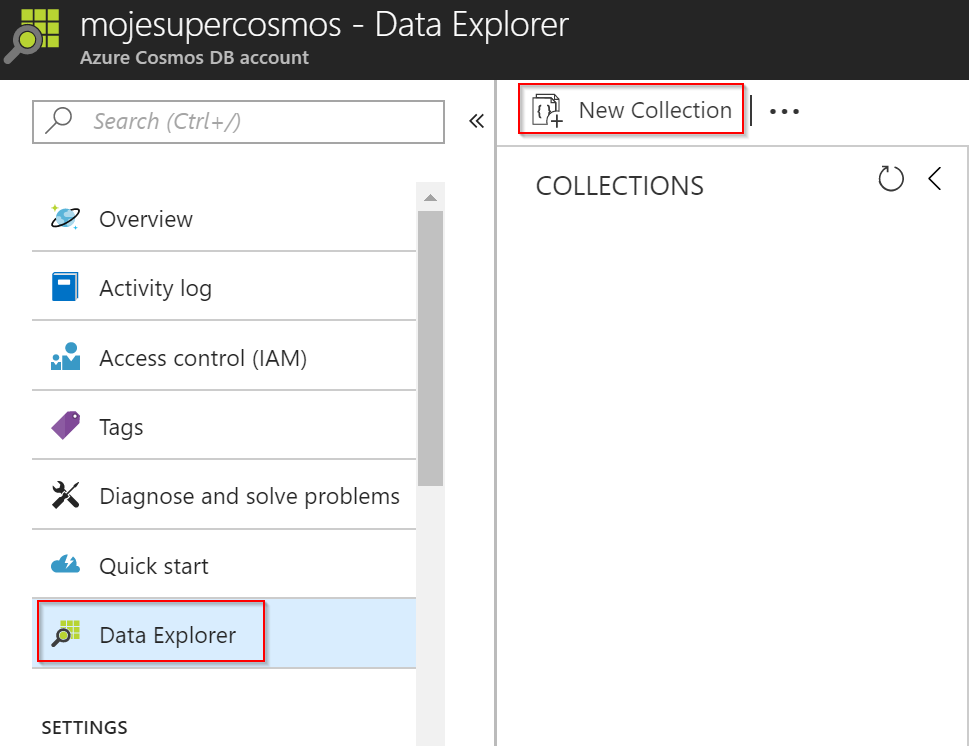
Já použiji model jedné partition (tedy pro menší použití). Na začátek zvolím nejmenší výkon 400 RU.
Stáhněte si malinkatou sadu JSON dokumentů, kterou jsem si pro účely zkoušení připravil: https://raw.githubusercontent.com/tkubica12/cosmosdb-demo/master/zviratka.json
Stáhněte si utilitku mongoimport (pro Linux nebo Windows - jak na to najdete na stránkách MongoDB) a všimněte si, že nepoužíváme nic specifického pro Cosmos DB! Jde o standardní řešení využívající Mongo API. Pošleme data do databáze.
mongoimport --db mojedb \
--collection zviratka \
--file ./zviratka.json \
--host mojesupercosmos.documents.azure.com \
--username mojesupercosmos \
--password "tadyjevasklicek" \
--port 10255 \
--ssl \
--sslAllowInvalidCertificates
Až import proběhne můžeme použít Azure portál a na dokumenty se podívat.
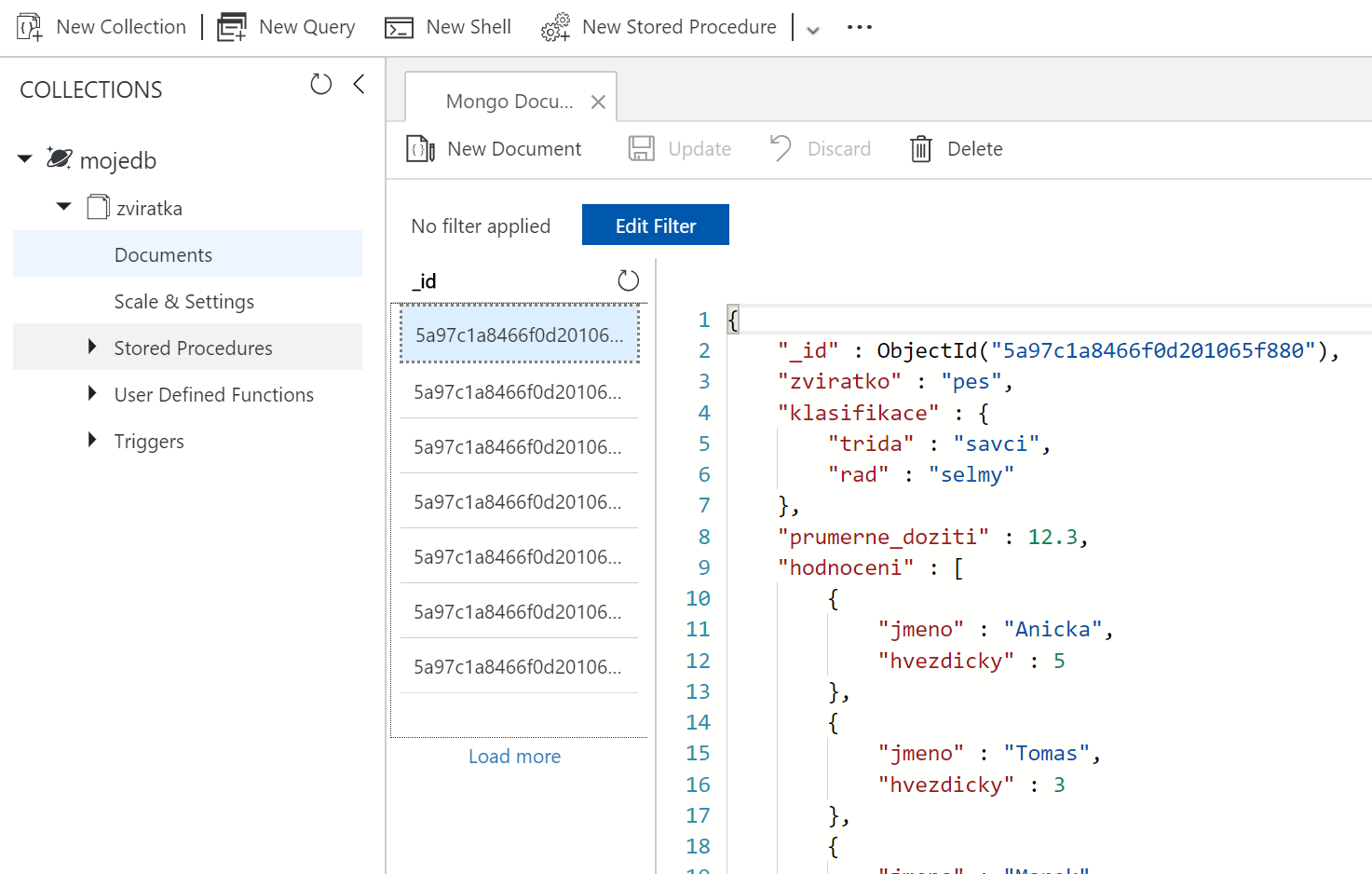
Naše první Mongo query
Můžeme si teď vyzkoušet nějaká jednoduchá query a to přímo z GUI. Dotazy se nejjednodušším způsobem formulují jako JSON, který funguje jako filtr na data. V jednom objektu předáte filtrovací kritéria a případně v druhém projekci, tedy která políčka chcete ve výstupu (tzn. něco jako místo SELECT * chcete konkrétní výčet).
Vypišme si zvířátko pes.
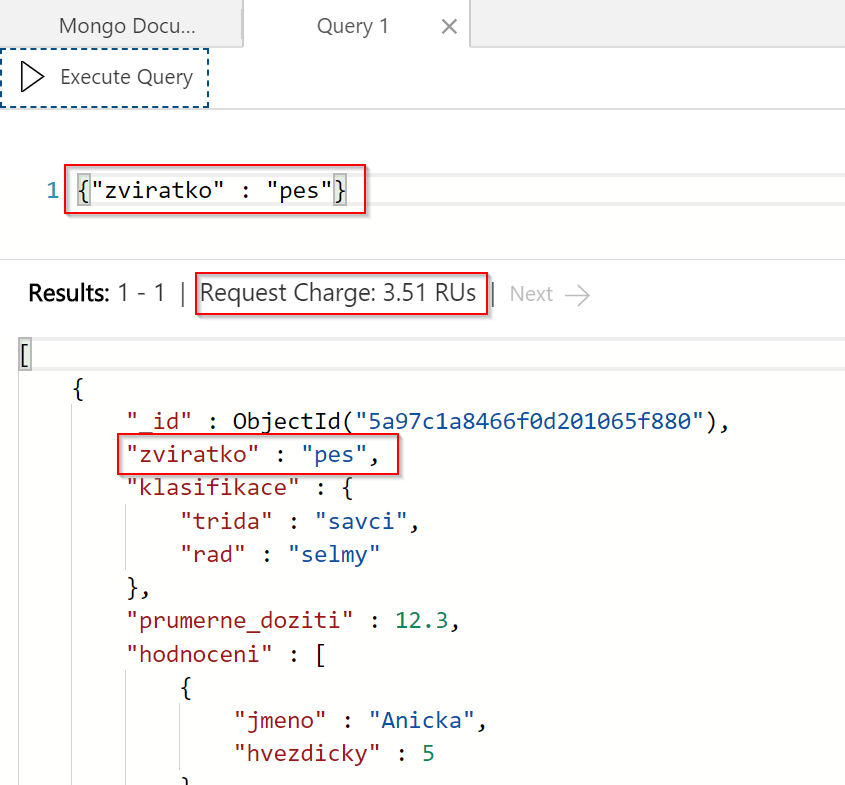
Všimněte si, že nám GUI rovnou říká kolik RU náš dotaz přesně spotřeboval. Snadno si tak uděláte představu jakou výkonnost DB potřebujete (zvolili jsme nejlevnější variantu s 400 RU/s).
Zeptat se můžeme nejen na hlavní klíče, ale i vnořené.
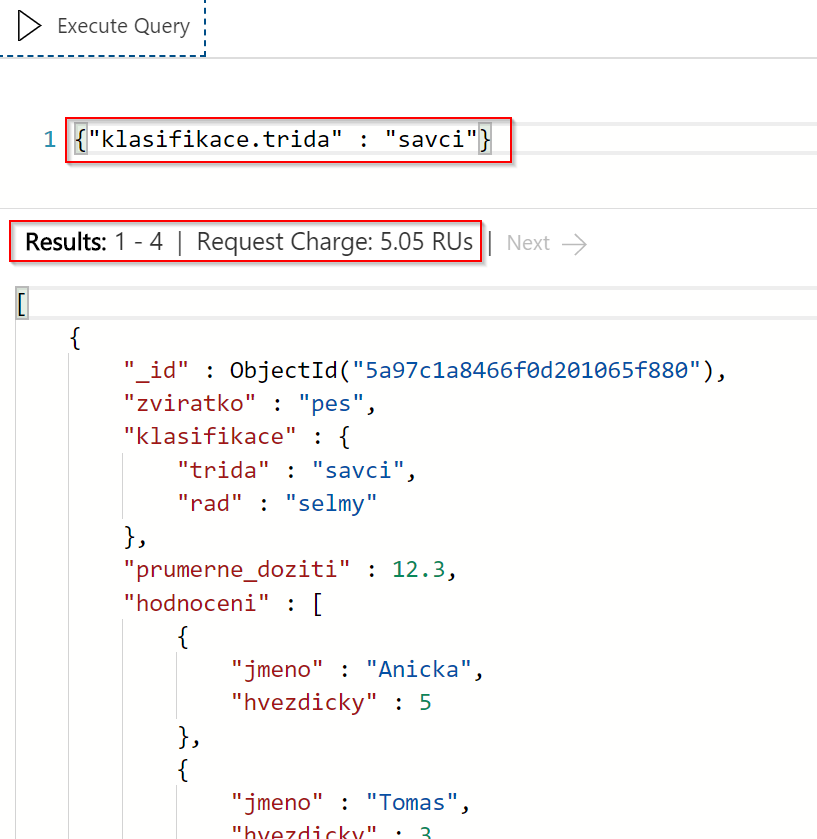
Mongo query jazyk podporuje i range dotazy, například vypišme si všechny záznamy, kde je průměrné dožití větší, než 10 let.
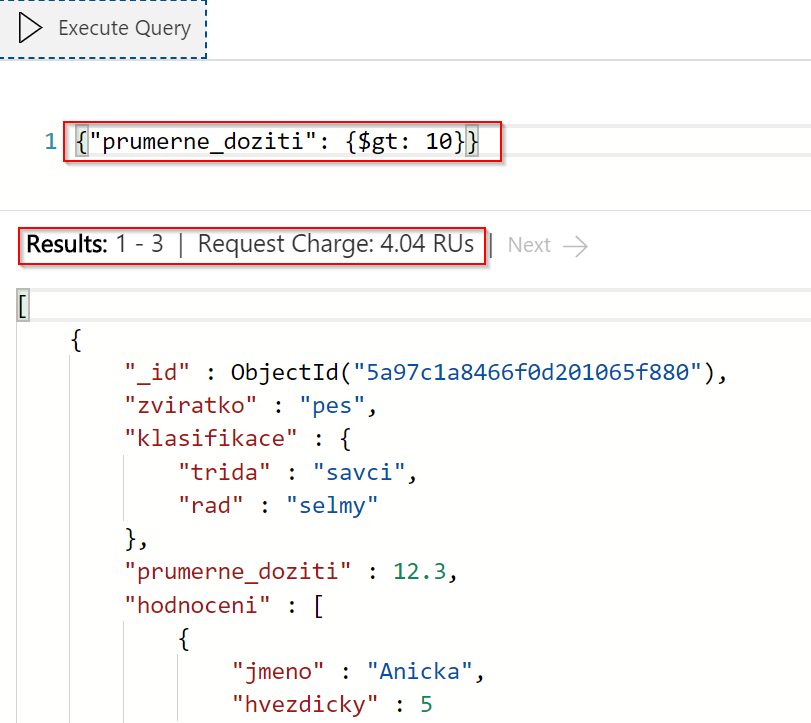
Všimněte si RU spotřeby, která zůstala stále nízka. To ukazuje, že všechna pole jsou indexována nejen na exact match, ale i na range operace.
Zeptat se můžeme i na obsah vnořeného pole. Například vypišme si všechna zvířátka, u kterých má nějaké hodnocení Tomas.

Pojďme teď podobné operace udělat v kódu, například s využitím Python. Nainstalujeme běžnou Mongo knihovnu (pymongo), otevřeme interaktvní Python a knihovnu naimportujeme.
$ pip install pymongo $ python Python 2.7.12 (default, Nov 19 2016, 06:48:10) [GCC 5.4.0 20160609] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import pymongo
Následně se potřebujeme připojit. Potřebný kód najdeme v sekci QuickStart v Azure portálu.
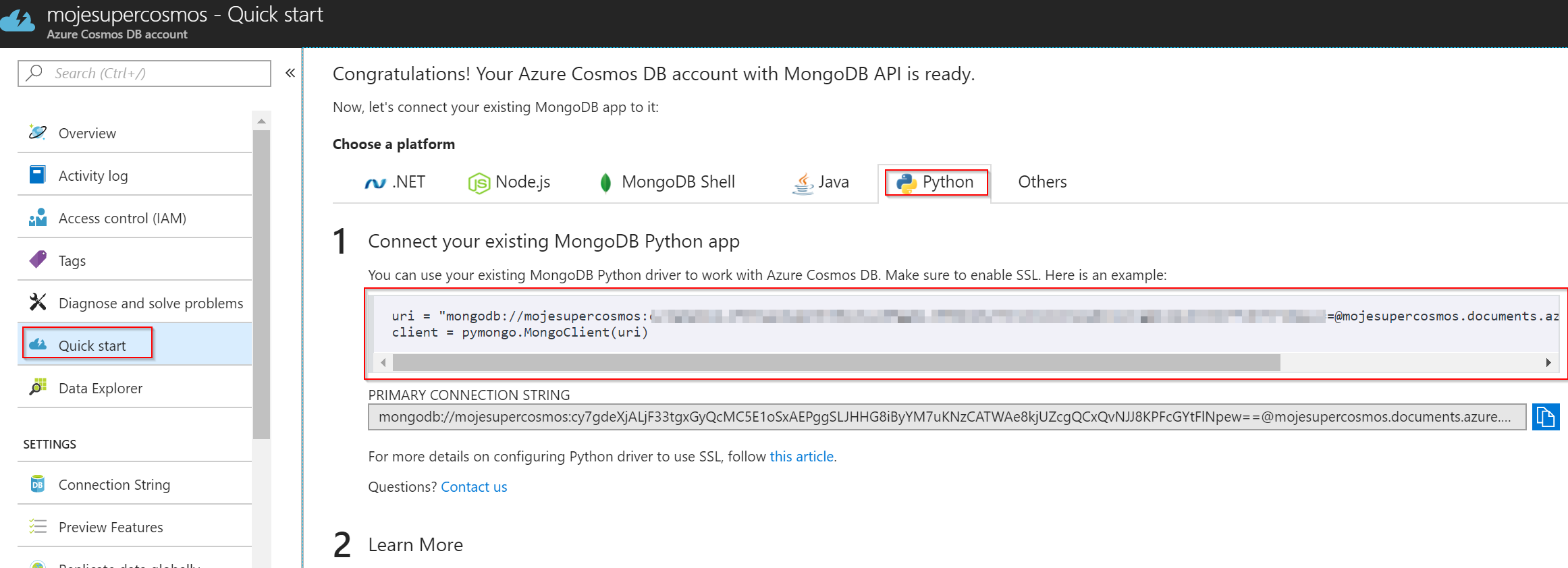
Vložíme do interaktivního Python a pak můžeme pokračovat vyhledáním a zobrazením dokumentů. Vypišme si všechny savce.
$ pip install pymongo
$ python
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import pymongo
>>> uri = "mongodb://mojesupercosmos:cy7gdeXjALjF33tgxGyQcMC5E1oSxAEPggSLJHHG8iByYM7uKNzCATWAe8kjUZcgQCxQvNJJ8KPFcGYtFlNpew==@mojesupercosmos.documents.azure.com:10255/?ssl=true&replicaSet=globaldb"
>>> client = pymongo.MongoClient(uri)
nt.>>> db = client.mojedb
>>> zviratka = db.zviratka
>>> for doc in zviratka.find({"klasifikace.trida" : "savci"}):
... print doc
...
{u'zviratko': u'pes', u'_id': ObjectId('5a97c1a8466f0d201065f880'), u'hodnoceni': [{u'hvezdicky': 5.0, u'jmeno': u'Anicka'}, {u'hvezdicky': 3.0, u'jmeno': u'Tomas'}, {u'hvezdicky': 4.0, u'jmeno': u'Marek'}], u'klasifikace': {u'rad': u'selmy', u'trida': u'savci'}, u'prumerne_doziti': 12.0}
{u'zviratko': u'kocka', u'_id': ObjectId('5a97c1a8466f0d201065f881'), u'hodnoceni': [{u'hvezdicky': 4.0, u'jmeno': u'Anicka'}, {u'hvezdicky': 4.0, u'jmeno': u'Karel'}, {u'hvezdicky': 2.0, u'jmeno': u'Martin'}], u'klasifikace': {u'rad': u'selmy', u'trida': u'savci'}, u'prumerne_doziti': 10.0}
{u'zviratko': u'krecek', u'_id': ObjectId('5a97c1a8466f0d201065f882'), u'hodnoceni': [{u'hvezdicky': 4.0, u'jmeno': u'Anicka'}], u'klasifikace': {u'rad': u'hlodavci', u'trida': u'savci'}, u'prumerne_doziti': 2.0}
{u'zviratko': u'morce', u'_id': ObjectId('5a97c1a8466f0d201065f883'), u'hodnoceni': [{u'hvezdicky': 3.0, u'jmeno': u'Petr'}, {u'hvezdicky': 4.0, u'jmeno': u'Tomas'}], u'klasifikace': {u'rad': u'hlodavci', u'trida': u'savci'}, u'prumerne_doziti': 4.0}
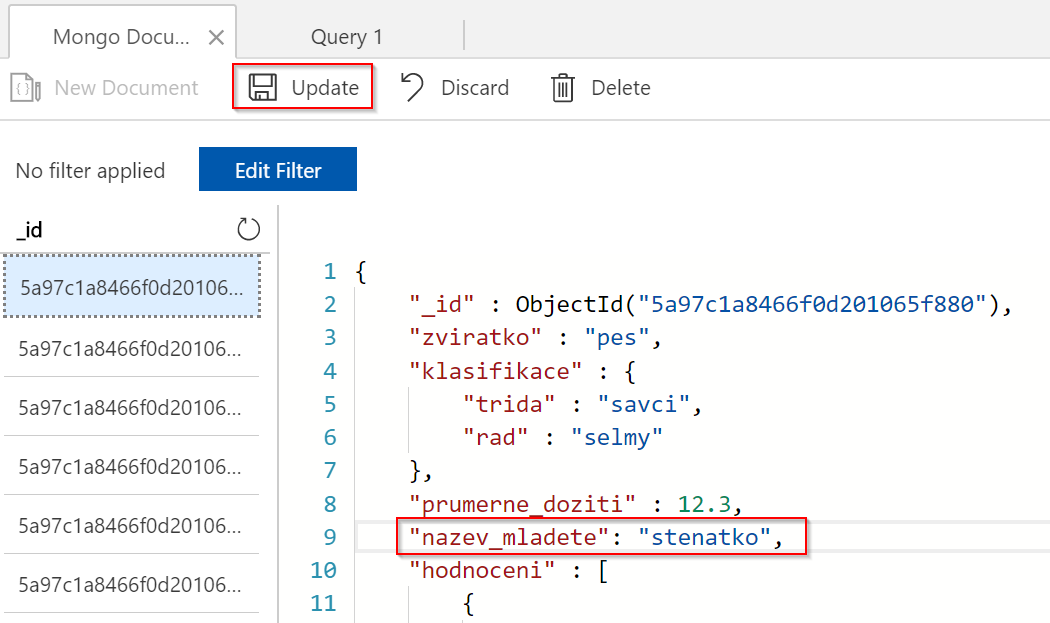
Funguje. Můžeme teď například modifikovat nějaký dokument. To se dá udělat na zkoušku přímo v portálu nebo samozřejmě použijeme příslušné operace v pymongo.
Na zkoušku můžete upravit dokument i přímo v GUI. JSON dokumenty nemají nějaké dopředu dané schéma, můžeme přidat cokoli co se nám může hodit, každý dokument může mít klidně jiné klíče.
Pokročilejší operace a agregace
V okamžiku psaní tohoto článku jsou pokročilejší věci jako wire protokol 3.4 nebo agregační pipeline v režimu Preview, ale tyto funkce si jednoduše zapneme.
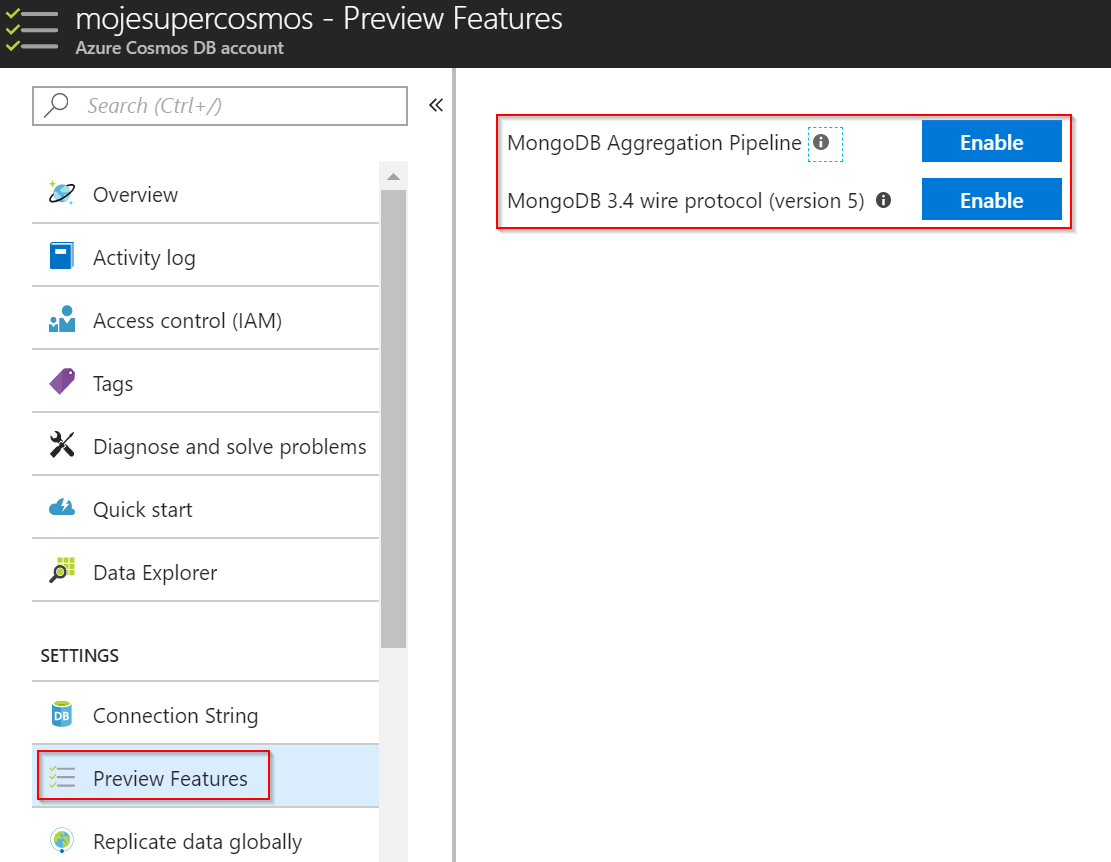
Pro zkoušení pokročilejších věcí použijeme standardní mongo shell. Nainstalujte jej a údaje pro připojení najdete v GUI.
Připojíme se a přepneme do mojedb.
mongo mojesupercosmos.documents.azure.com:10255 -u mojesupercosmos -p vasklic --ssl --sslAllowInvalidCertificates globaldb:PRIMARY> use mojedb switched to db mojedb
Zůstaňme u jednoduchých query, ale přidejme projekci, tedy druhý objekt, ve kterém řekneme, která políčka chceme (1) a která ne (0) - výchozí stav je, že _id se zobrazuje (proto ho explicitně vypínám) a zbytek ne, dokud explicitně neřekneme.
db.zviratka.find({},{"zviratko": 1, "klasifikace.trida": 1, "_id": 0})
{ "zviratko" : "pes", "klasifikace" : { "trida" : "savci" } }
{ "zviratko" : "kocka", "klasifikace" : { "trida" : "savci" } }
{ "zviratko" : "krecek", "klasifikace" : { "trida" : "savci" } }
{ "zviratko" : "morce", "klasifikace" : { "trida" : "savci" } }
{ "zviratko" : "kakadu", "klasifikace" : { "trida" : "ptaci" } }
{ "zviratko" : "andulka", "klasifikace" : { "trida" : "ptaci" } }
{ "zviratko" : "zelva", "klasifikace" : { "trida" : "plazy" } }
Ukažme si jak modifikovat objekt, ale rovnou si dáme něco složitějšího. V dokumentu máme pole s hodnocením a nechceme ho nahradit, spíše přidat nové hodnocení do existujícího pole. K tomu použijeme operaci push.
db.zviratka.update(
{ "zviratko": "pes" },
{ $push:
{
"hodnoceni": {
"jmeno": "Tina",
"hvezdicky": 5
}
}
}
)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })

Zkusme si teď nějakou trochu složitější operaci. Zajímalo by mne kolik máme v databázi savců. Nejprve provedu operaci match, abych savce vyfiltroval a pak operaci group. V té ve skutečnosti potřebuji všechno jako jedinou skupinu (pro nové _id odpovědi bude null) a přičtu jedničku za každý řádek.
db.zviratka.aggregate([
{ $match : { "klasifikace.trida": "savci" }},
{ $group: { _id: null, celkem: { $sum: 1 } } }
])
{
"_t" : "AggregationPipelineResponse",
"ok" : 1,
"waitedMS" : NumberLong(0),
"result" : [
{
"_id" : null,
"celkem" : 4
}
]
}
A co třeba počty zvířat v jednotlivých třídách seřazené podle tohoto počtu? Neprve použiji operaci group a klíčem pro seskupení (_id) bude klasifikace.trida. V policku celkem pak vezmu jedničku za každé zvířátko v třídě. V druhé operaci provedu seřazení podle tohoto pole.
db.zviratka.aggregate([
{ $group: { _id: "$klasifikace.trida", celkem: { $sum: 1 } } },
{ $sort: { celkem: -1 } }
])
{
"_t" : "AggregationPipelineResponse",
"ok" : 1,
"waitedMS" : NumberLong(0),
"result" : [
{
"_id" : "savci",
"celkem" : 4
},
{
"_id" : "ptaci",
"celkem" : 2
},
{
"_id" : "plazy",
"celkem" : 1
}
]
}
Mimochodem i přímo z Mongo API se můžeme zeptat na spotřebované RU poslední operace. Všimněte si, že ani tentokrát není spotřeba RU vysoká - systém indexuje všechno a dobře toho využívá.
db.runCommand({getLastRequestStatistics: 1})
{
"_t" : "GetRequestStatisticsResponse",
"ok" : 1,
"CommandName" : "aggregate",
"RequestCharge" : 4.44,
"RequestDurationInMilliSeconds" : NumberLong(5)
}
V rámci agregace samozřejmě nemusíme jen sčítat počty, ale provádět agregační operace na nějakých hodnotách. Co třeba průměrná délka dožití jednotlivých tříd?
db.zviratka.aggregate([
{ $group: { _id: "$klasifikace.trida", delka_zivota: { $avg: "$prumerne_doziti" } } },
{ $sort: { delka_zivota: -1 } }
])
{
"_t" : "AggregationPipelineResponse",
"ok" : 1,
"waitedMS" : NumberLong(0),
"result" : [
{
"_id" : "plazy",
"delka_zivota" : 100
},
{
"_id" : "ptaci",
"delka_zivota" : 20
},
{
"_id" : "savci",
"delka_zivota" : 7.25
}
]
}
Na závěr zkusme něco ještě složitějšího (stále ale zdaleko nevyužíváme celý potenciál). Uvnitř objektu máme vnořené pole s hodnocením. Mohlo by nás zajímat průměrné hodnocení jednotlivých zvířátek. Jak na to?
Nejdřív udělám projekci, protože mě zajímá pouze zvířátko a hodnocení, nic dalšího. Následně vnořené pole potřebuji rozmontovat (v relačním světě bychom řekli, že uděláme join), tím mi vznikne co záznam to zvířatko a jedno konkrétní hodnocení. Teď to můžu zase smontovat, tedy provedu group operaci podle zvířátka s tím, že spočítám průměr hodnocení.
db.zviratka.aggregate([
{ $project: { zviratko: 1, hodnoceni: 1 }},
{ $unwind: {
path: "$hodnoceni"
} },
{ $group: { _id: "$zviratko", delka_zivota: { $avg: "$hodnoceni.hvezdicky" } } },
])
{
"_t" : "AggregationPipelineResponse",
"ok" : 1,
"waitedMS" : NumberLong(0),
"result" : [
{
"_id" : "pes",
"delka_zivota" : 4.25
},
{
"_id" : "kocka",
"delka_zivota" : 3.3333333333333335
},
{
"_id" : "krecek",
"delka_zivota" : 4
},
{
"_id" : "morce",
"delka_zivota" : 3.5
},
{
"_id" : "kakadu",
"delka_zivota" : 3.3333333333333335
},
{
"_id" : "andulka",
"delka_zivota" : 3
},
{
"_id" : "zelva",
"delka_zivota" : 4.5
}
]
}
To je co jsem potřeboval! Otázka je, jak to bylo drahé. Podívejme se.
db.runCommand({getLastRequestStatistics: 1})
{
"_t" : "GetRequestStatisticsResponse",
"ok" : 1,
"CommandName" : "aggregate",
"RequestCharge" : 4.44,
"RequestDurationInMilliSeconds" : NumberLong(14)
}
Latence je samozřejmě vyšší, než jednoduchá čtecí operace, nicméně spotřebované RU nejsou vůbec špatné.
Jak se naší DB vede?
Přímo v GUI najdete velmi přehledně všechny potřebné metriky. Tak například jaká byla latence našich dotazů a splňovala SLA? Uvedené údaje se týkají vybavovací a zapisovací doby DB, tedy za jak dlouho vrátí data - nepočítá se do toho samozřejmě doba potřebná pro případné agregační výpočty nad daty.
Během mých pár pokusů bylo SLA výrazně přeplněno :)
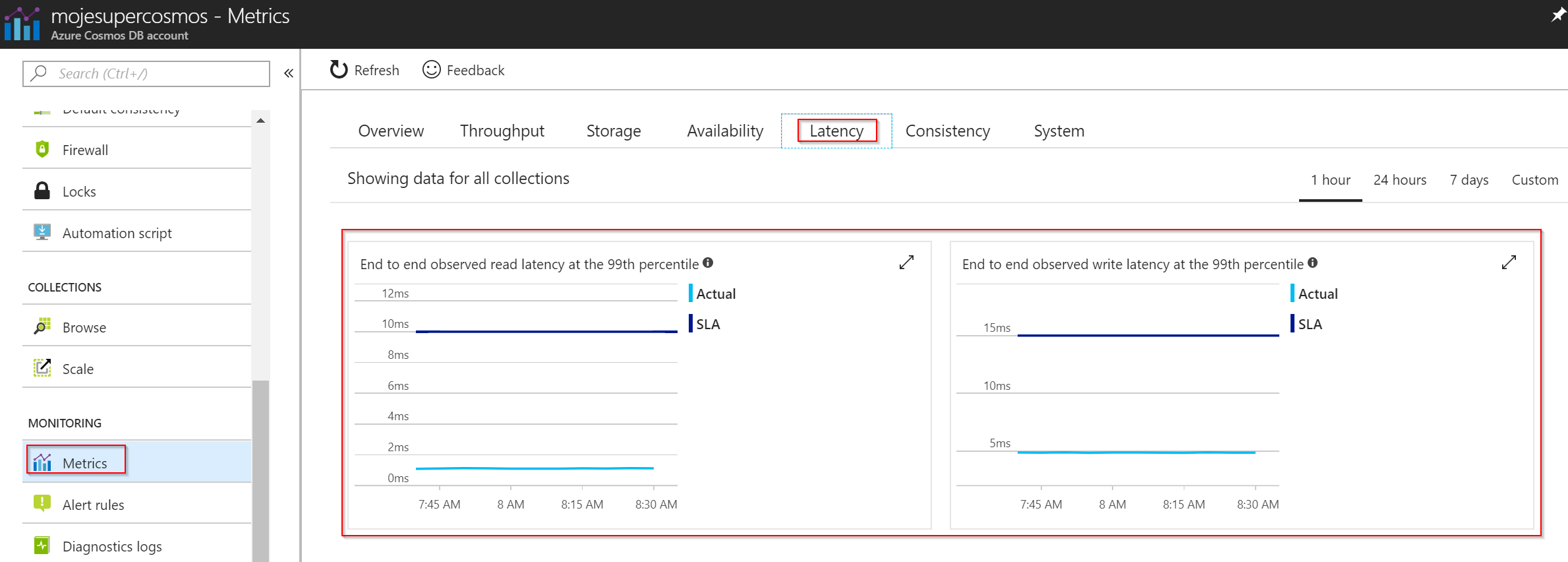
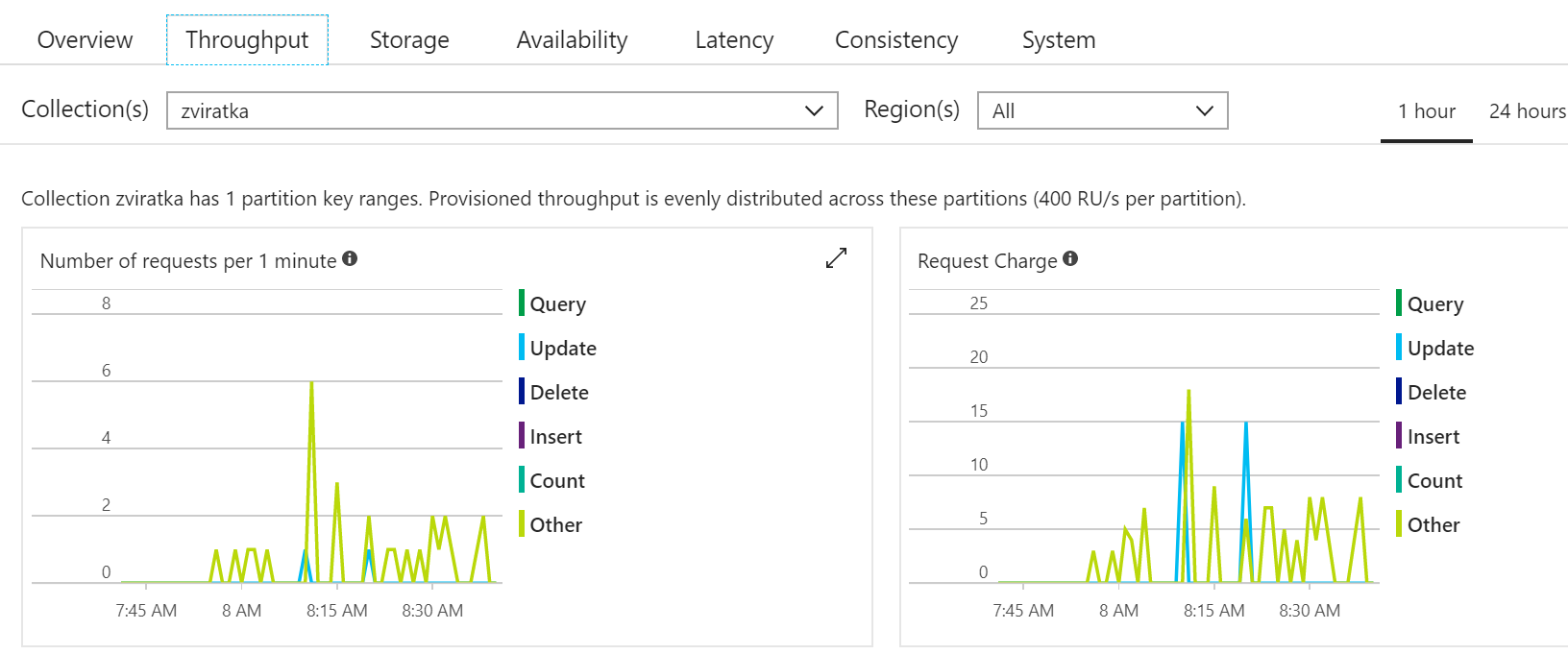
Jak to bylo s výkonností a spotřebou RU?
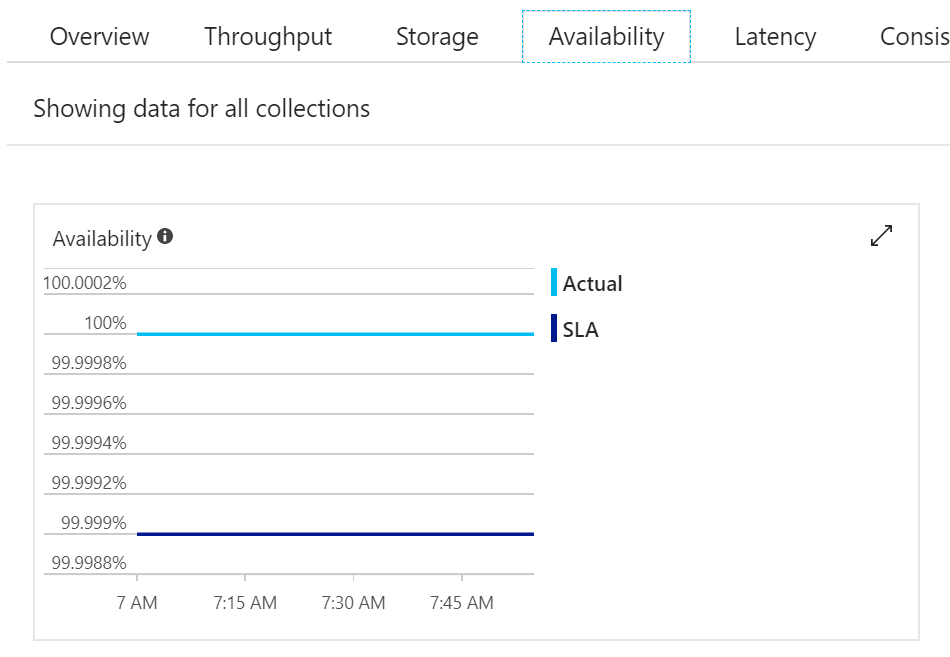
A jak Microsoft dostál SLA na na dostupnost - během mé hodiny samozřejmě výpadek nebyl, ale je skvělé, jak je všechno transparentní a sami se můžete přesvědčit na vlastních databázích.
Cosmos DB je databáze jako služba - velmi výkonná a rychlá, s SLA na výkon, latenci, konzistenci i dostupnost, lze ji globálně distribuovat. Pokud preferujete Mongo DB API, snadno ho s Cosmos DB použijete. Dnes jsme nepotřebovali žádné specifické knihovny - všechny SDK a nástroje byly standardní Mongo. To je síla multi-model a multi-API databáze Cosmos DB. Zkuste si ji!