Obrovskou výhodou Kusto je, že dokáže dobře sloužit i pokud data nemá uložena v pro sebe ideálním formátu. Perfektní je, když dostává krásně strukturované logy, které si rovnou na vstupu parsuje a Kusto ukládá zaindexované. To je typický příklad Application Insights, Log Analytics agentů pro sběr síťových informací z VM, chybějící Updaty, inventory, Kubernetes Pody a nebo CEF agent pro příjem bezpečnostních zpráv. Nicméně občas to takhle nejde a musíme uložit data ve formátu, který není takhle ideální. Například je to výpis z obrazovky nebo Syslog hláška s proprietární strukturou místo CEF, JSON uložený jako text (v poli message) a tak podobně. Kusto s daty ale umí dělat spoustu věcí, takže sice možná bude dotaz trvat o pár vteřin déle, ale nic není ztraceno - parsovat můžete v “query time”.
Podívejme se dnes na pár transformací a parsování.
Vypočítaný sloupec
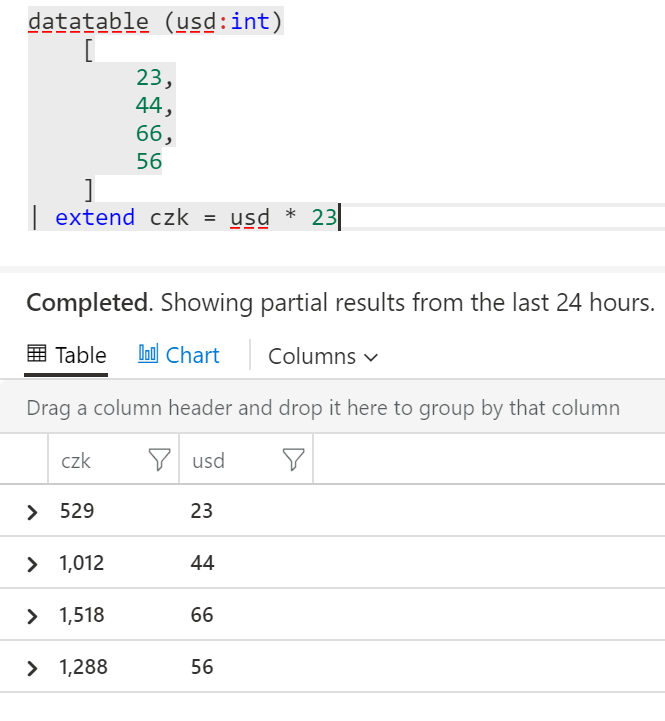
Začneme tím, co už jsme použili mnohokrát. Přes extend můžeme přidat vlastní sloupeček v libovolném formátu. Tak například:
datatable (usd:int)
[
23,
44,
66,
56
]
| extend czk = usd * 23
Pivot
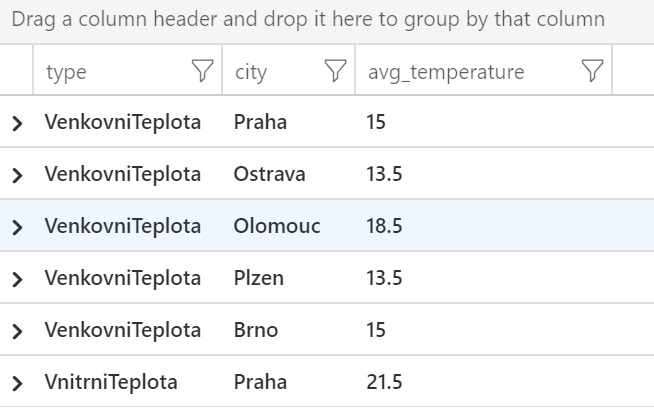
Mějme následující tabulku představují jednotlivá teplotní měření v různých městech s tím, že jeden senzor měří vnitřní teplotu a druhý venkovní. Rádi bychom spočítali průměrnou vnitřní a venkovní teplotu za jednotlivá města. Toho můžeme dosáhnout sumarizací, jak už jsme v této sérii článků udělali mnohokrát.
datatable (measurementid:string, type:string, city:string, temperature:int)
[
"a01", "VenkovniTeplota", "Praha", 16,
"a02", "VenkovniTeplota", "Ostrava", 14,
"a03", "VenkovniTeplota", "Olomouc", 18,
"a04", "VenkovniTeplota", "Plzen", 13,
"a05", "VenkovniTeplota", "Brno", 12,
"a06", "VnitrniTeplota", "Praha", 22,
"a07", "VnitrniTeplota", "Ostrava", 21,
"a08", "VnitrniTeplota", "Olomouc", 22,
"a09", "VnitrniTeplota", "Plzen", 20,
"a10", "VnitrniTeplota", "Brno", 21,
"b01", "VenkovniTeplota", "Praha", 14,
"b02", "VenkovniTeplota", "Ostrava", 13,
"b03", "VenkovniTeplota", "Olomouc", 19,
"b04", "VenkovniTeplota", "Plzen", 14,
"b05", "VenkovniTeplota", "Brno", 18,
"b06", "VnitrniTeplota", "Praha", 21,
"b07", "VnitrniTeplota", "Ostrava", 21,
"b08", "VnitrniTeplota", "Olomouc", 20,
"b09", "VnitrniTeplota", "Plzen", 22,
"b10", "VnitrniTeplota", "Brno", 22,
]
| summarize avg(temperature) by type, city
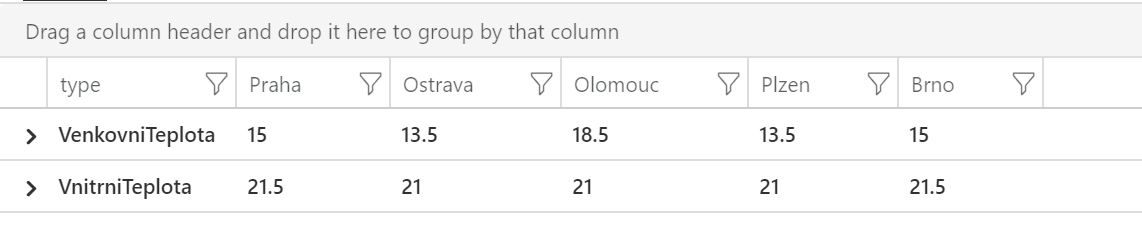
Jsou to sice ty informace, co hledáme, ale mohlo by to být přehlednější. Konkrétně bychom se potřebovali z řádků dostat do sloupců. Místo odlišování vnitřní/vnější a města oboje v řádcích, by bylo lepší mít vnitřní/vnější v řádcích a města ve sloupcích (nebo naopak). Na to použijeme pivot.
datatable (measurementid:string, type:string, city:string, temperature:int)
[
"a01", "VenkovniTeplota", "Praha", 16,
"a02", "VenkovniTeplota", "Ostrava", 14,
"a03", "VenkovniTeplota", "Olomouc", 18,
"a04", "VenkovniTeplota", "Plzen", 13,
"a05", "VenkovniTeplota", "Brno", 12,
"a06", "VnitrniTeplota", "Praha", 22,
"a07", "VnitrniTeplota", "Ostrava", 21,
"a08", "VnitrniTeplota", "Olomouc", 22,
"a09", "VnitrniTeplota", "Plzen", 20,
"a10", "VnitrniTeplota", "Brno", 21,
"b01", "VenkovniTeplota", "Praha", 14,
"b02", "VenkovniTeplota", "Ostrava", 13,
"b03", "VenkovniTeplota", "Olomouc", 19,
"b04", "VenkovniTeplota", "Plzen", 14,
"b05", "VenkovniTeplota", "Brno", 18,
"b06", "VnitrniTeplota", "Praha", 21,
"b07", "VnitrniTeplota", "Ostrava", 21,
"b08", "VnitrniTeplota", "Olomouc", 20,
"b09", "VnitrniTeplota", "Plzen", 22,
"b10", "VnitrniTeplota", "Brno", 22,
]
| project-away measurementid
| evaluate pivot(city, avg(temperature))
Kondicionály v hodnotách
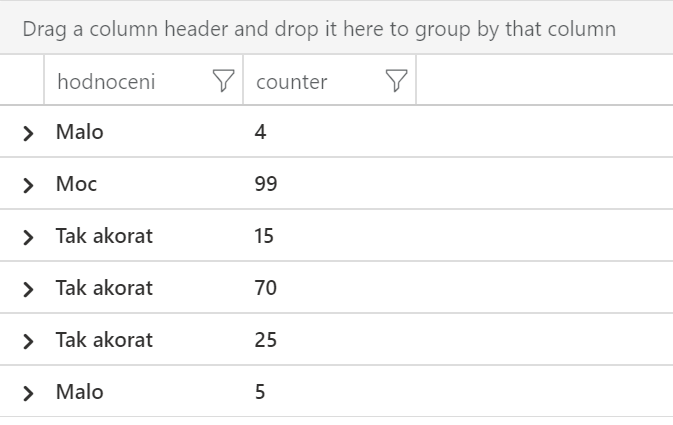
Kusto dovoluje při vytváření sloupce použít if logiku. Tak například mějme nějaké telemetrické odečty (třeba obsazenost paměti) a kromě čísla budeme chtít vytvořit sloupeček říkající, jestli je to málo, moc nebo tak akorát. Funkce iff má tři argumenty - podmínku dávající true nebo false, hodnotu pokud to vyšlo true a hodnotu pokud false. Pokud je číslo menší jak 10, napíšeme Malo, v opačném případě dosadíme výstup dalšího vnořeného iff. V něm vracíme buď Tak akorat nebo Moc.
datatable(counter:int)
[
4,99,15,70,25,5,78,64,32,44,1,93,75
]
| extend hodnoceni =
iff(counter<10, "Malo",
iff(counter>=10 and counter < 90, "Tak akorat", "Moc"))
Cesta k souboru
Kusto má připravený parser na zkoumání cesty k souboru a to jak pro formát Windows tak Linux. V následujícím zápisu najdete před Windows řetězcem zavináč. Jde o to, že \ je v Kusto escape znak a tím, že dáme před uvozovky zavináč mu řekneme, ať to bere tak jak to je.
datatable(cesta:string)
[
@"C:\windows\soubor.txt",
"/home/tomas/soubor.txt"
]
| extend parsed = parse_path(cesta)
| extend filename=parsed.Filename
Vidíme, že parser vrací různá políčka typu soubor, přípona a tak podobně.


URL
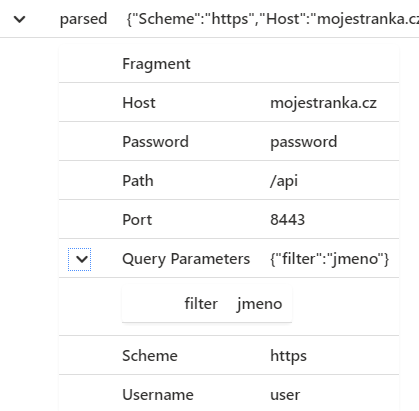
Další připravený parser je na URL. Vyzkoušíme, co vrací.
datatable(url:string)
[
"https://user:password@mojestranka.cz:8443/api?filter=jmeno"
]
| extend parsed = parse_url(url)
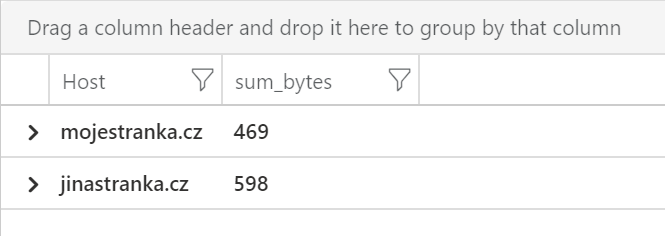
Představme si třeba, že máme log z reverse proxy, který ukazuje celou volanou URL a k tomu počet přenesených bytů. Možná potřebujeme udělat sumarizaci podle host.
datatable(url:string, bytes:int)
[
"https://mojestranka.cz:8443/api?filter=jmeno", 100,
"https://mojestranka.cz:8443/blog", 70,
"https://mojestranka.cz:8443/user", 77,
"https://mojestranka.cz:8443/api?filter=score", 90,
"https://mojestranka.cz:8443/index.html", 132,
"https://jinastranka.cz:8443/api?filter=jmeno", 130,
"https://jinastranka.cz:8443/login", 111,
"https://jinastranka.cz:8443/blog", 120,
"https://jinastranka.cz:443/users", 105,
"https://jinastranka.cz:443/api/posts", 132,
]
| summarize sum(bytes) by tostring(parse_url(url).Host)
Parsování JSON
Možná jste v situaci, kdy máte data v JSON, ale uložena jsou jako jeden řetězec. Jak se to může stát? Logovací agent si obvykle dává záležet, aby data posílal přes API strukturovaně. Ale možná jde o syslog server přijímající data z různých systémů (třeba síťových prvků) a agent pak posílá data ve struktuře čas, id stroje a message a tu může zdrojový systém posílat jako JSON (nebo XML či CSV - Kusto má parsery i na ně). Pak máme celý JSON v jednom textovém poli. Druhý příklad může vypadat divně, ale viděl jsem ho už několikrát. Máte systém, který posílá data jako strukturovaný JSON, jenže tento systém do nějakého políčka uloží jiný JSON. Tak například aplikace zaloguje nějakou událost (strukturovaně v JSON) a v té do jednoho z políček vloží jiný JSON pro debug účely (například co mu vrátila jiná mikroslužba). Jasně - mohla by to udělat tak, že provede merge, ale to neplní účel debugu. Když bude ten vnořený JSON neplatný (a kvůli tomu mám problém v aplikaci), tak výsledkem bude, že celý JSON je neplatný a nezaloguje se správně - je tedy lepší to skutečně vložit jako escapovaný řetězec.
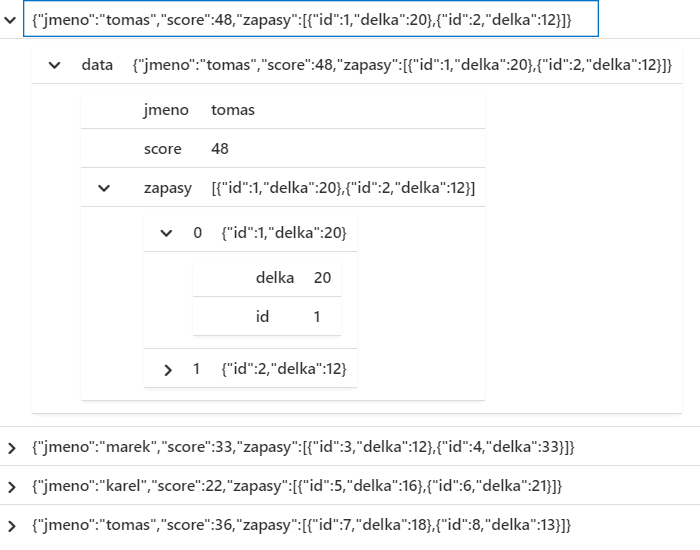
Náš příklad bude jednoduchý JSON ve sloupečku message. Při vytváření tabulky příkazem datatable musím escapovat uvozovky.
datatable (message:string)
[
"{\"jmeno\":\"tomas\",\"score\":48, \"zapasy\":[{\"id\": 1, \"delka\":20}, {\"id\": 2, \"delka\":12}]}",
"{\"jmeno\":\"marek\",\"score\":33, \"zapasy\":[{\"id\": 3, \"delka\":12}, {\"id\": 4, \"delka\":33}]}",
"{\"jmeno\":\"karel\",\"score\":22, \"zapasy\":[{\"id\": 5, \"delka\":16}, {\"id\": 6, \"delka\":21}]}",
"{\"jmeno\":\"tomas\",\"score\":36, \"zapasy\":[{\"id\": 7, \"delka\":18}, {\"id\": 8, \"delka\":13}]}",
"{\"jmeno\":\"milan\",\"score\":51, \"zapasy\":[{\"id\": 9, \"delka\":22}, {\"id\": 10, \"delka\":31}]}",
"{\"jmeno\":\"marek\",\"score\":52, \"zapasy\":[{\"id\": 11, \"delka\":21}, {\"id\": 12, \"delka\":35}]}"
]
| project data=parse_json(message)
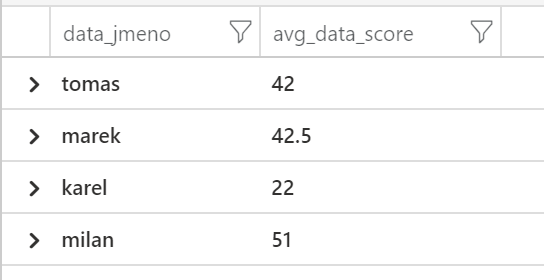
S políčky pak můžeme normálně pracovat tečkovou syntaxí, například spočítat průměrné score podle jména. Všimněte si ale, že JSON neobsahuje definici datových typů a parser se je nepokouší odhadnout - políčka budou dynamická (“beztypová”). Proto pro sumarizaci a výpočty musíme explicitně určit typ.
datatable (message:string)
[
"{\"jmeno\":\"tomas\",\"score\":48, \"zapasy\":[{\"id\": 1, \"delka\":20}, {\"id\": 2, \"delka\":12}]}",
"{\"jmeno\":\"marek\",\"score\":33, \"zapasy\":[{\"id\": 3, \"delka\":12}, {\"id\": 4, \"delka\":33}]}",
"{\"jmeno\":\"karel\",\"score\":22, \"zapasy\":[{\"id\": 5, \"delka\":16}, {\"id\": 6, \"delka\":21}]}",
"{\"jmeno\":\"tomas\",\"score\":36, \"zapasy\":[{\"id\": 7, \"delka\":18}, {\"id\": 8, \"delka\":13}]}",
"{\"jmeno\":\"milan\",\"score\":51, \"zapasy\":[{\"id\": 9, \"delka\":22}, {\"id\": 10, \"delka\":31}]}",
"{\"jmeno\":\"marek\",\"score\":52, \"zapasy\":[{\"id\": 11, \"delka\":21}, {\"id\": 12, \"delka\":35}]}"
]
| project data=parse_json(message)
| summarize avg(toint(data.score)) by tostring(data.jmeno)
Parsování volného textu s Regex
Na závěr si nechme horší případ, který je velmi časý pro Syslog nebo logy ze síťových prvků. Není to ani JSON, ani XML, ani CSV a dokonce ani CEF (textový formát určený pro bezpečnostní logy přes Syslog), ale proprietární syntaxe. Něco se odděluje mezerou, něco pipe, něco dvojtečkou, zkrátka může to být jakkoli.
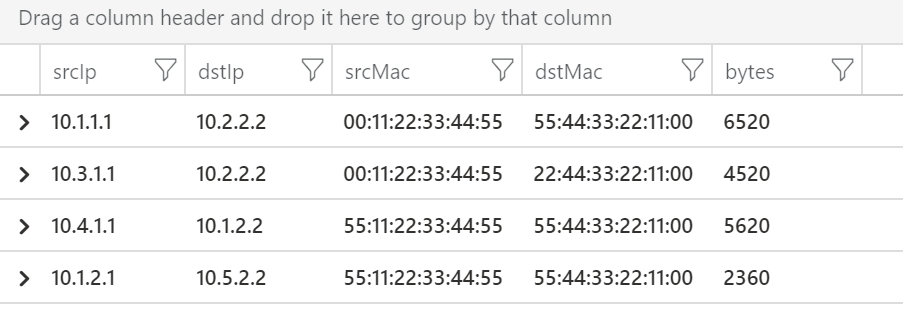
Začneme jednodušším příkladem, který často vídám u logů z firewallů a podobných zařízení. Jeho výhodou je, že má explicitní strukturu jako součást textu. Spotřebovává to znaky navíc, ale z pohledu parsování to je rozhodně lepší varianta. Každý budoucí sloupec tedy v textu najdeme ve formátu srcIp=10.1.1.1, stačí nám tedy najít srcIp= a vzít si celou hodnotu do další mezery. Asi by to šlo i jednodušší syntaxí, ale já na tohle vždy doporučuji naučit se RegEx (regular expression), protože ta je univerzální a daleko mocnější. Potřebujeme tedy najít řetězec srcIp= a hned po něm jsou znaky, které chceme zachytit (group), což se dělá závorkou. V té je symbol pro všechny znaky (tečka) v libovolném počtu (hvězdička) a pouze do prvního výskytu (otázník) následované mezerou (lomeno s), která je už ale mimo závorky (mezeru zachytit nechceme). Totéž pro všechny ostatní kromě bytes, které jsou poslední hodnota a nekončí mezerou, ale koncem zprávy (dolar). Příkaz extract tedy má tři vstupní hodnoty - regex, číslo skupiny (my máme jen jednu) a vstupní řetězec.
datatable(message:string)
[
"srcIp=10.1.1.1 dstIp=10.2.2.2 srcMac=00:11:22:33:44:55 dstMac=55:44:33:22:11:00 bytes=6520",
"srcIp=10.3.1.1 dstIp=10.2.2.2 srcMac=00:11:22:33:44:55 dstMac=22:44:33:22:11:00 bytes=4520",
"srcIp=10.4.1.1 dstIp=10.1.2.2 srcMac=55:11:22:33:44:55 dstMac=55:44:33:22:11:00 bytes=5620",
"srcIp=10.1.2.1 dstIp=10.5.2.2 srcMac=55:11:22:33:44:55 dstMac=55:44:33:22:11:00 bytes=2360"
]
| project srcIp = extract(@"srcIp=(.*?)\s", 1, message),
dstIp = extract(@"dstIp=(.*?)\s", 1, message),
srcMac = extract(@"srcMac=(.*?)\s", 1, message),
dstMac = extract(@"dstMac=(.*?)\s", 1, message),
bytes = extract(@"bytes=(.*?)$", 1, message)
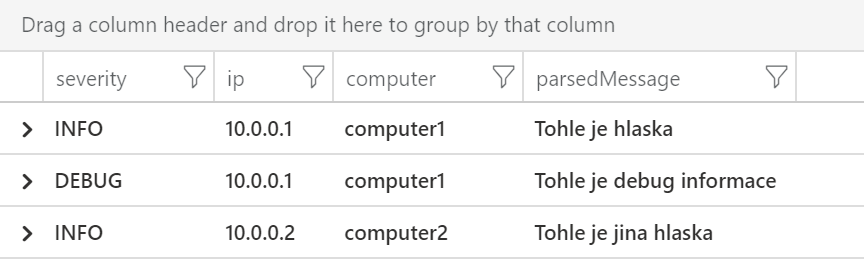
Asi nejhorší je situace, kdy struktura je implicitní a jde o nějaké pořadí apod. Tak například tento stroj loguje tak, že nejprve píše severitu oddělenou dvojtečkou, pak IP adresu stroje, název počítače (oboje odděleno mezerou) a pak hlášku, v které ale mohou být mezery. Protože záleží na pořadí, musíme udělat regex, který jedním šmahem vytípne všechno (budeme mít tedy víc group, víc závorek). První zachycení je začátek řetězce (stříška), libovolný znak libovolněkrát a zakončeno dvojtečkou s mezerou. Druhá skupina je tečka, hvězdička, otazník (zkrátka další slovo), pak ještě další a čtvrtá skupina je cokoli (zbytek řetězce). První možnost je použít extract_all a projet to najednou, což nám vrátí pole hodnot, což pak můžeme převést na sloupce.
datatable(message:string)
[
"INFO: 10.0.0.1 computer1 Tohle je hlaska",
"DEBUG: 10.0.0.1 computer1 Tohle je debug informace",
"INFO: 10.0.0.2 computer2 Tohle je jina hlaska",
]
| extend parsed = extract_all(@"(^.*):\s(.*?)\s(.*?)\s(.*)", message)
| project severity=parsed[0][0], ip=parsed[0][1], computer=parsed[0][2], parsedMessage=parsed[0][3]
Druhá možnost je jet sloupeček po sloupečku, ale regex musíme nechat stejný a mít v něm skupiny (nemůžeme matchovat každý zvlášť, jak jsme to dělali u srcIp=), ale druhý argument je číslo skupiny.
datatable(message:string)
[
"INFO: 10.0.0.1 computer1 Tohle je hlaska",
"DEBUG: 10.0.0.1 computer1 Tohle je debug informace",
"INFO: 10.0.0.2 computer2 Tohle je jina hlaska",
]
| project severity = extract(@"(^.*):\s(.*?)\s(.*?)\s(.*)", 1, message),
ip = extract(@"(^.*):\s(.*?)\s(.*?)\s(.*)", 2, message),
computer = extract(@"(^.*):\s(.*?)\s(.*?)\s(.*)", 3, message),
parsedMessage = extract(@"(^.*):\s(.*?)\s(.*?)\s(.*)", 4, message)
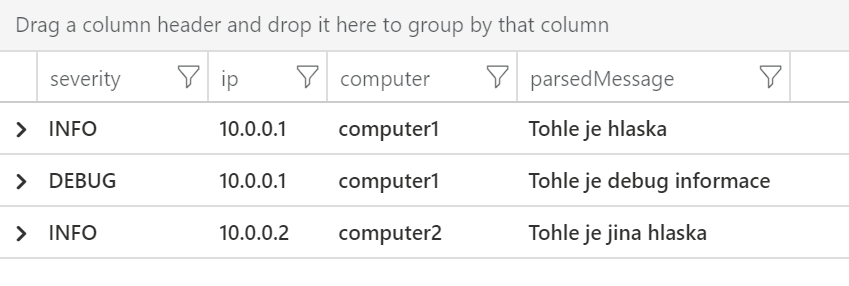
A máme to.
Dnes jsme si ukázali, že to, že máme data nějakým způsobem uložena ještě neznamená, že s nimi nemůžeme nic dalšího dělat. Sloupečky se dají vytvářet, otáčet a hodnoty parsovat ať už jde o jednoduché věci typu URL, strukturované formáty typu JSON, XML nebo CSV, nebo nám nezbyde, než na to jít textově a přes regex z toho vydolovat co potřebujeme.