Aplikace v Kubernetes mají smysl pouze tehdy, když se k nim dá připojit. Deployment vám umožní běžet víc instancí kontejnerů a integrovaná service discovery dovoluje ostatním mikroslužbám tyto Pody najít. Předpokládám ale, že pro většinu situací nebudete chtít discovery provádět sami a uvítáte jednu virtuální IP, která bude zátěž rozhazovat na jednotlivé instance. A udělat službu dostupnou pro klienty mimo cluster? Jak se sticky session? Jaká bude zdrojová IP? A jak to vlastně celé funguje? Podívejme se dnes na Service v Kubernetes.
Koncept Service vs. vaše vlastní discovery vs. Ingress
Objekt Deployment vám vytvoří a udržuje instance Podů a díky integrovanému service discovery může váš klient ve formě druhé mikroslužby všechny tyto instance najít. Dokážete tak implementovat vlastní mechanismus balancování. Většinou ale budete chtít, aby pro vás Kubernetes něco takového udělal sám.
Dnes se zaměříme na Service. Jde (v základním nastavení) o vytvoření virtuální IP adresy pro vaše Pody, která pro vás zaregistruje DNS jméno uvnitř clusteru a bude zátěž rozhazovat. Je to implementované tak, že každý node clusteru si tuto IP “vezme”. Ona ve skutečnosti není přiřazena žádnému konkrétnímu interface, ale je použita v iptables, které jsou pod kapotou (pracuje se i na ještě výkonější implementaci ipvs). O zakládání těchto pravidel se stará komponenta kube-proxy na každém nodu. Existuje víc režimů jak může Service fungovat a na ty se dnes podíváme. Podstatné ale je, že všechny níže předvedené implementace jsou L4. Nefungují tedy jako reverse proxy. Komunikace mezi klientem a Pody je přímá, celé je to tedy o směrování a případně NAT operacích. Věci jako certifikáty pro TLS tedy implementujete například v samotných Podech nebo naopak v nějaké WAFce ještě před celým clusterem případně přes Ingress nebo nějaký Service Mesh (Istio, Linkerd 2) v clusteru. Service má řadu výhod. Není závislá na HTTP (funguje pro jakýkoli protokol), dosahuje přímé komunikace klienta s vaším kódem a díky tomu má také po cestě méně komponent, což přispívá k nižší latenci.
Alternativou je použití již zmíněného Ingress, o kterém si řekneme někdy příště. Jedná se o L7 řešení, tedy reverse proxy. Díky tomu můžete provádět věci jako je URL směrování (podle cesty - například /images půjde jinam než /catalog) nebo TLS terminaci. Pro vystavování web serverů je to jistě velmi elegantní a ucelené řešení, proto se k němu v jiném článku vrátíme.
Volné vázání Service a Podů
Důležitým konceptem je to, že přiřazení Podů k Service není pevné hierarchické, ale využívá se selekce přes metadata. U Podů máte definované labely a právě ty používá Service pro identifikaci těch Podů, které jsou její součástí. To je velmi praktické. Můžete například vytvořit Service a ještě v ní žádné Pody nemít. Dokážete třeba udělat dva Deploymenty a oba přiřadit pod stejnou službu (třeba pro canary release). O technikách nasazování a upgradování aplikací si řekneme podrobněji jindy.
Interní služba s použitím ClusterIP
Začneme nasazením služby pouze pro interní účely clusteru, tzv. type ClusterIP. Takhle bude vypadat můj deployment. Jde o jednoduchou webovou aplikaci, která na výstupu vrací zdrojovou IP klienta, jméno Podu, Nodu a další informace. Zdroják aplikace a Dockerfile najdete na mém GitHub. Deploymentu přes downwards API předáváme informace o Podu a Nodech.
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: httpecho
spec:
replicas: 2
template:
metadata:
labels:
app: httpecho
spec:
containers:
- name: httpecho
image: tkubica/httpecho
ports:
- containerPort: 5000
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
Nad deploymentem si založíme základní Service (všimněte si selektoru).
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
Služba je dostupná jen uvnitř clusteru, tak si vytvořme jednoduchý Pod na testování.
kind: Pod
apiVersion: v1
metadata:
name: ubuntu
spec:
containers:
- name: ubuntu
image: ubuntu
command: ["bash"]
args: ["-c", "apt update && apt install -yq dnsutils curl && tail -f /dev/null"]
A můžeme vyzkoušet. Pro naše účely potřebujeme AKS cluster se třemi nody. Scheduler by měl rozmístit naše Pody automaticky na jiné Nody a protože máme dvě repliky, jeden Node ho mít nebude (to se nám bude hodit později).
kubectl apply -f deployment.yaml
kubectl apply -f serviceClusterIp.yaml
kubectl apply -f podUbuntu.yaml
V průběhu dnešní článku se nám bude hodit vědět IP adresu Nodů.
kubectl get nodes -o custom-columns=NAME:.metadata.name,IP:status.addresses[1].address
NAME IP
aks-nodepool1-40944020-vmss000001 192.168.0.105
aks-nodepool1-40944020-vmss000002 192.168.0.4
aks-nodepool1-40944020-vmss000003 192.168.0.206
Mám 3 nody a deployment httpecho má dvě repliky. Ve výchozím stavu by měl scheduler dát pody na dva různé Nody, což si ověříme.
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
httpecho-797967574f-5p9jn 1/1 Running 0 2m 192.168.0.102 aks-nodepool1-40944020-vmss000002
httpecho-797967574f-schtl 1/1 Running 0 2m 192.168.0.226 aks-nodepool1-40944020-vmss000003
ubuntu 1/1 Running 0 1d 192.168.1.31 aks-nodepool1-40944020-vmss000003
Služba je automaticky vystavena v interní DNS clusteru pod svým názvem httpecho. Použijeme dig a prozkoumáme tento záznam. Dig ovšem vyžaduje kompletní fqdn, které je v našem případě httpecho.default.svc.cluster.local (jméno služby, jméno namespace a k tomu svc.cluster.local).
kubectl get service httpecho
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpecho ClusterIP 192.168.7.125 <none> 80/TCP 3m
kubectl exec ubuntu -- dig httpecho.default.svc.cluster.local
; <<>> DiG 9.11.3-1ubuntu1.5-Ubuntu <<>> httpecho.default.svc.cluster.local
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 61893
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 2e9a623c34d37b4b (echoed)
;; QUESTION SECTION:
;httpecho.default.svc.cluster.local. IN A
;; ANSWER SECTION:
httpecho.default.svc.cluster.local. 5 IN A 192.168.7.125
;; Query time: 1 msec
;; SERVER: 192.168.4.10#53(192.168.4.10)
;; WHEN: Sat Feb 23 19:11:21 UTC 2019
;; MSG SIZE rcvd: 125
Přes kubectl exec oslovíme přes curl interní DNS jméno služby (stačí to krátké) a uděláme to víckrát. Měli bychom vidět, že dostaneme odpověď z obou instancí - balancing nám tedy funguje.
kubectl exec ubuntu -- curl -s httpecho
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 192.168.1.31
------
Headers:
Host: httpecho
User-Agent: curl/7.58.0
Accept: */*
kubectl exec ubuntu -- curl -s httpecho
Pod Name: httpecho-797967574f-5p9jn
Pod IP: 192.168.0.102
Node Name: aks-nodepool1-40944020-vmss000002
Node IP: 192.168.0.4
Client IP: 192.168.1.31
------
Headers:
Host: httpecho
User-Agent: curl/7.58.0
Accept: */*
Pokud vaše služba není stavová, je to ideální, protože zátěž bude hezky rozložena. Pokud ovšem držíte nějaký session state v paměti (což nedoporučuji, ale u kontejnerizace existujících aplikací to tak může být), budete možná potřebovat, aby Service podle zdrojové IP klienta posílala komunikaci stále na jednu instanci (na základě hash IP adresy). To se dá nastavit v definici Service takhle:
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
sessionAffinity: ClientIP
Pošleme tam nové nastavení a vyzkoušíme. Tentokrát bychom měli dostat i podruhé odpověď ze stejné instance. Držme ale na paměti, že zatímco u přístupu z mnoha klientů někde v Internetu kdy se zátěž statisticky rozloží docela dobře, v našem případě se ptáme z jednoho Podu do služby, zdrojová IP je tak stále stejná a balancing jsme defacto vypnuli. Pro komunikaci backend služeb mezi sebou je proto dost důležité vyvarovat se potřeby stavovosti na základě paměti.
kubectl apply -f serviceClusterIpSessionAffinity.yaml
kubectl exec ubuntu -- curl -s httpecho
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 192.168.1.31
------
Headers:
Host: httpecho
User-Agent: curl/7.58.0
Accept: */*
kubectl exec ubuntu -- curl -s httpecho
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 192.168.1.31
------
Headers:
Host: httpecho
User-Agent: curl/7.58.0
Accept: */*
Jak funguje balancování a externí přístup s NodePort
Pojďme trochu proniknout do tajů balancování a pro studijní účely použijeme variantu Service v režimu NodePort. Půjde o to, že služba začne být dostupná na IP adrese každého nodu Kubernetes clusteru na nějakém vysokém portu (později si všechno zautomatizujeme použitím typu LoadBalancer, kdy se automaticky sestaví i balancing v Azure - teď se nám ale NodePort hodí pro nahlédnutí pod kapotu).
Protože Nody mají pouze interní IP adresu VNETu (a zatím nebudeme používat Azure LB před tím), potřebujeme vytvořit testovací VM, která bude ve stejném VNETu. Není podporováno hodit ji do Kubernetes subnetu (ten mějte vyhražený jen pro AKS a nikdy tam nedávajte nic dalšího), takže mám ve VNETu subnety dva:
az network vnet subnet list -g aksnetwork --vnet-name aks-network -o table
AddressPrefix Name ProvisioningState ResourceGroup
--------------- ---------------- ------------------- ---------------
192.168.0.0/22 aks-subnet Succeeded aksnetwork
192.168.8.0/24 testingvm-subnet Succeeded aksnetwork
VM založím v testingvm-subnet.
az group create -n aks-testingvm -l westeurope
export subnetId=$(az network vnet subnet show -g aksnetwork --vnet-name aks-network -n testingvm-subnet --query id -o tsv)
az vm create -n testingvm \
-g aksnetwork \
--image UbuntuLTS \
--nsg "" \
--admin-username tomas \
--admin-password Azure12345678 \
--authentication-type password \
--size Standard_B1s \
--subnet $subnetId
Ještě, než se postíme dál, ukažme si jednu důležitou věc. Protože používáme AKS v režimu Advanced Networking, tedy s Azure CNI implementací, jsou Pody běžnou součástí našeho VNETu. To znamená, že z druhého subnetu (nebo i jiného VNETu přes peering či dokonce z on-premises přes VPNku neo ExpressRoute) můžeme přímo mluvit s Pody.
tomas@testingvm:~$ curl 192.168.0.102:5000
Pod Name: httpecho-797967574f-5p9jn
Pod IP: 192.168.0.102
Node Name: aks-nodepool1-40944020-vmss000002
Node IP: 192.168.0.4
Client IP: 192.168.8.4
------
Headers:
Host: 192.168.0.102:5000
User-Agent: curl/7.58.0
Accept: */*
Definici naší Service teď změníme na typ NodePort:
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: NodePort
Pošleme to tam a podíváme se, jaký port na hostiteli nám byl přidělen.
kubectl apply -f serviceNodePort.yaml
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpecho NodePort 192.168.7.125 <none> 80:31786/TCP 34m
kubernetes ClusterIP 192.168.4.1 <none> 443/TCP 19d
Připomeňme si, kde moje Pody běží.
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
httpecho-797967574f-5p9jn 1/1 Running 0 30m 192.168.0.102 aks-nodepool1-40944020-vmss000002
httpecho-797967574f-schtl 1/1 Running 0 30m 192.168.0.226 aks-nodepool1-40944020-vmss000003
ubuntu 1/1 Running 0 1d 192.168.1.31 aks-nodepool1-40944020-vmss000003
Připojme se do externí VM a vyzkoušejme, jak se to chová. Provedeme curl na IP adresu druhého nodu (vmss000002) našeho Kubernetes clusteru (192.168.0.$).
tomas@testingvm:~$ curl 192.168.0.4:31786
Pod Name: httpecho-797967574f-5p9jn
Pod IP: 192.168.0.102
Node Name: aks-nodepool1-40944020-vmss000002
Node IP: 192.168.0.4
Client IP: 192.168.0.4
------
Headers:
Host: 192.168.0.4:31786
User-Agent: curl/7.58.0
Accept: */*
Dostali jsme zpátky odpověď. V Host headeru vidíme, že jsme s naším curl kontaktovali 192.168.0.4 (tedy IP nodu). Vešli jsme do nodu a aplikovali se iptables. Výchozí implementace provádí source NAT, takže zdrojová IP paketu se mění na IP adresu nodu (hned uvidíme proč). Dostáváme odpověď z instance, která na nodu běží.
Zkusme to ještě jednou (nebo několikrát), jestli dostaneme i něco jiného. A je to tak:
tomas@testingvm:~$ curl 192.168.0.4:31786
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 192.168.0.4
------
Headers:
Host: 192.168.0.4:31786
User-Agent: curl/7.58.0
Accept: */*
Co to znamená? Dostali jsme odpověď od jiné instance. Ta ovšem neběží na nodu 192.168.0.4, ale na jiném. Service tedy balancuje provoz na instance bez ohledu na to odkud jsme do clusteru vstoupili. Aby to fungovalo a dosáhli jsme i na instanci na jiném nodu, musí Service provést source NAT. Dostali jsme se do nodu s IP adresou 192.168.0.206, na kterém běží druhý Pod. Ten odpověděl. Můžeme vidět, že zdrojová IP je IP toho nodu zatímco Host hlavička ukazuje původní požadavek (192.168.0.4).
To má ještě jeden efekt. Můžeme si to klidně namířit na node, na kterém žádný náš Pod neběží a přesto dostaneme odpověď!
tomas@testingvm:~$ curl 192.168.0.105:31786
Pod Name: httpecho-797967574f-5p9jn
Pod IP: 192.168.0.102
Node Name: aks-nodepool1-40944020-vmss000002
Node IP: 192.168.0.4
Client IP: 192.168.0.105
------
Headers:
Host: 192.168.0.105:31786
User-Agent: curl/7.58.0
Accept: */*
Tohle je tedy výchozí chování a je velmi praktické. Ať se dostanete kamkoli, Kubernetes vás k Podu dopraví. Balancing je férový a každý Pod má stejnou šanci dostat nějakou zátěž.
Jsou s tím ale spojené i dva méně příjemné efekty. Tak zaprvé Service musí používat Source NAT, takže se nám ztrácí IP adresa klienta. Pokud na ni máte něco navázaného (marketingová statistika s geo-lokací, whitelisting, rate-limit podle IP klienta apod.), nebude to fungovat. Druhá věc je, že i když jsme na Nodu s naším Podem, můžeme být směrováni na jiný Node - může se nám tedy zvyšovat latence. Oboje můžeme vyřešit použitím módu externalTrafficPolicy Local. To ale přináší zase jiné nevýhody. Vyzkoušejme si to.
Takhle bude vypadat pozměněná definice Service.
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: NodePort
externalTrafficPolicy: Local
Pošleme to tam.
kubectl apply -f serviceNodePortLocal.yaml
Z testovací VM si to namíříme na druhý node (192.168.0.4).
tomas@testingvm:~$ curl 192.168.0.4:31786
Pod Name: httpecho-797967574f-5p9jn
Pod IP: 192.168.0.102
Node Name: aks-nodepool1-40944020-vmss000002
Node IP: 192.168.0.4
Client IP: 192.168.8.4
------
Headers:
Host: 192.168.0.4:31786
User-Agent: curl/7.58.0
Accept: */*
I když to zkusíte několikrát, dostanete vždy dostaneme stejnou odpověď, protože na tomto nodu běží jen jedna instance Podu. Take vidíte, že v sekci Client IP vidíme skutečnou IP adresu klienta (pokud to tak ve vašem případě není, pak máte asi AKS cluster s Advanced Networking bez posledních updatů - tuto schopnost CNI implementace získala teprve nedávno). Všimněte si také, že pokud teď namíříme test na node, na kterém žádná instance není, nedostaneme žádnou odpověď!
Výhodou řešení je, že nemáme hop navíc (lepší latence) a IP adresa klienta zůstane zachována. Na druhou stranu musíme si ohlídat na který node komunikujeme (to ale lze elegantně vyřešit s Azure Load Balancer) a rozložení zátěže není optimální. Balancovat musíte mimo cluster na úrovni Azure LB a ten bude umisťovat provoz na nody bez ohledu na to, kolik instancí na nich běží. Pokud bude na jednom Nodu Podů 9 a na druhém nodu 1, tak oba nody dostanou 50% trafficu - takže první se bude flákat a druhý bude přetížený.
Pokud tedy potřebujete znát zdrojovou IP adresu a/nebo potřebujete minimalizovat latenci i za cenu horšího rozložení zátěže, použijte režim Local. Pokud například pro vstup do světa vaší aplikace používáte reverse proxy nasazenou v Kubernetes (například NGINX implementaci Ingresu), můžete ji nasadit jako DaemonSet, tedy mít ji puštěnou na každém Nodu a v ten okamžik dává určitě smysl použít Local a balancovat jen v externím balanceru (Azure LB).
Kompletní řešení s použitím infrastrukturního automatizovaného balanceru s LoadBalancer Service
Už umíme vystavit službu na venkovní IP adresu nodů, ale to není kompletní řešení. Rozhodně budeme chtít skutečnou jednu virtuální IP adresu pro naší službu, která bude platná ve venkovní síti nebo celém Internetu (public IP). Co pro to musíme udělat? Požádáme infrastrukturu. Můžeme vytvořit Azure Load Balancer, začlenit AKS nody do backend poolu, zjistit jaký port má služba na nodu a nastavit příslušné LB pravidlo. Nesmíme zapomenout na health probe pro případ, že by node měl nějaký problém (a zejména pro traffic policy Local, kdy na Nodu třeba vůbec není). Navíc při škálování či upgradech nesmíme zapomenout vše přenastavit na nové nebo změněné nody. To není zrovna praktické, že?
Všechno se dá zautomatizovat a udělat elegantněji s využitím Service typu LoadBalancer. Ta využije “driver” pro prostředí, ve kterém Kubernetes běží - v našem případě Azure - a zautomatizuje kompletní nastavení balanceru.
Takhle bude vypadat služba s type LoadBalancer.
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
Pošleme ji tam. Po nějaké době si vypíšeme naší službu a objeví se tam externí IP adresa.
kubectl apply -f serviceExt.yaml
kubectl get svc httpecho
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpecho LoadBalancer 192.168.7.125 40.118.18.20 80:31786/TCP 1h
Odkud se vzala? V MC resource group v Azure najdete externí Load Balancer a v něm IP adresu.
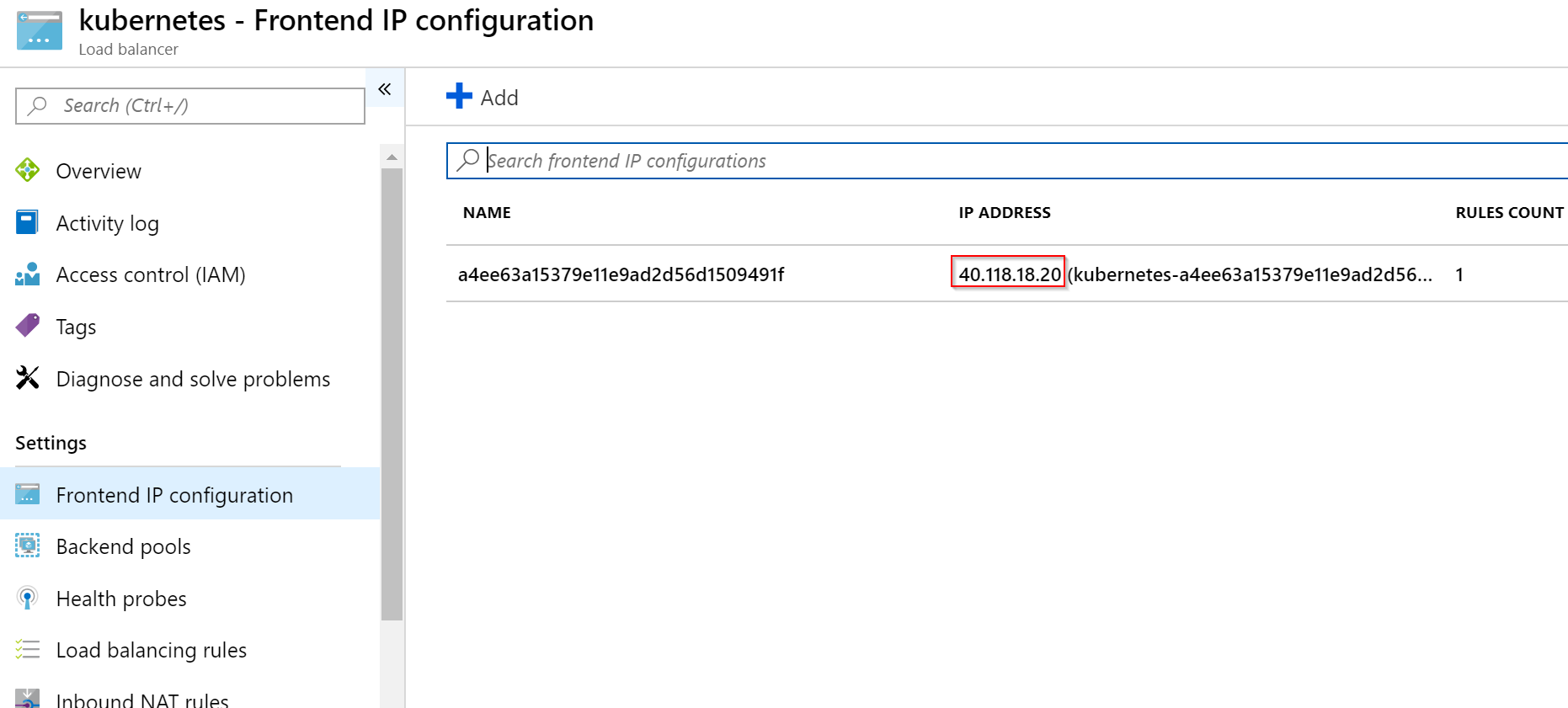
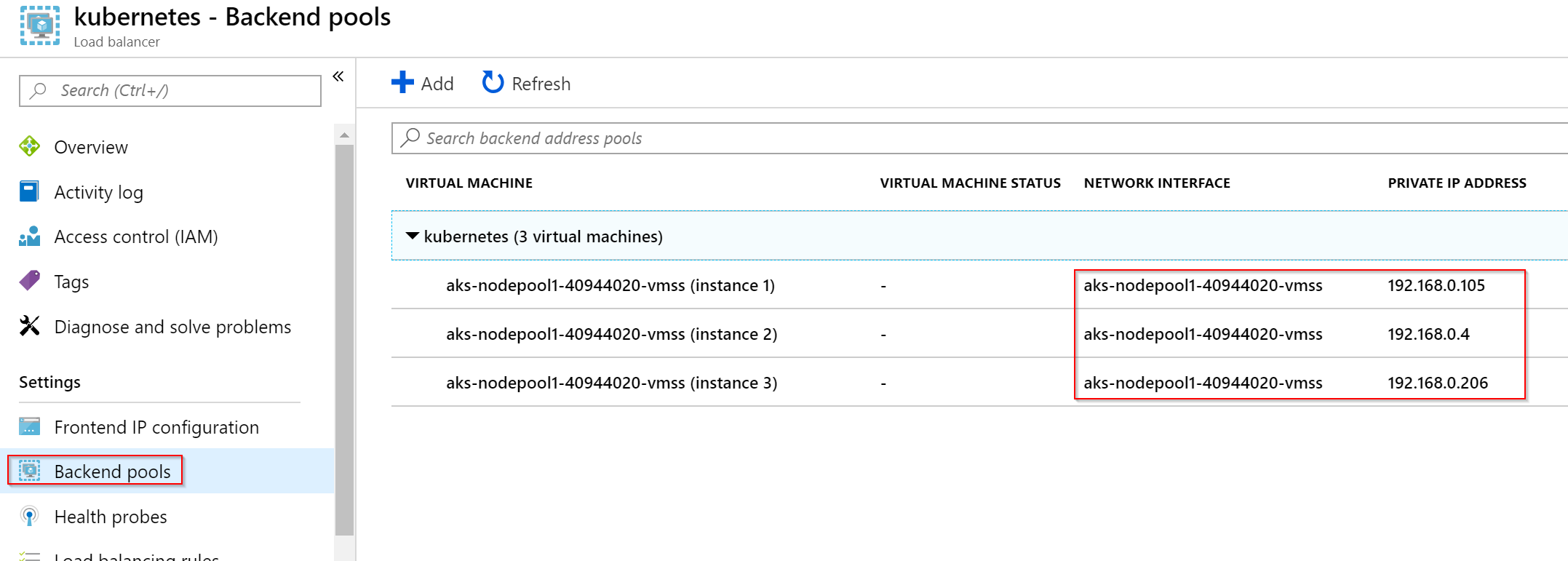
V backend poolu jsou všechny Nody.
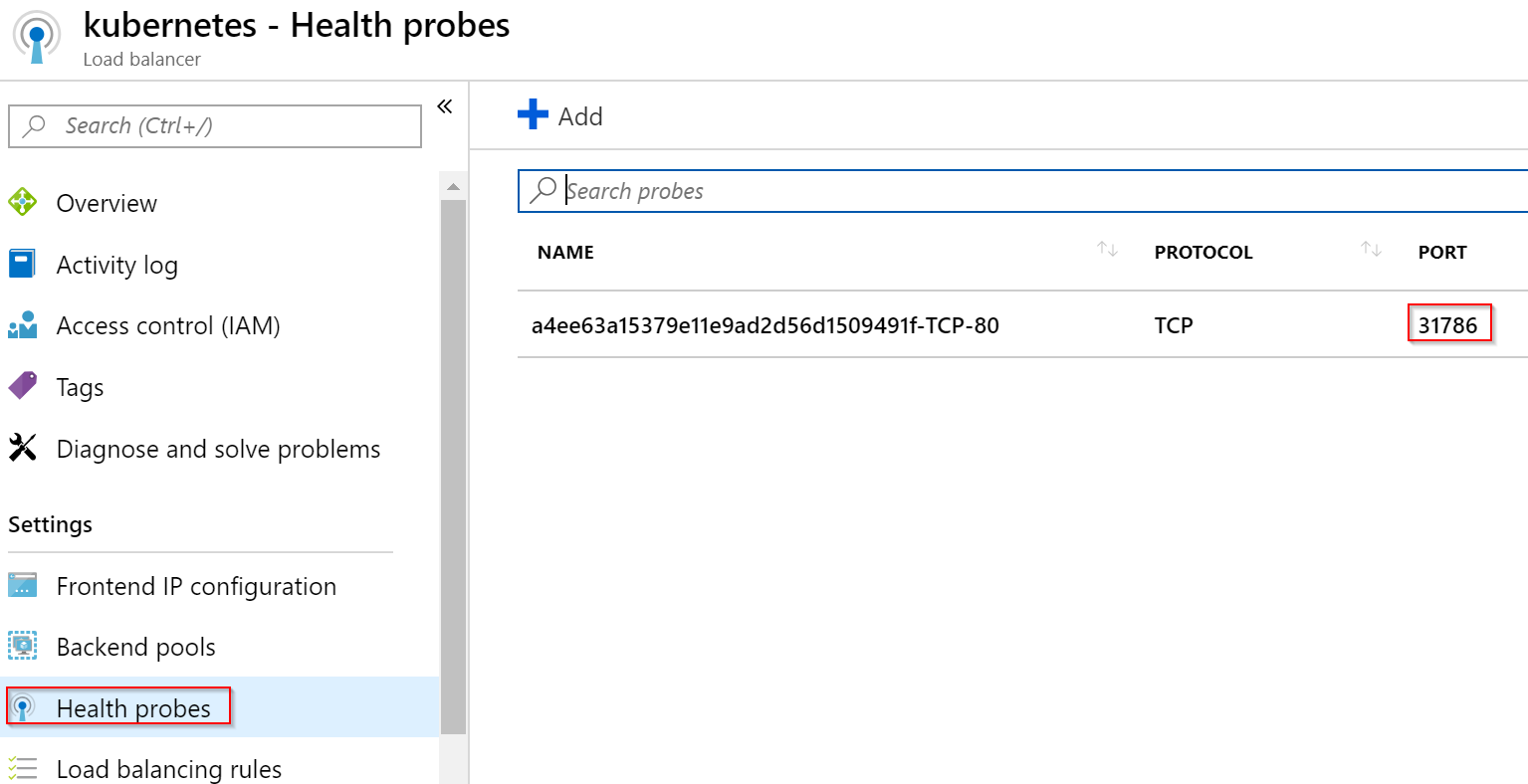
Jak balancer pozná, že je služba nahoře? Má nastaven Health Probe a není náhoda, že běží na portu 31786, což je port, na kterém je služba vystavena na IP adrese Nodů.
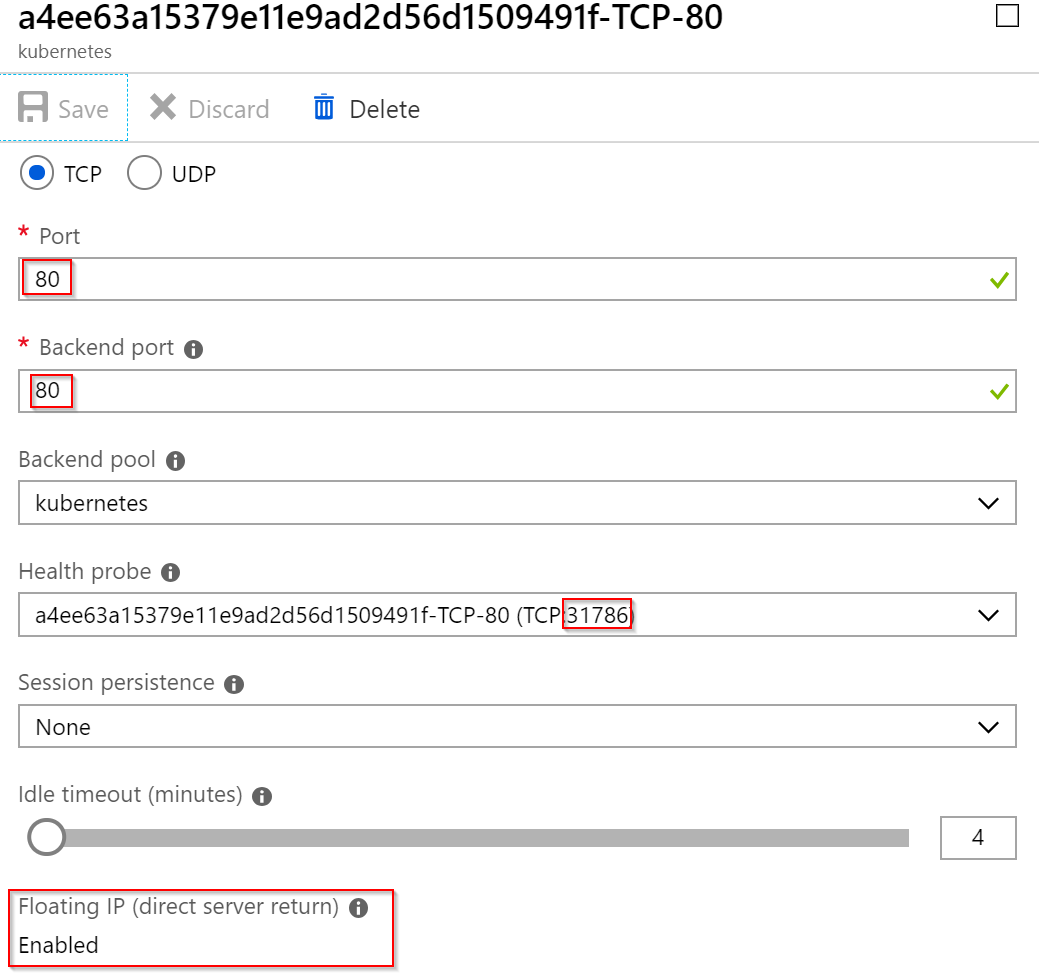
Nicméně LB pravidla jsou taková, že jako backend pool je použit také port 80 (nikoli 31786) a je aktivováno direct server return. Tady se implementace v různých cloudech mohou rozcházet. Azure LB je nastaven tak, že do Kubernetes pošle paket bez přepisu cílové IP adresy - tedy tou bude stále veřejná IP balanceru. V pravidlech na jednotlivých nodech se v iptables objeví zápis reagující právě na portu 80 této konkrétní veřejné IP adresy. Azure tedy přes NodePort provádí Health Probe, ale samotný provoz je řešen jinak.
S klienskou IP to funguje stejně, jako u NodePort. Ve výchozím stavu se balancuje spravedlivě a provádí se source NAT.
curl 40.118.18.20
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 192.168.0.105
------
Headers:
Host: 40.118.18.20
User-Agent: curl/7.58.0
Accept: */*
Může použít externalTrafficPolicy Local a zachovat tak IP klienta.
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
externalTrafficPolicy: Local
curl 40.118.18.20
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 90.181.122.97
------
Headers:
Host: 40.118.18.20
User-Agent: curl/7.58.0
Accept: */*
Při vytváření balanceru můžete použít i dopředu připravenou IP v Azure, takže budete mít předvídatelnou adresu. Ve výchozím stavu má účet Service Principal pro AKS přístup jen do své MC_ resource group, tak ji založíme tam (lze samozřemě přiřadit účtu jiná práva, ale s tím se teď nebudeme zdržovat).
az network public-ip create -n mojeIp -g MC_aks_aks_westeurope --allocation-method Static
az network public-ip show -n mojeIp -g MC_aks_aks_westeurope --query ipAddress -o tsv
52.232.113.129
Při zakládání Service tuto IP můžeme specifikovat.
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
loadBalancerIP: 52.232.113.129
kubectl get svc httpecho
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpecho LoadBalancer 192.168.7.125 52.232.113.129 80:31786/TCP 13h
Kromě externího balanceru s public adresou můžeme založit i interní balancer, například pro přístup pouze z VNETu či on-premises. Že to chceme takhle řekneme Kubernetu a potažmo Azure přes anotace. Těmi určíme, že chceme interní balancing a specifikujeme subnet (použijeme jiný, než ten, kde jsou Pody!). Současně zvolím i předem definovanou adresu (tentokrát ji ale nemusíme vytvářet dopředu, privátní adresy se jednoduše přidělí, jen si ověřte, že nedáváte adresu, kterou už máte použitou).
Výsledek vypadá nějak takhle:
kind: Service
apiVersion: v1
metadata:
name: httpecho
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
service.beta.kubernetes.io/azure-load-balancer-internal-subnet: "testingvm-subnet"
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
loadBalancerIP: 192.168.8.100
Ze své testovací VM ve VNETu si můžu ověřit, že to zafungovalo.
tomas@testingvm:~$ curl 192.168.8.100
Pod Name: httpecho-797967574f-schtl
Pod IP: 192.168.0.226
Node Name: aks-nodepool1-40944020-vmss000003
Node IP: 192.168.0.206
Client IP: 192.168.0.105
------
Headers:
Host: 192.168.8.100
User-Agent: curl/7.58.0
Accept: */*
Speciální případy Service
Nejčastěji budete používat Service typu ClusterIP a LoadBalancer tak, jak jsme to doteď dělali. Jsou ale i situace, kdy se vám bude hodit trochu jiné nastavení. Bude to například při potřebě adresovat služby mimo váš cluster (typicky dočasně pro účely postupné migrace) nebo pro objevování služeb, ale bez balancování.
Discovery služeb bez virtuální IP
Klasická Service si podle selektoru najde běžící pody, zařadí si je do Endpoints, kontroluje jejich dostupnost přes readinessProbe, založí virtuální IP adresu, přes kterou balacnuje provoz a přiřadí ji k DNS záznamu. Co když ale máte aplikační komponentu, která je stavová a například volí lídra, který má jako jediný právo zapisovat? Můžeme si pohrát s tím, že dáme dvě služby a různé readinessProbe, ale to vyžaduje podporu aplikace. Dost možná pro takové případy existuje klientská část. Nějaké SDK nebo sidecar v patternu ambassador, která si udržuje přehled o dostupných nodech a zjišťuje, který je zapisovací (na něj posílá zápisy) a které jsou dostupné pro čtení (a tam přístupy balancuje) případně dělá sharding a podobné věci. Pro takovou komponentu určitě využijeme některé vlastnosti Service - discovery Endpointů, monitoring jejich dostupnosti, DNS záznam. Naopak balancování přes virtuální IP ale nechceme, SDK potřebuje použít sofistikovanější metody. Potřebujeme tedy Service pro discovery, ale ne pro balancing. Jak na to?
Při definici služby dáme clusterIP na None. Tím vypneme balancování.
kind: Service
apiVersion: v1
metadata:
name: httpecho
spec:
selector:
app: httpecho
ports:
- protocol: TCP
port: 80
targetPort: 5000
clusterIP: None
Discovery se změní tak, že pod DNS názvem už nenajdeme A záznam pro virtuální IP, ale jednotlivé A záznamy pro endpointy. Díky tomu můžeme v ambassadoru získat přehled všech členů služby a nasadit vlastní balancovací mechanismus apod.
kubectl exec ubuntu -- dig httpecho.default.svc.cluster.local
; <<>> DiG 9.11.3-1ubuntu1.5-Ubuntu <<>> httpecho.default.svc.cluster.local
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62694
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 5a61408eecf7dc96 (echoed)
;; QUESTION SECTION:
;httpecho.default.svc.cluster.local. IN A
;; ANSWER SECTION:
httpecho.default.svc.cluster.local. 5 IN A 192.168.0.102
httpecho.default.svc.cluster.local. 5 IN A 192.168.0.226
;; Query time: 2 msec
;; SERVER: 192.168.4.10#53(192.168.4.10)
;; WHEN: Sun Feb 24 08:55:05 UTC 2019
;; MSG SIZE rcvd: 175
Discovery služeb běžících mimo Kubernetes cluster
Při definici služby používáte selector, který umožní Kubernetu automaticky najít endpointy. Místo toho ale můžete selektor zrušit a endpointy vyplnit ručně. Proč? Můžete chtít do Kubernetu dát službu, která je ale implementovaná zatím na IP mimo cluster. To se může hodit třeba pro účely migrace komponenty do clusteru. Od začátku použijete discovery mechanismus vevnitř, ale implementace je zatím venku. Až ji přesunete, pro ostatní komponenty se nic nezmění. Mějte ale na paměti, že tento model nedělá health check, takže není vhodný pro balancování na dvě venkovní VMka. Použije interní Azure LB přes dvojicí VM a Service namiřte na IP balanceru. Nastavení funguje tak, že vytvoříte service bez selektoru a pak vytvoříte ručně objekty Endpoint.
kind: Service
apiVersion: v1
metadata:
name: mojevm
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
---
kind: Endpoints
apiVersion: v1
metadata:
name: mojevm
subsets:
- addresses:
- ip: 192.168.8.4
ports:
- port: 80
Druhá možnost je použít objekt Service jen pro DNS nastavení a vrátit CNAME s jménem služby. Může to vypadat takhle:
kind: Service
apiVersion: v1
metadata:
name: extapi
spec:
type: ExternalName
externalName: api.ipify.org
Vyzkoušíme si. Vaše řešení by mělo vědět, že má poslouchat na novém hostname. Tato externí služba to neví, tak ji musím tuto informaci poslat v headeru, nicméně náš příklad je o ukázání toho, že DNS vrací CNAME a to zafunguje.
kubectl exec ubuntu -- curl -s extapi -H 'Host: api.ipify.org'
23.97.152.103
Dnes to bylo trochu delší, ale snad se podařilo ukázat co všechno Service v Kubernetes dokáže. Málo toho není, ale třeba chcete ještě víc? TLS terminaci, URL směrování, hrátky s hlavičkami? Service je jednoduchý L4 balancer - vysoký výkon, jednoduchost, nízká latence, podpora jakéhokoli protokolu včetně binárních i UDP variant. Pokud jde o frontend vaší webové aplikace, možná použijete komfort Ingress objektu, o kterém se pobavíme příště. Ale je také docela dobře možné, že reverse proxy ve vašem enterprise prostředí řeší jiný tým na své F5 a vy tak budete publikovat služby přes interní balancer - správu TLS a dalších věcí řeší někdo jiný. Buď jak buď Service je základní objekt v Kubernetes a je rozhodně dobré se s ní pořádně seznámit.