Serverless znamená, že nemusíte přemýšlet o kapacitě. Platíte za jednotlivá spuštění svého kódu z hlediska času zpracování a použité paměti. Oproti třeba Application Services (PaaS), kde musíte přemýšlet o počtech zdrojů v servisní plánu a řešit jejich případné škálování, u Azure Functions je to vlastnost samotné platformy a vás to nemusí trápit. Pojďme to vyzkoušet a trochu se u toho podívat Azure Functions pod kapotu.
Zátěžový test
Nejdřív si připravme HTTP funkci, na které bude simulovat vysokou zátěž. Půjde o funkci, která na vstupu přijme řetězec a vrátí jeho sha256 hash. Nicméně to na serveru neudělá moc velkou zátěž, tak tu hash (zbytečně) uděláme 5000x při každém spuštění, abychom mu dali trochu zabrat. Kód bude vypadat takhle:
using System.Net;
using System.Security.Cryptography;
using System.Text;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log)
{
dynamic data = await req.Content.ReadAsAsync<object>();
string stringToHash = data?.stringToHash;
StringBuilder sb = new StringBuilder();
foreach (byte b in GetHash(stringToHash))
sb.Append(b.ToString("X2"));
string hashResult = sb.ToString();
return stringToHash == null
? req.CreateResponse(HttpStatusCode.BadRequest, "Please pass a stringToHash on the query string or in the request body")
: req.CreateResponse(HttpStatusCode.OK, hashResult);
}
public static byte[] GetHash(string inputString)
{
HashAlgorithm algorithm = SHA256.Create();
for (int i = 1; i <= 5000; i++)
{
algorithm.ComputeHash(Encoding.UTF8.GetBytes(inputString));
}
return algorithm.ComputeHash(Encoding.UTF8.GetBytes(inputString));
}
Při vytváření Function ji napojíme na Application Insights, abychom přijímali informaci o každém requestu. Důvodem je, že se chceme mrknout pod kapotu a v tomto logu bude cloud_RoleInstance, tedy GUID nodu! V klasickém PaaS modelu máte servisní plán a v něm jsou instance, na kterých se kód spouští (a to v několika paralelních vláknech). V Azure Functions je to podobné, ale ty přidělené zdroje neřídíte a neřešíte. Přesto bude zajímavé zjistit jak s nimi budou Azure Functions při zátěži hospodařit.
Pro simulace zátěže zvolím Load Test ve Visual Studio Team Services, kdy do funkce bude masivně bušit 2000 uživatelů současně. Namíříme test na mojí funkci:
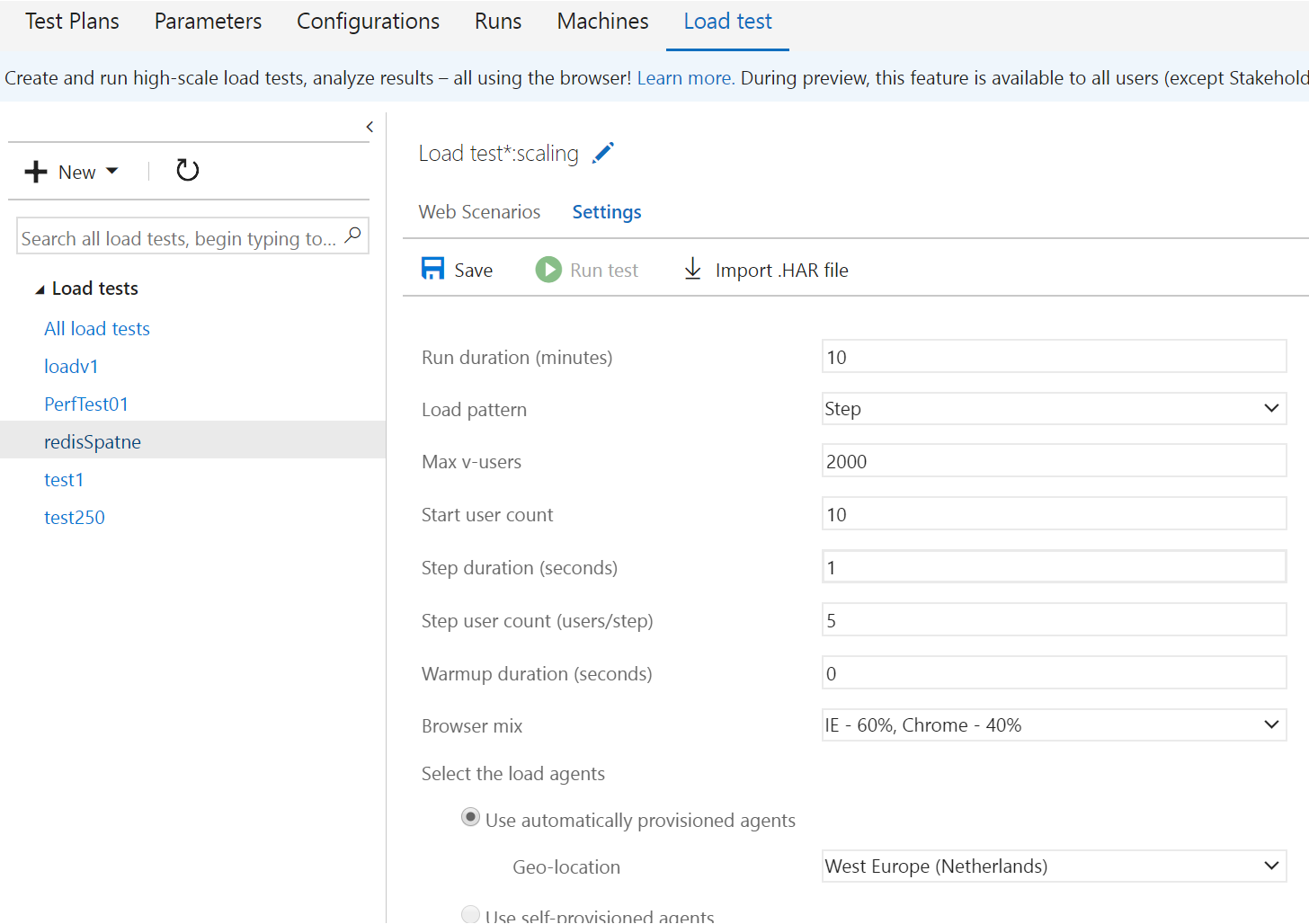
Test budu provádět tak, že budu postupně přitáčet. Každou vteřinu přidám 5 uživatelů až do maximální počtu 2000 a test takto poběží 10 minut.
Výsledky testu
Po dokončení testu se podíváme na celkové výsledky.
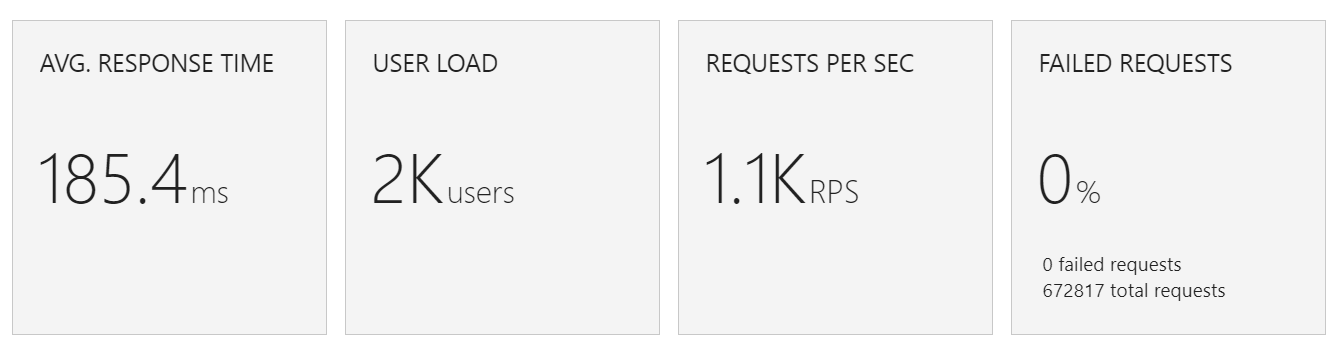
Celkově funkce zpracovala 672 817 requestů, což je slušný počet na deset minut :) Průměrná latence byla 185,4 ms a především - nic nám nepopadalo na zem!
Jak se dokázala funkce vypořádat s nárůstem požadavků?
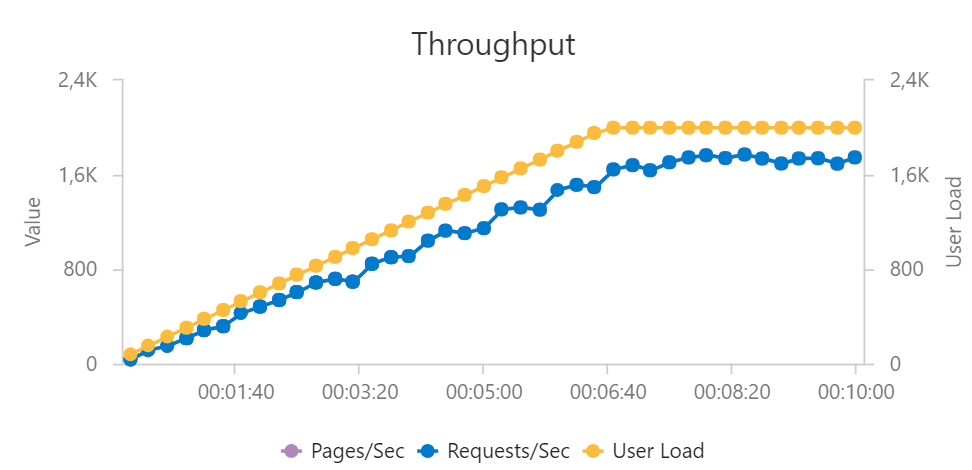
Výkon funkce hezky kopíruje nárůst uživatelů, Azure Functions tedy dokázaly velmi dobře přitáčet ve svém výkonu.
Co se dělo s latencí? Funkce byla pod neustálým stresem, protože požadavky stále rostly, takže musela pořád reagovat na přetížení a příslušné zvyšování latence. Reagovala opravdu dost rychle, takže samozřejmě latence kolísala, ale držela se stále na velmi dobré úrovni vzhledem k dramatické změně zátěže. Po sedmi minutách už můj test další uživatele nepřidával a tak si Azure Functions mohla trochu oddechnout a dokonvergovat do vhodného množství přiřazených zdrojů. To vidíme na snížení latence a stabilizaci odchylek.
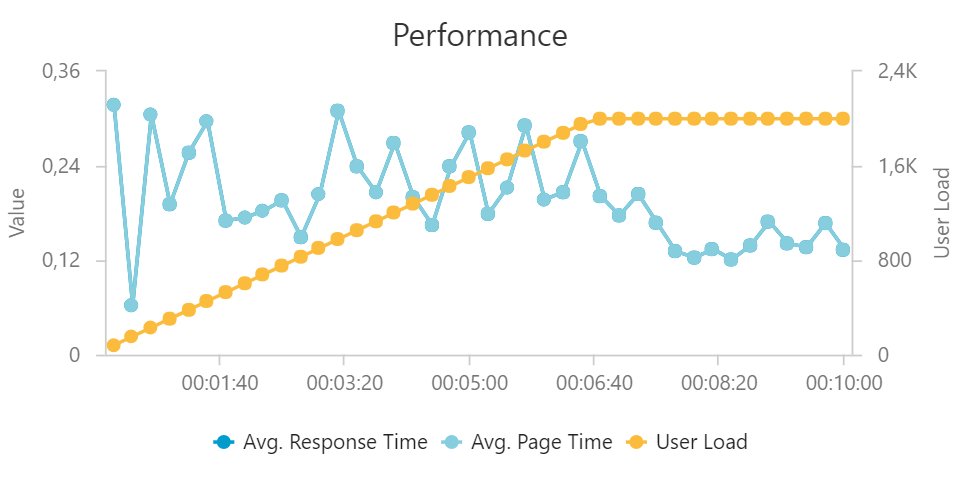
Průměrná latence mi připadá vzhledem k situaci (a 5000 hashování při každém volání) velmi dobrá, ale nevypovídá nic o rozptylu (co když bylo hodně uživatelů, co trpěli velkou latencí?). Na pomoc si beru Application Insights a koukneme se na rozložení latence.
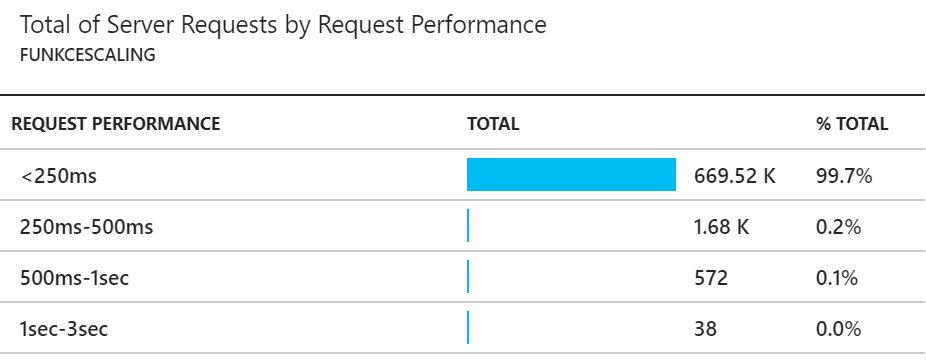
99,7% všech requestů mělo latenci pod 250ms, což je myslím perfektní výsledek! Naprostá většina zbytku se vešla do půl vteřiny a jen velmi málo bylo víc a stále to bylo do vteřiny. Počet requestů s latencí mezi 1 a 3 vteřinami je vzhledem k počtu naprosto zanedbatelný. Za mne - dobrá práce.
Pohled pod kapotu
Zátěž byla velka a zpracování u každého requestu docela náročné (5000x hash). Pokud bych chtěl něco takového ustát ve standardním servisním plánu, kolik nodů bych potřeboval? Jak se Azure Functions rozhodovala o přidání nodů do podvozku a na kolik se dostala? Tuhle informaci najdeme v Application Insights logu. Použijeme tenhle dotaz:
requests | project cloud_RoleInstance, timestamp | summarize dcount(cloud_RoleInstance) by bin(timestamp, 1m) | render timechart
Tady je výsledný graf:
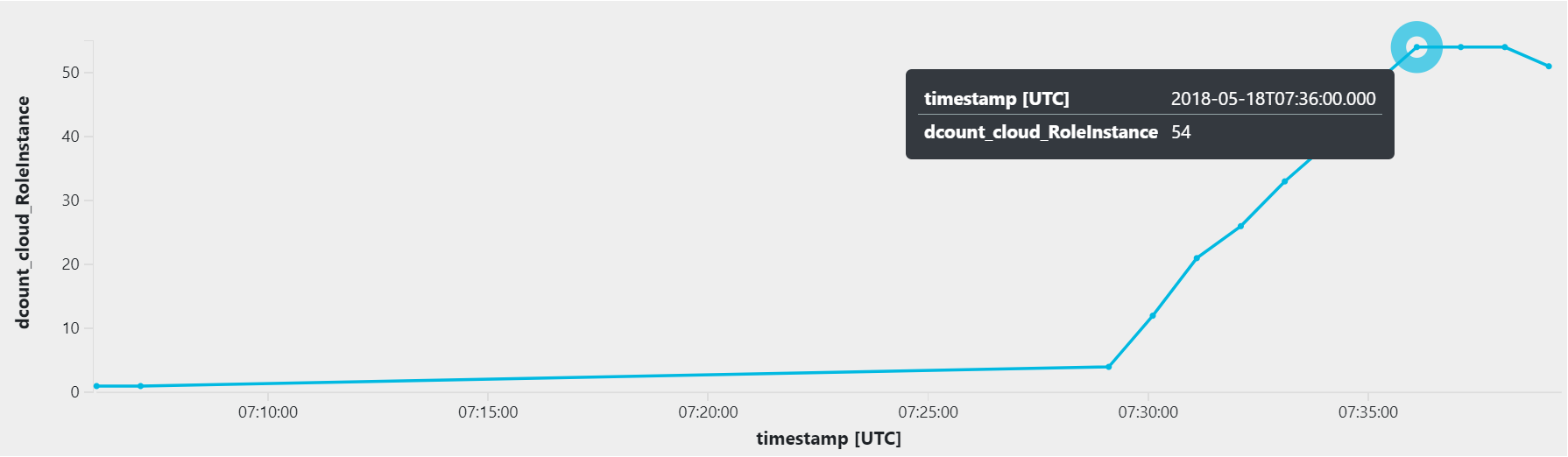
Azure Functions během asi 7 minut vyškálovaly podvozek až na 54 nodů (serverů)!
Tak vidíte. Žádná magie, jen dobře vyladěný stroj. Kapotu můžete nechat zaklapnutou a nic z toho fungování vás nemusí trápit. Nicméně pro mě je krásné a inspirativní se podívat jak to tam dole ve strojovně vypadá. Co pro vás? Napadlo by vás před pěti lety, že věci můžou takhle fungovat a to tak, že je to opakovatelné, stabilní a zasaditelné do formy hotového produktu?