Dnes se podíváme na Kusto dotazy nad telemtrickými údaji z Azure jako jsou zátěž CPU a podobné metriky. Je to tedy problematika časových řad a ukážeme si základní dotazy, časovou a jinou agregaci, ale dostane se i na pokročilejší analýzu jako je detekce anomálií či predikce budoucího vývoje. To všechno je k dispozici v rámci KQL v dotazech, které jsou téměř v reálném čase. Pojďme na to.
Základní pohled a agregace
Azure Monitor má v Log Analytics Workspace data uložena v různých tabulkách a my začneme s tabulkou Perf, ve které najdeme základní telemetrii primárně ze světa IaaS, tedy věci jako je zatížení procesoru, paměti a tak podobně. Nicméně Azure Monitor dokáže sbírat i síťovou komunikaci, zátěž jednotlivých běžících procesů i telemetrii z platformních služeb.
Co najdu v tabulce Perf? Začínám obvykle tak, že si nechám vypsat nějaký náhodně vybraný sample těchto dat.
Perf
| sample 100
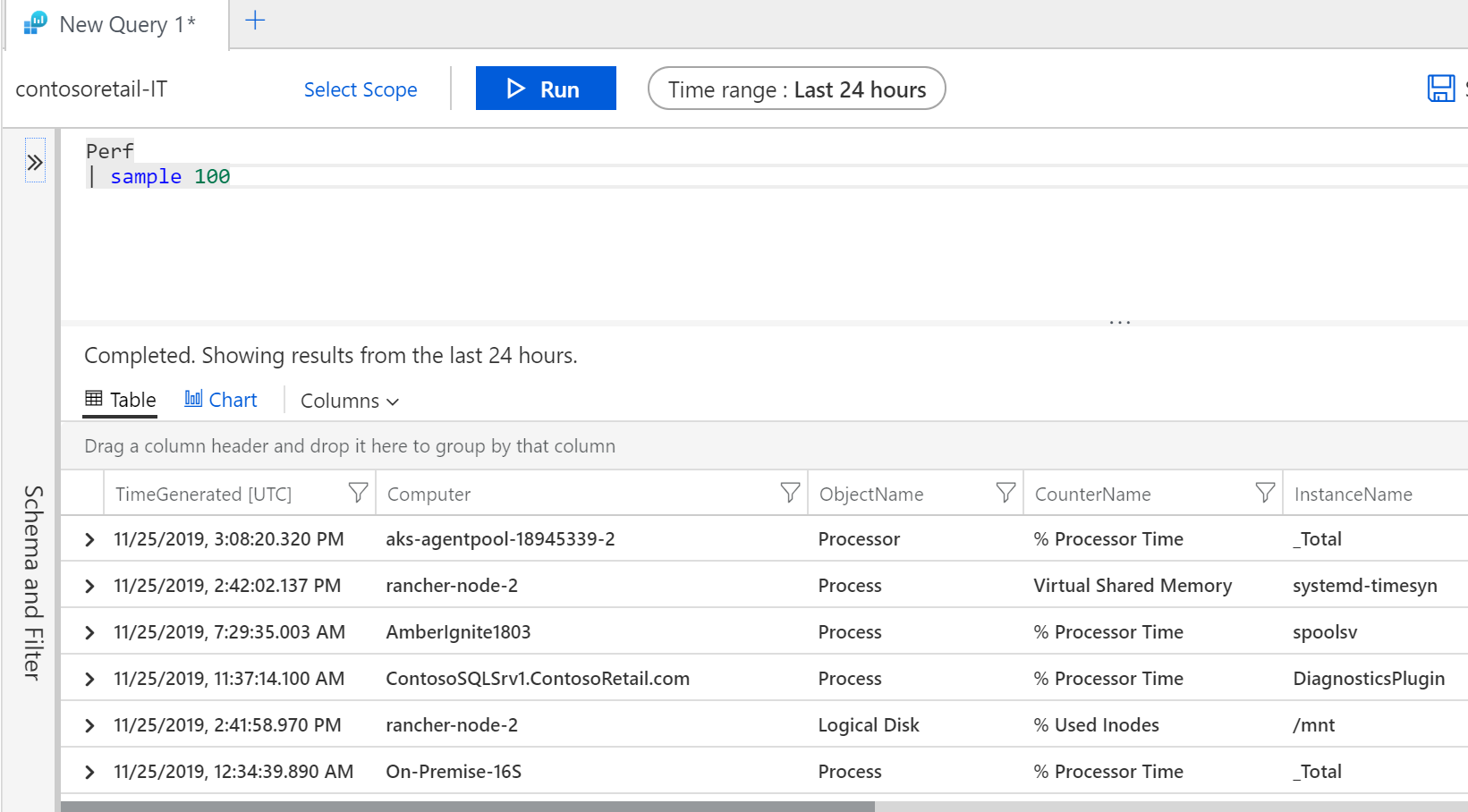
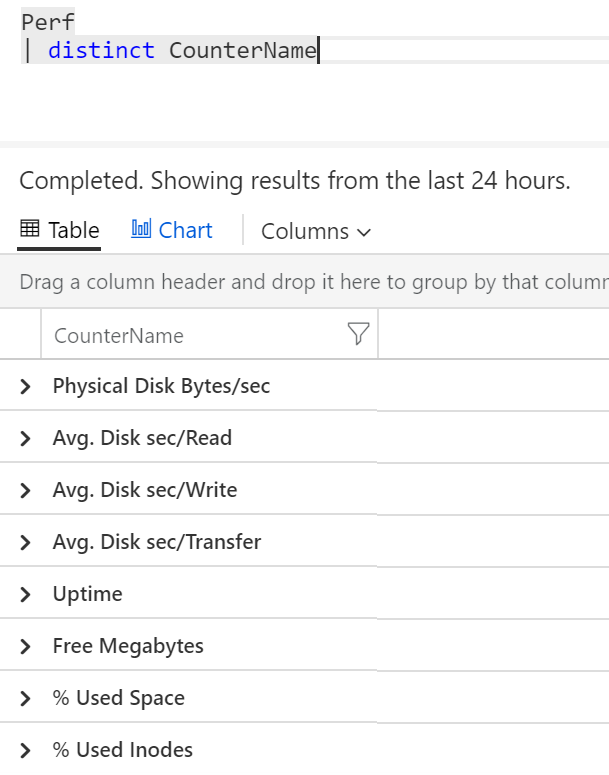
Zajímalo by mne, jakých všech hodnot v mých datech nabývá sloupeček CounterName.
Perf
| distinct CounterName
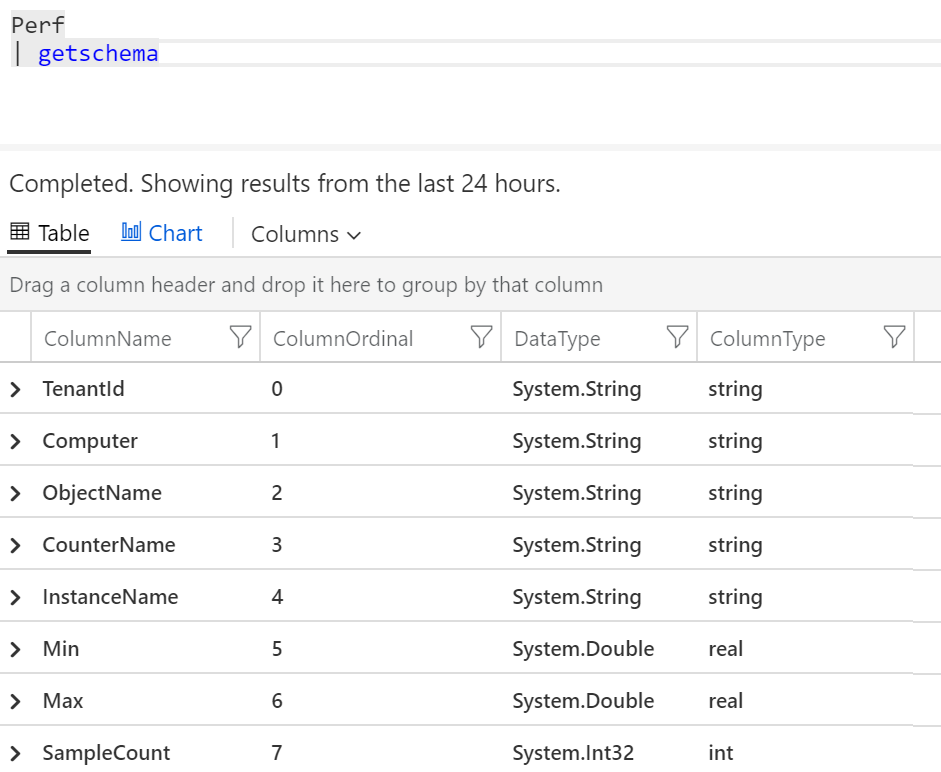
Možná se mi také bude hodit informace o schématu této tabulky.
Perf
| getschema
Zdá se mi, že ObjectName, který chci zkoumat, je Processor. Jaké všechny CounterName jsou u něj v datech k nalezení?
Perf
| where ObjectName == "Processor"
| distinct CounterName
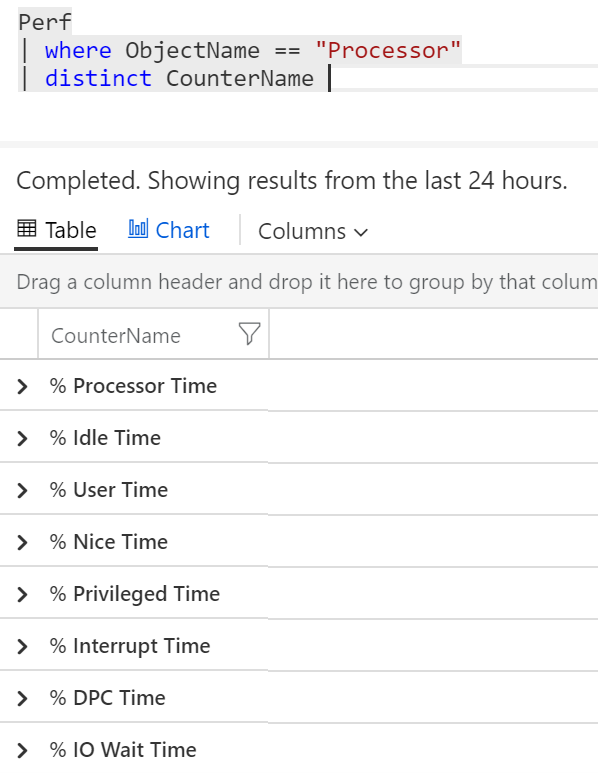
Skvělé, půjdu po % Processor Time. Jaké všechny InstanceName může mít?
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time"
| distinct InstanceName
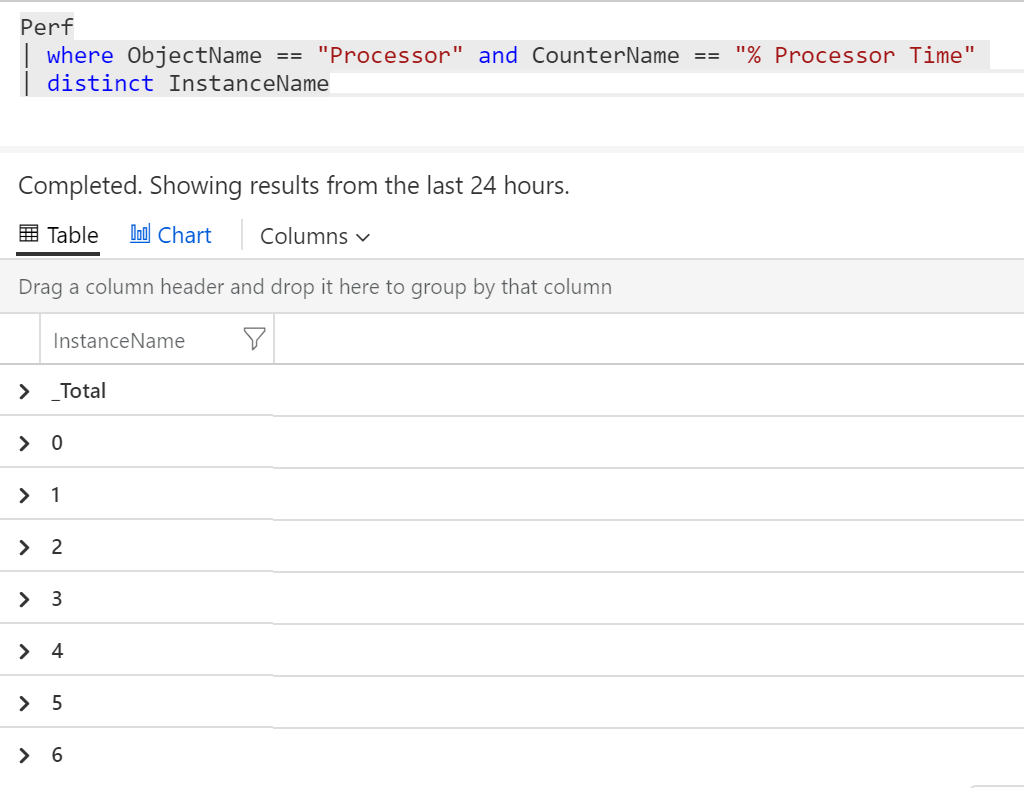
Jsou to tedy údaje za jednotlivé čísla core v systému a já si vyberu _Total, tedy pohled za všechny, co na tom kterém stroji jsou.
S tím už bych si mohl udělat nějakou agregaci. Průměr možná pro CPU není moc vypovídající, protože systém může být občas přetížen a v průměru se mi to zahladí. Koukat na maximum ale také nebude úplně směrodatné, protože krátkodobé špičky jsou běžná věc. Nejlepší mi připadá podívat se na percentil a typicky volím 90-tý, 95-tý nebo 99-tý. Pojďme tedy spočítat 95-tý percentil z CounterValue (to je zatížení procesoru v procentech) a to samostatně pro každý můj Computer.
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUload=percentile(CounterValue, 95) by Computer
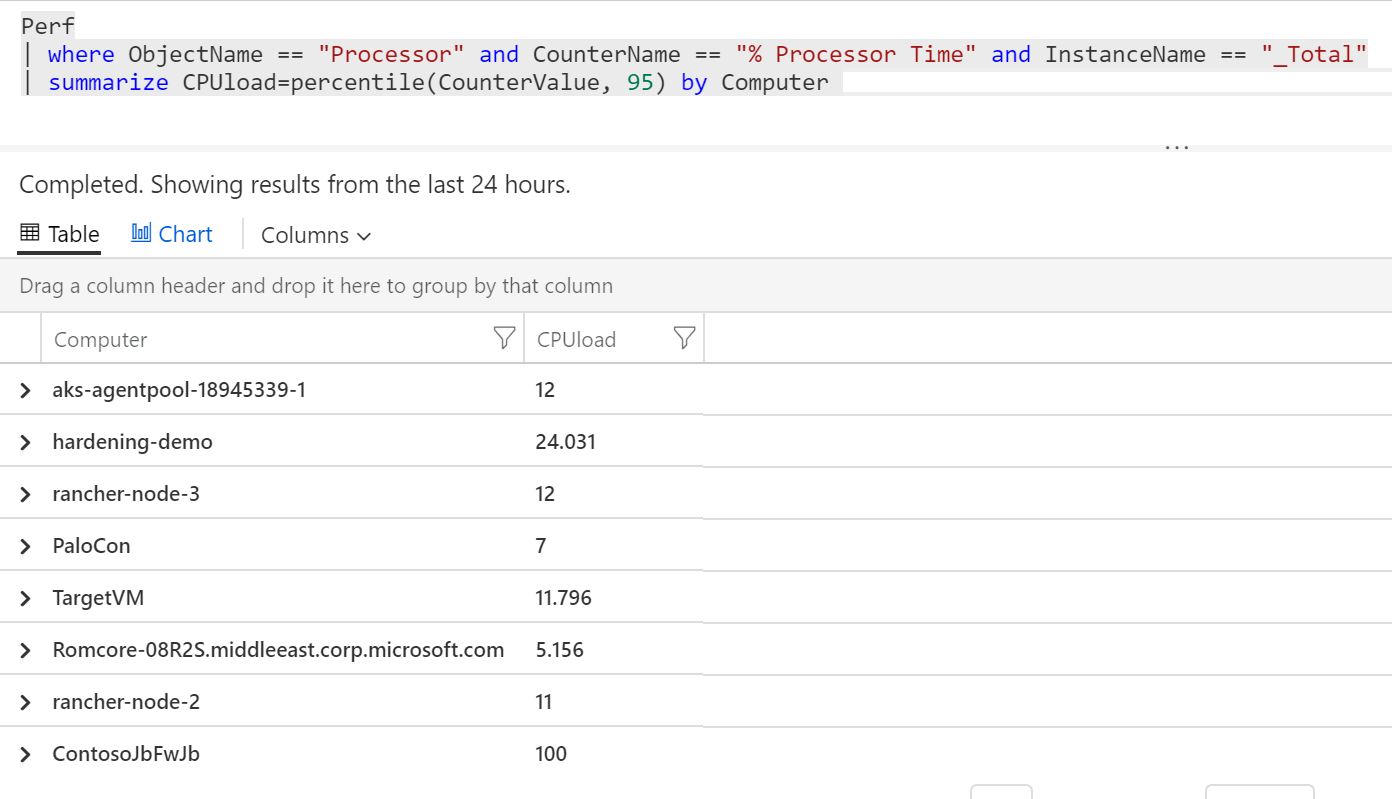
Výborně. Podobným postupem jsem si našel totéž pro využití paměti.
Perf
| where ObjectName == "Memory" and CounterName == "% Available Memory"
| summarize memoryUsage=percentile(CounterValue, 95) by Computer
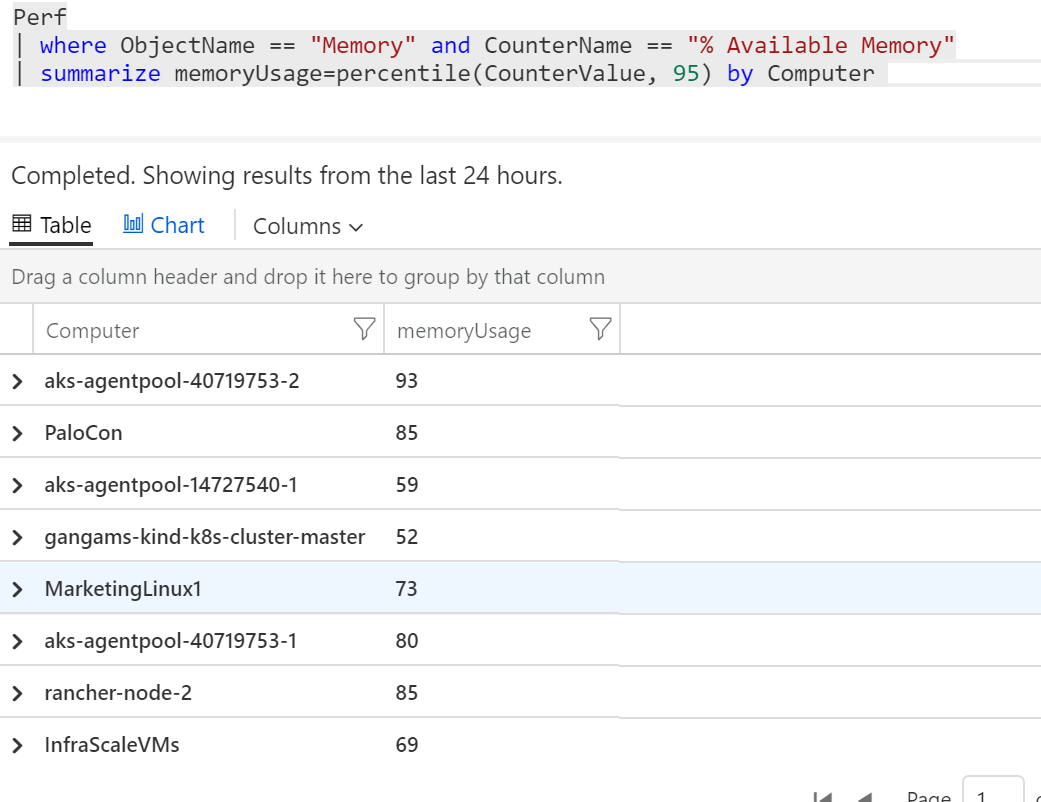
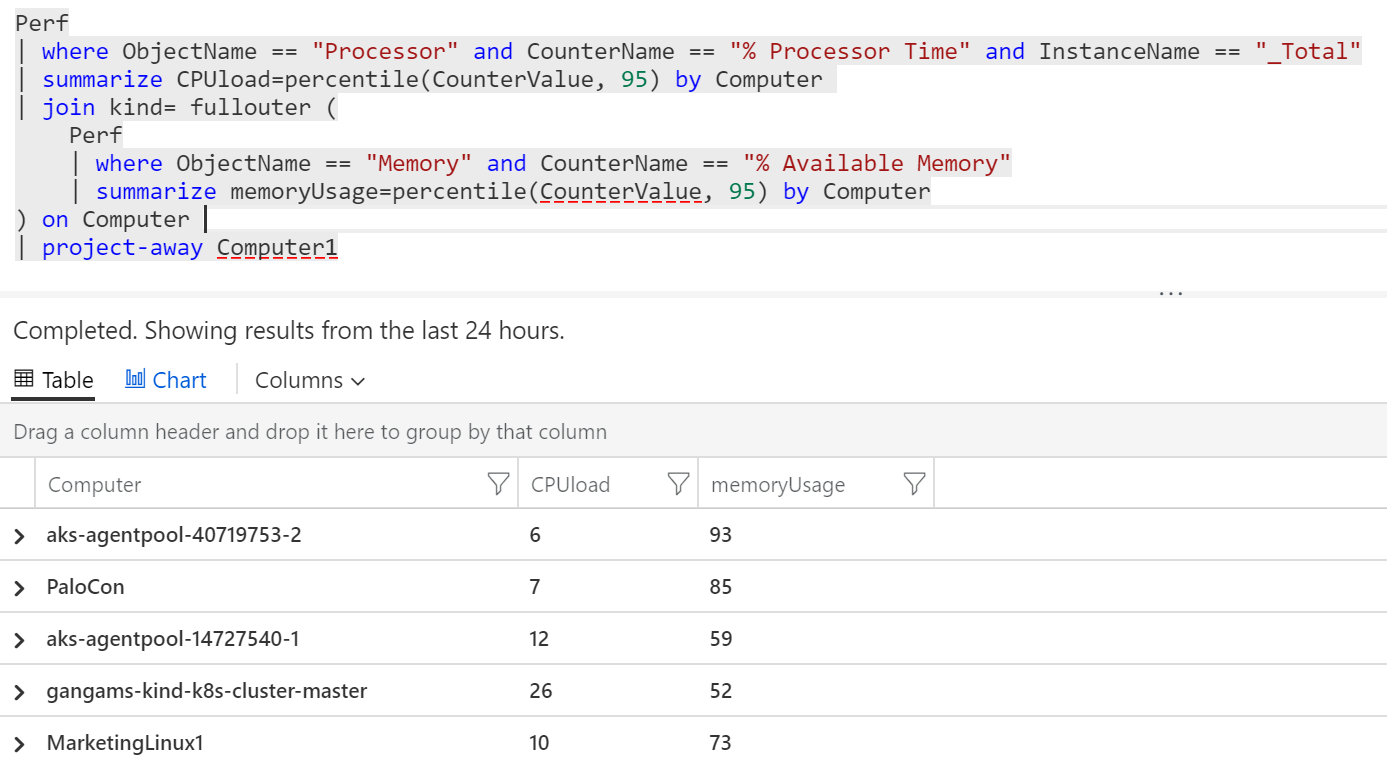
Teď bych chtěl ale dostat jednu tabulku, ve které bude na řádku Computer a k němu percentil za CPU a za paměť. Můžeme tedy smontovat dvě předchozí query do jediného. Nejdřív si vypíšu percentil CPU a provedu join na můj druhý výpis s pamětí. Jako metodu spojení tady použiji fullouter, protože se může stát, že u nějakého Computer nemám změřeno CPU, ale paměť jo, a u jiného opačně. Do tabulky tedy chci i stroje, které v jednom z dotazů nejsou - proto fullouter. Jak výsledky spojím tak, aby byly co řádek to Computer? Join udělám právě přes tento sloupeček. Ve výsledné sestavě se mi tak Computer objeví dvakrát a podruhé v sloupečku Computer1. Ten je zbytečný a nechci ho tam, takže přes project-away ho dám z výpisu pryč. Výsledek vypadá takhle:
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUload=percentile(CounterValue, 95) by Computer
| join kind= fullouter (
Perf
| where ObjectName == "Memory" and CounterName == "% Available Memory"
| summarize memoryUsage=percentile(CounterValue, 95) by Computer
) on Computer
| project-away Computer1
Pokud se mi to hodně líbí, mohu si query uložit, připnout si výslednou tabulku na dashboard, vytvořit z něj alert nebo ho exportovat jako CSV či jako dotaz do PowerBI (k tomu se někdy vrátíme - může to být výborná volba, když potřebuji dát do jednoho obrázku data z Azure Monitor a vedle toho ukázat jaký má zatíženost infrastruktury vliv na prodejnost triček velikosti XL, který vytahuji třeba z Azure SQL).

Časová agregace a vývojové grafy
Přímo stránka pro zadávání dotazů může udělat i jednoduchou vizualizaci, ale k té se vrátíme ještě později, protože tu budeme ideálně dělat třeba s Azure Monitor Workbooks, kde bude možností nekonečně víc. Ale tématem dneška je jak psát dotazy a někdy příště si je vykreslíme pěkně ve Workbooku.
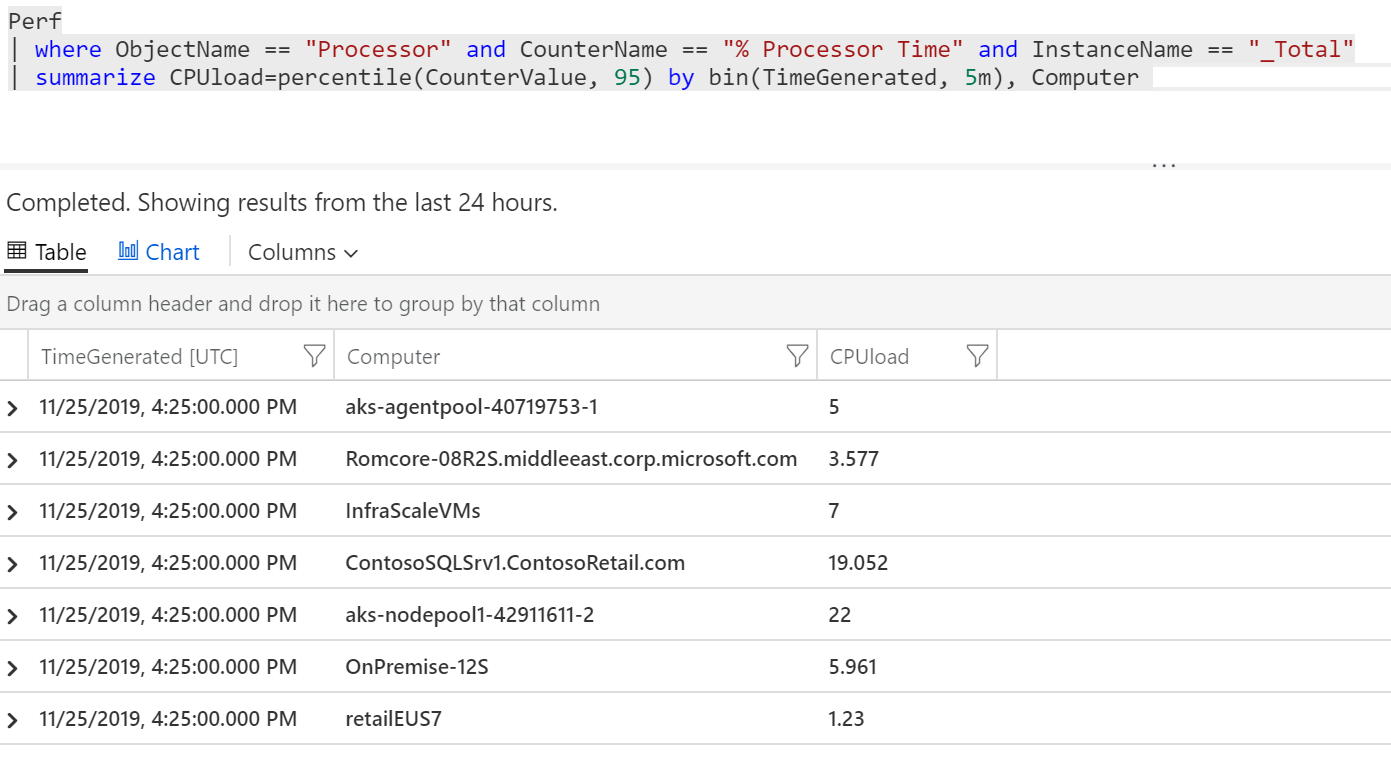
Aby graf mohl vzniknout, potřebuji údaje učesat. Každý Computer teoreticky může odečítat countery v jiných intervalech a třeba taková vteřinová granularita v obrázku za poslední měsíc by vykreslovala milion teček a trvala by nesmyslně dlouho. Chci tedy data sumarizovat do nějakých fixních časových oken, třeba pětiminutových intervalů. Řeknu tedy: nasekej data do pětiminutových intervalů a z hodnot v nich udělej agregaci, konkrétně 95-tý percentil a kromě sumarizace podle časových oken to chci ještě podle Computer.
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUload=percentile(CounterValue, 95) by bin(TimeGenerated, 5m), Computer
Textově výsledek vypadá takhle a všimněte si, že časy jsou “hezké”, tedy pětiminutové intervaly.
Nechám si udělat time chart.
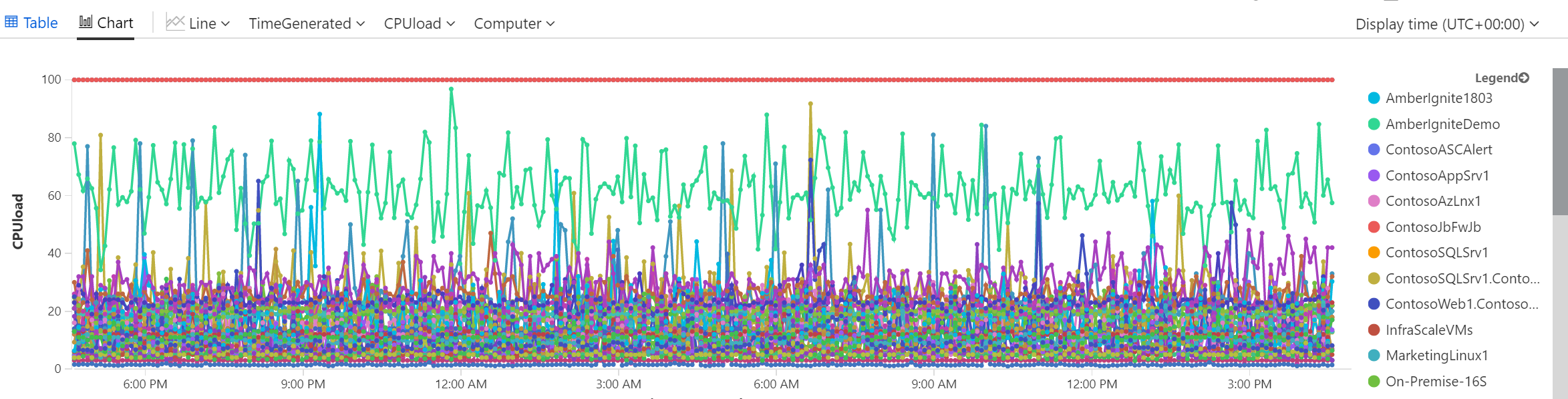
Krása, ale je tam toho strašně moc - není to přehledné.
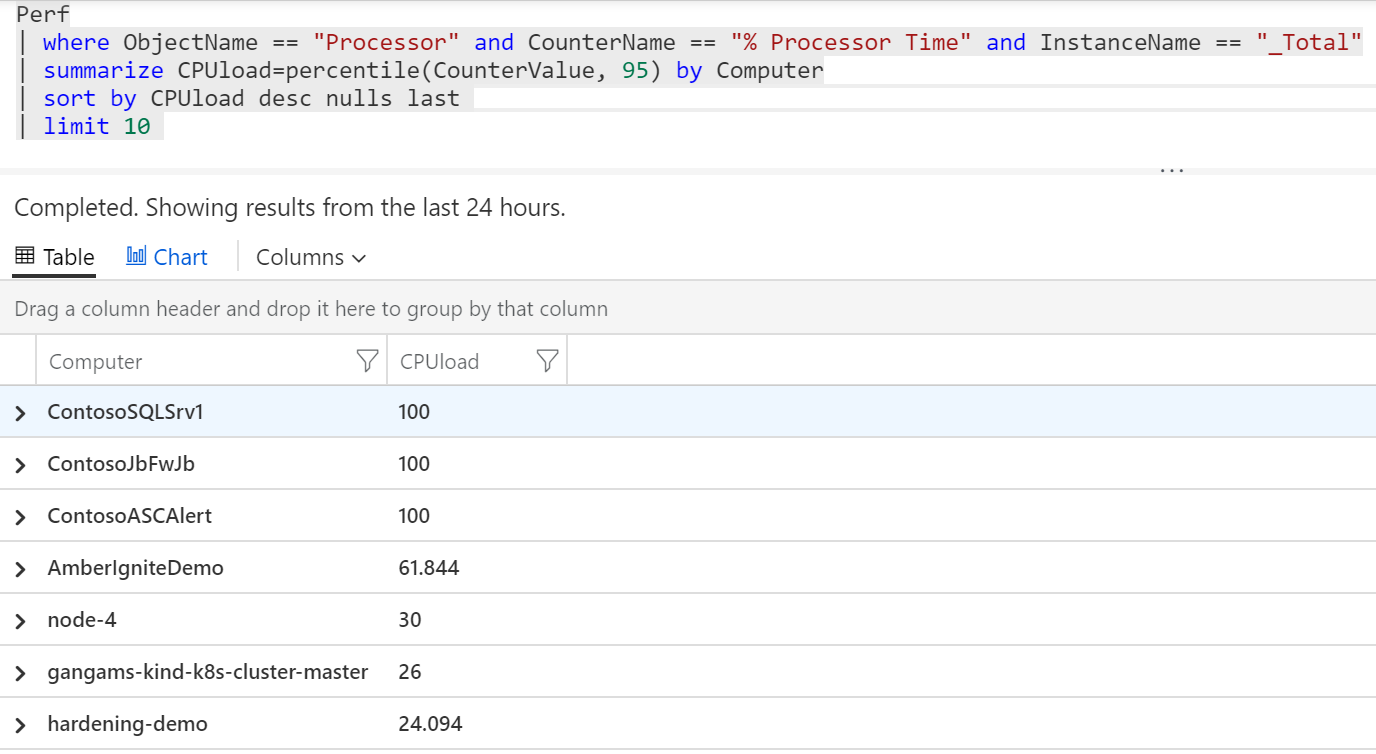
Co kdybychom si tedy udělali graf jen z těch systémů, které jsou na tom nejhůř co se týče celkového percentilu zatížení. Nejprve musím najít 10 nejhorších. Takový dotaz jsme tady už měli, jen si ho setřídím a oříznu na deset.
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUload=percentile(CounterValue, 95) by Computer
| sort by CPUload desc nulls last
| limit 10
Výborně - teď z nich budu chtít udělat graf. Použijeme tedy join. Prvním dotazem dostanu 10 celkově nejhorších a teprve pro ně si nechám udělat sumarizaci hodnot po intervalech. V tomto případě budu chtít použít inner join, tedy ve výsledku chci mít jen ty Computers, které jsem vybral prvním dotazem, ostatní mě nezajímají. Join provedu přes Computer a ve výsledné tabulce nepotřebuji duplikátní Computer1 a také tam nechci mít CPUload, který jsem použil pro selekci v prvním dotazu. Do grafu chci jen CPUtrend, který jsem počítal v druhém dotazu.
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUload=percentile(CounterValue, 95) by Computer
| sort by CPUload desc nulls last
| limit 10
| join kind= inner (
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUtrend=percentile(CounterValue, 95) by bin(TimeGenerated, 15m), Computer
) on Computer
| project-away Computer1, CPUload
Po zakreslení do grafu mám tento o poznání přehlednější výsledek.
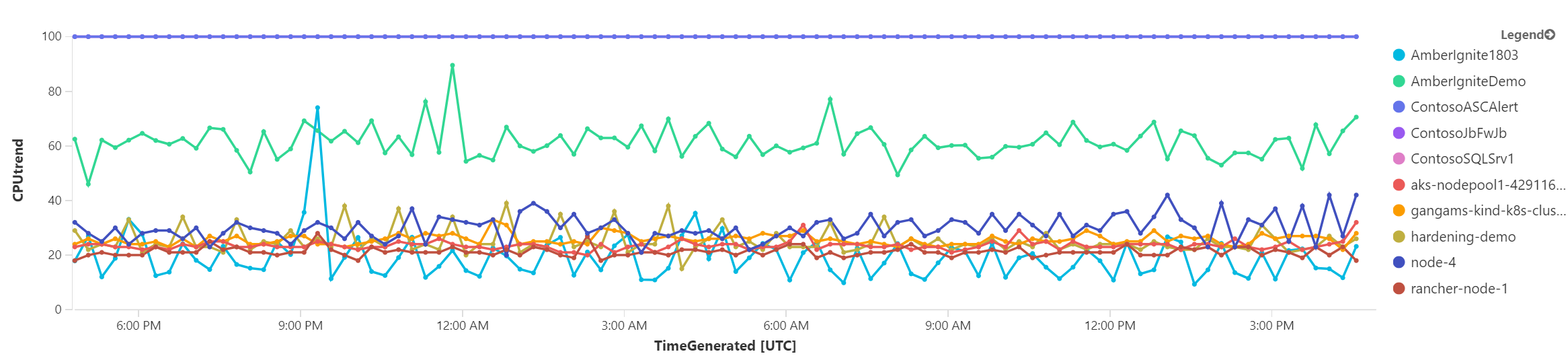
Vyzkoušejme ještě něco jiného. Co kdybychom si nechali vypsat ty stroje, jejich zátěž je nejméně rovnoměrná (tedy graf je nejklikatější). K tomu použiji funkci směrodatné odchylky a vyberu si 3 nejklikatější a ty pak vygreslím.
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize stdev=stdev(CounterValue) by Computer
| sort by stdev desc
| limit 3
| join kind= inner (
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUtrend=percentile(CounterValue, 95) by bin(TimeGenerated, 15m), Computer
) on Computer
| project-away Computer1, stdev
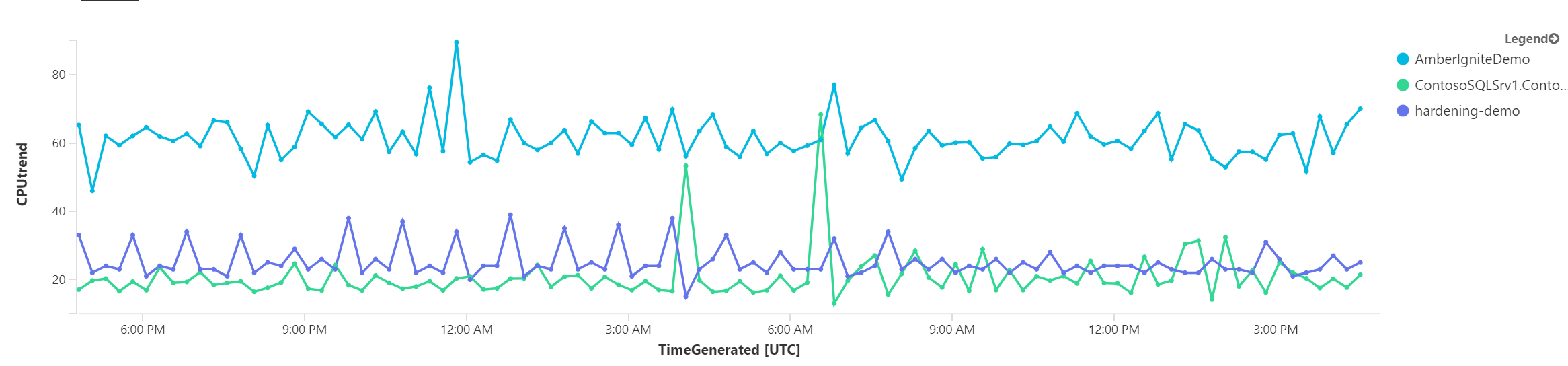
Abych se ujistil, že to funguje, zkusím opak, tedy tři nejvyrovnanější servery.
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize stdev=stdev(CounterValue) by Computer
| sort by stdev asc
| limit 3
| join kind= inner (
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUtrend=percentile(CounterValue, 95) by bin(TimeGenerated, 15m), Computer
) on Computer
| project-away Computer1, stdev
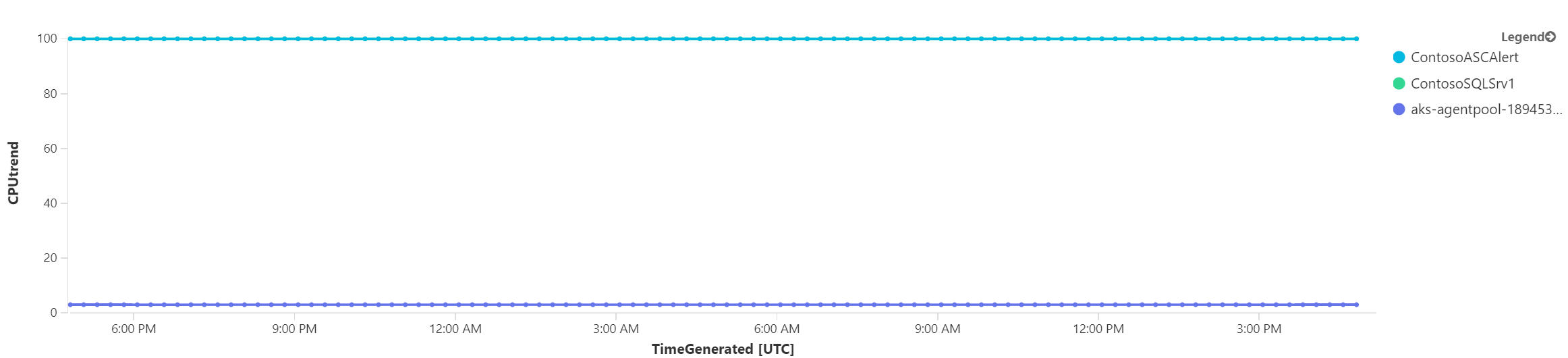
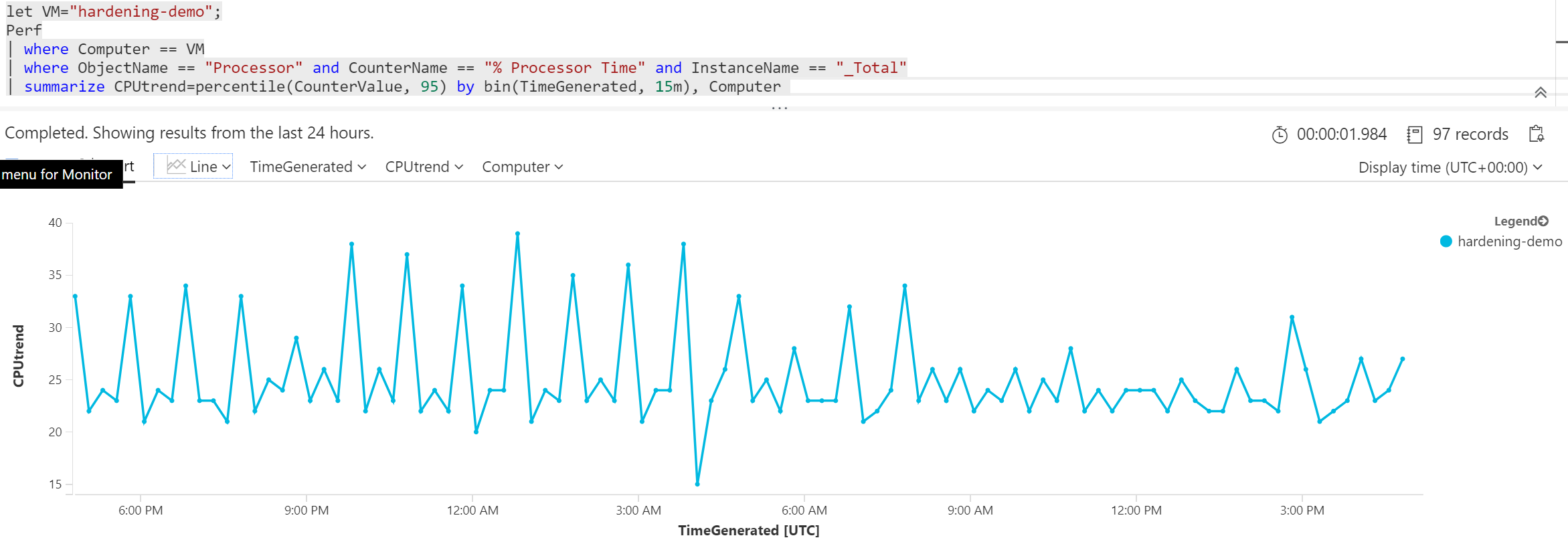
Co když bych chtěl stopovat jen jedno konkrétní VM. Samozřejmě pak použiji where na název takového VM, ale pro uživatele bude složité to v kódu najít. Kusto umožňuje definovat proměnné příkazem let. Stačí pak změnit let na začátku a nemusím se hrabat vnitřkem dotazu. Jak uvidíte v jiném díle, ve Workbooku můžu dát uživatelům jednoduché tlačítko na selekci stroje, ale i tak se vyplatí tyto měnící se věci vyndat z query ven do proměnné.
let VM="hardening-demo";
Perf
| where Computer == VM
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| summarize CPUtrend=percentile(CounterValue, 95) by bin(TimeGenerated, 15m), Computer
Na závěr této sekce si ukažme ještě jednu fintu. Občas bych potřeboval vzít vrácená data s hromadou řádků a hodnoty counterů vzít a vyrobit z nich časovou řadu, tedy pole, které bude uvnitř jednoho sloupečku na jednom řádku. Má to dvě zásadní použití. Tím první jsou sofistikovanější možnosti analýzy časových řad tak, jak to budeme za chvilku dělat. Tou druhou jsou vizualizace ve Workbooku. Tam totiž můžete chtít udělat tabulku strojů, v nich agregovaného hodnoty zatížení CPU, ale v té samé tabulce mít vložený malý grafík s vývojem zatíženosti CPU. Tedy vizualizuji do řádků, ale historii counteru počítače uložím do jednoho sloupečku té stejné řádky jako pole, což mi Workbook vykreslí jako malý graf na řádku. Ale k tomu se dostaneme. Zatím se podíváme jen na to, jak vypadá výsledek make-series příkladu. Tomu předávám políčko s hodnotami (v našem případě CounterValue) a jak má časovou řadu sumarizovat. Já použil posledních 7 dní v časových oknech jedné hodiny.
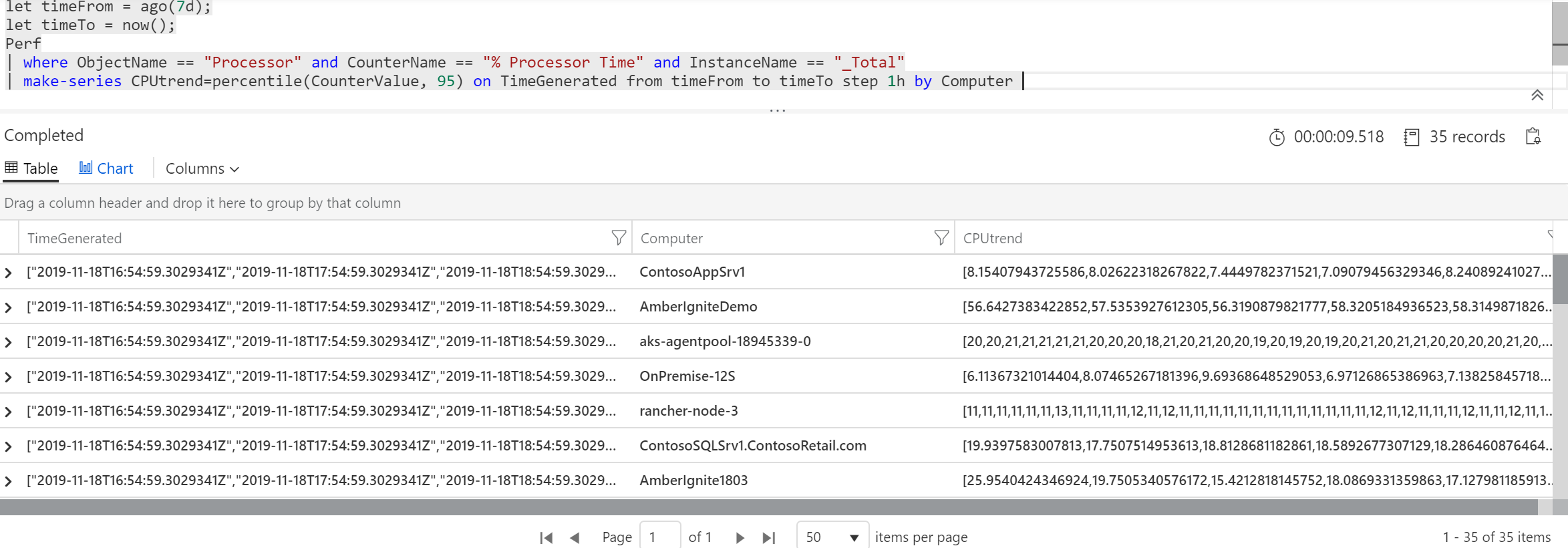
let timeFrom = ago(7d);
let timeTo = now();
Perf
| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total"
| make-series CPUtrend=percentile(CounterValue, 95) on TimeGenerated from timeFrom to timeTo step 1h by Computer
Na to jak náročná operace to je a kolik dat zpracovávám dostávám výsledek do deseti vteřin, což mi přijde úžasné.
Diagnostické metriky z PaaS
Ještě než se pustíme do sofistikovanější dotazů bych rád zmínil, že jsou v rámci Azure Monitor i jiné tabulky, které mne mohou zajímat z pohledu telemetrie. Platformní služby v Azure mají na sobě záložku Diagnostic Settings, která umožňuje namířit jak logy tak telemetrii do Azure Monitor tak, že nad nimi můžete dělat dotazy tak, jak jsme to dělali pro tabulku Perf. Zajímat mě bude tabulka AzureMetrics a podívám se, jaké typy zdrojů tam já aktuálně vidím, tedy pro jaké typy mám zapnuté sbírání. Nutno ještě podotknout, že Azure pozvolna přecházení na vytváření specializovaných tabulek per-PaaS služba, což povede k větší přehlednosti a rychlosti zpracování dat. Nicmeně pro dnešek zůstaneme v AzureMetrics tabulce.
AzureMetrics
| distinct ResourceProvider
Pár jich sbírám a to zdaleka ne všechny. Dejme tomu, že mě zajímá konkrétní WebApp. Podívám se, jaké metriky tam najdu.
let WebApp = "CONTOSORETAIL-USAGE-GENERATOR";
AzureMetrics
| where Resource == WebApp
| where ResourceProvider == "MICROSOFT.WEB"
| distinct MetricName
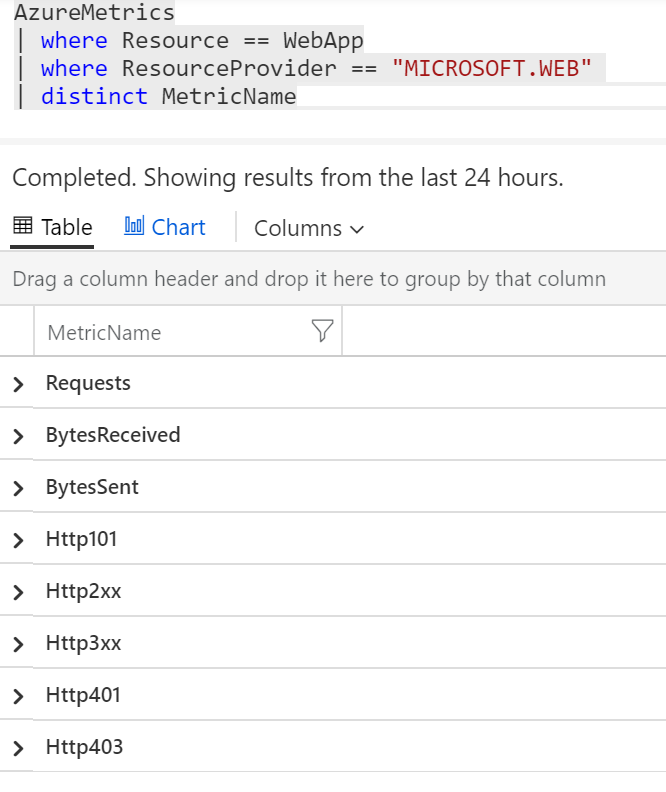
Jsou to tedy přístupy, přenesená data, počty úspěšných volání, počty chybových stavů typu návratové kódy 400 či 500. Dejme tomu, že si chci namalovat requesty za posledních 7 dní a zajímá mne průměr v časových oknech 15 minut.
let WebApp = "CONTOSORETAILWEB";
let timeFrom = ago(7d);
let timeTo = now();
AzureMetrics
| where TimeGenerated >= timeFrom and TimeGenerated < timeTo
| where Resource == WebApp
| where ResourceProvider == "MICROSOFT.WEB" and MetricName == "Requests"
| summarize requests=avg(Average) by bin(TimeGenerated, 15m)
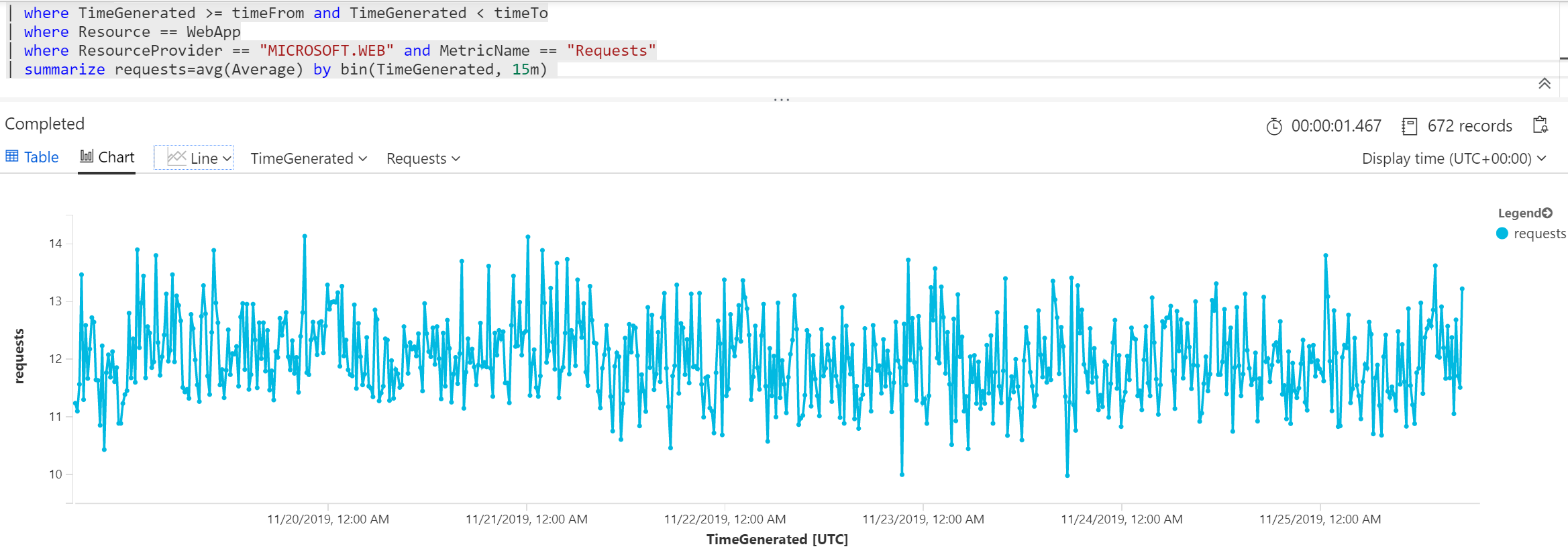
Pokud se vám graf líbí, můžete ho klidně rovnou připnout na svůj Dashboard. Později si ukážeme, jak tyto dotazy použít pro vytváření Workbooků, tedy interaktivních sestav.
Hrátky s časovými řadami
V poslední části se budeme věnovat pokročilejší práci s časovými řadami. Abyste si to mohli také sami vyzkoušet a dostali jste stejné výsledky, nebudu pracovat s reálnými daty, ale vytvořím si fixní tabulku v paměti a dotazy budu klást nad ní.
datatable (Date:datetime, Counter:int)
[
datetime(2019-09-23), 72,
datetime(2019-09-24), 64,
datetime(2019-09-25), 65,
datetime(2019-09-26), 74,
datetime(2019-09-27), 43,
datetime(2019-09-28), 7,
datetime(2019-09-29), 12,
datetime(2019-09-30), 79,
datetime(2019-10-01), 66,
datetime(2019-10-02), 63,
datetime(2019-10-03), 77,
datetime(2019-10-04), 41,
datetime(2019-10-05), 12,
datetime(2019-10-06), 15,
datetime(2019-10-07), 78,
datetime(2019-10-08), 64,
datetime(2019-10-09), 67,
datetime(2019-10-10), 73,
datetime(2019-10-11), 45,
datetime(2019-10-12), 13,
datetime(2019-10-13), 11,
datetime(2019-10-14), 210,
datetime(2019-10-15), 69,
datetime(2019-10-16), 62,
datetime(2019-10-17), 71,
datetime(2019-10-18), 48,
datetime(2019-10-19), 11,
datetime(2019-10-20), 12,
datetime(2019-10-21), 88,
datetime(2019-10-22), 72,
datetime(2019-10-23), 34,
datetime(2019-10-24), 68,
datetime(2019-10-25), 41,
datetime(2019-10-26), 8,
datetime(2019-10-27), 10,
datetime(2019-10-28), 90,
datetime(2019-10-29), 69,
datetime(2019-10-30), 62,
datetime(2019-10-31), 71,
datetime(2019-11-01), 45,
datetime(2019-11-02), 12,
datetime(2019-11-03), 11
]
| limit 100
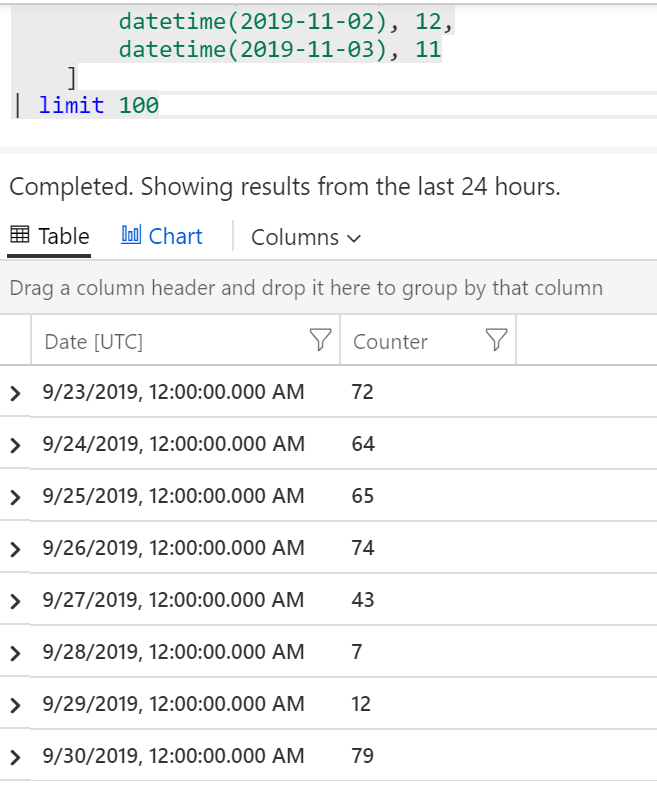
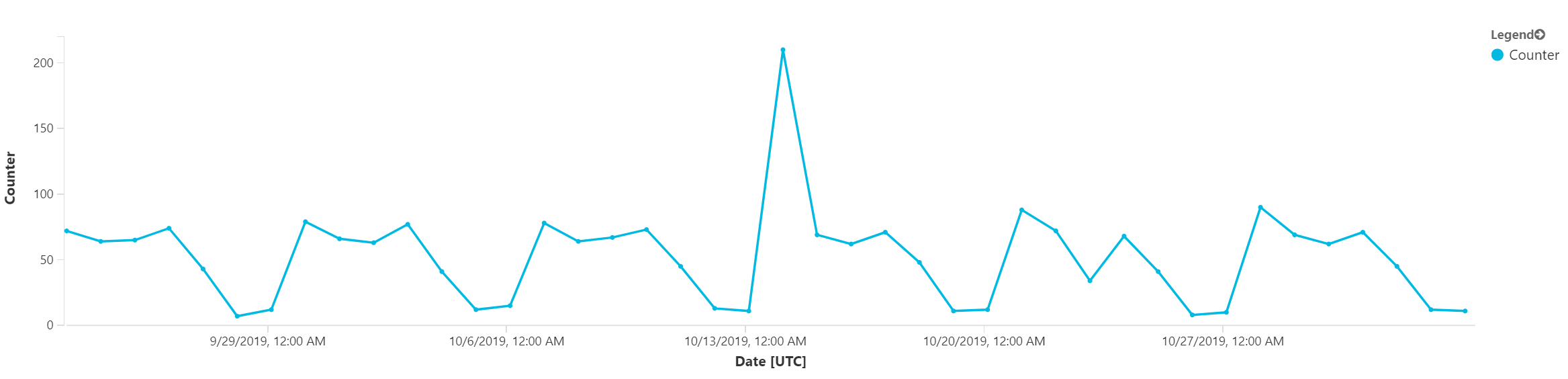
Nejdřív si data poskládáme do časové řady, tedy místo řádků z toho chci pole.
datatable (Date:datetime, Counter:int)
[
datetime(2019-09-23), 72,
datetime(2019-09-24), 64,
datetime(2019-09-25), 65,
datetime(2019-09-26), 74,
datetime(2019-09-27), 43,
datetime(2019-09-28), 7,
datetime(2019-09-29), 12,
datetime(2019-09-30), 79,
datetime(2019-10-01), 66,
datetime(2019-10-02), 63,
datetime(2019-10-03), 77,
datetime(2019-10-04), 41,
datetime(2019-10-05), 12,
datetime(2019-10-06), 15,
datetime(2019-10-07), 78,
datetime(2019-10-08), 64,
datetime(2019-10-09), 67,
datetime(2019-10-10), 73,
datetime(2019-10-11), 45,
datetime(2019-10-12), 13,
datetime(2019-10-13), 11,
datetime(2019-10-14), 210,
datetime(2019-10-15), 69,
datetime(2019-10-16), 62,
datetime(2019-10-17), 71,
datetime(2019-10-18), 48,
datetime(2019-10-19), 11,
datetime(2019-10-20), 12,
datetime(2019-10-21), 88,
datetime(2019-10-22), 72,
datetime(2019-10-23), 34,
datetime(2019-10-24), 68,
datetime(2019-10-25), 41,
datetime(2019-10-26), 8,
datetime(2019-10-27), 10,
datetime(2019-10-28), 90,
datetime(2019-10-29), 69,
datetime(2019-10-30), 62,
datetime(2019-10-31), 71,
datetime(2019-11-01), 45,
datetime(2019-11-02), 12,
datetime(2019-11-03), 11
]
| make-series counter=avg(Counter) on Date from datetime(2019-09-23) to datetime(2019-11-03) step 1d

První pokročilejší funkcí, kterou použijeme, bude detekce anomálií. Funkce series_decompose_anomalies nám vrátí hodnotu 0 pro ty hodnoty časové řady, které nijak nevybočují a zdají se OK. Tam kde jde o nějakou anomálii vrátí nějaké kladné či záporné číslo. Čím větší (v absolutní hodnotě) toto číslo je, tím vážnější je odchylka od normálu. S tím se dá v query různě pracovat a korelovat to třeba s jinými údaji, například hláškami z logů, ale o tom až příště. My si zakreslíme výsledek funkce detekce anomálie do grafu a uvidíme tak kde si myslí, že je vážná odchylka.
datatable (Date:datetime, Counter:int)
[
datetime(2019-09-23), 72,
datetime(2019-09-24), 64,
datetime(2019-09-25), 65,
datetime(2019-09-26), 74,
datetime(2019-09-27), 43,
datetime(2019-09-28), 7,
datetime(2019-09-29), 12,
datetime(2019-09-30), 79,
datetime(2019-10-01), 66,
datetime(2019-10-02), 63,
datetime(2019-10-03), 77,
datetime(2019-10-04), 41,
datetime(2019-10-05), 12,
datetime(2019-10-06), 15,
datetime(2019-10-07), 78,
datetime(2019-10-08), 64,
datetime(2019-10-09), 67,
datetime(2019-10-10), 73,
datetime(2019-10-11), 45,
datetime(2019-10-12), 13,
datetime(2019-10-13), 11,
datetime(2019-10-14), 210,
datetime(2019-10-15), 69,
datetime(2019-10-16), 62,
datetime(2019-10-17), 71,
datetime(2019-10-18), 48,
datetime(2019-10-19), 11,
datetime(2019-10-20), 12,
datetime(2019-10-21), 88,
datetime(2019-10-22), 72,
datetime(2019-10-23), 34,
datetime(2019-10-24), 68,
datetime(2019-10-25), 41,
datetime(2019-10-26), 8,
datetime(2019-10-27), 10,
datetime(2019-10-28), 90,
datetime(2019-10-29), 69,
datetime(2019-10-30), 62,
datetime(2019-10-31), 71,
datetime(2019-11-01), 45,
datetime(2019-11-02), 12,
datetime(2019-11-03), 11
]
| make-series series=avg(Counter) on Date from datetime(2019-09-23) to datetime(2019-11-03) step 1d
| extend series_decompose_anomalies(series)
| project Date, series, anomaly=series_decompose_anomalies_series_ad_score

První odchylka směrem nahoru je samozřejmě viditelná na první pohled. Ta druhá směrem dolu už možná až tak ne. Detekce anomálie bere v úvahu i seazonalitu (k tomu se hned dostaneme) a ta odchylka směrem dolu není obvyklá (už je vám jistě zřejmé, že vždy v sobotu a v neděli je tam propad dolu a s tím počítáme, ale tohle bylo uprostřed týdne). Teď si představte, že máte enormní množství dat a nevíte přesně kde hledat - tam se vám taková detekce může nesmírně hodit. Dá se na základě toho třeba udělat alarm a tak podobně. Tohle už je opravdu chytré a může vám to dost pomoci.
Hodně je to o tom, že analýzou časové řady je nějaká pro mě asi moc složitá matematika schopná oddělit složku baseline, ve které zvládá identifikovat nějaké opakující se patterny od celkového trendu. Něco takového si můžeme zobrazit.
datatable (Date:datetime, Counter:int)
[
datetime(2019-09-23), 72,
datetime(2019-09-24), 64,
datetime(2019-09-25), 65,
datetime(2019-09-26), 74,
datetime(2019-09-27), 43,
datetime(2019-09-28), 7,
datetime(2019-09-29), 12,
datetime(2019-09-30), 79,
datetime(2019-10-01), 66,
datetime(2019-10-02), 63,
datetime(2019-10-03), 77,
datetime(2019-10-04), 41,
datetime(2019-10-05), 12,
datetime(2019-10-06), 15,
datetime(2019-10-07), 78,
datetime(2019-10-08), 64,
datetime(2019-10-09), 67,
datetime(2019-10-10), 73,
datetime(2019-10-11), 45,
datetime(2019-10-12), 13,
datetime(2019-10-13), 11,
datetime(2019-10-14), 210,
datetime(2019-10-15), 69,
datetime(2019-10-16), 62,
datetime(2019-10-17), 71,
datetime(2019-10-18), 48,
datetime(2019-10-19), 11,
datetime(2019-10-20), 12,
datetime(2019-10-21), 88,
datetime(2019-10-22), 72,
datetime(2019-10-23), 34,
datetime(2019-10-24), 68,
datetime(2019-10-25), 41,
datetime(2019-10-26), 8,
datetime(2019-10-27), 10,
datetime(2019-10-28), 90,
datetime(2019-10-29), 69,
datetime(2019-10-30), 62,
datetime(2019-10-31), 71,
datetime(2019-11-01), 45,
datetime(2019-11-02), 12,
datetime(2019-11-03), 11
]
| make-series series=avg(Counter) on Date from datetime(2019-09-23) to datetime(2019-11-03) step 1d
| extend series_decompose(series)
| project Date, series, baseline=series_decompose_series_baseline, trend=series_decompose_series_trend
Podívejme se na výsledný graf.
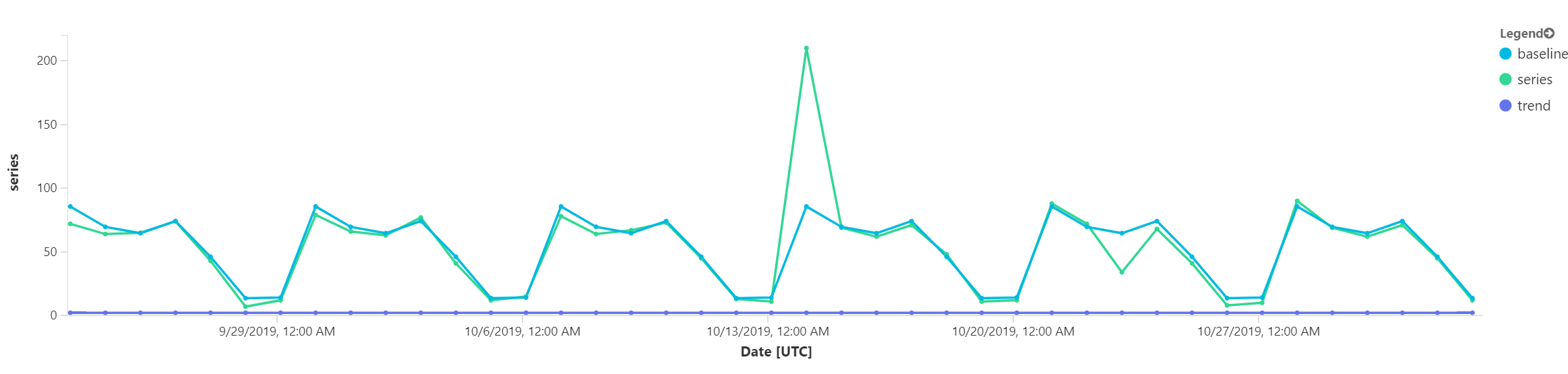
Je patrné, že celkový trend je rovný a modrá baseline celkem stínuje zelené skutečné hodnoty. Ale vidíme, že se to jednou rozešlo hodně nahoru a podruhé trochu dolu. No a to jsou ty anomálie, které jsme viděli v tom grafu před tím.
Evidentně se nám tady podařilo zachytit nějaký pattern (u našeho jednoduchého příkladu je jasně vidět). Můžeme si nechat tento najít funkcí series_periods_detect s tím, že minimální délka periody bude 1 vzorek, maximální dám 8 a chci maximálně 3 periody.
datatable (Date:datetime, Counter:int)
[
datetime(2019-09-23), 72,
datetime(2019-09-24), 64,
datetime(2019-09-25), 65,
datetime(2019-09-26), 74,
datetime(2019-09-27), 43,
datetime(2019-09-28), 7,
datetime(2019-09-29), 12,
datetime(2019-09-30), 79,
datetime(2019-10-01), 66,
datetime(2019-10-02), 63,
datetime(2019-10-03), 77,
datetime(2019-10-04), 41,
datetime(2019-10-05), 12,
datetime(2019-10-06), 15,
datetime(2019-10-07), 78,
datetime(2019-10-08), 64,
datetime(2019-10-09), 67,
datetime(2019-10-10), 73,
datetime(2019-10-11), 45,
datetime(2019-10-12), 13,
datetime(2019-10-13), 11,
datetime(2019-10-14), 210,
datetime(2019-10-15), 69,
datetime(2019-10-16), 62,
datetime(2019-10-17), 71,
datetime(2019-10-18), 48,
datetime(2019-10-19), 11,
datetime(2019-10-20), 12,
datetime(2019-10-21), 88,
datetime(2019-10-22), 72,
datetime(2019-10-23), 34,
datetime(2019-10-24), 68,
datetime(2019-10-25), 41,
datetime(2019-10-26), 8,
datetime(2019-10-27), 10,
datetime(2019-10-28), 90,
datetime(2019-10-29), 69,
datetime(2019-10-30), 62,
datetime(2019-10-31), 71,
datetime(2019-11-01), 45,
datetime(2019-11-02), 12,
datetime(2019-11-03), 11
]
| make-series series=avg(Counter) on Date from datetime(2019-09-23) to datetime(2019-11-03) step 1d
| extend series_periods_detect(series, 1, 8, 3)
Našla se jedna perioda o délce 7 dní.

Pokud by byla data složitější, pravděpodobně bychom jich našli víc. Třeba jeden cyklus během dne (pracovní doba), jeden během týdne (pracovní dny) a jeden třeba roční (Vánoce).
Zakončíme předvídáním budoucnosti. Funkci make-series teď přetáhnu o 7 dní do “budoucnosti”, tedy tam nemám data a tím pádem to budou logicky nuly. Nicméně těch 7 dalších hodnot si nechám předpovědět.
datatable (Date:datetime, Counter:int)
[
datetime(2019-09-23), 72,
datetime(2019-09-24), 64,
datetime(2019-09-25), 65,
datetime(2019-09-26), 74,
datetime(2019-09-27), 43,
datetime(2019-09-28), 7,
datetime(2019-09-29), 12,
datetime(2019-09-30), 79,
datetime(2019-10-01), 66,
datetime(2019-10-02), 63,
datetime(2019-10-03), 77,
datetime(2019-10-04), 41,
datetime(2019-10-05), 12,
datetime(2019-10-06), 15,
datetime(2019-10-07), 78,
datetime(2019-10-08), 64,
datetime(2019-10-09), 67,
datetime(2019-10-10), 73,
datetime(2019-10-11), 45,
datetime(2019-10-12), 13,
datetime(2019-10-13), 11,
datetime(2019-10-14), 210,
datetime(2019-10-15), 69,
datetime(2019-10-16), 62,
datetime(2019-10-17), 71,
datetime(2019-10-18), 48,
datetime(2019-10-19), 11,
datetime(2019-10-20), 12,
datetime(2019-10-21), 88,
datetime(2019-10-22), 72,
datetime(2019-10-23), 34,
datetime(2019-10-24), 68,
datetime(2019-10-25), 41,
datetime(2019-10-26), 8,
datetime(2019-10-27), 10,
datetime(2019-10-28), 90,
datetime(2019-10-29), 69,
datetime(2019-10-30), 62,
datetime(2019-10-31), 71,
datetime(2019-11-01), 45,
datetime(2019-11-02), 12,
datetime(2019-11-03), 11
]
| make-series series=avg(Counter) on Date from datetime(2019-09-23) to datetime(2019-11-09) step 1d
| extend forecast=series_decompose_forecast(series, 7, -1, 'linefit', 0.1)
Podívejte na poslední týden grafu. Zelená je nula, protože jsme v budoucnosti, ale modré je predikce.
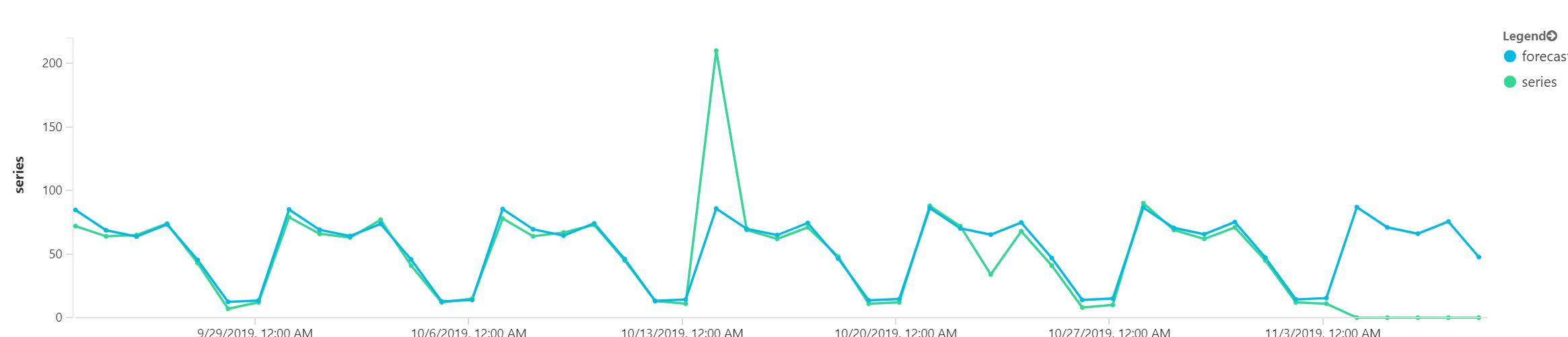
Dnes jsme si vzali v jazyce Kusto do parády telemetrii. Připomínám, že datové zdroje do Azure Monitor jsou agenti ve VM, parametry všech platformních služeb včetně databází, síťových prvků či aplikačních platforem, patří sem i správa Kubernetes prostředí nebo aplikační telemetrie přes Application Insights. Nad tím vším můžete klást jednoduché i složitější dotazy. A ty bude pak ideální vizualizovat ve Workbooku, korelovat mezi sebou nebo obohatit o logy. A to všechno budou další témata v sérii článků o Kusto. A mimochodem - pokud se vám to líbí, ale chtěli byste pod tím mít svoje ne-IT data jako jsou telemetrie z IoT senzorů, vytočte si svůj vlastní Kusto cluster s Azure Data Explorer a dejte si tam úplně co chcete.