V minulých dílech jsme se seznámili s konceptem a také variables a parametry. Než se pustíme do pokročilých kousků měli bychom probrat to nejdůležitější - resources, tedy to, co se vlastně do Azure nasadí.
Jaké zvolit nástroje a pracovní postupy
Popíšu vám jak pracuji já a určitě to není jediná cesta k cíli.
Editor
V první řadě potřebuji editor, který mě upozorní na chyby v JSON (čárka navíc apod.), dokáže formátovat JSON a ukáže mi barevně která závorka ke které patří. Kromě těchto JSON věcí potřebuji inteligentní znalost ARM šablon, tedy ať mi to radí jaké klíče jsou možné, když používám variable ať mi nabídne seznam těch, které mám skutečně definované a pokud mám nějakou, která neexistuje nebo je deklarována ale není použita, tak ať ji podtrhne. To všechno splňuje Visual Studio Code a jeho následující extensions:
- msazurermtools.azurerm-vscode-tools
- eriklynd.json-tools
- coenraads.bracket-pair-colorizer
Formátování a barevné závorky:
Sbalování objektů:
Nápověda:
Doplňování dle deklarovaných proměnných a parametrů:
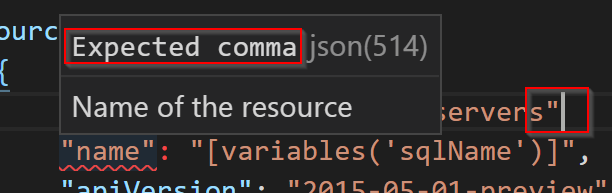
Chyby v JSON:
Příklady
Azure nabízí obrovské množství příkladů. Pokud potřebuji řešit konkrétní typ zdroje, najdu tam obvykle dobrý příklad, kde je to řešeno: https://github.com/Azure/azure-quickstart-templates
Dokumentace
Jak ale zjistím jaké všechny možnosti (atributy) jsou vlastně u daného zdroje možné, jakou mají strukturu a tak podobně? To je perfektně řešeno v dokumentaci: https://docs.microsoft.com/en-us/azure/templates/
Pohled pod Azure kapotu
Někdy ale možná přesně nevíte. Umíte to v GUI, ale nevíte co hledat v ARMu. Nebo sice víte, ale změnili jste nějaký parametr a potřebujete zjistit, jaká je podoba tohoto nastavení v ARMu. U Resource Group existuje volba Deployment script, ale tu já rád nemám. Jde o to, že robot se tam pokusí vytvořit šablonu sám a dost nesmyslně volí parametry (udělá parametr prakticky ze všeho), což je nepoužitelné. Daleko rychlejší a příjemnější mi je https://resources.azure.com. To je pohled přímo pod kapotu vašeho Azure. Najdete tam všechny svoje nasazené zdroje tak, jak je vnímá Azure a odtamtud lze skvěle vykopírovávat potřebné objekty a parametry. Jen si uvědomme jednu věc. V tomto pohledu jsou i věci, které jsou “runtime”, takže Azure si je tam píše, ale vy je nezadáváte v ARM šabloně (například vygenerované id) a také jsou tam explicitně napsané všechny výchozí hodnoty parametrů, které v šabloně často vůbec neřešíte. Nicméně mám příklad z quickstart, nastudovanou dokumentaci a potřebuji se mrknout, kam si Azure vlastně zapisuje třeba velikost Azure SQL storage? Na to je tento pohled ideální.
Stažení šablony po dokončení průvodce
Automaticky generované šablony jsou nepřehledné, ale v mnoho položek v marketplace má pod kapotou dobře udělané šablony, které připravují lidé. Platí to pro některé průvodce nativní (například vytvoření VM) i pro komplexnější šablony včetně třetích stran. Obvykle je na konci průvodce možnost si stáhnout šablonu a to včetně parametrů tak, jak jste je předtím zadali do GUI. To může být dost užitečné.
Pár ukázek s komentářem
Podívejme se na první šablonu.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"variables": {
"location": "[resourceGroup().location]"
},
"resources": [
{
"type": "Microsoft.Network/virtualNetworks",
"name": "mujnet",
"comments": "Zalozeni virtualni site a subnetu",
"apiVersion": "2017-06-01",
"location": "[variables('location')]",
"properties": {
"addressSpace": {
"addressPrefixes": [
"10.0.0.0/16"
]
},
"subnets": [
{
"name": "sub1",
"properties": {
"addressPrefix": "10.0.0.0/24"
}
}
]
}
},
{
"type": "Microsoft.Network/networkInterfaces",
"name": "nic1",
"comments": "Zalozeni sitove karty",
"apiVersion": "2017-06-01",
"location": "[variables('location')]",
"dependsOn": [
"mujnet"
],
"properties": {
"ipConfigurations": [
{
"name": "ipconfig1",
"properties": {
"subnet": {
"id": "[resourceId('Microsoft.Network/virtualNetworks/subnets', 'mujnet', 'sub1')]"
},
"privateIPAllocationMethod": "Dynamic"
}
}
]
}
}
],
"outputs": {}
}
Tato šablona v sobě má pár důležitých vlastností. Jedná se o vytvoření sítě, subnetu a síťové karty, která musí žít v subnetu. První důležité políčko je dependsOn. ARM bude paralelizovat jak to jen půjde a my mu musíme říct, že co se týče síťovky, tak tu může začít dělat teprve až bude vytvořena síť se subnetem. Do dependsOn můžete dát název zdroje nebo celé jeho ID.
Druhá věc k prozkoumání je subnet coby vložený resource do VNETu. Celá řada zdrojů v ARM má delší cestu, než je základní ResourceProvider/neco. Ono neco může mít různé parametry a konfigurace, ale pokud má v sobě velikánské celky, ty budou jako samostatný zdroj, tedy ResourceProvider/neco/soucastka. Něco může být síť a součástka subnet, virtuální DB server a databáze, NSG a její pravidla apod. V první ukázce nasazujme podřízené zdroje přímo v tom hlavním tak, že v jeho těle dáme resources a v nich jsou ty vnořené. Není to jediná metoda (jak uvidíte později), ale zrovna pro subnety je to ta jediná správná.
Třetí zajímavost je, že potřebujeme síťové kartě dát plné ID subnetu. Na to se odkážeme funkcí resourceId. Té jako parametr předáváme typ zdroje, což je síťový provider / VNET / subnet a funkce očekává další řetězce, které jsou dosazením názvů pro ty věci za lomítkem. Máme tam dvě - VNET / subnet, takže musíme zadat jméno VNETu a subnetu.
Mrkněme teď na druhou šablonu. Tu první jsem nasazoval do resource group mojerg (az group deployment create -g mojerg –template-file resource01.json) a tu druhou chci scválně do jiné (mojerg2). Takhle vypadá šablona:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"variables": {
"location": "[resourceGroup().location]",
"existingVnetName": "mujnet",
"existingVnetSubnet": "sub1",
"existingVnetResourceGroup": "mojerg"
},
"resources": [
{
"type": "Microsoft.Network/networkInterfaces",
"name": "nic2",
"comments": "Zalozeni sitove karty v siti vytvorene mimo tuto sablonu",
"apiVersion": "2017-06-01",
"location": "[variables('location')]",
"properties": {
"ipConfigurations": [
{
"name": "ipconfig1",
"properties": {
"subnet": {
"id": "[resourceId(variables('existingVnetResourceGroup'), 'Microsoft.Network/virtualNetworks/subnets', variables('existingVnetName'), variables('existingVnetSubnet'))]"
},
"privateIPAllocationMethod": "Dynamic"
}
}
]
}
}
],
"outputs": {}
}
Tahle šablona je dost klasická ukázka. Síťařina se obvykle dává do samostatné resource group, aplikační komponenty a s nimi i síťovou kartu VM budu chtít dát do jiné resource group. Jak ale tato druhá šablona získá referenci na VNET, který ale nevytváří? Možná ho udělal síťař ručně nebo vznikla jinou šablonou? Typickým řešením je šabloně předat všechny potřebné informace k tomu, aby dokázala existující zdroj najít. K tomu potřebujeme jméno VNETu, subnetu a v jaké resource group se nachází. Všimněte si, že u funkce resourceId máme na prvním místě resource group, pak resource providera, pak jméno sítě a jméno subnetu. V minulé šabloně tam resource group nebyla, takže ARM vzal jako výchozí tu resource group, v které se šablona nasazuje. Referenci můžete získat i na objekty v jiné subskripci (pokud na ně máte práva), pak ještě před resource group dáte ID subskripce (nicméně u síťovky to smysl nedává, ta musí být ve VNETu, který je součástí subskripce).
Vraťme se teď k těm objektům, které jsou vnořejné v jiných. Podívejte se na třetí šablonu.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"variables": {
"location": "[resourceGroup().location]",
"sqlServerName": "[uniqueString(resourceGroup().Id)]"
},
"resources": [
{
"type": "Microsoft.Sql/servers",
"name": "[variables('sqlServerName')]",
"apiVersion": "2015-05-01-preview",
"location": "[variables('location')]",
"properties": {
"administratorLogin": "tomas",
"administratorLoginPassword": "Azure12345678",
"version": "12.0"
},
"resources": [
{
"type": "firewallRules",
"name": "rule1",
"apiVersion": "2015-05-01-preview",
"location": "[variables('location')]",
"dependsOn": [
"[variables('sqlServerName')]"
],
"properties": {
"endIpAddress": "1.2.3.4",
"startIpAddress": "1.2.3.4"
}
},
{
"type": "databases",
"name": "db1",
"location": "[variables('location')]",
"apiVersion": "2015-01-01",
"dependsOn": [
"[variables('sqlServerName')]"
],
"properties": {
"edition": "Basic",
"collation": "SQL_Latin1_General_CP1_CI_AS",
"requestedServiceObjectiveName": "Basic"
}
}
]
},
{
"type": "Microsoft.Sql/servers/firewallRules",
"name": "[concat(variables('sqlServerName'), '/rule2')]",
"apiVersion": "2015-05-01-preview",
"location": "[variables('location')]",
"dependsOn": [
"[variables('sqlServerName')]"
],
"properties": {
"endIpAddress": "1.2.3.5",
"startIpAddress": "1.2.3.5"
}
},
{
"type": "Microsoft.Sql/servers/databases",
"name": "[concat(variables('sqlServerName'), '/db2')]",
"location": "[variables('location')]",
"apiVersion": "2015-01-01",
"dependsOn": [
"[variables('sqlServerName')]"
],
"properties": {
"edition": "Basic",
"collation": "SQL_Latin1_General_CP1_CI_AS",
"requestedServiceObjectiveName": "Basic"
}
}
],
"outputs": {}
}
Resource provider Microsoft.SQL má jako hlavní objekt servers a v něm zakládáme virtuální SQL server. Kromě toho potřebuji ale dva další vnořené zdroje. Jednak jsou to firewallová pravidla (/firewalls) a druhak databáze (/databases). db1 a rule1 jsem vytvořil přímo při vytváření objektu serveru, ale to není vždy vhodné. Tak například server už může existovat a já chci jen přidat další databázi. Pokud všechny databáze budu nasazovat stejnou šablonou, tak to samozřejmě nebude problém - připíšu další a jedu. Ale co když jsou věci typu virtuální server a firewallová pravidla nasazována jiným týmem (infra) a já si jako vývojář jen potřebuju nahodit další databázi pro testování? Životní cyklus obou bude v jiných šablonách.
Zdroje podřízené není nutné nasazovat společně s nadřízenými, ale můžete to udělat kdykoli později. Takhle jsem založil rule2 a db2. Všimněte si type obsahuje celou cestu ke zdroji a název musí obsahovat cestu taky, tzn. název musí být složen z jmenoserveru/jmenodb. Tímto postupem můžu oddělit vytváření nadřazeného zdroje od podřazených. Ve většině případů je tohle můj preferovaný postup, ale u síťového resource provideru to takhle vhodné není. Ten totiž pokud vytvoříte VNET bez subnetů dojde k přesvědčení, že ty subnety má dát pryč (a protože v nich už obvykle jsou síťovky, tak to selže a šablona pak není idempotentní) - u sítí vždy dávejte subnety jako vnořený resource rovnou u definice VNETu, pak to bude idempotentní a můžete subnety vesele přidávat.
Pojďme na poslední dnešní ukázku.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"variables": {
"location": "[resourceGroup().location]",
"storageAccountName": "[uniqueString(resourceGroup().Id)]",
"appInsightsName": "[uniqueString(resourceGroup().Id)]"
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"name": "[variables('storageAccountName')]",
"apiVersion": "2017-06-01",
"location": "[variables('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "Storage",
"properties": {}
},
{
"type": "Microsoft.Insights/components",
"name": "[variables('appInsightsName')]",
"apiVersion": "2014-04-01",
"location": "[variables('location')]",
"properties": {
"ApplicationId": "[variables('appInsightsName')]"
}
},
{
"type": "Microsoft.Web/serverfarms",
"name": "mujPlan",
"kind": "app",
"apiVersion": "2017-08-01",
"location": "[variables('location')]",
"properties": {},
"sku": {
"name": "B1",
"tier": "Basic",
"size": "B1",
"family": "B",
"capacity": 1
}
},
{
"type": "Microsoft.Web/sites",
"name": "[uniqueString(resourceGroup().Id)]",
"kind": "app",
"apiVersion": "2016-08-01",
"location": "[variables('location')]",
"properties": {
"serverFarmId": "[resourceId('Microsoft.Web/serverfarms', 'mujPlan')]",
"siteConfig": {
"appSettings": [
{
"name": "APPINSIGHTS_INSTRUMENTATIONKEY",
"value": "[reference(resourceId('Microsoft.Insights/components', variables('appInsightsName')), '2014-04-01').InstrumentationKey]"
},
{
"name": "STORAGE_KEY",
"value": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', variables('storageAccountName')), '2016-01-01').keys[0].value]"
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms', 'mujPlan')]",
"[resourceId('Microsoft.Insights/components', variables('appInsightsName'))]"
]
}
],
"outputs": {}
}
Copak se nám děje tady? Chci demonstrovat vytvoření zdrojů a předání jejich runtime informací do jiného resource. Konkrétně tady vytváříme storage account. Pro přístup k němu potřebujeme klíč, který si aplikace načte a používá. Rád bych tedy vytvořil WebApp a zařídil, že klíč ke storage si aplikace bude moci přečíst jako svůj parametr. Totéž potřebuji pro Application Insights, kde moje WebApp musí znát instrumentation key. Oba tyto klíče se nazadávají při vytváření zdroje - jsou generované Azurem a nedají se dopředu určit. Potřebujeme tedy při vytváření WebApp počkat na to, až bude storage i app insights vytvořena. To už známe - dependsOn, nicméně tady jsem použil plné ID přes funkci resourceId. Proč? V mém případě by to jinak končilo chybou. Všimněte si totiž, že appInsightsName a název WebApp je stejný řetězec, takže ARM neví přesně na co má čekat. Plné ID mi umožňuje se tomuto vyvarovat.
Jak tedy do WebApp předat klíče? Pro storage account je na to funkce listKeys a pro app insights použiji univerzálnější funkci reference. Ta vám umožní načíst si prakticky libovolný atribut existujícího zdroje. Takhle se dostanete třeba k přiřazené IP adrese, výsledné URL, instrumentation key nebo něčemu dalšímu a to tento zdroj nemusí být nasazován touhle šablonou (reference je tedy vlastně čtecí operace nad existujícím zdrojem).
A co deployment subscription zdrojů? Nebo nasazení do dvou subskripcí či resource group?
To všechno se dá udělat! Potřebujeme k tomu ale použít vnořené a linkované šablony, o kterých se pobavíme někdy jindy a k tomuto tématu se vrátíme. Jen krátce naznačím. Šablona může nasazovat jiné šablony a tyto lze spustit nad jinou resource group či dokonce v jiné subskripci (v rámci nějakých limitů, ale o tom jindy). No a také existuje šablona, která se nasazuje na úrovni subskripce, ne resource group a ta se používá pro vytváření zdrojů, které nežijí v resource group (moc jich není, ale jeden z nich je resource group jako taková, RBAC pravidla subskripce nebo nějaká per-subskripce nastavení security center apod.).
Pár tipů a častých chyb
Tady je pár věcí, které mne dovedou potrápit:
- Pokud zapomenete u hodnoty dát závěrečné hranaté závorky, bere to ARM jako normální řetězec - “[concat(‘dobry’, ‘ ‘, ‘den’)” nebude brán jako funkce
- Když odkazujete na zdroje třeba v dependsOn, je jistější tam dát celý identifikátor místo pouhého názvu. Ten obvykle stačí, ale pokud máte dva zdroje se stejným názvem, šablona vám na tom havaruje a můžem vám dlouho trvat pochopit proč
- Častá potíž při kopírování kousků šablon je záměna parameters a variable, protože vy to máte v parametru, ale kopírovaný resource v proměnné. Někoho (ale mě osobně ne) to rozčiluje natolik, že si do variable převádí i parametry, aby bylo tělo resources jen na variables, tzn. dá variable “klic”: “[parameters(‘klic’)]”
- Nezapomínejte u vnořených zdrojů na správně dlouhá jména. Pokud je zdroj type provider/celek/soucastka musí být název ve formátu jménocelku/jménosoučástky
- Klasický JSON nepodporuje komentáře typu //. Aktuálně některé metody deploymentu šablony // podporují, ale některé ještě ne a v tuto chvíli je lepší držet se přísného JSON standardu. Nicméně v každém resource můžete použít klíč comments a/nebo metadata, který bude ARM ignorovat a můžete si takto udělat poznámky a přitom udržet plně validní JSON
- Pozor na dependence. Pokud tvoříte šablonu postupně a přidáváte zdroje (což je myslím ideální postup) nezapomeňte nakonec všechno smazat a zkusit to načisto znova. Při postupném přidávání totiž nezjistíte, jestli nemáte problém v dependsOn.
- Dejte pozor na názvy, které musí být globálně unikátní a používejte uniqueString. Nezapomeňte do něj dát vhodný startovací string. Například pokud použijete jen resourceGroup().name a provedete deployment do stejného názvu resource group v různých subskripcích, vyjde vám řetězec stejně a to nechcete. V takovém případě použijte raději resourceGroup().id, které obsahuje celou cestu k resource group včetně subscription ID.
- Dejte pozor na omezení v hodnotách a držte se doporučeného systému malá písmenka a pomlčka. Ale ani to není zcela univerzální, třeba storage account pomlčku mít nesmí. Stejně tak NETBIOS VM name má maximálně 13 znaků, hesla do SQL musí mít požadovanou komplexitu apod.
- Verze API se snažte pochopit, ne je jen vykopírovat z příkladů. Azure je obvykle zpětně kompatibilní mnoho let dozadu, ale určitě je vždy dobré použít co nejnovější API. V novějších verzích mohou být nové funkce, které budete chtít použít, ale současně tam mohou být i nekompatibilní změny. Dobrá praxe je preferovat vyšší verze a v jedné šabloně pro jeden typ zdroje používat stále stejnou verzi.
Dnes jsme se podívali na nasazování zdrojů a zkusil jsem vám předat co nejvíc mých chyb a záseků, které snad nebudete opakovat. Pusťte se do Infrastructure as Code s Azure Resource Manager šablonama - stojí to opravdu za to.