Může se stát, že v Azure někdy něco nefunguje? Může, ostatně proto na většinu služeb je SLA, které je menší než 100% (výjimkou je tady třeba Azure DNS se 100% SLA). Typicky platí vztah mezi inovacemi a dostupností. Inovace = změna, změna = riziko, riziko = snížená dostupnost. Na to jak obrovským tempem se Azure rozvíjí je jeho dostupnost skutečně příkladná a ostatní velké public cloudy na tom nejsou o moc hůře. Je vidět, že ty investice, které si může dovolit jen málo firem na světě, vrací to co mají. Řídící systém letadla nebo jaderné elektrárny má dostupnost jistě větší, ale obvykle jede na technologiích, které třeba výkonnostně odpovídají dnešnímu mobilu - vývoj a testování trvá třeba deset let a jen se ladí a ladí, inovace jsou nepřítel (ty se odehrají až v další generaci letadla/elektrárny v další dekádě). Azure je tedy vysoce inovující systém a chyba se tak logicky někdy stát musí.
Nejčastěji se logicky mohou objevit potíže s jednou konkrétní službou v jednom konkrétním regionu a v omezeném okruhu zákazníků. Služba typicky není jeden megasystém pro všechny zákazníky, ale z důvodu škálovatelnosti je rozdělena na nějaké clustery a typicky se chyby v software projevují jen na omezeném počtu clusterů, ostatně i veškeré změny software se právě z důvodu opatrnosti rolují postupně. Chyba hardware je standardní součást života služby, takže nějaký upadnutý server není žádný problém.
Podstatně méně častěji může dojít k výpadku celé zóny dostupnosti. To se stává hodně málo (a mluvím teď o třech hlavních cloudech, kde je to podobné - lokální hosting často zóny dosupnosti, tedy plně oddělené budovy v synchronní vzdálenosti, nemá - buď má jednu budovu nebo má asynchronní vzdálenost druhé, což je v kontextu Azure region) a je to většinou naprosto nečekaná souhra okolností (musí se stát obvykle 3 naprosto nestandardní věci najednou, protože se vším ostatním je počítáno). Pokud vaše VM běží v té budově, která aktuálně hoří, tak tam to VM samosebou nefunguje. Nicméně proto můžete mít další v jiné zóně a řada platformních služeb je automaticky rozprostřena přes zóny (například Azure SQL DB Business Critical nebo Azure Kubernetes Service).
Aspektů je ovšem samozřejmě víc. Tak například cloudový poskytovatel se v případě problému bude vždy snažit primárně řešit integritu (obnovu) dat místo opětovného spuštění. Tedy nerozhodne se rychle službu obnovit za cenu ztráty dat, vždy se je bude snažit rekonstruovat. Pěkný příklad jsem popisoval tady. Proto je vhodné mít i nějakou DR strategii s možností si sami určit za jakých okolností překlopit (čekat na obnovu všech dat nebo se spokojit s nějakým RPO a raději službu nahodit v jiném regionu - to je byznys rozhodnutí, které musíte přijmout vy, poskytoval do vašeho byznysu nevidí). Jedna zajímavá chyba v minulosti byla způsobena výpadkem služby v jednom clusteru, takže do toho uživatelé bušili jak o závod a systém samozřejmě vyškáloval v jiném clusteru. Jenže to způsobilo dost neobvyklou a nečekanou zátěž, kterou služba chybně vyhodnotila jako útok a začala se bránit. Mechanismus, který ji už mnohokrát uchránil od skutečných globálních útoků se teď obrátil proti ní - něco jako autoimunitní onemocnění u člověka. Inženýři museli zjistit co se děje, ručně zasáhnout (píchnout kortikoidy) a do budoucna pozměnit nastavení. Katastrofální mohou být globální síťové problémy (což se Microsoftu ve velké škále ještě naštěstí nestalo díky hodně zajímavé možnosti simulace celé globální sítě před aplikací změn) kdy směrovací protokol odkloní provoz zákazníků omylem do černé díry. Zkrátka jsou to všechno složité systémy a chyby se stávají, i když vzhledem ke škále a inovacím podstatně méně často, než u běžného “domácího” datového centra.
Proto je tedy na místě otázka - když se něco bude dít, jak se o tom dozvím?
Azure Service Health
Najděte si v portálu Service Health.
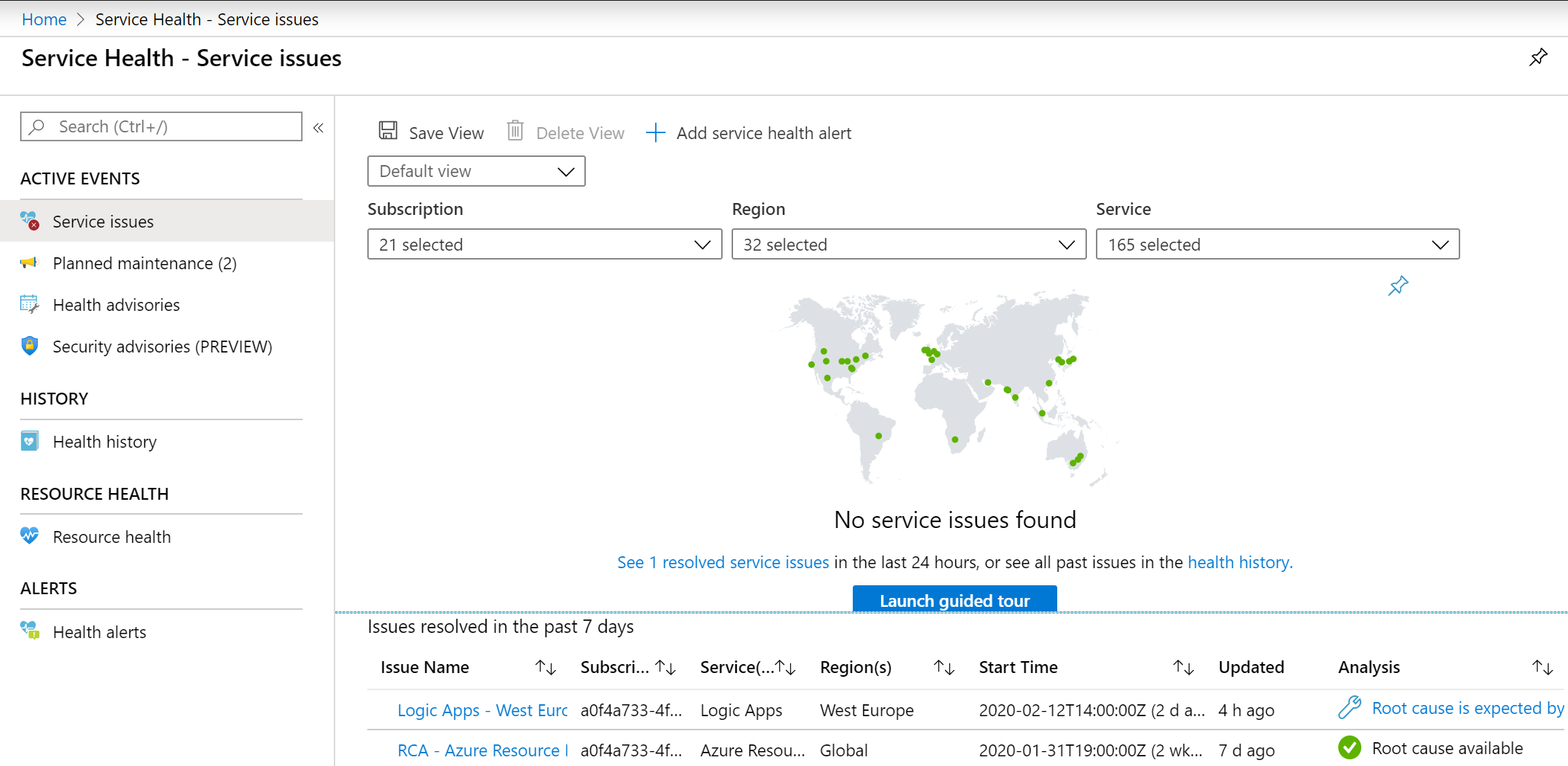
Nahoře jsou filtry, kterými můžete omezit příliv informací na ty, co vás zajímají. Například nemá cenu se nechat znervóznit nějakou chybou v Brazílii, když používáte jen West Europe. Také může filtrovat podle služeb, protože ne všechny používáte. GUI vám samo předvyplňuje co by vás mohlo zajímat podle toho co reálně používate a jaké subskripce máte označené.
Tady je issue, které se mě dotklo (a bylo důvodem proto sepsat něco o tomto tématu, protože můžu ukázat nějaký pěkný problémek a ne teoretizovat nad prázdným polem).
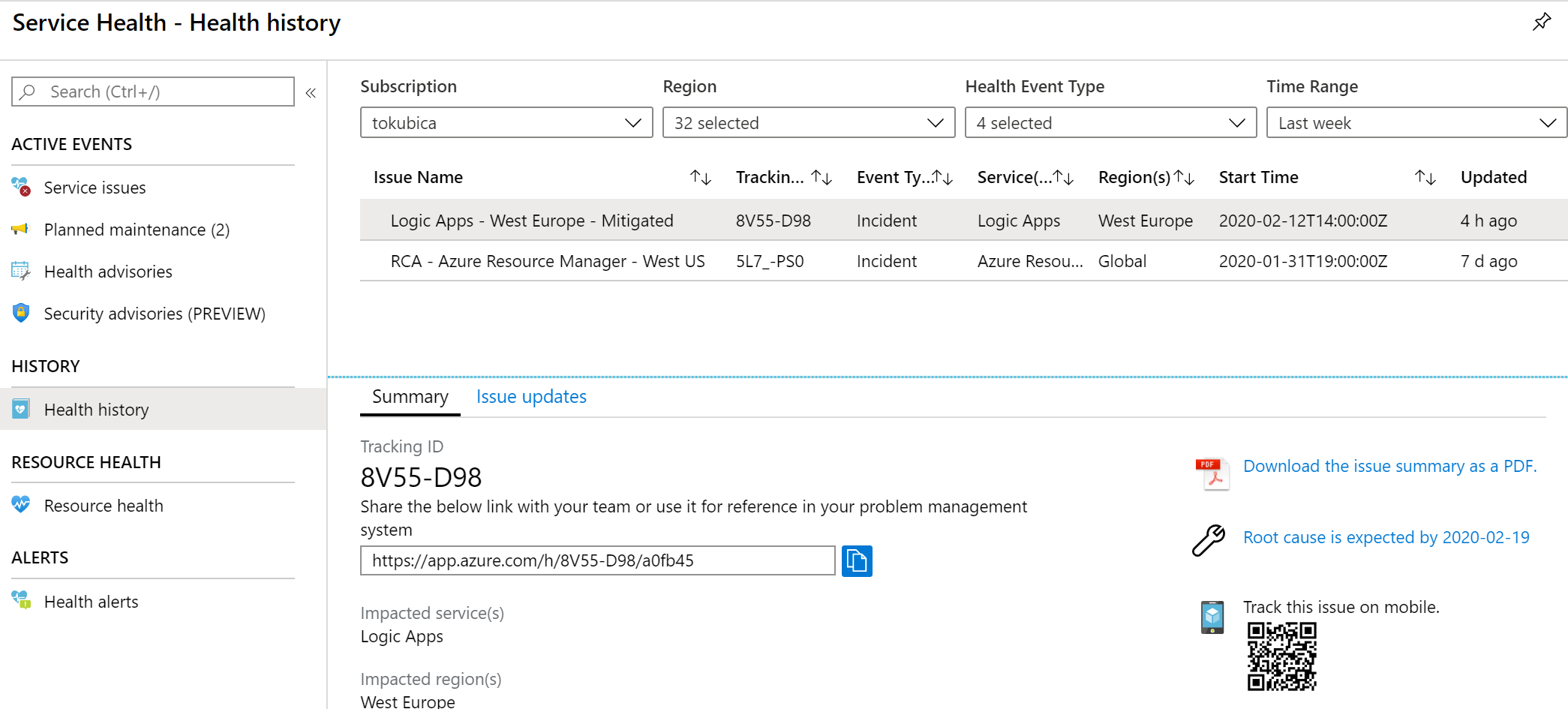
Přečtu si víc detailů.
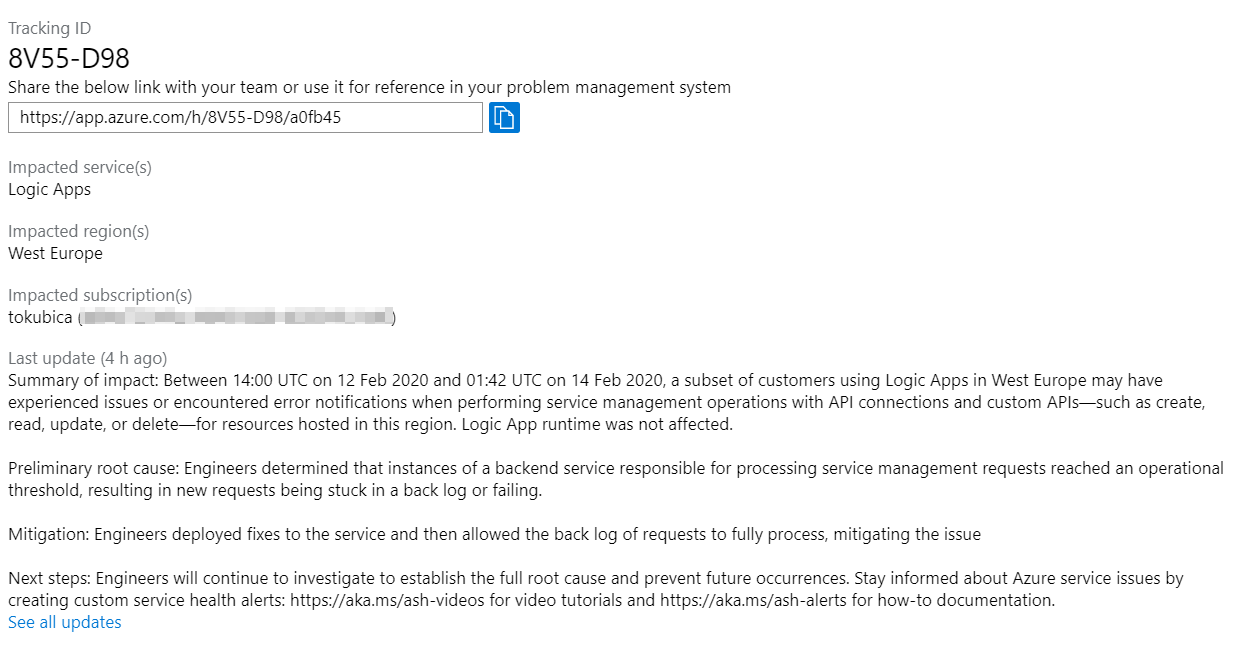
Podle všeho v průběhu několika hodin se některým zákazníkům Logic App ve West Europe stávalo, že nemohli editovat nastavení. Logic App jako taková jela a fungovala bez problémů, ale nebylo možné nějakou dobu modifikovat nastavení nebo vytvářet nové s některými konektory. To je dobrý příklad nejčastější chyby - služba funguje, ale má nějaké omezení. V textu je i link vedoucí na tuto stránku, který můžete použít v nějakém vašem ticketovacím systémů apod.
Jaké máte možnosti sledování incidentu?
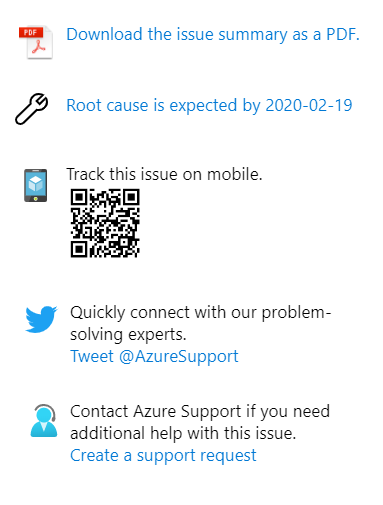
Lze si stáhnout PDF (třeba pro účely archivace), sledovat vývoj z mobilu nebo kontaktovat podporu přes Twitter nebo založit ticket. Všimněte si také informace o tom, že root cause analysis ještě není, ale očekává se tehdy a tehdy. V okamžiku incidentu se samozřejmě řeší primárně zprovoznění služby. Samozřejmě vznikají nějaké teorie čím to může být a rolují se opravy. Dostáváte informaci o tom jak inženýři postupují s řešením incidentu, kdy můžete očekávat další update a tak podobně.
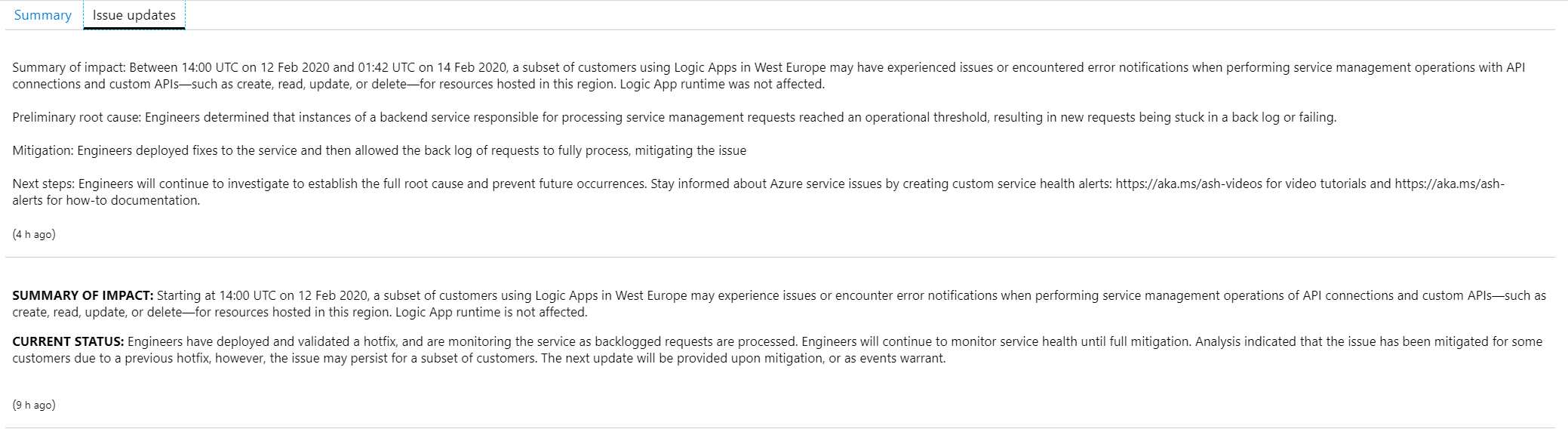
Po zprovoznění služby začne detailní analýza co se vlastně stalo a přijmou se opatření, aby se chyba nikdy neopakovala. Jako zákazník samozřejmě máte právo hlavní závěry této analýzy vidět a není potřeba nikam volat - automaticky si ji stáhnete z portálu. K tomu se pojďme podívat na jiný incident, kde už je RCA k dispozici.
Tady bylo pro dobu několika hodin ve West US zpožděné API, tedy zase - všechny službu fungují a není impact na provoz, nicméně jste omezeni v ovládání Azure (vytváření nových zdrojů apod.), protože je velká latence a občas to dokonce i neodpoví a musíte příkaz/kliknutí opakovat.
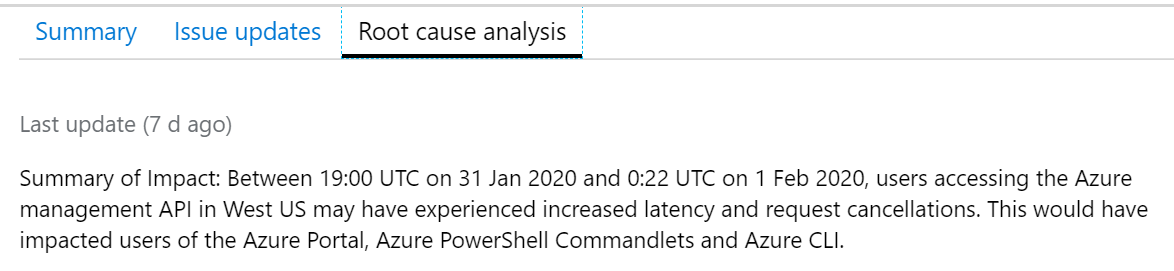
Tady je root cause - typická záležitost, velmi zajímavá souhra okolností.

Co inženýři udělali, aby se chyba už nikdy neopakovala?

Na tyto hlášky si můžete vytvořit Alert, který dokáže spouštět Action Group. To znamená:
- Poslání emailu
- Zavolání webhook
- Založení incidentu v ITSM nástroji (např. Service Now)
- Spuštění kódu v Azure Functions
- Spouštění skriptu v Azure Automation
- Vyvolání Logic App s orchestračním workflow, které může dělat obrovské množství zajímavých věcí včetně email, Teams, Slack, Service Now - celkem asi 600 různých konektorů do světa Microsoftu i třetích stran
Azure Status page
Co kdyby byl problém takový, že se do portálu ani nepřihlásíte? Nebo jste na dovolené a koukáte z počítače na recepci, odkud se logovat nechcete? K tomu slouží status stránka status.azure.com, kde žádného přihlášení netřeba.
Myslím, že transparentnost v komunikaci incidentů je úžasnou vlastností velkých public cloud prostředí. Když si čtu RCA říkám si jak těžké je nějakou nedostupnost způsobit a fascinuje mě rychlost řešení problémů a síla preventivních opatření. Jasně - každý výpadek je nepříjemný, ale transparentnost a profesionalita dává srovnání s tím, že ve svém na tom budu dost možná hůř. “RCA”, které znám ze světa některých firemních datových center, totiž v těchto reportech ani zdalaka nenacházím :)
Například:
- Někdo na serveru udělal bridge dvou síťovek a způsobil broadcast storm, kritické služby odpadly (AD) a s tím všechno ostatní
- Při upgrade páteřních prvků někdo aktualizoval a otočil první, ale nevšiml si, že se po restartu cluster s tím druhým nespojil - otočil druhý a páteř byla fuč
- DNS server lehnul a druhý nefunguje (což jsme nevěděli, když se nepoužívá), tak se nikdo nikam nedostal
- Někdo si myslel, že je na testu, takže omylem promazal data a otočil produkci
- Někdo v panice usoudil, že je nakopnutá databáze a spustil recovery, které se nedá zastavit a poběží ještě 4 hodiny … samozřejmě 30 vteřin po tomto kliknutí mu došlo, že je to nečím jiným, což obratem fixnul a dalších 3 hodiny 58 minut se čekalo
- Poctivě se zálohovalo, ale recovery nikdo nezkoušel - když bylo potřeba, nezafungovalo
- Záložní DC samozřejmě bylo, ale z důvodu rizika se to nikdy nezkusilo přepnout - nakonec se při havárii 5 hodin řešil routing sítě, pak se tam nahodily aplikace, ale polovina z nich nenaběhla, protože byly legacy a naskakovaly ve špatném pořadí (tuhle ještě nebyl řadič, tuhle ještě nebyla DNS, tuhle ještě nebyl aplikáč, tuhle nebyl druhý node databáze) - další 4 hodiny se hledalo v jakém pořadí co restartovat, aby to nějak najelo.
- Zapomenutá trubka ve zdi pod omítkou praskla a vylila se do storage pole a trvalo asi týden, než se všechny workloady znova rozběhly
Tak věřím, že něco z toho v RCA Azure nikdy nenajdu…