V Azure Stack hardwarovém balíčku není žádné klasické storage pole a SANka. Najdete tam ale storage softwarově definovanou. Jak funguje spodek? A jak je Azure Stack konzistentní s Azure principy jako je Storage acount, Blob storage, Queue storage nebo Table storage? Podívejme se dnes na to.
Storage spaces direct (S2D) jako softwarově definovaná storage pro Azure Stack
Azure používá neuvěřitelně distribuovaný systém pro storage. Jak to Azure dělá? Základní designové principy jsou popsané ve whitepaper z roku 2011 zde: http://sigops.org/sosp/sosp11/current/2011-Cascais/printable/11-calder.pdf
Je to fascinující čtení pro technicky zaměřeného člověka a ukazuje jak složité je designovat vysoce distribuovaný storage systém ve škále jakou má Azure. Použití přesně stejné technologie v Azure Stack by ale moc nešlo, protože minimální počty nodů jsou nesmírně vysoko (typický storage stamp coby nejmenší jednotka nasazení storage v Azure je asi 800 fyzických serverů). Nicméně myšlenky použité v Azure se postupně začaly v menší škále projevovat i ve vlastnostech Windows Serveru a to nejdřív jako Storage Spaces a ve Windows 2016 přišla hyperkonvergovaná varianta Storage Spaces Direct. Hyperkonvergence znamená, že jeden server může současně sloužit jako storage jednotka a zároveň jako jednotka výpočetního výkonu. Ideální technologie, na které lze postavit Azure Stack.
Zjednodušeně to funguje nějak takhle. Na lokálním serveru můžete mít pool disků a již desítky let existují možnosti je spojit do jednoho systému a zajistit nějakou formu redundance ať už to jsou různé technologie typu RAID nebo jiná forma replikace a resilience. Můžete mít sadu rychlých disků (NVMe nebo SSD) a k nim levné kapacitní disky (HDD). S2D udělá to, že rychlé disky použije jako cache. Všimněte si, že jsme ještě nic nepropojili ani neudělali cluster - cache je implementovaná velmi dole, lokální data mají lokální cache. To je velmi výhodné, protože veškeré věci ohledně perzistence a distribuce bloků můžete provádět až nad tím a odpadne vám řada zajímavých problémů. Každý node má tedy lokální sadu kapacitních disků a k tomu lokální rychlou cache. Tato cache způsobuje, že veškeré zápisy mohou jít do cache vrstvy a nikdy ne přímo do HDD a na jejich přesun není třeba nějak spěchat (SSD jsou perzistentní a ochrana před výpadkem nodu je řešena o úroveň výš). Data v cache se postupně propisují do HDD a při tom se dělají některé optimalizace (například serializace zápisů, což rotačním diskům hodně pomáhá). Data, která jsou často používaná v cache zůstávají a tak i čtení probíhá odtamtud.
Další co potřebujeme je roztáhnout lokální storage bus přes síť tak, aby všechny servery v S2D viděly na všechny disky a mohl se tak vytvořit jeden logický pool disků. Potřebujete tedy zajistit dostatečně výkonnou komunikační vrstvu s nízkou latencí. Tady přichází ke slovu protokol SMB3 a jeho nasazení přes RDMA nad Ethernetem. Jednou z takových variant je RoCE (RDMA over Converged Ethernet), tedy komunikace přes vylepšený Ethernet schopný zajistit lepší kvalitu služby a bezstrátovost a současně akcelerace obejitím procesoru (přímý zápis do paměti). Proto je mimochodem součástí Azure Stacku i networking, protože tvoří zásadní komponentu celého řešení a tohle správně odladit není nijak jednoduché.
Nad tímto už mohou běžet Storage Spaces, tedy něco jako softwarově řešený "RAID". S2D nabízí různé varianty, ale v Azure Stack je aktuálně použita výhradně třícestná replika. To znamena každý blok vašich dat je uložen na třech místech v clusteru. To umožňuje ztratit celý node a ve stejný okamžik disk na jiném zdravém nodu a stále ještě jste nepřišli o data. Musím ještě zmínit, že kombinace S2D a ReFS je velmi mocná a ve světě mimo Azure Stack (tzn. na Windows Server 2016 Datacenter) umožňuje třeba ještě používat paritní redundanci (pomalejší, ale lepší výtěžnost disků), automatický tiering a to dokonce tak, že tierem mohou být stejné disky, jen rychlý tier je mirror a pomalejší tier je erasure coding (paritní redundance). Je možné, že se později některá z těchto technologií nějakým způsobem objeví i v Azure Stack.
Nad Storage Spaces už je pak potřeba tohle nějak naprezentovat operačnímu systému a používají se na to Cluster Shared Volume třeba s ReFS. Nad nimi už pak sedí klasické konstrukty, které znáte z Azure - storage account, page bloby na disky, block bloby na objekty, queue storage, table storage.
Jaké to má implikace pro Azure Stack? V aktuální podobě je Azure Stack nabízen tak, že má cache vrstvu a kapacitní vrstvu (S2D umožňuje ještě tiering takže hierarchie může vypadat třeba jako NVMe cache, SSD rychlý tier a HDD pomalý tier, ale to v tuto chvíli v Azure Stack použito není). V rámci Azure Stack tedy veškeré zápisy jdou do cache vrstvy a čtení často používaných dat jde rovněž odtamtud. Není to tier, ale cache, takže ta se nezapočítává do celkové storage kapacity, kterou máte v Azure Stack k dispozici. U výrobců najdete hardwarové konfigurace, které nabízí poměr cache ke kapacitě obvykle mezi 8% a 20% s tím, že nejčastější je varianta kolem 10%. Když si vezmeme, že v Azure Stack bude hodně dat statických (například image disků v katalogu) je cache poměrně velká. Samozřejmě čím větší bude, tím větší je pravděpodobnost, že se bude z cache i číst - na druhou stranu to samozřejmě znamená vyšší náklady. K dispozici jsou i all-flash varianty Azure Stacku, kde cache tvoří obvykle NVMe a kapacita je celá v SSD. V takovém scénáři bude Azure stack používat cache pouze pro zápisy, ale číst se bude rovnou z SSD. Technicky jsou možné i varianty, kde jak cache tak kapacitní vrstva jen na SSD s tím, že jsou použity jinak vyladěná SSD (cache optimalizovaná na zápisy a kapacitní vrstva pro čtení). Ve všech případech je kapacitní vrstva využívána v Azure Stacku v režimu třícestné repliky, takže efektivní kapacita storage prostoru je součet kapacitních disků dělený třemi. Pokud si kupujete Azure Stack třeba pro získání Azure konzistentního prostředí pro testování a vývoj nebo provoz Web Apps (PaaS) či business aplikací, varianta s HDD nabídne velikou kapacitu s rychlou cache za dobrou cenu. Pokud hodláte provozovat něco s masivním důrazem na výkon, například velké databáze, doporučuji variantu NVMe + SSD (all flash).
Zní to složitě? Naštěstí Azure Stack je hotové řešení - nic z toho nenastavujete, všechno je vymyšleno a odladěno a vy dostáváte hotovou krabici.
Storage accounty
V Azure se storage točí kolem konceptu storage accountů a v Azure Stack je to stejné. Tyto accounty vytváří namespace a podle typu blobu jsou podloženy vhodnou technologií jako je chunk store pro Block Blob a ReFS pro Page Blob (tím jsou implementované disky).
Jako administrátor se mohu podívat na svůj storage subsystém v Azure.
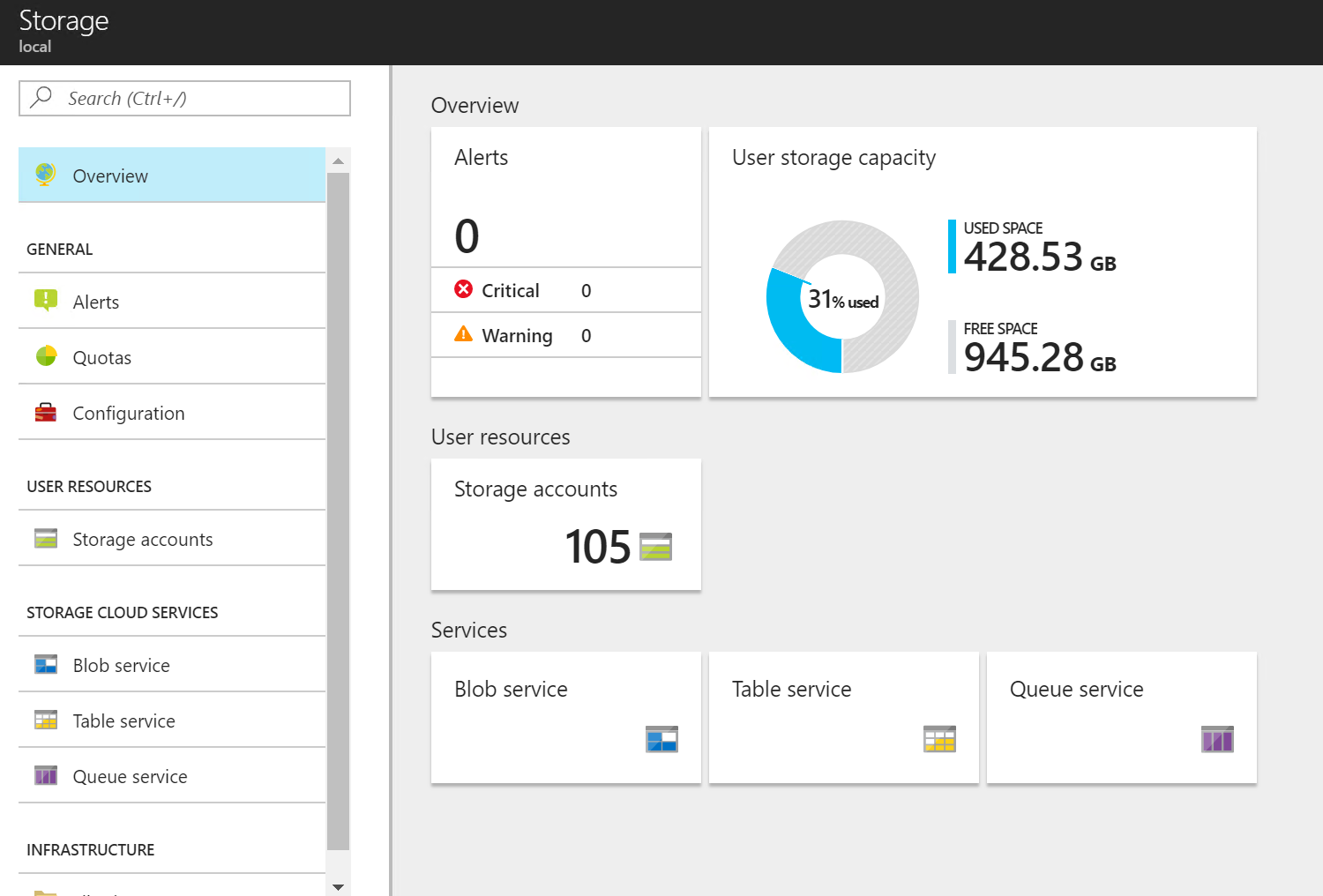
A samozřejmě jaké storage accounty existují v různých subscription.
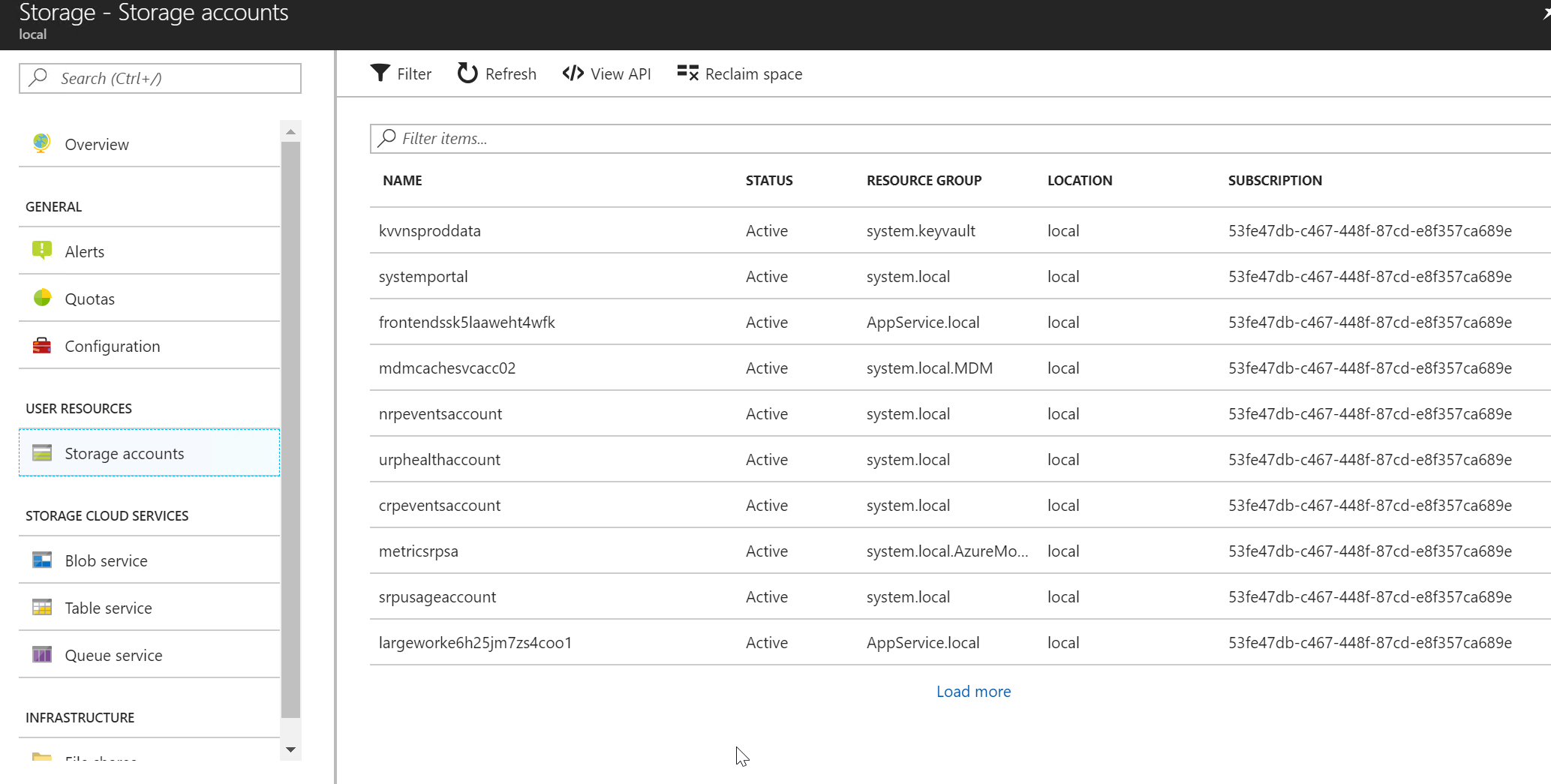
Disky v Azure Stack (Page Blob)
Každý perzistentní disk v Azure je vlastně VHD soubor v Page Blobu v nějakém storage accountu. Klasické řešení bylo si vytvářet accounty, v nich mít VHD a z toho pouštět VM. Později přišel Azure s konceptem Managed Disks. Je to technologicky to samé, ale starost o správu storage accountů pro vás řeší Azure na pozadí. V Azure Stack aktuálně Managed Disk ještě není, ale je na veřejné roadmapě a zdá se, že se brzy objeví. Aktuálně tedy vaše deployment šablony musí pracovat s klasickými disky ve storage accountech - nicméně to je stále Azure koncept, který je k dispozici jak ve velkém Azure tak Azure Stack, takže lze vytvořit konzistentní deployment šablony pro obě prostředí. Ale jak říkám Managed Disky jsou na roadmapě.
UPDATE: Od verze 1808 jsou Managed Disky v Azure Stack k dispozici.
Ve velkém Azure jsou k dispozici Standard Storage, Premium Storage a Temp Storage. To první je storage postavená na HDD a limitem je 500 IOPS per disk, Premium Storage je totéž, ale na SSD s výkony od 100 IOPS do 7500 podle velikosti použitého disku a Temp Storage je rychlá lokální storage pro VMko, která ale není perzistentní (používá se na dočasné soubory, nikdy nic, co má být perzistentní). Storage architektura Azure Stack je pod kapotou ale trochu jiná (S2D) a chování Azure Stack je tak blízké Azure, ale má určité rozdíly - ty vám ale nijak neznemožňují konzistentní chování vašich šablon a deployment skriptů.
V čem je tedy rozdíl (alespoň v aktuální verzi Azure Stack - tak jak jde Azure rychle dopředu totéž se týká i Azure Stacku). Všechny tři typy disků jsou v Azure Stack k dispozici, ale implementačně jsou všechny opřeny o stejný S2D systém. Jinak řečeno podkladová storage se chová minimálně pro Standard a Premium storage stejně (mám rozporuplné informace ohledně Temp disků a z Dev Kitu nechci usuzovat jak to funguje v hardwarovém Azure Stacku - buď jsou také S2D nebo jsou skutečně lokální, kde ale na rozdíl od velkého Azure může být problém s Live Migration, kterou velký Azure nepoužívá). Nějspíš to tedy vždy bude S2D s tím, že zápisy jdou do cache, čtení je ideálně z cache nebo z kapacitního disku. Pro ochranu výkonu a rozlišení Standard, Premium a Temp disků používá Azure stack limity na úrovni hypervisoru (Storage QoS). Pro Standard Storage je tak implementován limit 500 IOPS na každý disk (stejně jako v Azure). U Premium Storage není rozlišováno podle velikosti, ale každý Premium Disk má QoS limit 2300 IOPSů. Temp disky nejsou ve skutečnosti Temp, ale zase S2D a limity IOPS jsou dané velikostí VM (to je také velmi podobné velkému Azure, kde máte VM s lokálním HDD, jiné s lokálním SSD a čím větší máte VM, tím větší máte disk a o to větší máte povolené IOPSy). Na rozdíl od Azure tyto IOPS jsou limity a nikoli garance. I když budete mít Premium Disk neznamená to, že když se tam dlouho nebude nic dít, že nedojde ke čtení z kapacitní vrstvy, která může být postavena na HDD. Je možné, že se Azure Stack bude i v tomto do budoucna vyvíjet, ale tohle je aktuální stav, s kterým je třeba počítat. Výsledné chování je velmi podobné velkému Azure z pohledu nasazování a ovládání, takže přináší kýženou konzistenci. Pokud potřebujete mít jistotu, že vaše data budou vždy na SSD za všech okolností, poohlédněte se po all-flash verzi Azure Stack. Standard disky budou mít limity bránící nadměrnému zatěžování systému a Premium disky dostanou 2300 IOPS každý (a podobně jako ve velkém Azure jich můžete do VM připojit víc a uvnitř VM je složit do jednoho třeba přes striping se Storage Spaces nebo LVM v Linuxu).
Jako administrátor mohu výkon Blob storage v celém Azure Stacku sledovat.
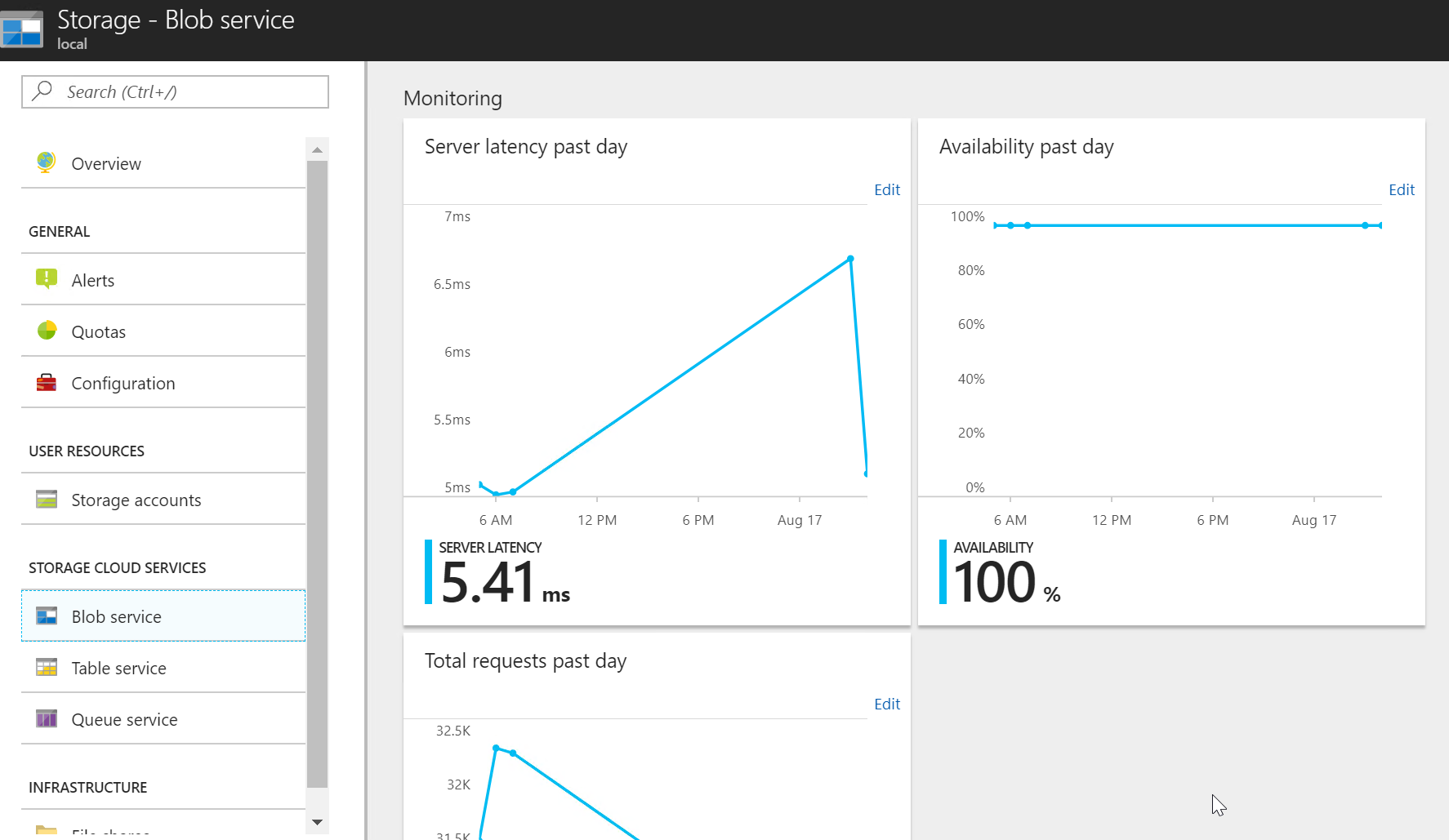
Pro svůj konkrétní storage account se mohu podívat jako tenant.
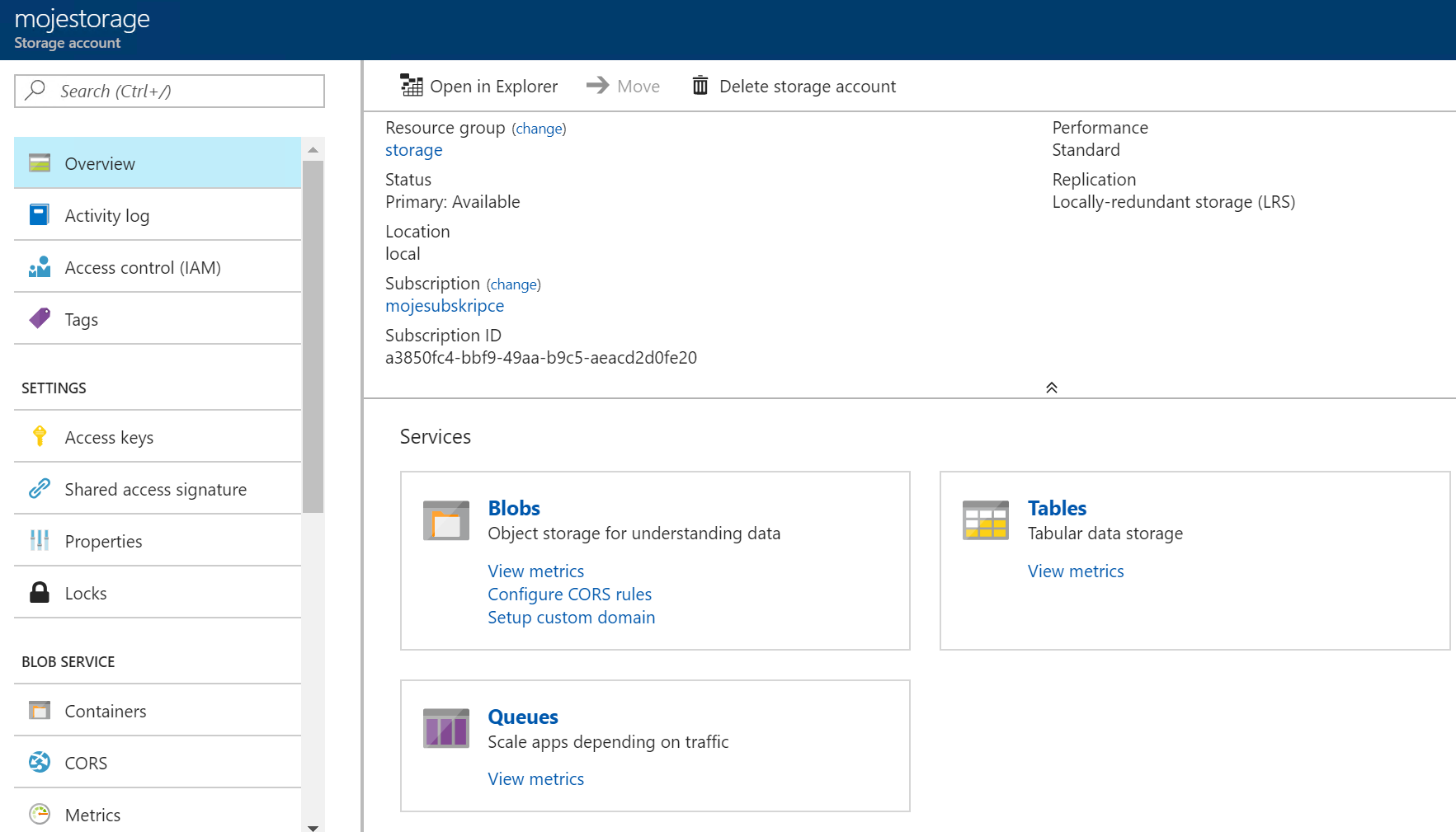
Block Blob storage
Objektová storage je moderní způsob uložení dat postavený na masivní škále a HTTP API. Nabízí velmi příjemnou aplikační integraci, servírování objektů rovnou ze storage (můžete například nastavit CORS a uživatelé mohou koukat na videa na vaší stránce třeba v Web App v Azure Stack přímo ze storage bez nutnosti protáhnout to web serverem) a celou řadu dalších výhod včetně generování klíčů pro časově omezený přístup apod. Je to konzistentí s Azure, takže váš kód, SDK i další nástroje jsou s Azure Stack krásně funkční.
Table storage
Účelem dnešního článku není popisovat Azure technologie, spíše poukázat na konzistenci s Azure Stack. Nicméně pokud neznáte tak Table storage je velmi jednoduchá NoSQL databáze, kam si můžete uložit jednoduché key/value páry nebo tabulky. Dotazovací jazyk je postaven na OData a existují pro něj SDK do různých jazyků. Není to relační ani transakčně orientovaná databáze, ale pro jednoduché uložení strukturovaných dat v aplikaci je velmi zajímavá (a levná, v Azure Stacku vás bude stát 0,018 USD za GB a měsíc). Opět je konzistentní s Azure, takže pokud o ni opřete vaší aplikaci, bude jí jedno jestli je v Azure nebo Azure Stacku.
Queue storage
Často je v aplikacích potřeba asynchronní zpracování a to se obvykle řeší nějakou frontou (pull mechanismus) nebo aktivním informováním (push). V Azure je k dispozici Queue storage, ale také Service Bus (pokročilé funkce typu garance právě jednoho doručení, dead letter fronta, topic, podpora více protokolů včetně AMQP), Event Hub (masivní škála pro přijem proudu informací třeba z IoT nebo click stream z webu, podpora hromady protokolů včetně AMQP, MQTT nebo Kafka) a pro push potřeby je tu Event Grid. Azure Stack v tuto chvíli podporuje Queue storage s tím, že na roadmapě je explicitně zmíněna práce na Event Hub, což je pak velmi zajímavé pro IoT scénáře. Queue storage je jednoduchá, ale krásně funguje, je nativní součástí Azure Stack už dnes a je levná (považte, že v Azure Stack za ni zaplatíte jen 0,018 USD za GB a měsíc, což je pro zprávy mezi aplikacemi takřka zadarmo).
Dnes jsme si ukázali jak funguje storage v Azure Stack. Pod kapotou je to udělané tak, aby to fungovalo v malé škále, tedy už od 4 nodů a z toho pramení určité rozdíly v chování toho spodku. Nicméně nad tím je Azure vrstva, která je s Azure plně konzistentní (stejné API i portál). Vaše znalosti storage accountů, blobů, table a queue z Azure se plně uplatní i v Azure Stack a naopak. Ono totiž jak už jsem mnohokrát řekl Azure Stack je Azure, který se ocitl u vás ve sklepě.