Asynchronní zpracování je technika vhodná pro oddělení aplikačních částí a mikroslužeb, lepší uživatelskou zkušenost díky neblokujícím operacím a také velmi dobrá metoda škálování zátěže. Podívejme se jak něco takového využít ve formě služby v Azure a proč dává smysl to kombinovat se serverless přístupem.
Asynchronní zprávy
Jedním ze způsobů jak urychlit a zpřehlednit vývoj, snížit riziko zavlečení chyby a zbavení se špagetového propojení a efektu motýlých křídel (tak jak mávnutí křídel motýla může vyústit ve změnu počasí na druhé straně planety tak může změna v kódu pro příjem zpětné vazby zákazníků znefunkčnit třeba kód pro objednávky) je oddělit celky od sebe - klasicky formou tradiční SOA s ESB komunikací nebo moderněji s využitím microservices a nebo dokonce serverless s jednolivými programovými funkcemi. Blokující komunikace, tedy synchronní volání, je problematická - může zastavit zpracování ostatních věcí, mít negativní vliv na uživatelskou zkušenost a GUI a je náchylná k šíření problémů v systému (výpadek jednoho shodí i ostatní, což se musí řešit nasazováním circuit breakerů apod.).
Asynchronní řešení je v tomto směru lepší. Integrace není řešena nabídkou, kdy každá služba dává na odiv své API a ostatní se učí jak s ní komunikovat (rozumět jejímu API). Spíše jde o systém tažený poptávkou. Jedna komponenta generuje nějakou informaci (uživatel zaplatil za objednávku), nemusí řešit co se má stát dál, ale informaci o této události publikuje do - a o tom to dnes bude - například Azure Service Bus. Z něj si informaci mohou odebrat příjemci, tedy další aplikační součástky, které tato událost zajímá - vyskladňovací služba, dopravní služba, konfirmační email apod. Události mohou v systému zůstat i několik dní, takže případné dočasné selhání emailové služby neznamená, že celý systém má problém. Jakmile se nahodí sáhne si do fronty a zpracuje všechno co se mezitím stalo. Navíc i v rámci služeb může události zpracovávat vícero worker nodů a asynchronní frontu lze efektivně využít k balancingu a škálování. Funguje to jako lístečky na poště. To že jste vstoupili je událost, kterou zaznamená krabička na vydávání lístků. Worker nody představují otevřená okénka. Když se udělá moc velká fronta stačí otevřít další přepážky a odbaví se rychleji. Jakmile je nápor překonán, může si jít zase část personálu vařit kávu.
A co kdyby worker node vzniknul až v okamžiku, kdy je to opravdu potřeba? Proč sedět u okénka, když nikdo nejde? Skutečná plná elasticita cloudu přichází s konceptem serverless jako jsou Azure Functions (pro vámi psaný kód) a Azure Logic Apps (hotové integrace, kdy si proces naklikáte). Platí jen za samotné zpracování události z fronty, ne za běžící worker node.
Azure Service Bus a jak má vypadat aplikační architektura
Azure Service Bus (na rozdíl od jednodušších Azure Storage Queue) dokáže zajistit konzistentní pořadí zpráv (FIFO) i transakční zpracování (doručení celého shluku událostí jako celek s garantovaným pořadím a neoddělitelností) a detekci duplikátních zpráv. Nicméně platíte za to nižším výkonem a odolností (z hlediska teorie distribuovaných systémů je vám asi zřejmé že to vede buď na single node, což je jak to řeší ASB, nebo na distribuovaný konsensus aka dvoufázový commit - oboje nemá masivní škálovatelnost). Takže za mne - snažil bych se napsat aplikaci tak, aby to rozhodně nepotřebovala!
Kód zpracovávající událost by měl idempotentní. Pokud se omylem provede dvakrát, nemůže to vadit (pokud je moje funkce puvodni_hodnota = puvodni_hodnota + 5 tak to nesplňuji, po dvou spuštěních mám přičteno 10). Funkce musí být schopna jet znovu od začátku. Pokud proces zpracování umře v polovině, fronta po nějaké době neodpovídání procesu (ten si může blokaci na zpracování prodlužovat, ale pokud umře, už to neudělá), zařadí se zpět a zpracuje ji jiný worker node (a to je dobře). Ten ale musí být schopen jednoduše začít od začátku, systém nesmí být v nějakém neopravitelném polostavu.
Jednoduchá fronta s HTTP a Node.js knihovnou
Vyzkoušejme si odeslání a příjem v jednoduché Service Bus Queue. Azure nabízí jednoduché HTTP API a ta je velmi dobré pro jednoduché situace (nicméně existuje rozhodně efektivnější varianta viz dále).
Takhle vypadá můj Service Bus.
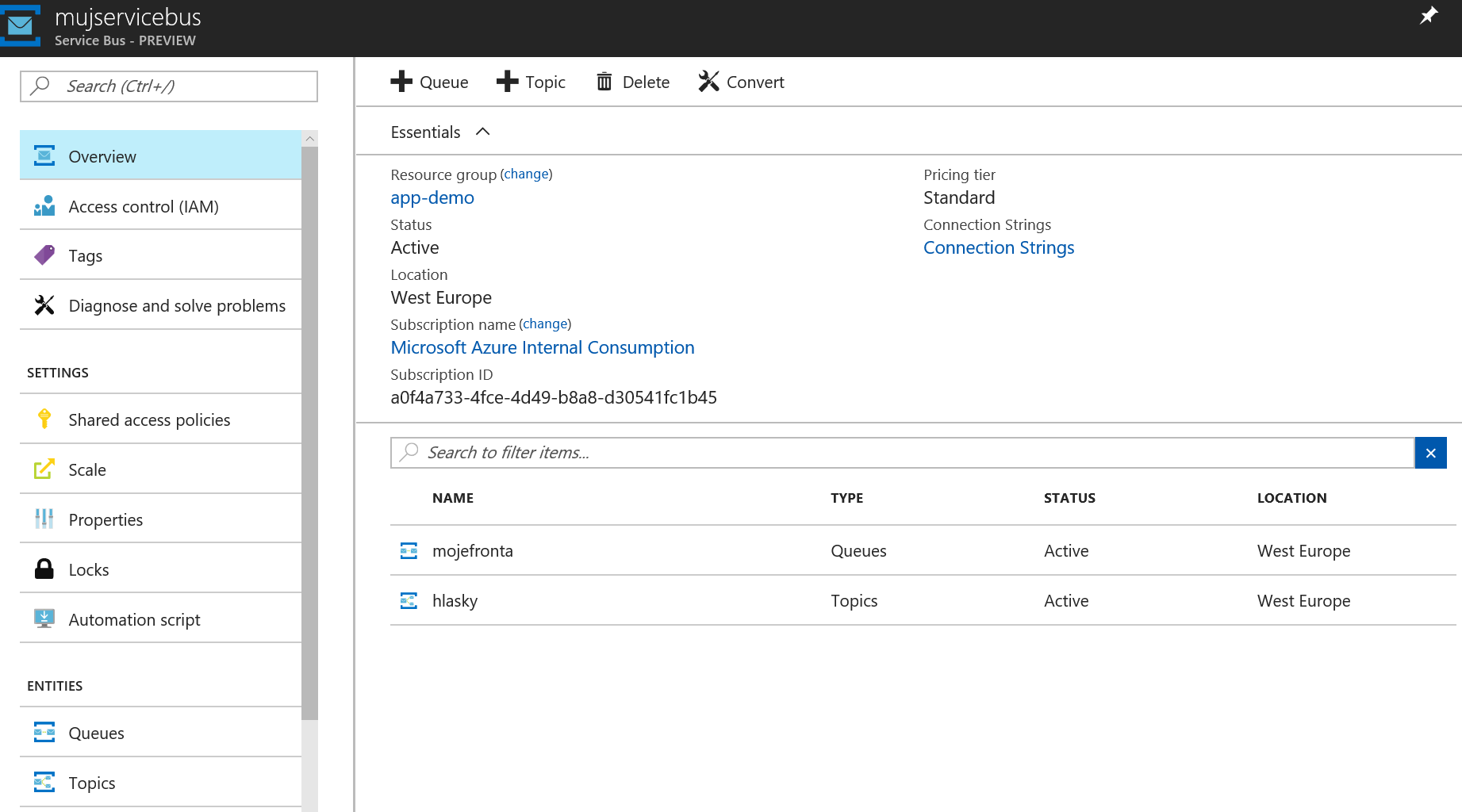
Mám založenou jednu frontu.
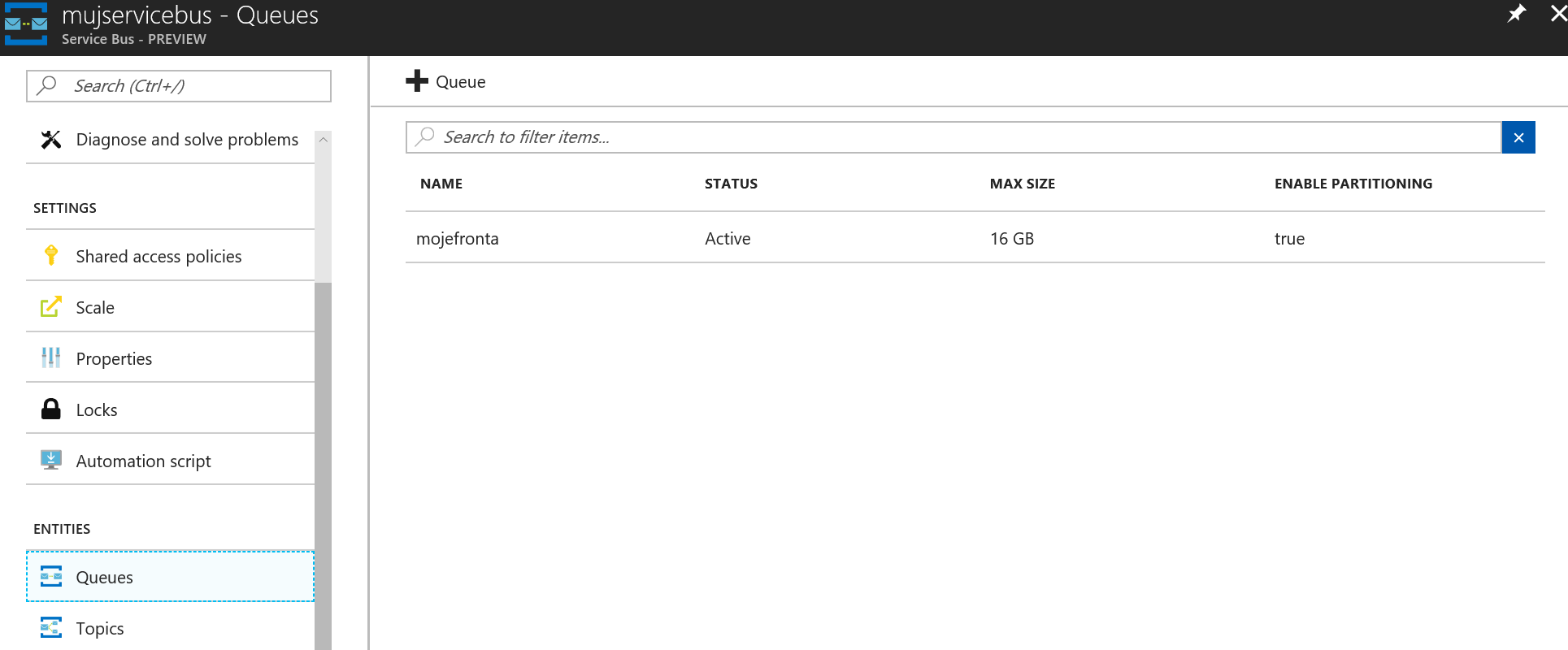
U každé fronty musíme mít nějakou přístupovou politiku, řekněme jméno a heslo. To mám i já.
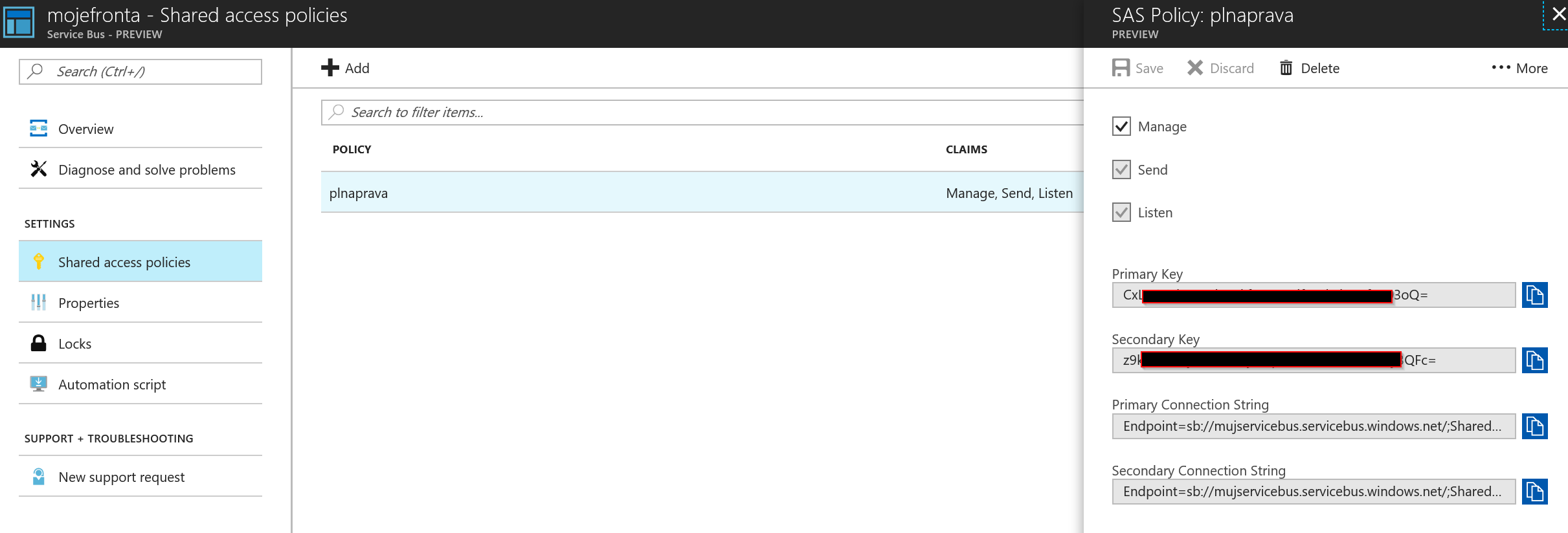
Podívejme se na jednoduchou Node.js appku na odeslání zprávy do fronty s využitím Azure SDK.
var azure = require('azure');
var args = require('cli.args')(['message:!']);
console.log('Posilame zpravu: ' + args.message);
var mujSB = azure.createServiceBusService('Endpoint=sb://mujservicebus.servicebus.windows.net/;SharedAccessKeyName=plnaprava;SharedAccessKey=CxL5........03oQ=');
var queueName = 'mojefronta';
mujSB.createQueueIfNotExists(queueName, function(error){
if(!error){
console.log('Mame pristup do fronty');
}
});
var message = { body: args.message };
mujSB.sendQueueMessage(queueName, message, function(error){
if(!error){
console.log('Zprava odeslana')
}
});
Nic složitého. A teď stranu příjemce, která bude co chvilku zprávy číst.
var azure = require('azure');
var mujSB = azure.createServiceBusService('Endpoint=sb://mujservicebus.servicebus.windows.net/;SharedAccessKeyName=plnaprava;SharedAccessKey=CxL5.....oQ=');
var queueName = 'mojefronta';
mujSB.createQueueIfNotExists(queueName, function(error){
if(!error){
console.log('Mame pristup do fronty');
setInterval(checkForMessage.bind(null, mujSB, queueName, processMessage.bind(null, mujSB)), 2000);
} else {
console.log('Nepodarilo se pripojit frontu');
}
});
var config = { isPeekLock: true };
function checkForMessage(mujSB, queueName, callback) {
mujSB.receiveQueueMessage(queueName, config, function(error, lockedMessage){
if(error){
if (error == 'No messages to receive') console.log('Zadne nove zpravy')
else callback(error);
} else {
console.log('Prijimame zpravu: ' + lockedMessage.body);
callback(null, lockedMessage);
}
})
};
function processMessage(mujSB, error, lockedMessage) {
if(!error){
console.log('Zpracovavame zpravu: ' + lockedMessage.body);
mujSB.deleteMessage(lockedMessage, function (deleteError){
if(!deleteError){
console.log('Zprava zpracovana a smazana');
}
});
} else console.log(error)
};
To je všechno. Žádné složitější funkce jsme si ale nevyzkoušeli, Service Bus toho umí víc - long polling (při neustálém zjišťování zda tam pro nás není nějaká nová zpráva nebudeme sestavovat session pokaždé znovu, ale budeme ji držet nahoře), dead letter queue (když se něco nepodaří doručit třeba třikrát, což naznačuje, že obsah způsobí crash ve zpracování, uklidí tuto zprávu Azure do separátn fronty, kde ji můžete prozkoumat), nepoužívá FIFO garance a tak podobně. Nicméně vidíme, že zprávu si z fronty pouze půjčujeme (Peek). Ta není v ten moment vidět pro ostatní, ale běží timeout (můžeme si ho při zpracování prodlužovat). Teprve po dokončení zpracování zprávu smažeme. Tzn. pokud by náš kód umřel mezi příjmem a dokončením, po nějaké době se zpráva do fronty vrátí a zpracuje ji někdo jiný.
Vážné použití s AMQP 1.0
REST API je skvělé pro řadu věcí, ale na zasílání a příjem zpráv ve frontě není ideální mimo jiné i z důvodu výkonu a efektivity. Existuje zcela standardní binární protokol AMQP 1.0 a Azure Service Bus ho podporuje! Díky tomu nepotřebujete žádné Azure specifické API či SDK. Použijete implementaci AMQP (pozor - původní verze standardu 0.9 není kompatibilní s 1.0) jakou chcete. Stejný kód vám bude fungovat jak na Azure Service Bus tak na jiné AMQP kompatibilní řešení jako je ActiveMQ, Qpid či RabbitMQ. Žádné přepisování.
Takhle vypadá odesílací část. Důležitá věc - musíme vytvořit URI fronty s názvem policy a heslem (za dvojtečkou). To musí být URL kompatibilní, takže znaky jako = musíte přepsat na %3D apod. (nebo do kódu použijte urlencode funkci).
var args = require('cli.args')(['message:!']);
console.log('Posilame zpravu: ' + args.message);
var AMQPClient = require('amqp10').Client, Promise = require('bluebird');
var Policy = require('amqp10').Policy;
var connectionString = 'amqps://plnaprava:CxL5XSUl.....oQ%3D@mujservicebus.servicebus.windows.net'
var client = new AMQPClient(Policy.ServiceBusQueue);
var queueName = 'mojefronta';
var message = { body: args.message };
client.connect(connectionString)
.then(function() {
return Promise.all([
client.createSender(queueName)
]);
})
.spread(function(sender) {
sender.on('errorReceived', function(tx_err) { console.warn('===> TX ERROR: ', tx_err); });
return sender.send(message).then(function (state) {
console.log('state: ', state);
process.exit(0);
});
})
.error(function(err) {
console.log("error: ", err);
});
A takto příjemce, který bude zobrazovat zprávy jak se mu objeví (nemusíme se ptát periodicky v kódu - knihovna to dělá sama).
var AMQPClient = require('amqp10').Client, Promise = require('bluebird');
var Policy = require('amqp10').Policy;
var connectionString = 'amqps://plnaprava:CxL5XS......03oQ%3D@mujservicebus.servicebus.windows.net'
var client = new AMQPClient(Policy.ServiceBusQueue);
var queueName = 'mojefronta';
client.connect(connectionString)
.then(function () {
return Promise.all([
client.createReceiver(queueName)
]);
})
.spread(function(receiver) {
receiver.on('errorReceived', function(rx_err) { console.warn('===> RX ERROR: ', rx_err); });
receiver.on('message', function (message) {
console.log('start');
var i = 0;
while (i < 1e10) i++; // simulate load
console.log('received: ', message.body);
if (message.annotations) console.log('annotations: ', message.annotations);
})
return null;
})
.error(function (e) {
console.warn('connection error: ', e);
});
Jedna událost, která zajímá víc ostatních
Queue je jen jednoduchá trubka kam padají události a soustava worker nodů (nebo jen jeden) si je odebírá. Víc nodů na odběru je z důvodu škálování, ale každý dělá to samé (platforma zajistí doručení minimálně jednou, což je na prakticky vždy jednou - jak jsme říkali lze za cenu nižšího výkonu vynutit i garance na právě jednou a FIFO). Co když je ale událost zajímavá pro víc dalších procesů? Třeba, jak jsem psal, dokončená objednávka zajímá skupinu worker nodů zajišťujících vyskladňování, jinou skupinku řešící dopravu a také jinou, která posílá zákazníkovi email. Na to použijeme Topic. Tématem tady bude dokončená objednávka a každá další navázaná služba bude subscriber. Ten také může použít různé formy filtru, tedy zajímat se jen o některé situace (třeba dokončená objednávka, která má osobní vyzvednutí na hlavním skladu, není zajímavá pro modul řešící dopravu).
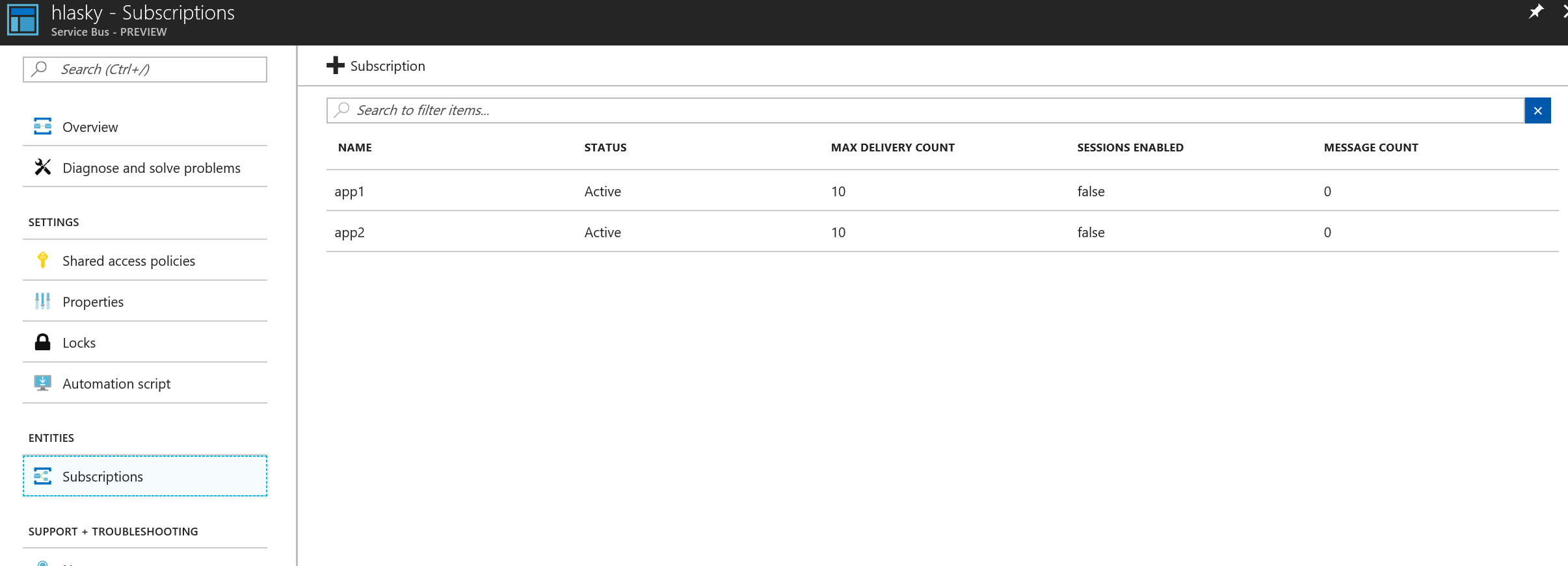
Založil jsem tedy topic. Jeho credentials si poznamenáme.
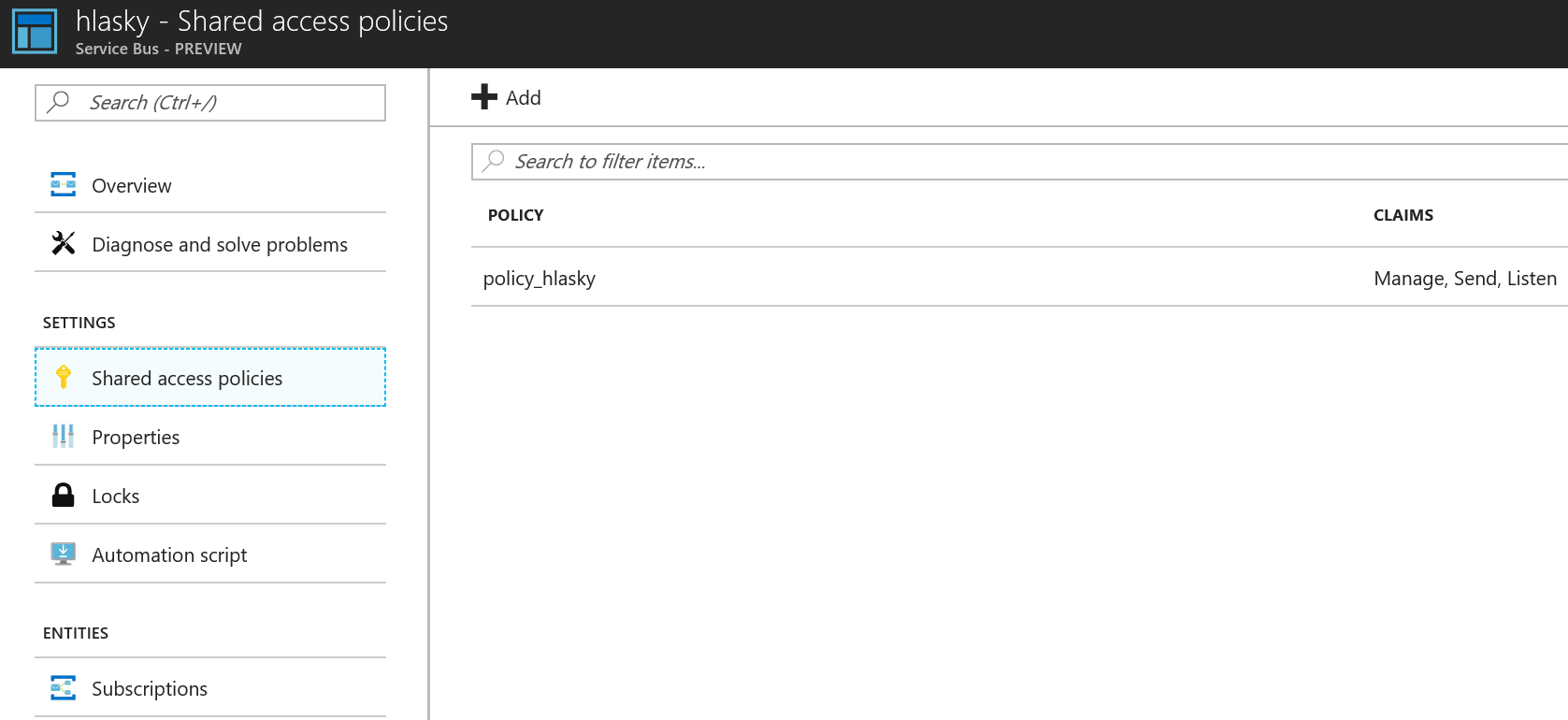
Založil jsem také dva odběratele - dvě mikroslužby, které obě tato událost zajímá.
Takto vypadá lehce pozměněný kód pro poslání zprávy do Topicu.
var args = require('cli.args')(['message:!']);
console.log('Posilame zpravu: ' + args.message);
var AMQPClient = require('amqp10').Client, Promise = require('bluebird');
var Policy = require('amqp10').Policy;
var connectionString = 'amqps://policy_hlasky:6sOR.....EU%3D@mujservicebus.servicebus.windows.net'
var client = new AMQPClient(Policy.ServiceBusQueue);
var topicName = 'hlasky';
var message = { body: args.message };
client.connect(connectionString)
.then(function() {
return Promise.all([
client.createSender(topicName)
]);
})
.spread(function(sender) {
sender.on('errorReceived', function(tx_err) { console.warn('===> TX ERROR: ', tx_err); });
return sender.send(message).then(function (state) {
console.log('state: ', state);
process.exit(0);
});
})
.error(function(err) {
console.log("error: ", err);
});
Kód příjemce je tady.
var args = require('cli.args')(['subscription:!']);
console.log('Poslouchame na subscription: ' + args.subscription);
var AMQPClient = require('amqp10').Client, Promise = require('bluebird');
var Policy = require('amqp10').Policy;
var connectionString = 'amqps://policy_hlasky:6sORZD.......t79yEU%3D@mujservicebus.servicebus.windows.net'
var client = new AMQPClient(Policy.ServiceBusQueue);
var topicName = 'hlasky';
var subscription = topicName + '/Subscriptions/' + args.subscription;
client.connect(connectionString)
.then(function () {
return Promise.all([
client.createReceiver(subscription)
]);
})
.spread(function(receiver) {
receiver.on('errorReceived', function(rx_err) { console.warn('===> RX ERROR: ', rx_err); });
receiver.on('message', function (message) {
console.log('received: ', message.body);
})
return null;
})
.error(function (e) {
console.warn('connection error: ', e);
});
V jednom okně si otevřeme příjmce app1.
node sb_topic_receive.js --subscription app1
V druhém příjemce app2.
node sb_topic_receive.js --subscription app2
A ve třetím okně pošleme zprávu. Pokud je vše správně dorazí oběma příjemcům.
node sb_topic.send.js --message "Ahoj frajeri"
Serverless s Logic App
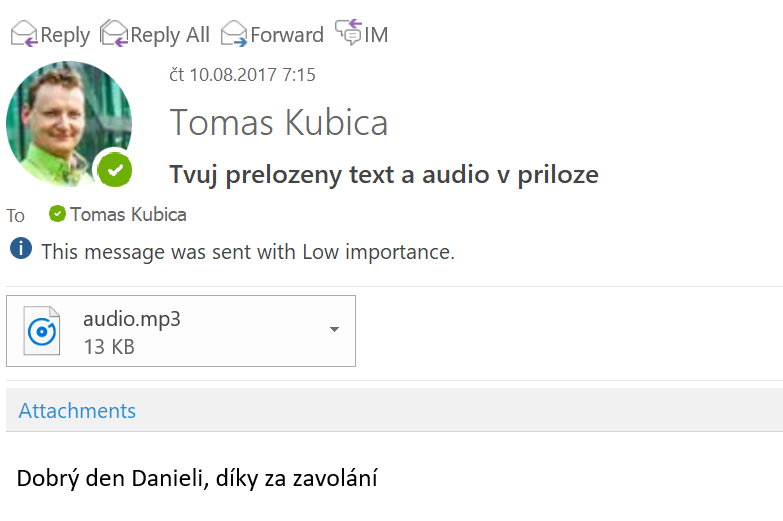
Co reagovat na událost až v okamžiku, kdy je to opravdu potřeba? Bez nutnosti mít nějakou VM, alokovaný zdroj v App Service Plan, puštěné nody v mém kontejnerovém clusteru? Ukažme si serverless reakci na událost a tentokrát bez psaní kódu s využitím Logic Apps. Zpracujeme zprávu tak, že její anglický text převedeme na řeč ve formátu MP3, přeložíme zprávu do českého textu a do mého emailu pošleme jednak přeložený text a nahrávku anglického přečtení. Uvidíte, že to bude triviální.
Celý proces vypadá takhle:
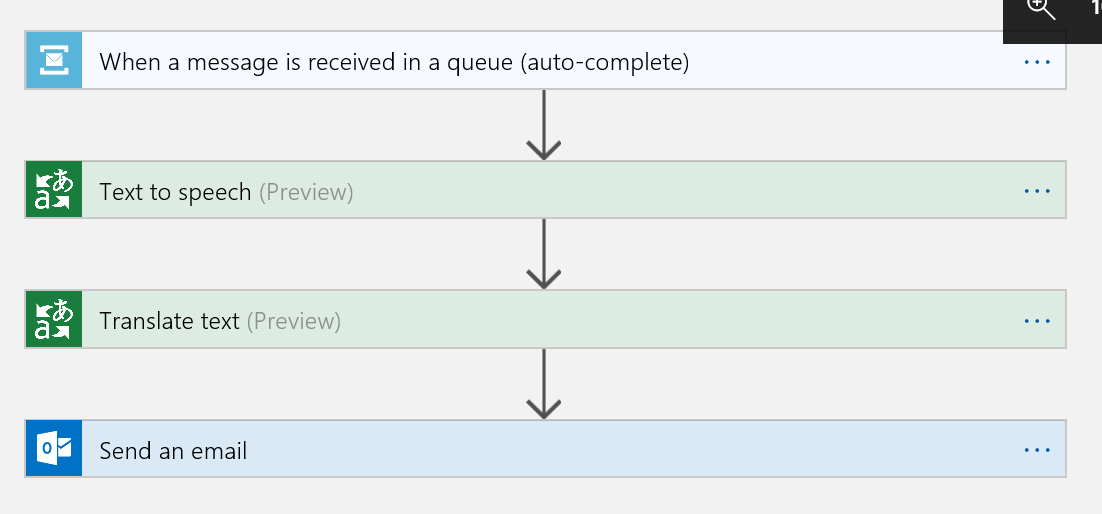
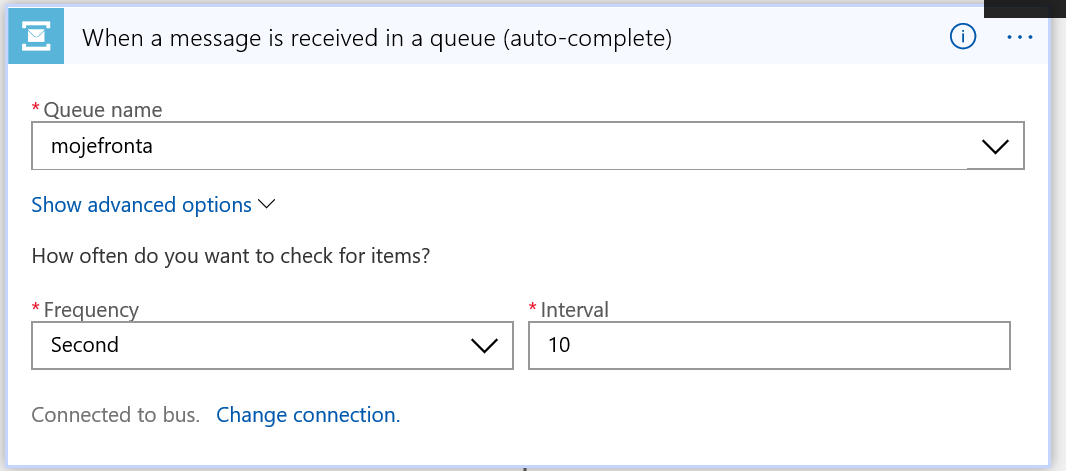
Nejprve načítám data z fronty. Tady si všimněte jedné nepříjemnosti - musím pollovat frontu, jestli v ní není náhodou něco nového. To není ideální a ještě se k tomu vrátíme.
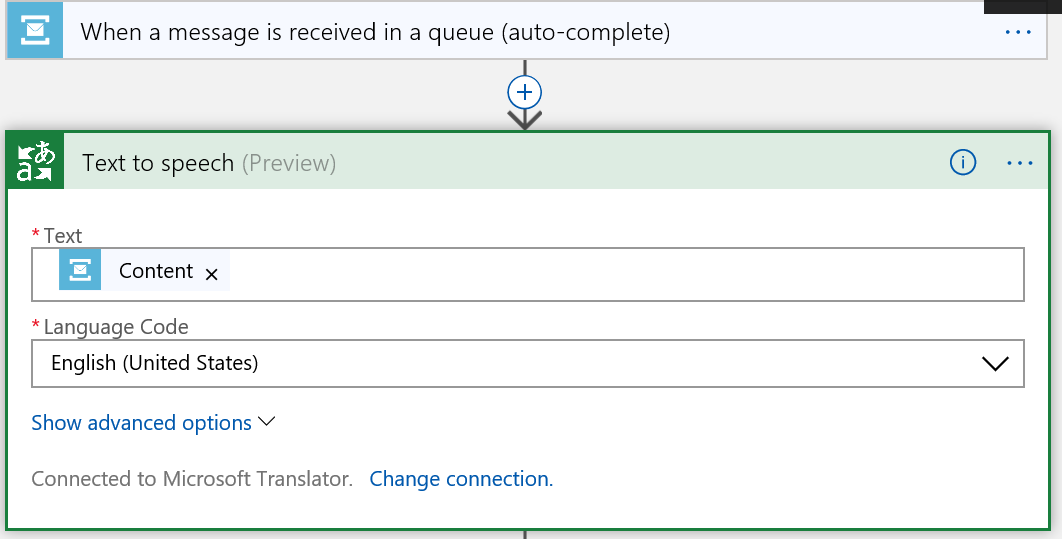
Obsah zprávy předhodím Azure kognitivní službě, aby mi z něj udělala nahrávku.
Obsah zprávy také přeložím do češtiny.
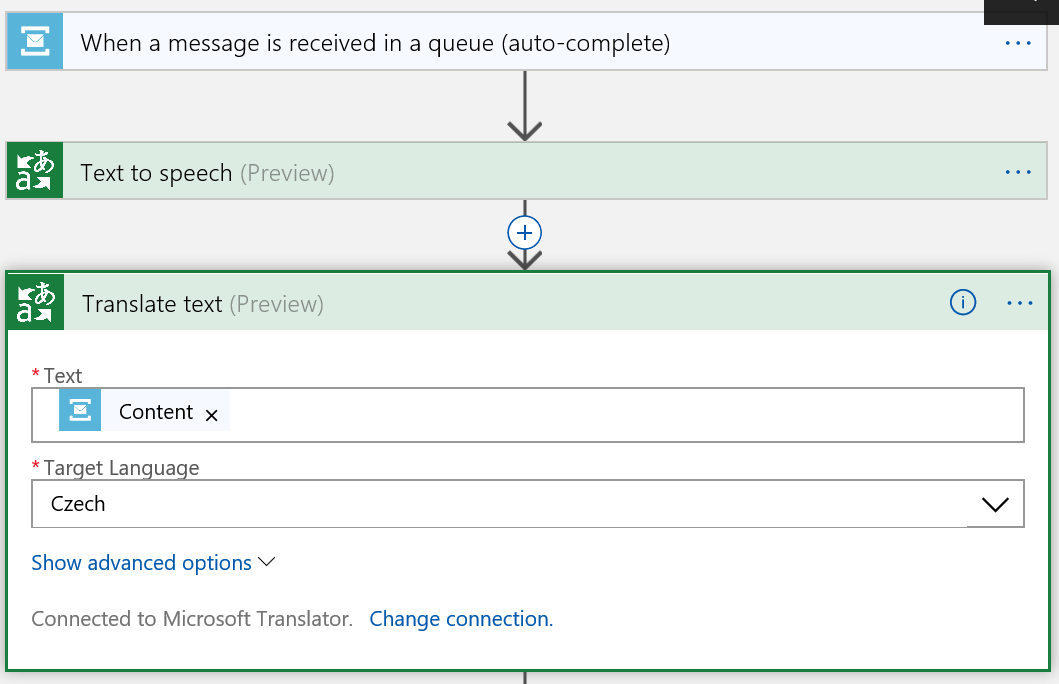
No a výsledek so pošlu do mailu.
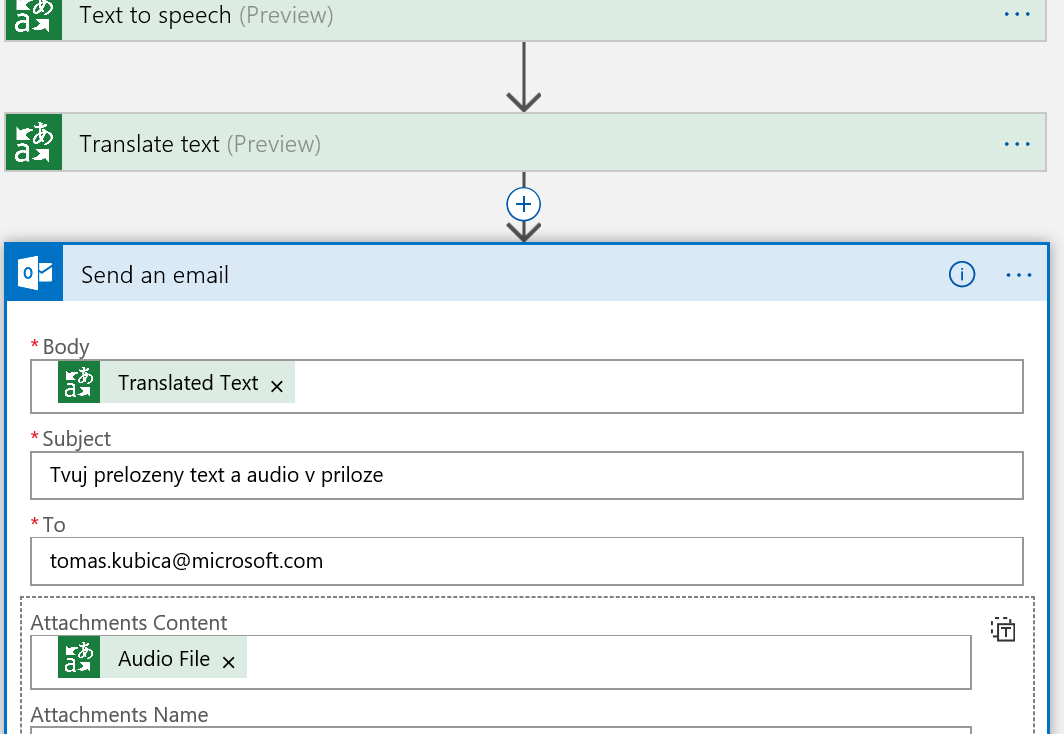
Snadné. Pošleme něco do fronty.
node .\sb_queue_send.js --message "Hello Daniel, thanks for calling me"
Během pár vteřin se všechno provede.
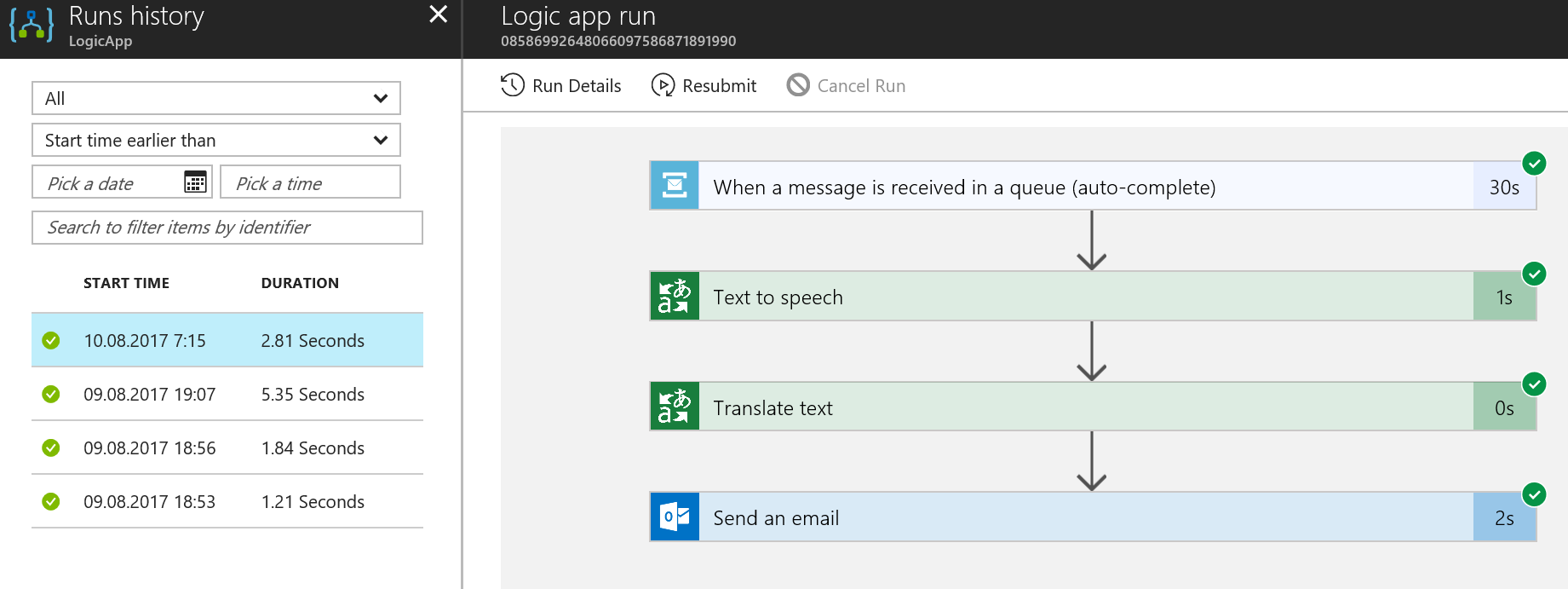
Momentíček... něco mi přišlo...
Jednoduché, ne?
Event Grid aneb řekni mi, až se bude něco dít
Všem těmto asynchronním principům chybí něco velmi důležitého. Je fajn, že nemusíme napřímo komunikovat a stačí zapsat zprávu do fronty a z té si ji někdo přečte. Bylo by ale efektivnější, kdyby se příjemci dozvěděli, že je něco hodné jejich zřetele. To se typicky řeší webhookem. Příjemce zprávy řekne odesílateli, že mu má zaťukat na jeho URL. Odesílatel připraví potřebná data (a klidně je třeba dá někam do fronty, to už je jedno) a zklepe příjemci na rameno přes webhook. To je fajn, ale je to "bilaterální dohoda". Každý odesílatel si to musí vyjasnit s každým příjemcem. Fantastická oddělenost, kterou přináší zejména publish/subscribe model je pryč. Správa něčeho takového je komplikovaná. No a zajištění retry při nedoručitelnosti je noční můra. Chybí nějaký mechanismus notifikací. Něco, co nebude přímo zasílat data, ale bude ve správný čas ťukat správným komponentám na rameno. To je Azure Event Grid.
Event Grid si představte jako spolehlivého správce webhooků. Na jdené straně má vstupní události - například to, že je nový soubor v blob storage, nová zpráva ve frontě a tak podobně. K Event Grid se registrují ti, kteří chtějí zaklepat na rameno - říkají co je zajímá. Třeba Logic Apps (spuštění nějakého workflow), Azure Function (spuštění nějakého kódu) nebo i generický webhook (odeslání notifikace do jakékoli aplikace). V zásadě je Event Grid skutečně něco jako správce a zprostředkovatel webhooků.
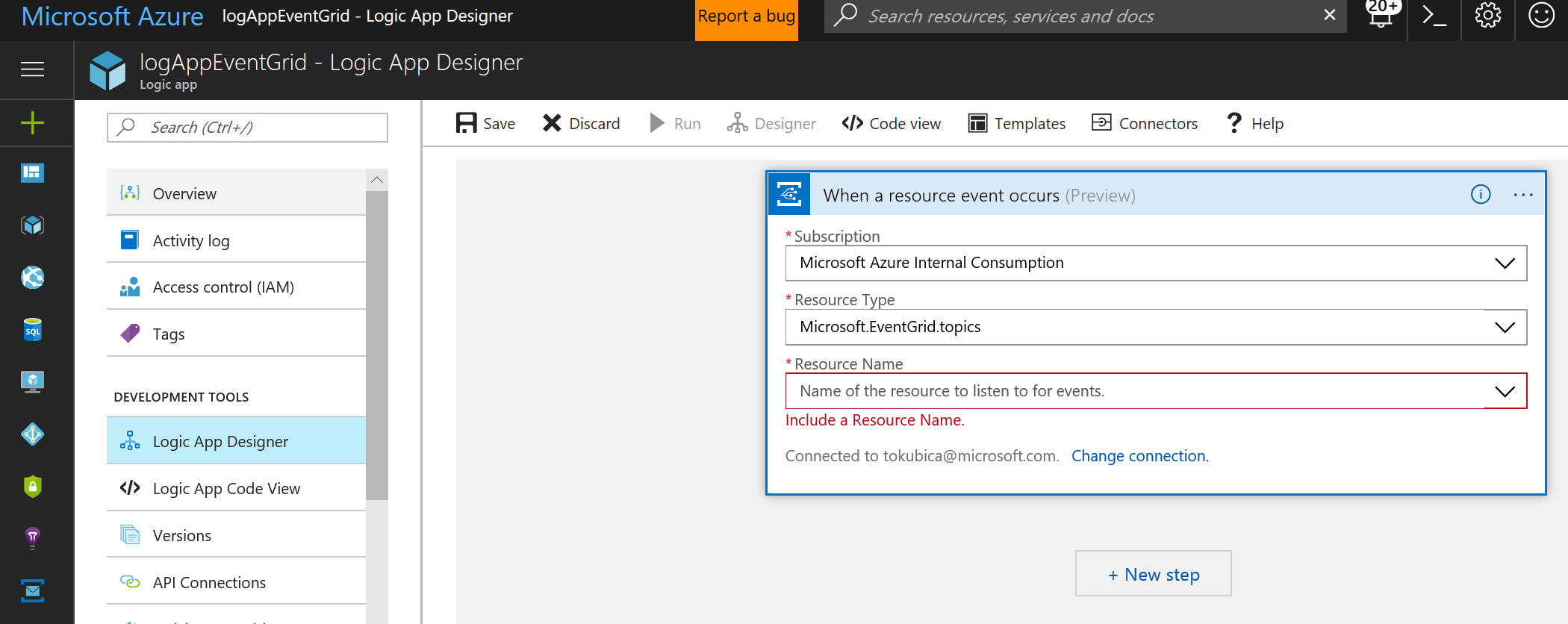
Takhle například můžeme v Logic Apps reagovat na události v Event Grid.
K tématu Event Grid se na tomto blogu ještě vrátíme, je tam hodně o čem mluvit.
Používání asynchronních principů je ve světě moderních aplikací a mikroslužeb velmi populární a Azure nabízí frontu jako službu a to kompatibilní se standardem AMQP 1.0, takže nejste nijak uzamčeni k jedné platformě. Zejména v kombinaci se serverless světem jako jsou Azure Functions a Azure Logic Apps se dá zvádnout opravdu hodně velmi rychle a elegantně. Vylepšete své aplikace ještě dnes.