Chcete v Azure provozovat SQL? Mojí první volbou by byla platformní služba, tedy SQL Database. Možná ale máte důvody, které vás vedou k nasazení klasického SQL ve VM v Azure - musíte udělat drobné změny ve správě a účtech a není na to zatím čas, spoléháte se na některé v PaaS nepodporované formy monitoringu a tak podobně. Víte, že od SQL Server 2016 můžete běžet SQL ve VM, ale datové soubory a log mít napřímo v Azure storage? Oddělit tak životní cyklus dat a VM a v neposlední řadě využít rychlou a efektivní snapshotovou zálohu. Extrémně rychlá záloha a dramaticky svižnější restore a navíc méně zabraného místa. A můžete ještě bokem na levnou storage posílat data pro dlouhodou archivaci. Podívejme se jak na to.
Vytvořme si v Azure běžící SQL Server 2016 standard. Kromě toho založíme tři storage accounty. Jeden prémiový (SSD) - to bude přímé úložiště pro naše data a log (můžeme také jednotlivé MDF, NDF a LDF soubory oddělit do různých accountů). Nebude se využívat Block Blob (ostatně ten v prémiové verzi ani není) ale přímo Page Blob, tedy technologie která je právě pod kapotou běžných disků v Azure - jen tady nepotřebujeme simulovat disk do VM, SQL umí Page Blob využít napřímo.
Dále potřebujeme standardní storage pro "backup". Ve skutečnosti tam nebudou žádná data, protože SQL použije snapshot technologii na prémiové storage, ale někam si musí zapsat metadata, tedy referenci na verzi příslušného snapshotu. Nepovinně jsem ještě vytvořil archivní storage. Retenci na prvních dvou použiji relativně krátkou, třeba 30 dní a pro dlouhodobou archivaci a náhradu pásky můžeme nasadit třetí standardní storage - ostatně pokud z ní opravdu budeme číst málo můžeme ji udělat v tieru Cool a významně ušetřit.
Ke každé storage potřebuji vygenerovat přístupy - konkrétně SAS policy a SAS token. Udělám to z příkazové řádky abych to měl automatizované. Pokud jste spíše klikací použijte Storage Explorer (http://storageexplorer.com/).
group="sql" data="storageprosqldata" backup="storageprosqlbackup" archive="storageprosqlarchive" publicname="mujtestsql" az group create -n $group -l westeurope az vm create -n sql -g $group --nsg "" --public-ip-address-dns-name $publicname --admin-username tomas --admin-password Azure12345678 --size Standard_D2s_v3 --image "MicrosoftSQLServer:SQL2016SP1-WS2016:Standard:latest" az storage account create -n storageprosqldata -g sql --sku Premium_LRS datastring=$(az storage account show-connection-string -g sql -n storageprosqldata -o tsv) az storage container create -n data --connection-string $datastring az storage container policy create -c data -n datapolicy --permissions dlrw --connection-string $datastring --expiry 2022-01-01'T'1:1:1'Z' datasas=$(az storage container generate-sas -n data --policy-name datapolicy --connection-string $datastring -o tsv) az storage account create -n storageprosqlbackup -g sql --sku Standard_LRS backupstring=$(az storage account show-connection-string -g sql -n storageprosqlbackup -o tsv) az storage container create -n backup --connection-string $backupstring az storage container policy create -c backup -n backuppolicy --permissions dlrw --connection-string $backupstring --expiry 2022-01-01'T'1:1:1'Z' backupsas=$(az storage container generate-sas -n backup --policy-name backuppolicy --connection-string $backupstring -o tsv) az storage account create -n storageprosqlarchive -g sql --sku Standard_LRS archivestring=$(az storage account show-connection-string -g sql -n storageprosqlarchive -o tsv) az storage container create -n archive --connection-string $archivestring az storage container policy create -c archive -n archivepolicy --permissions dlrw --connection-string $archivestring --expiry 2022-01-01'T'1:1:1'Z' archivesas=$(az storage container generate-sas -n archive --policy-name archivepolicy --connection-string $archivestring -o tsv) echo Token pro $data: $datasas echo Token pro $backup: $backupsas echo Token pro $archive: $archivesas
Přístupové tokeny si nakopírujeme - hned budou potřeba. Přihlásíme se do SQL Server s použitím Management Studio a zadáme následující query, kterým do SQL vložíme potřebné přístupové údaje k našim třem storage účtům.
CREATE CREDENTIAL [https://storageprosqldata.blob.core.windows.net/data] WITH IDENTITY='SHARED ACCESS SIGNATURE', SECRET = 'sv=2016-05-31&si=datapolicy&sr=c&sig=GvmcpLwjWS1qUmOQtFb6KsjrkOzfmtheyTgjXWEqMxo%3D'; CREATE CREDENTIAL [https://storageprosqlbackup.blob.core.windows.net/backup] WITH IDENTITY='SHARED ACCESS SIGNATURE', SECRET = 'sv=2016-05-31&si=backuppolicy&sr=c&sig=QDe9hysv42Uz%2BaQnhpo7NqcfFAsYZI7zGGpSdMtld3Y%3D'; CREATE CREDENTIAL [https://storageprosqlarchive.blob.core.windows.net/archive] WITH IDENTITY='SHARED ACCESS SIGNATURE', SECRET = 'sv=2016-05-31&si=archivepolicy&sr=c&sig=wFCcLmIBdqCp65shL7LFVaEakOjW1RIiRUppHuiScGM%3D';
Teď už klidně můžeme vytvořit novou prázdnou databázi se soubory přímo v Azure Storage - jednoduše místo lokální cesty k souboru použijete URL storage accountu. Já místo nové databáze nahraji existující demo data. Nejprve si je v cílovém stroji stáhnu.
Invoke-WebRequest -Uri https://github.com/Microsoft/sql-server-samples/releases/download/wide-world-importers-v1.0/WideWorldImporters-Standard.bak -Out D:\WideWorldImporters-Standard.bak
Následně tuto DB odbnovím do svého SQL Server a jednotlivé MDF, NDF a LDF soubory namířím rovnou do Azure Storage.
USE [master] RESTORE DATABASE [WideWorldImporters] FROM DISK = N'D:\WideWorldImporters-Standard.bak' WITH MOVE N'WWI_Primary' TO N'https://storageprosqldata.blob.core.windows.net/data/WideWorldImporters.mdf', MOVE N'WWI_UserData' TO N'https://storageprosqldata.blob.core.windows.net/data/WideWorldImporters_UserData.ndf', MOVE N'WWI_Log' TO N'https://storageprosqldata.blob.core.windows.net/data/WideWorldImporters.ldf' GO
Mám je tam! Podívejme se ve Storage Explorer co to v prémiové storage udělalo.
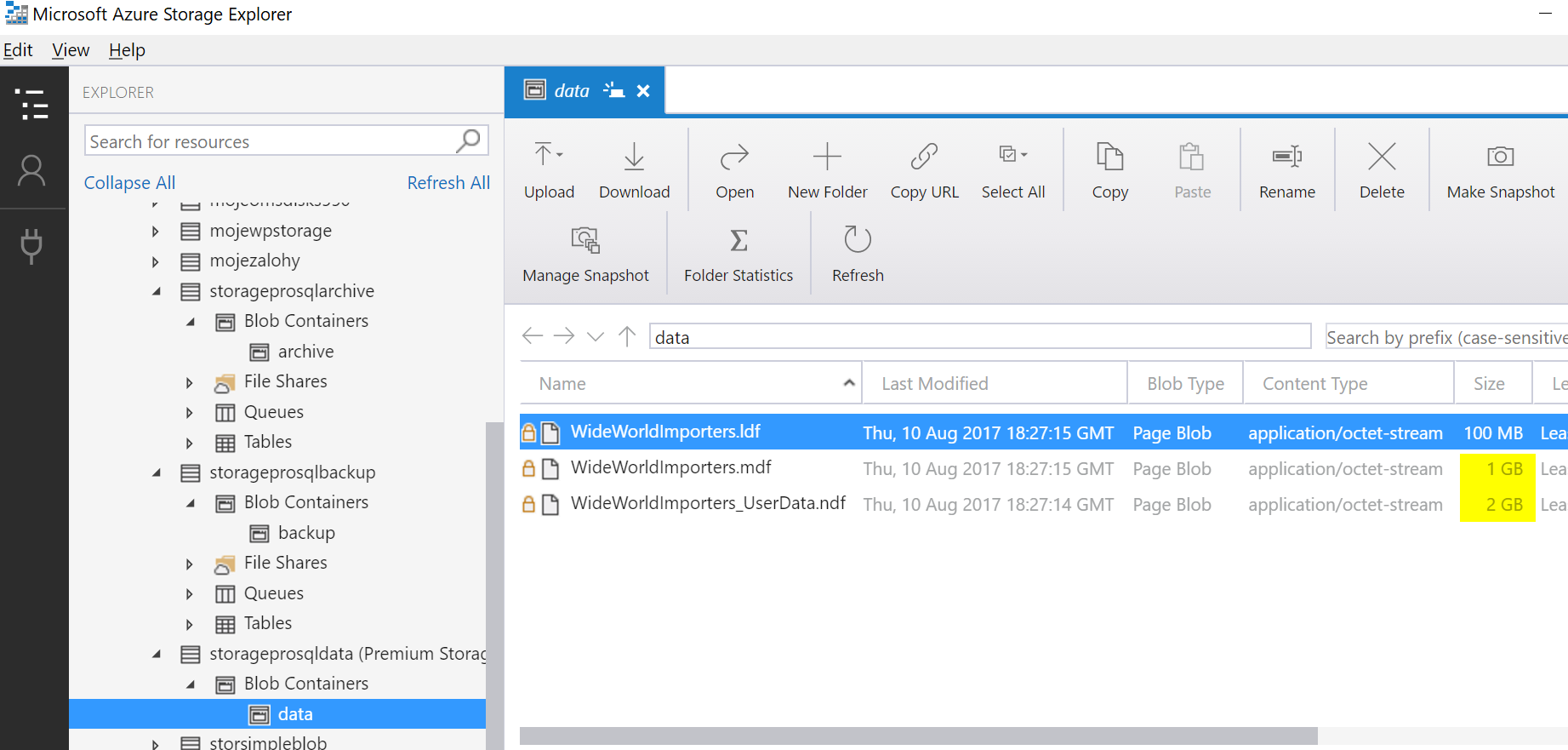
Perfektní. Mimochodem výkonu se zde obávat nemusíte. Jak už jsem psal je to stejný typ storage jaký bude použit když vytvoříte prémiový disk a soubor uděláte na něm. Tady je to ve skutečnosti jednodušší - nepotřebuji abstrakci disku (storage se nemusí tvářit jako disk) a nepotřebuji další file systém (abstrakci disku nemusím formátovat na NTFS), výkon je výborný.
Jak jsem sliboval toto řešení nám extrémně zrychlí backup. Jak to? Azure Storage podporuje snapshot technologii a copy-on-write. V okamžiku zálohy se z datového či log souboru stane snapshot - tedy vlastně zapíšou se pouze metadata, že tento snapshot má tyto chlívečky s daty. K žádnému kopírování a přesouvání dat nedošlo, proto je to tak rychlé. Od teď pokud v databázi něco změníte, Azure Storage v ten okamžik chlíveček zapíše nějam jinam. Pak uděláte další snapshot a celé se to opakuje.
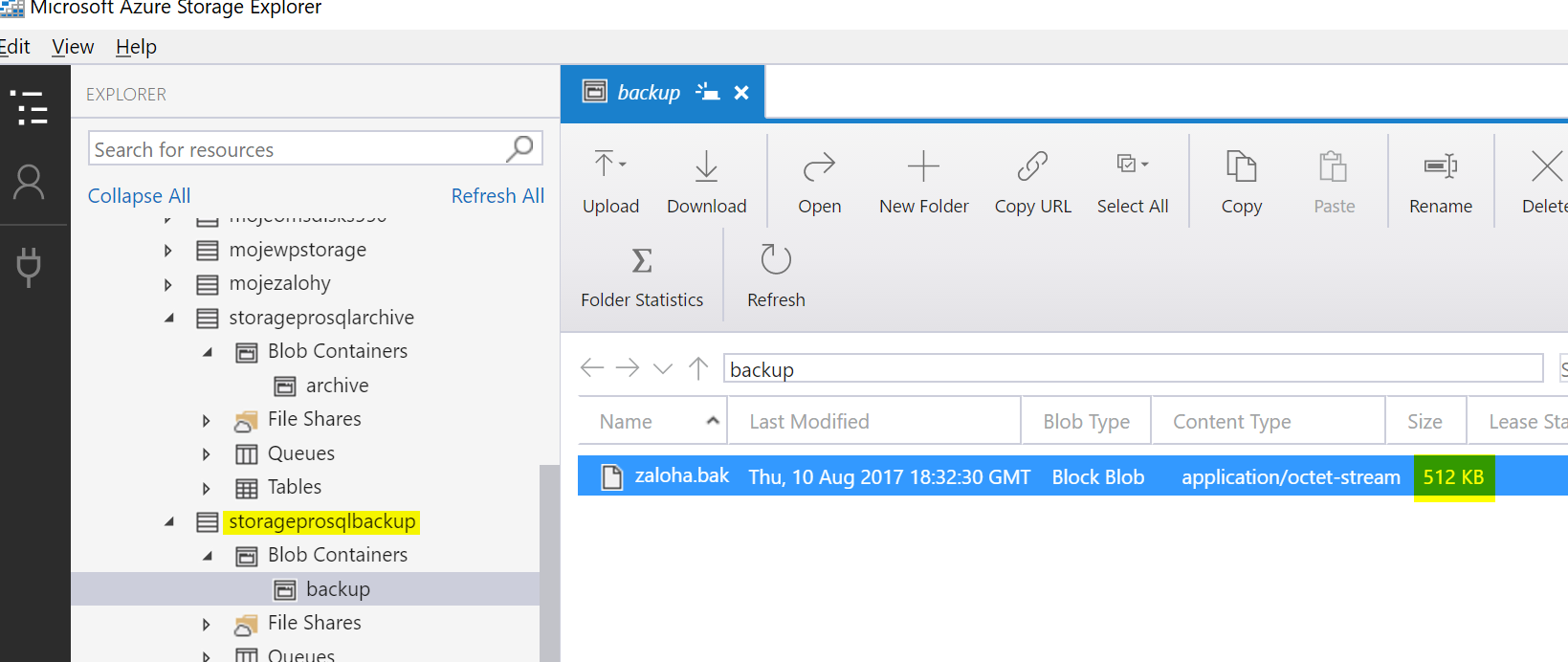
Provedeme backup se snapshot technologií - ten namíříme na mojí standardní backup storage.
BACKUP DATABASE [WideWorldImporters] TO URL = 'https://storageprosqlbackup.blob.core.windows.net/backup/zaloha.bak' WITH FILE_SNAPSHOT;
V primární datové storage uvidíme nový snapshot.
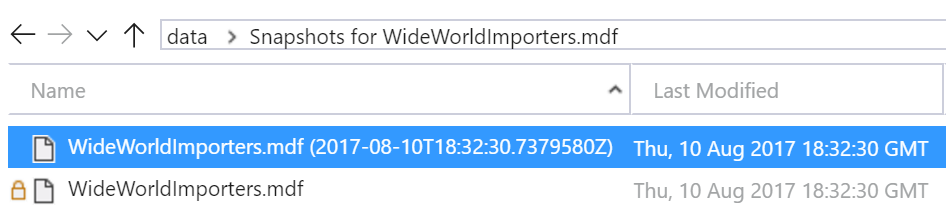
Jak vypadá bak soubor v té standardní backup storage? Podívejte se jak je malinkatý. Neobsahuje žádná reálná data, jde pouze o metadata, tedy referenci jaký snapshot patří k této záloze apod.
Pojďme si teď pro porovnání rozdílu provést řekněme archivní zálohu, tedy ne přes snapshoty, ale přímo rovnou komplet backup do Azure Storage, v mém případě archivního accountu. Tuto techniku můžete použít i pro on-premises SQL a tak dělat sekundární zálohu do Azure Storage přímo ze SQL prostředí.
BACKUP DATABASE [WideWorldImporters] TO URL = 'https://storageprosqlarchive.blob.core.windows.net/archive/archive.bak';
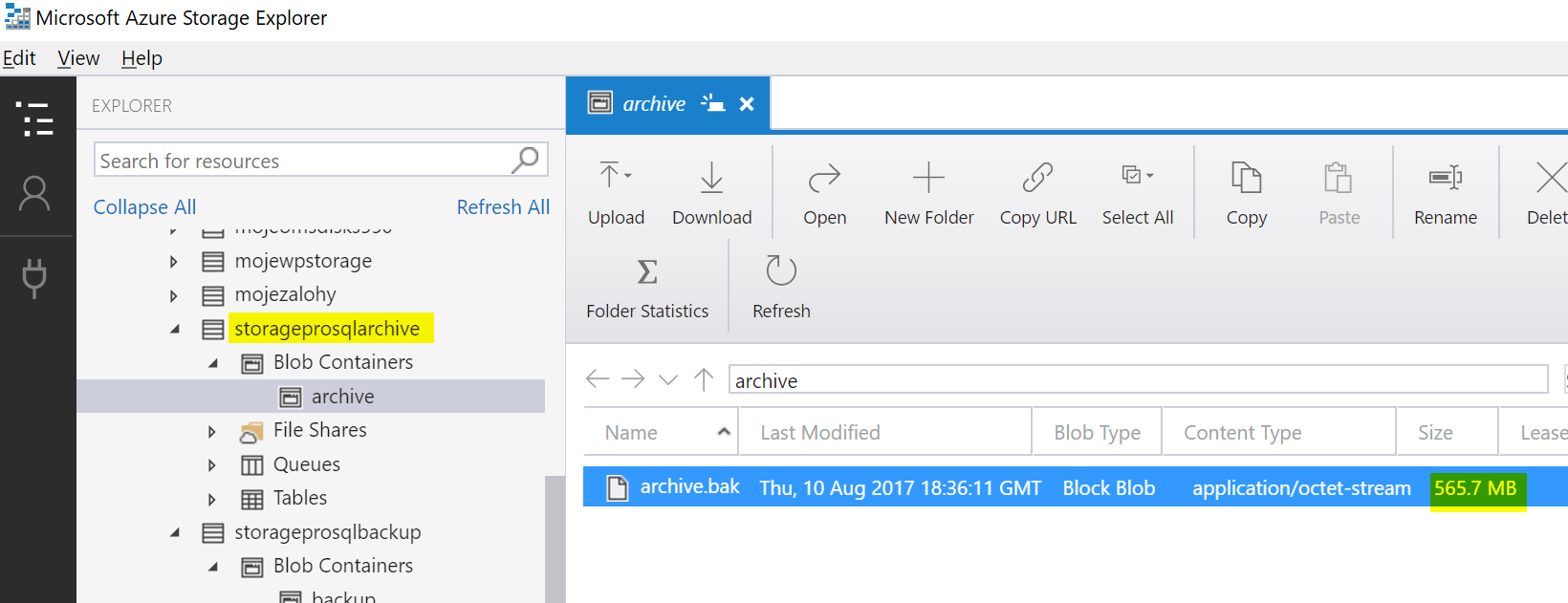
Jak to vypadá v archivní storage? Tentokrát soubor není titěrný - skutečně obsahuje naše data (komprimovaná).
Ukažme si jak se provádí restore. V tuto chvíli není možné obnovu provést přímo na sebe (tedy přepsat stávající soubory z verzí v snapshotu). Musíme vzít snapshot soubory a z těch udělat nové soubory a databázi přepojit na ně (je to jednodušší než to zní). Procedura vypadá nějak takhle. Odstavíme DB, provedeme restore do nových souborů, nahodíme DB. Všeproběhne velmi rychle.
ALTER DATABASE [WideWorldImporters] SET SINGLE_USER WITH ROLLBACK IMMEDIATE; USE [master] RESTORE DATABASE [WideWorldImporters] FROM URL = 'https://storageprosqlbackup.blob.core.windows.net/backup/zaloha.bak' WITH MOVE N'WWI_Primary' TO N'https://storageprosqldata.blob.core.windows.net/data/WideWorldImporters2.mdf', MOVE N'WWI_UserData' TO N'https://storageprosqldata.blob.core.windows.net/data/WideWorldImporters_UserData2.ndf', MOVE N'WWI_Log' TO N'https://storageprosqldata.blob.core.windows.net/data/WideWorldImporters2.ldf' GO ALTER DATABASE [WideWorldImporters] set multi_user;
Jak to vypadá v naší storage?
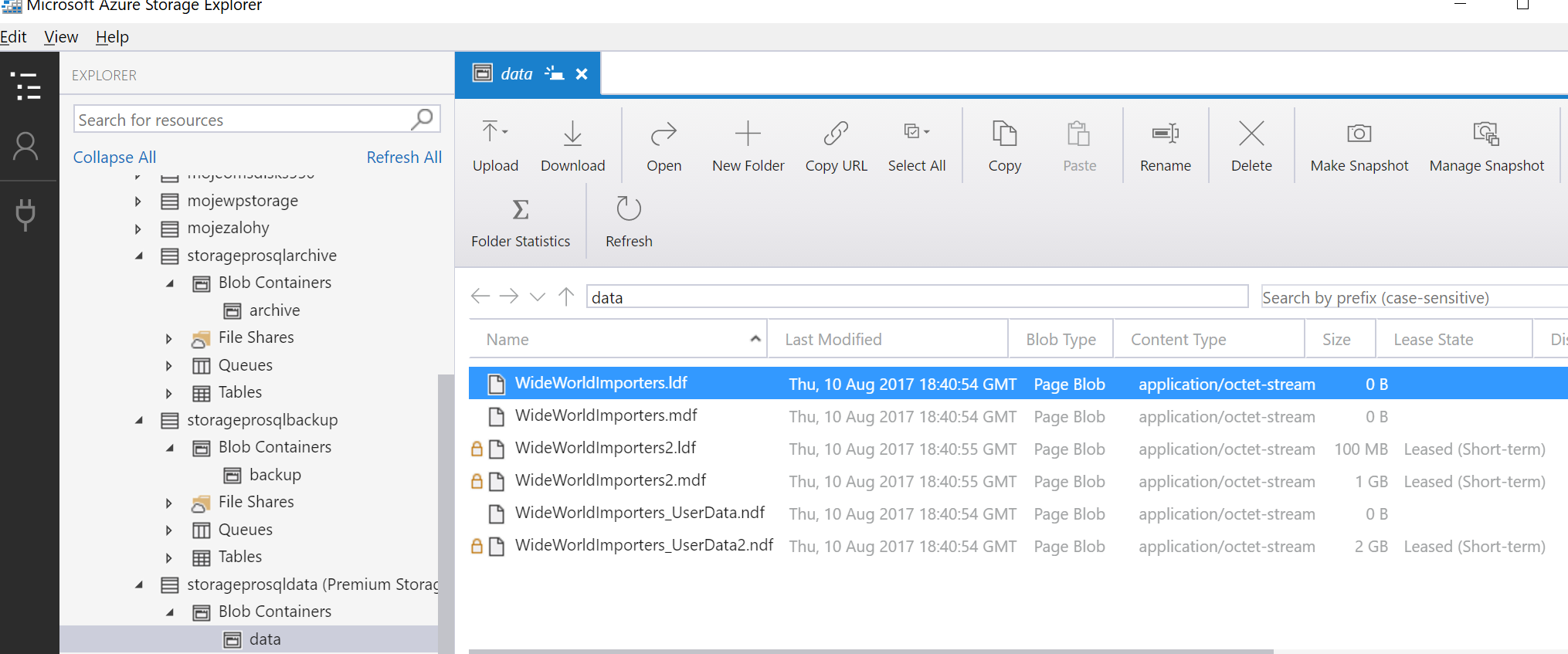
Azure SQL Database, tedy platformní databáze jako služba, je rozhodně moje primární volba. Nicméně pokud hledáte klasický SQL Server a chcete ho provozovat v Azure VM, zvažte využít verze 2016 s přímou podporou Azure Storage. Je to jednodušší, efektivnější a zálohy i obnovy jsou podstatně rychlejší.