V minulém díle jsem zkoumal nové vlastnosti Log Analytics pro Azure Monitor a Microsoft Sentinel, které mohou výrazně prolevnit celé řešení - basic logs, archive tier, search jobs a restore. Dnes si to vyzkoušíme prakticky.
V následujících textech budu pro některé operace používat přímo API. GUI pro nastavování archivací a search joby existuje v preview v rámci Sentinelu a nevím jak to bude ve finální podobě - API ale předpokládám zůstane, takže se na něj zaměřím.
Jedna z tabulek, která mě hodně zajímá, jsou logy z kontejnerů. Těch totiž může být hodně a nativní monitoring AKS tak mohou prodražovat, přitom nad nimi typicky nepotřebuji dělat nějaké složité analytické operace (na rozdíl třeba od bezpečnostních logů). Vytvořím tedy Azure Kubernetes Service s Azure Monitor a spustím kontejner, který mi bude generovat logy.
# Create resource group
az group create -n logs -l westeurope
# Create Log Analytics workspace
export workspaceName=tomaslogs$RANDOM
az monitor log-analytics workspace create -g logs -n $workspaceName
# Create AKS
export workspaceId=$(az monitor log-analytics workspace show -g logs -n $workspaceName --query id -o tsv)
az aks create -g logs -n logsaks -l westeurope -c1 -x -s Standard_B2s \
-a monitoring --workspace-resource-id $workspaceId
az aks get-credentials -g logs -n logsaks --admin --overwrite-existing
# Start log generating app
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: loggen
spec:
selector:
matchLabels:
app: loggen
template:
metadata:
labels:
app: loggen
spec:
containers:
- name: loggen
image: ubuntu
command:
- "/bin/bash"
args:
- "-c"
- "while true; do echo type\$(expr \$RANDOM % 5): ip=1.1.1.\$(expr \$RANDOM % 254) port=\$(expr \$RANDOM % 65554); sleep 2; done"
EOF
Dalším krokem teď bude tabulku ContainerLog přepnout z výchozího analytického tieru do režimu basic. Ten má v ceně retenci 8 dní a to je pro mě málo, nicméně prodloužit ji, na rozdíl od analytického tieru, nemůžu. Nicméně můžu použít archivní tier. To udělám tak, že nastavím parametr totalRetentionInDays a vše nad 8 dní bude v archivu.
# Configure ContainerLogs table as Basic and enable archive for 180 days
export url="https://management.azure.com$workspaceId/tables/ContainerLog?api-version=2021-12-01-preview"
az rest --method patch --url $url --headers "Content-Type=application/json" \
-b '{
"properties": {
"plan": "Basic",
"totalRetentionInDays": 180
}
}'
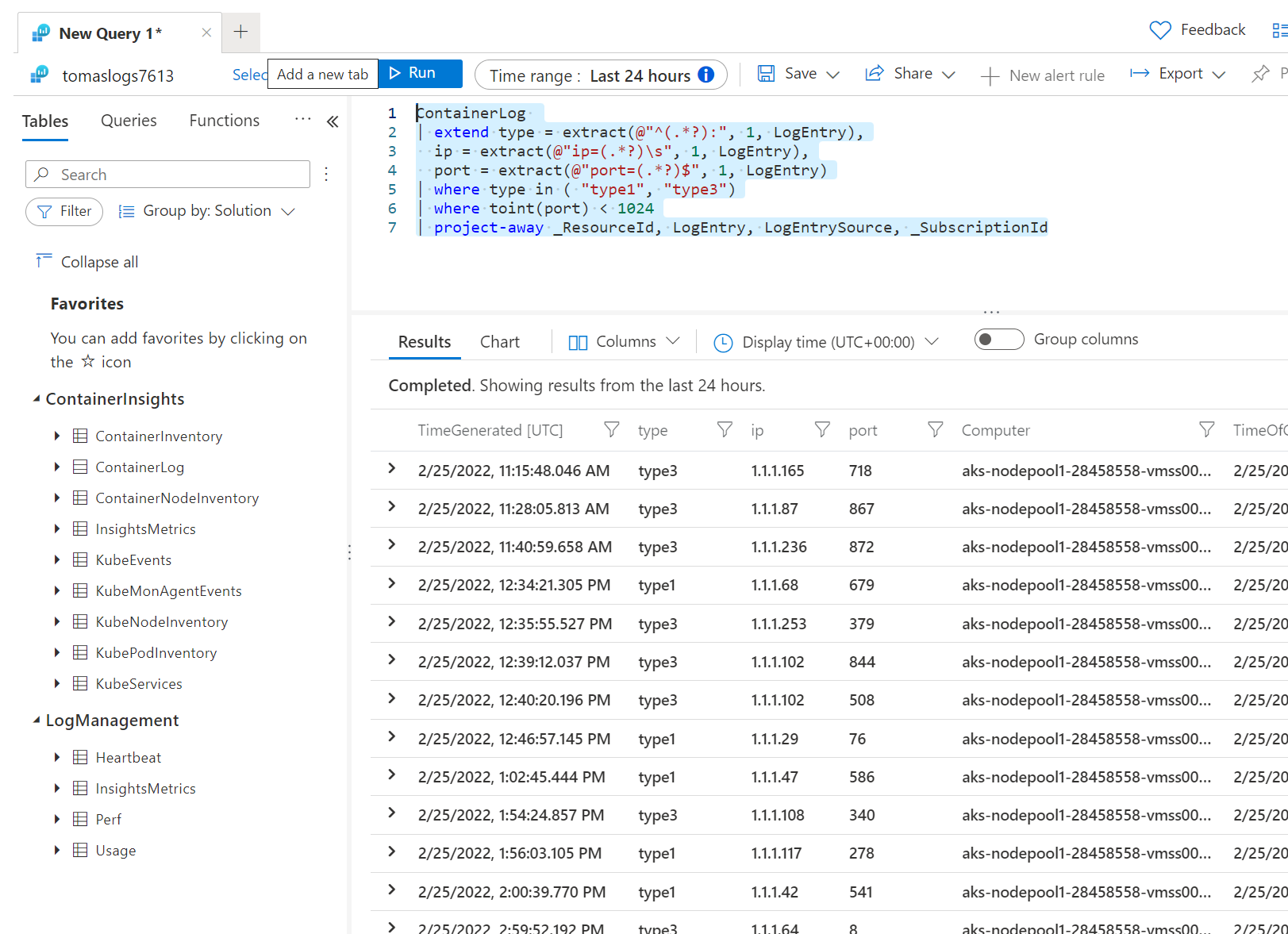
V basic jsem schopen efektivně vyhledávat. Zkusím například query, které nejprve přidá nový nové sloupečky, které vzniknou regex parsováním logu, následně podle těchto ad-hoc vytvořených sloupečků budu filtrovat na množinu typů a porty menší než 1024. Na závěr odejmu z výstupu sloupce, které mě nezajímají.
ContainerLog
| extend type = extract(@"^(.*?):", 1, LogEntry),
ip = extract(@"ip=(.*?)\s", 1, LogEntry),
port = extract(@"port=(.*?)$", 1, LogEntry)
| where type in ( "type1", "type3")
| where toint(port) < 1024
| project-away _ResourceId, LogEntry, LogEntrySource, _SubscriptionId
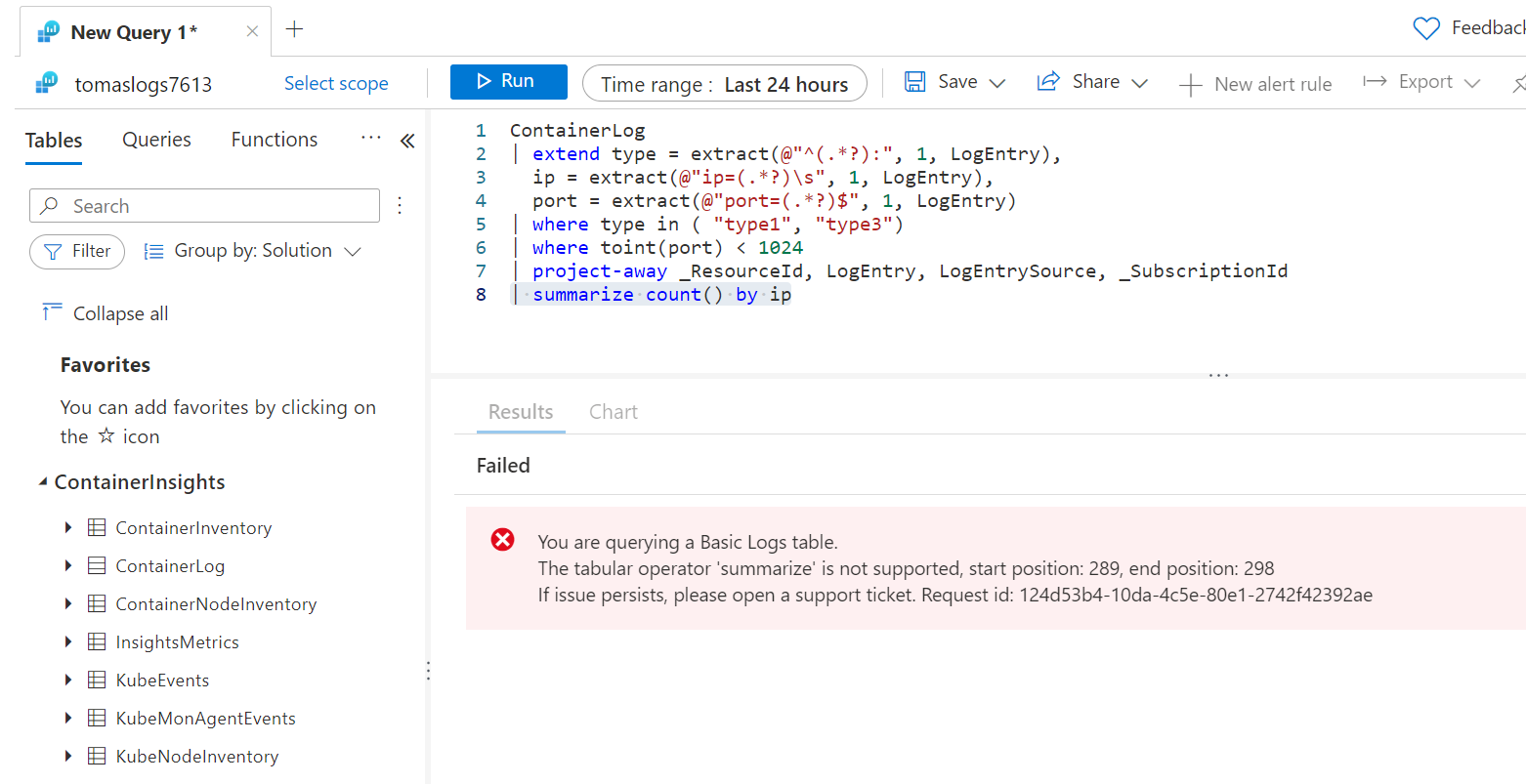
Nicméně pokud se pokusím o něco analytického, nebude to možné. Například zkusím jednoduše sumarizovat počet událostí za jednotlivé ip.
ContainerLog
| extend type = extract(@"^(.*?):", 1, LogEntry),
ip = extract(@"ip=(.*?)\s", 1, LogEntry),
port = extract(@"port=(.*?)$", 1, LogEntry)
| where type in ( "type1", "type3")
| where toint(port) < 1024
| project-away _ResourceId, LogEntry, LogEntrySource, _SubscriptionId
| summarize count() by ip
Protože v basic (a také v archivu) platím za to, jak velký objem dat musí engine projít, bude zajímavé o dotazu získat nějakou statistiku. V rámci API si stačí statistické informace vyžádat při zadávání dotazu.
# When quering we can requests stats to understand volume of scanned data
export workspaceCustomer=$(az monitor log-analytics workspace show -g logs -n $workspaceName --query customerId -o tsv)
az rest -u "https://api.loganalytics.io/v1/workspaces/$workspaceCustomer/search?timespan=P1D" \
--headers "Content-Type=application/json" \
--headers "Prefer=include-statistics=true" \
--method post \
--body '{"query":"ContainerLog"}' \
| jq .statistics
Tohle je výstup.
{
"query": {
"datasetStatistics": [
{
"tableRowCount": 43087,
"tableSize": 14598614
}
],
"executionTime": 0.5937856,
"inputDatasetStatistics": {
"extents": {
"scanned": 1,
"scannedMaxDatetime": "2022-02-26T12:41:19.2909747Z",
"scannedMinDatetime": "2022-02-25T11:03:02.2175447Z",
"total": 1
},
"rows": {
"scanned": 36656,
"total": 36656
},
"rowstores": {
"scannedRows": 12323,
"scannedValuesSize": 4308574
},
"shards": {
"queriesGeneric": 1,
"queriesSpecialized": 0
}
},
"resourceUsage": {
"cache": {
"disk": {
"hits": 0,
"misses": 0,
"total": 0
},
"memory": {
"hits": 0,
"misses": 0,
"total": 0
},
"shards": {
"bypassbytes": 0,
"cold": {
"hitbytes": 0,
"missbytes": 0,
"retrievebytes": 0
},
"hot": {
"hitbytes": 682106,
"missbytes": 0,
"retrievebytes": 0
}
}
},
"cpu": {
"kernel": "00:00:00",
"totalCpu": "00:00:00.0468750",
"user": "00:00:00.0468750"
},
"memory": {
"peakPerNode": 104100080
},
"network": {
"crossClusterTotalBytes": 0,
"interClusterTotalBytes": 34897588
}
}
}
}
Přímé volání query, kdy dostáváme velmi rychle výsledek, je možné v basic a analytickém tier, ale archiv funguje jinak. Ten bude procházet studená data, která jsou uložena levněji (= pomaleji) a bude obcházet větší množství nodů a odpověď skládat. To co trvalo vteřiny, může teď trvat třeba minuty.
Dejme tedy tomu, že si připravím query na rozparsování zprávy na nové sloupce a v jednom z nich hledám “type2”.
ContainerLog
| extend type = extract(@"^(.*?):", 1, LogEntry),
ip = extract(@"ip=(.*?)\s", 1, LogEntry),
port = extract(@"port=(.*?)$", 1, LogEntry)
| where type == "type2"
| project-away _ResourceId, LogEntry, LogEntrySource, _SubscriptionId
Jak to funguje? Search job poběží na pozadí a výsledky bude ukládat do nové analytické tabulky, která musí mít příponu _SRCH. Použije se API na založení tabulky, které nově podporuje vlastnost searchResults, ve kterém jsem specifikoval výše uvedené query, potom limit (může být vhodná ochrana před nějakou chybou v zadání, protože nechci, aby výsledná tabulka, u které platím za ingesting, měla třeba 1 TB, to by stálo moc peněz) a časové okno hledání.
# Search job - parse and query type2 logs
export resultTable=type2logs
export url="https://management.azure.com$workspaceId/tables/${resultTable}_SRCH?api-version=2021-12-01-preview"
az rest --method put --url $url --headers "Content-Type=application/json" \
-b '{
"properties": {
"searchResults": {
"query": "ContainerLog \r\n| extend type = extract(@\"^(.*?):\", 1, LogEntry),\r\n ip = extract(@\"ip=(.*?)\\s\", 1, LogEntry),\r\n port = extract(@\"port=(.*?)$\", 1, LogEntry)\r\n| where type == \"type2\"\r\n| project-away _ResourceId, LogEntry, LogEntrySource, _SubscriptionId",
"limit": 10000,
"startSearchTime": "2022-02-21T00:00:00Z",
"endSearchTime": "2022-02-26T00:00:00Z"
}
}
}'
Job běží na pozadí, což si můžu zkontrolovat GETem na stejnou URL
# Get job status
az rest --method get --url $url --headers "Content-Type=application/json"
{
"id": "/subscriptions/a0f4a733-4fce-4d49-b8a8-d30541fc1b45/resourcegroups/logs/providers/Microsoft.OperationalInsights/workspaces/tomaslogs7613/tables/type2logs_SRCH",
"name": "type2logs_SRCH",
"properties": {
"archiveRetentionInDays": 0,
"createdBy": "7424fb4c-5e9f-45cd-9f7d-453d45655e75",
"lastPlanModifiedDate": "2022-02-26T14:24:18.747Z",
"plan": "Analytics",
"provisioningState": "Updating",
"retentionInDays": 30,
"totalRetentionInDays": 30
},
"systemData": {
"createdBy": "7424fb4c-5e9f-45cd-9f7d-453d45655e75"
}
}
Vidím, že analytická tabulka s výsledky se právě vytváří. Po nějaké době GET zopakuji a už vidím strukturu tabulky, z kterého query vzešla a tak podobně.
{
"id": "/subscriptions/a0f4a733-4fce-4d49-b8a8-d30541fc1b45/resourcegroups/logs/providers/Microsoft.OperationalInsights/workspaces/tomaslogs7613/tables/type2logs_SRCH",
"name": "type2logs_SRCH",
"properties": {
"archiveRetentionInDays": 0,
"createdBy": "7424fb4c-5e9f-45cd-9f7d-453d45655e75",
"lastPlanModifiedDate": "2022-02-26T14:24:18.747Z",
"plan": "Analytics",
"provisioningState": "InProgress",
"resultStatistics": {
"ingestedRecords": 0,
"progress": 0.0,
"scannedGb": 0.0
},
"retentionInDays": 30,
"schema": {
"columns": [
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "SourceSystem",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "TimeGenerated",
"type": "datetime"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "Computer",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "TimeOfCommand",
"type": "datetime"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "ContainerID",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "Image",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "ImageTag",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "Repository",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "Name",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "Id",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "ip",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "port",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "_OriginalType",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "_OriginalItemId",
"type": "string"
},
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "_OriginalTimeGenerated",
"type": "datetime"
}
],
"name": "type2logs_SRCH",
"searchResults": {
"azureAsyncOperationId": "557f8f12-23e2-486c-9861-adf82274d850",
"description": "This table was created using a Search Job with the following query: 'ContainerLog \r\n| extend type = extract(@\"^(.*?):\", 1, LogEntry),\r\n ip = extract(@\"ip=(.*?)\\s\", 1, LogEntry),\r\n port = extract(@\"port=(.*?)$\", 1, LogEntry)\r\n| where type == \"type2\"\r\n| project-away _ResourceId, LogEntry, LogEntrySource, _SubscriptionId'.",
"endSearchTime": "2022-02-26T00:00:00Z",
"limit": 10000,
"query": "ContainerLog \r\n| extend type = extract(@\"^(.*?):\", 1, LogEntry),\r\n ip = extract(@\"ip=(.*?)\\s\", 1, LogEntry),\r\n port = extract(@\"port=(.*?)$\", 1, LogEntry)\r\n| where type == \"type2\"\r\n| project-away _ResourceId, LogEntry, LogEntrySource, _SubscriptionId",
"sourceTable": "ContainerLog",
"startSearchTime": "2022-02-21T00:00:00Z"
},
"solutions": [
"LogManagement"
],
"standardColumns": [
{
"isDefaultDisplay": false,
"isHidden": false,
"name": "TenantId",
"type": "guid"
}
],
"tableSubType": "DataCollectionRuleBased",
"tableType": "SearchResults"
},
"totalRetentionInDays": 30
},
"systemData": {
"createdBy": "7424fb4c-5e9f-45cd-9f7d-453d45655e75"
}
}
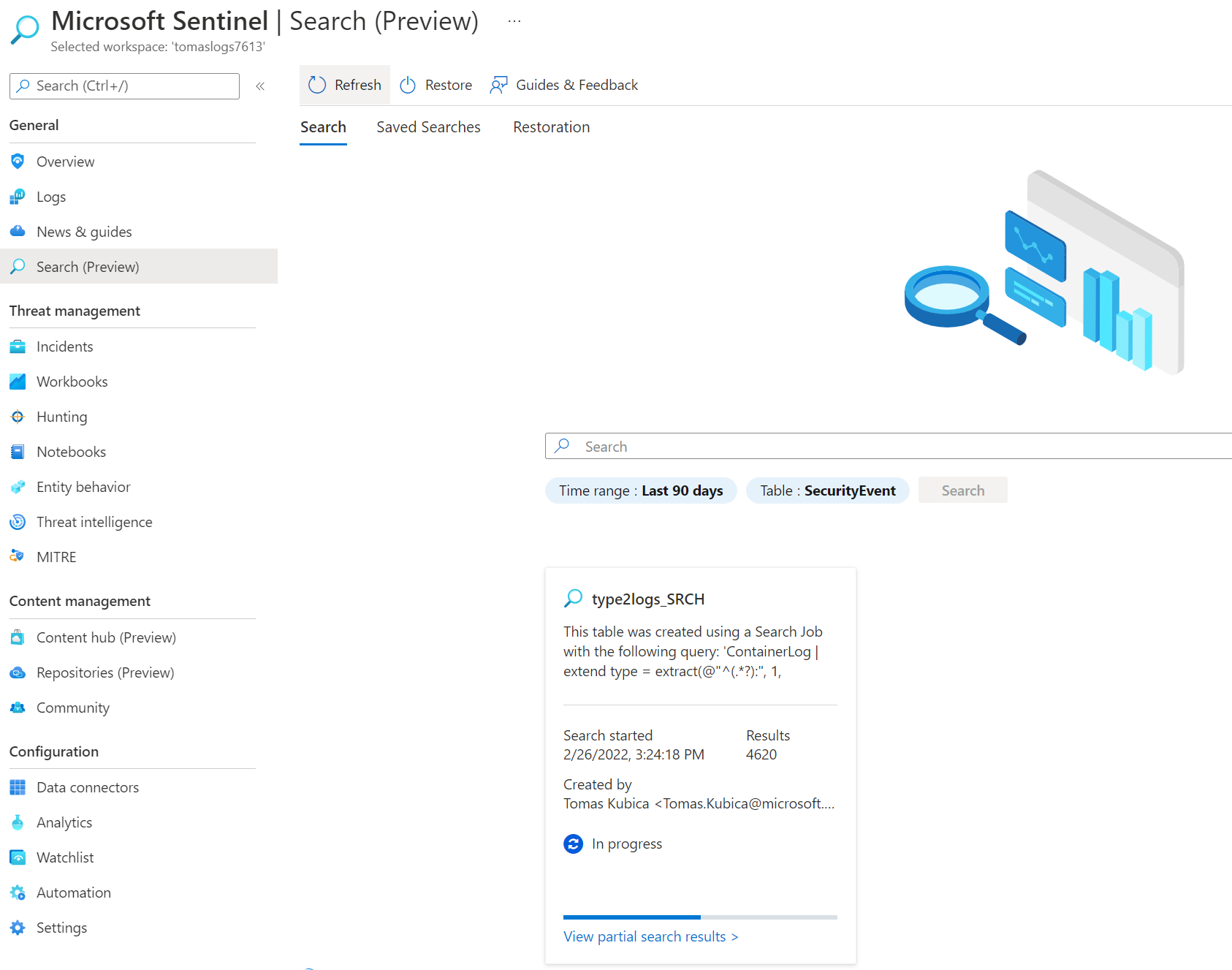
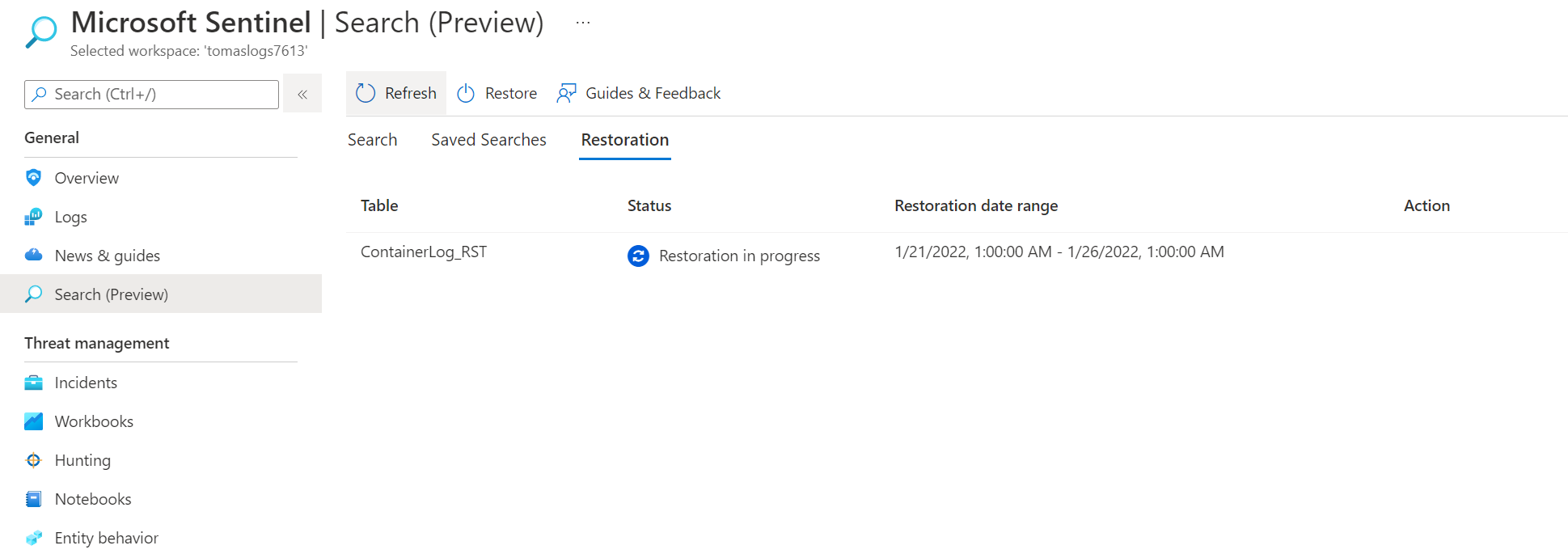
Pokud bych něco takového chtěl dělat graficky z portálu, takhle vypadá UI v Microsoft Sentinel.
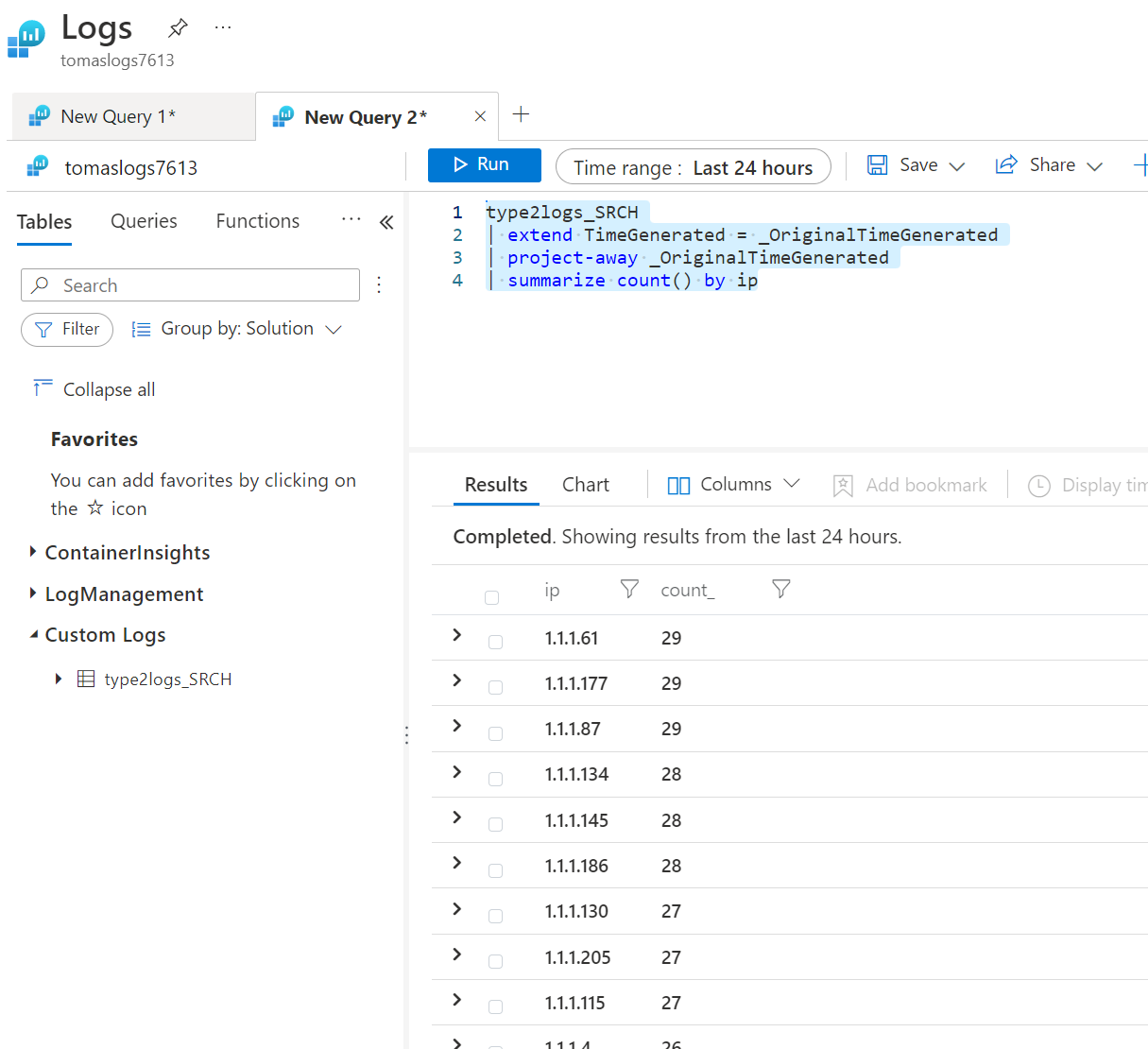
Pěkně je, že výsledky našeho hledání v archivu jsou teď v analytické tabulce, takže nad nimi můžeme pokračovat dál s analytikou - například sumarizaci podle IP.
type2logs_SRCH
| extend TimeGenerated = _OriginalTimeGenerated
| project-away _OriginalTimeGenerated
| summarize count() by ip
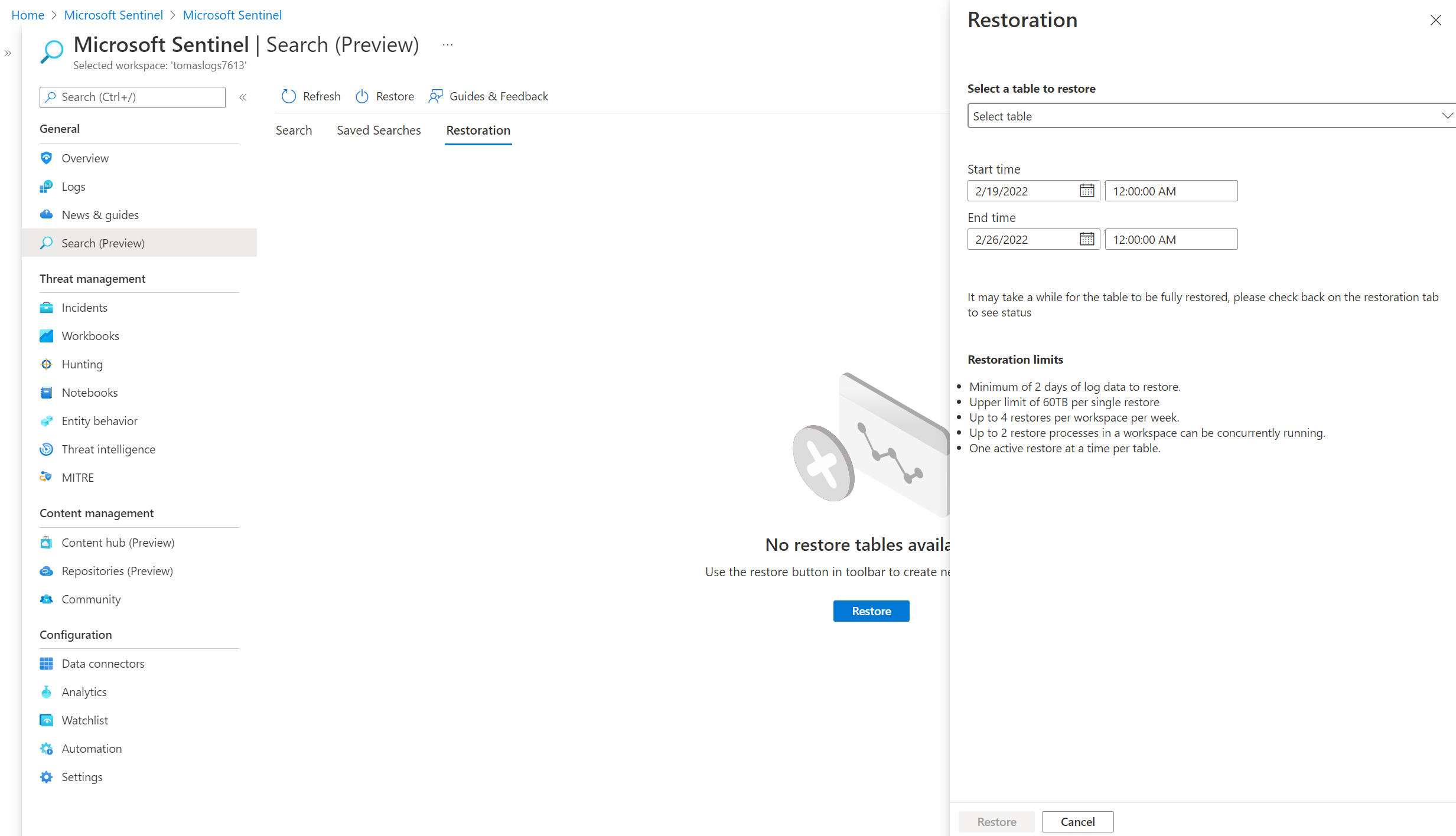
Místo search jobu můžeme také přistoupit k zavlažení archivních logů. Jak jsem minule popisoval, funguje to tak, že se data na nějakou dobu přesunou do analytického tieru a můžete se pak v nich prohrabávat naplno. Platíte podle objemu zavlažených dat a to za každý načatý den, kdy je chcete držet v analytice. Všimněte si, že v následujícím API volání nemůžeme specifikovat query, jen časové okno (minimum jsou dva dny). Pokud tedy hledám něco dost specifického, co mi z tabulky vrátí méně jak 4% dat, je výhodnější dát search job a zaplatit ingesting. Pokud ale nevím přesně co hledám a budu dat vracet významnější procento, bude výhodnější je zavlažit. V API stačí opět vytvořit novou tabulku tentokrát s příponou _RST a v properties specifikovat resourceLogs s časovým oknem a zdrojovou tabulkou.
# Restore archive logs to analytics tier
export url="https://management.azure.com$workspaceId/tables/ContainerLog_RST?api-version=2021-12-01-preview"
az rest --method put --url $url --headers "Content-Type=application/json" \
-b '{
"properties": {
"restoredLogs": {
"startRestoreTime": "2022-01-21T00:00:00Z",
"endRestoreTime": "2022-01-25T00:00:00Z",
"sourceTable": "ContainerLog"
}
}
}'
Takhle to vypadá v UI Sentinelu.
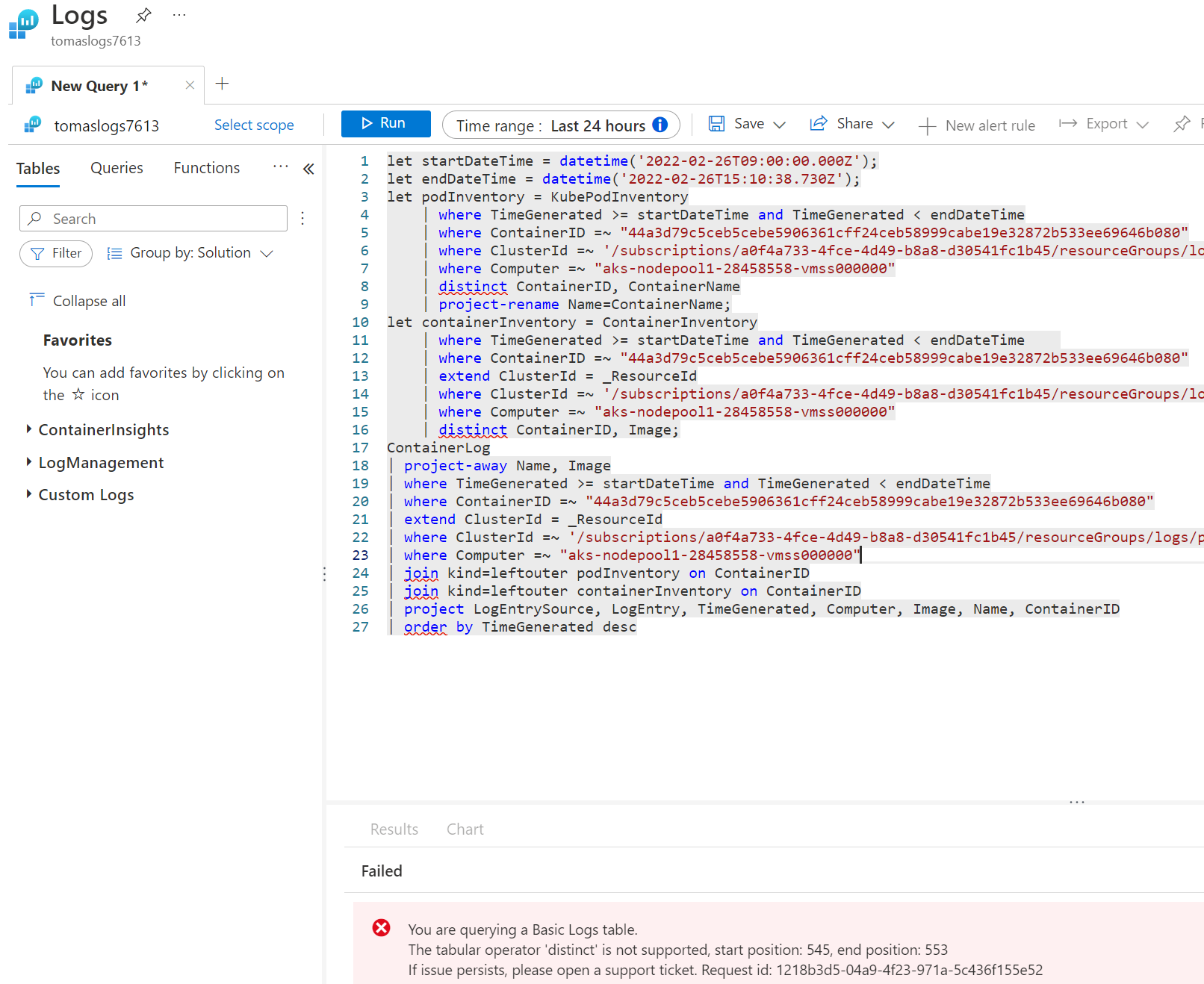
Na závěr - basic logs neumožňují joiny a jiné složité operace a to ovlivnilo UI Container Insights v Azure Monitor, které joinuje ContainerLogs s několika dalšími tabulkami s inventářem (jak se jmenoval Pod a tak).
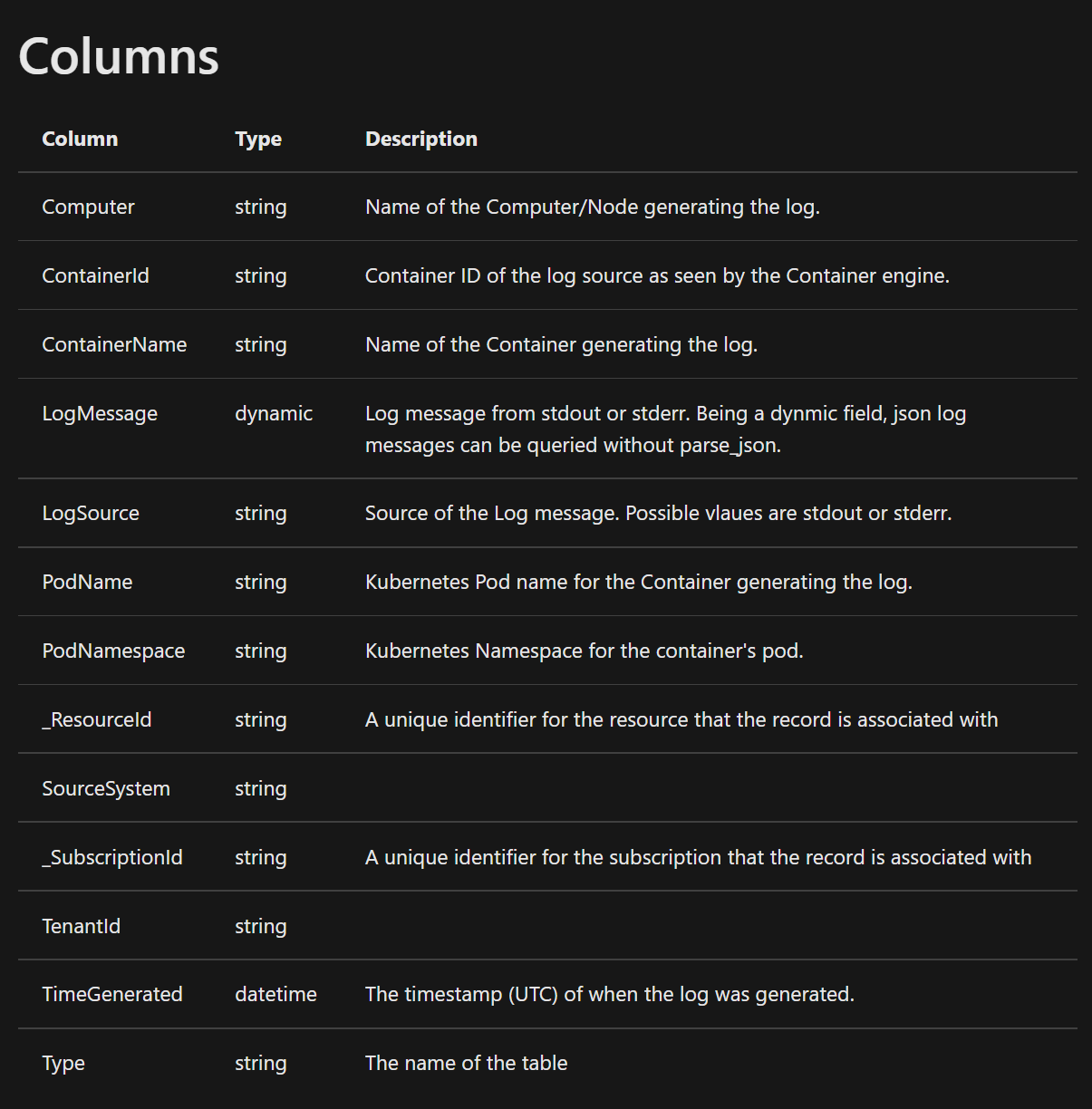
Možná právě proto je v private preview obohacování dat přímo na agentovi, takže v tabulce najdete i informaci o Podu nebo namespace. Znamená to samozřejmě, že takový denormalizovaný přístup generuje větší objem dat, ale na druhou stranu pak nepotřebujete složité join operace a search zvládnete v basic nebo archive tieru v pohodě. Aktuálně už je dokumentace datové struktury tabulky ContainerLogV2 - nicméně vyzkoušet zatím nelze, snad to bude brzy hotové.
Tolik tedy zatím k využití nových basic a archiv logů v praxi a metodám prohledávání nebo zavlažování archivních logů. Jsem zvědavý hlavně jak se bude rozvíjet podpora v jednotlivých řešeních typu různých Insights v Azure Monitor, protože UI v Microsoft Sentinel už teď vypadá myslím velmi dobře. Zkuste si to!