Přemýšlet o tom, jak zařídit, aby vaše aplikace byla skvělá, je zábavné a naplňující. Je to stejné jako přemítat o tom, jak úžasná bude vaše dovolená nebo nový byt - kam půjdete, co kam dáte, co jak zařídíte. Daleko míň nadšení přináší úvahy typu a co když materiál zdraží na dvojnásobek, co když to nebude pasovat, co když řemeslník nedorazí, co když ztratím pas, co když děcko dostane COVID. Často tak máme tendenci mít fantasticky promyšlený scénář úspěchu a přípravu na ty nepovedené trochu odflákneme. A to i při provozu aplikací.
Co s tím? Chce to myslet trochu negativně. Když o ničem moc nepřemýšlíte a ono vám to skvěle funguje, tak je klidně možné, že máte prostě jen kliku - a to není strategie. Lepší je nedoufat a tím peklem si projít a proč čekat na to, až to ovlivní vaše uživatele, když pořádné inferno můžete rozpoutat ve svém testovacím prostředí? Dnes budeme šířit chaos díky Azure Chaos Studio.
Proč dělat chaos
Důvody jsem naznačil v předchozím odstavci, tak je pojďme trochu rozvést:
- To, že si myslím, že je něco odolné, není totéž, jako vědět, že to odolné je.
- Vývojáři mohou udělat změny, které mají negativní dopad na schopnost přestát havárie a to nemusím chytnout ve standardní testu zaměřeném na to dobré. Jinak řečeno to, že jsem loni při výpadku ověřil, že redundance funguje neznamená, že funguje dnes, protože se kód mnohokrát změnil.
- Je samozřejmě skvělé, když se věci vyřeší automaticky a aplikace dokáže tolerovat výpadek, ale ne vždy je to možné nebo rentabilní vzhledem k velikosti týmu. Ruční zásah není nutně špatně, ale klíčem je schopnost detekovat problém a pochopit příčinu. Monitorujeme věci tak, abychom problémy včas odhalili a netápali ve tmě? Nenaletěli jsme na chybné vnímání světa na svítí/nesvítí a problém typu funguje, ale blbě, neumíme odhalit a řešit?
- Při havárii autobusu dokáže náhodou přítomný záchranář v civilu reagovat daleko rychleji a přesněji, než průměrný cestující. Jasně, znalosti mu pomůžou použít správné postupy, ale schopnost zareagovat není o znalosti, ale cviku a zkušenosti. Kdo nikdy nezachraňoval, má to mnohem těžší.
Azure Chaos Studio
Microsoft uvedl do preview novou službu na generování a řízení chaosu, která vychází z technologií, které používá dlouhodobě interně. Umožní naplánovat komplexní scénáře a postupy, celé workflow, kdy si vaše aplikace projde peklem - 3 minuty škodí tady, pak 2 minuty tady.V zásadě jde o tři hlavní oblasti testů:
- Azure jako takový, tedy restart platformní služby, sestřelení VM, síťové odizolování komponenty přes NSG a seznam se bude jistě významně rozšiřovat
- Aplikace ve VM, kdy se použije agent, který na základě příkazů z Azure Chaos Studio provádí záškodnické akce. U Linuxu typicky s využitím stress-ng nebo zabíjení procesů, u Windows díky interně vyvinuté technologii, která dokáže věci jako sestřelování procesů, izolace sítě, zanášení latence do síťové komunikace, generování zátěže apod.
- Kubernetes, kdy se využívá výborné open source technologie Chaos Mesh, o které jsem psal v samostatném článku
Co mě opravdu potěšilo je propracovanost co do řízení přístupů. Každý agent ve VM má svou identitu, celé chaos studio má svou identitu a každý jednotlivý experiment taky. Do toho přidejte proces onboardování a zapínání jaké funkce na kterém zdroji jsou k dispozici. Zkrátka zdá se mi, že služba udělala opravdu všechno pro to, abyste si omylem nezavraždili produkci nebo aby nějaký super silný účet nepřinášel bezpečnostní riziko.
Služba je v preview a očekávám tam bouřlivý vývoj. Jedna oblast, kde do budoucna doufám ve vylepšení je integrace s věcmi jako Azure Load Testing (generování zátěže a měření výsledků) nebo Application Insights (dostupnost a výkonnost aplikací). Moc rád bych tohle propojil dohromady a dostal výsledný report - tady je generovaná zátěž vs. dostupnost aplikace a jak to vypadá v jednotlivých fázích chaos experimentu.
Připravíme si prostředí
Nahodím si nějaká VMkaa, chaos studio, identity, přístupy.
az provider register -n Microsoft.Chaos
az group create -n chaos -l westeurope
az network vnet create -n chaosnet -g chaos --address-prefixes 10.10.0.0/16
subnetId=$(az network vnet subnet create -n default --address-prefixes 10.10.0.0/20 -g chaos --vnet-name chaosnet --query id -o tsv)
az aks create -n chaosaks -g chaos -c 1 -x -s Standard_B2s --vnet-subnet-id $subnetId -y
az network nsg create -n chaosvmnsg -g chaos
az network nsg rule create -n ssh -g chaos --nsg-name chaosvmnsg --priority 120 --source-address-prefixes $(curl ifconfig.io) --destination-port-ranges 22
az network nsg rule create -n rdp -g chaos --nsg-name chaosvmnsg --priority 130 --source-address-prefixes $(curl ifconfig.io) --destination-port-ranges 3389
az identity create -n chaosidentity -g chaos
az role assignment create --role Contributor \
--assignee-object-id $(az identity show -n chaosidentity -g chaos --query principalId -o tsv) \
-g chaos
az vm create -n chaosvm \
-g chaos \
--size Standard_B1s \
--image UbuntuLTS \
--admin-username tomas \
--ssh-key-values ~/.ssh/id_rsa.pub \
--public-ip-address chaosvmip \
--nsg chaosvmnsg \
--assign-identity chaosidentity
az vm create -n chaosvmwin \
-g chaos \
--size Standard_B2s \
--image Win2019Datacenter \
--admin-username tomas \
--admin-password Azure12345678 \
--public-ip-address chaosvmipwin \
--nsg chaosvmnsg \
--assign-identity chaosidentity
az aks get-credentials -n chaosaks -g chaos
redisName=chaosredis$RANDOM
az redis create -n $redisName -g chaos --sku Premium --vm-size p1 -l westeurope --shard-count 2
Nasazení Chaos Studia a první experiment
Pojďme tedy do Chaos studia.
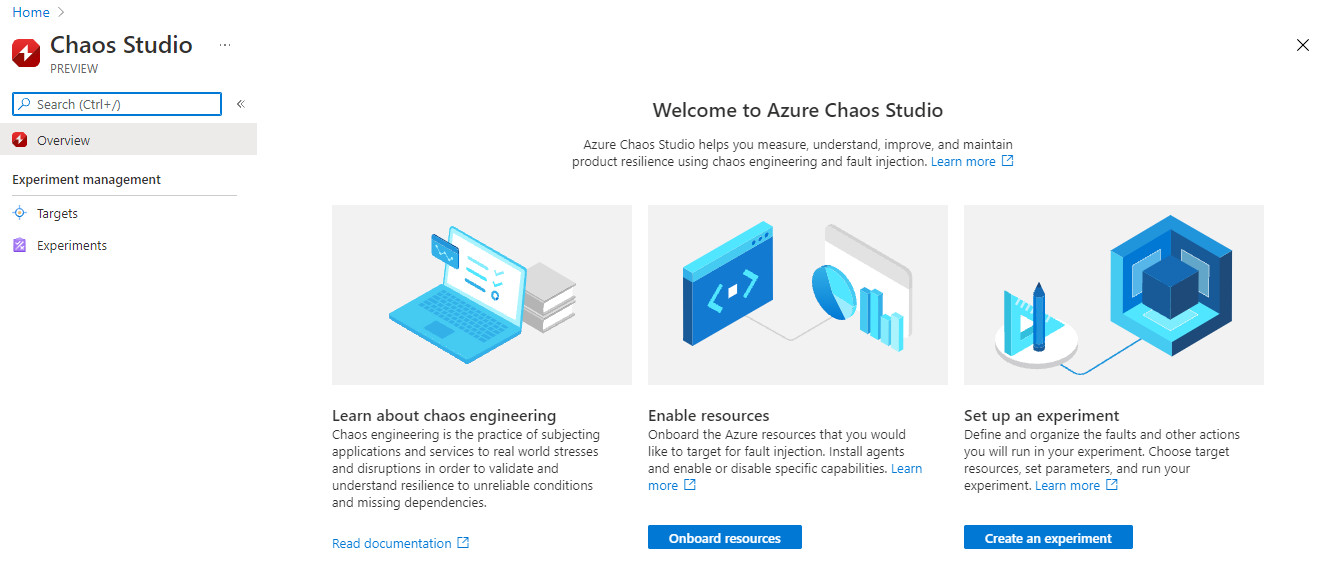
Nejdřív nalodíme všechny zdroje do studia.
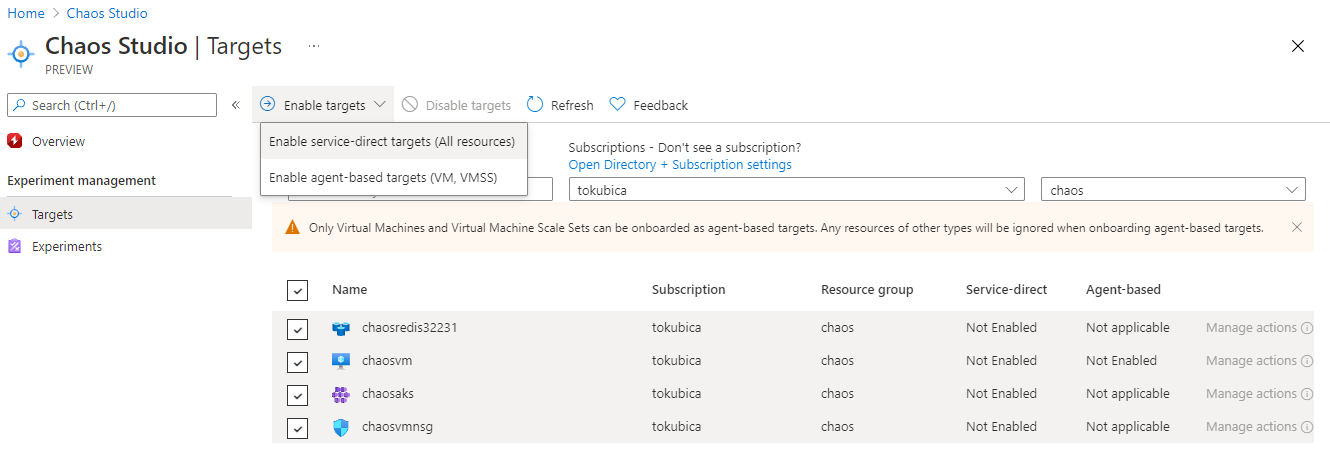
V případě VM musí Azure doručit Azure Chaos Studio agenta do virtuálky - nalodíme.
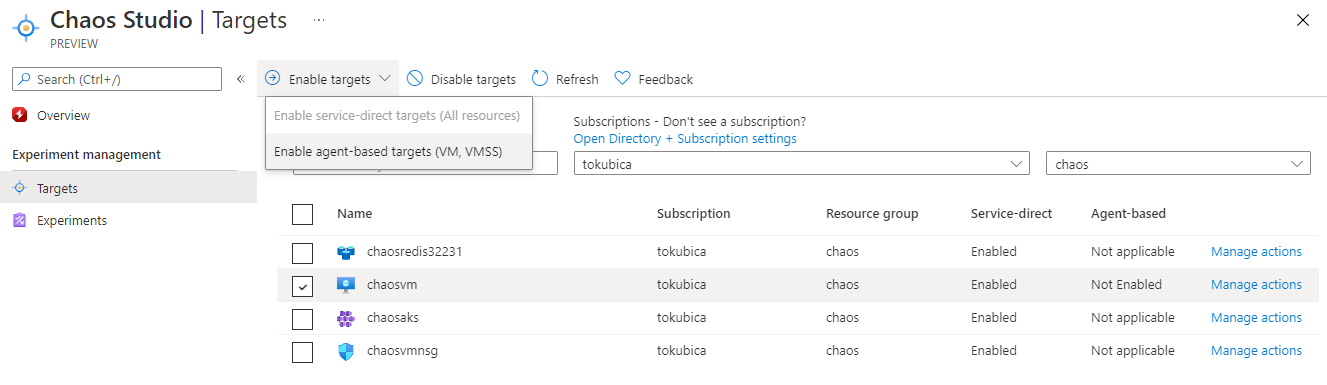
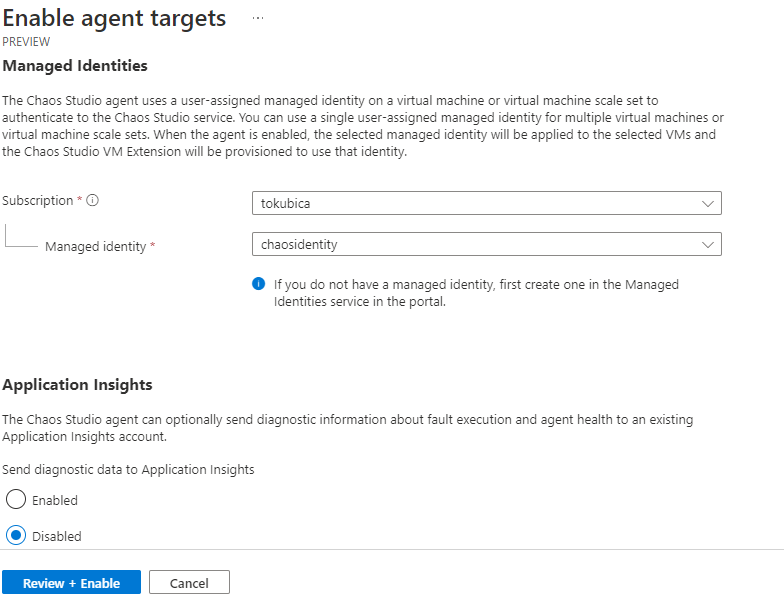
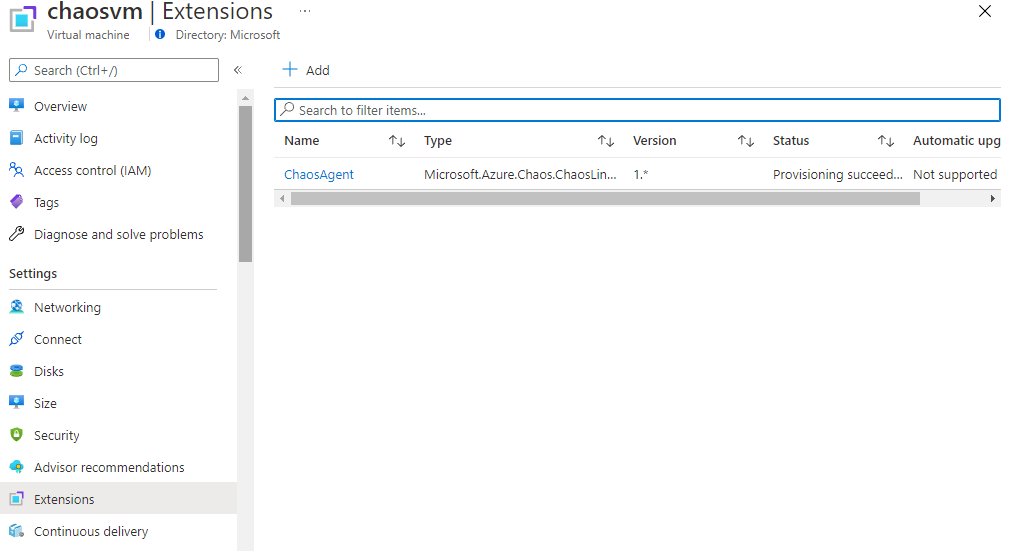
Následně můžu u každé VM selektivně říct, které testy jsem ochoten pro ni připustit.
Pojďme tedy vytvořit první experiment.
Každý experiment se skládá ze sekvenčních kroků a v každém může být několik větví. Do toho vkládáme jednotlivé záškodnické akce včetně možnosti čekat, než sestřelíme další věc.

Začněme NSG akcí - pojďme dost brutálně zakázat VM, na které NSG je, jakoukoli komunikaci ven, takže ji efektivně odstřihneme. Dejme jí tuto drastickou kůru po dobu jedné minuty.
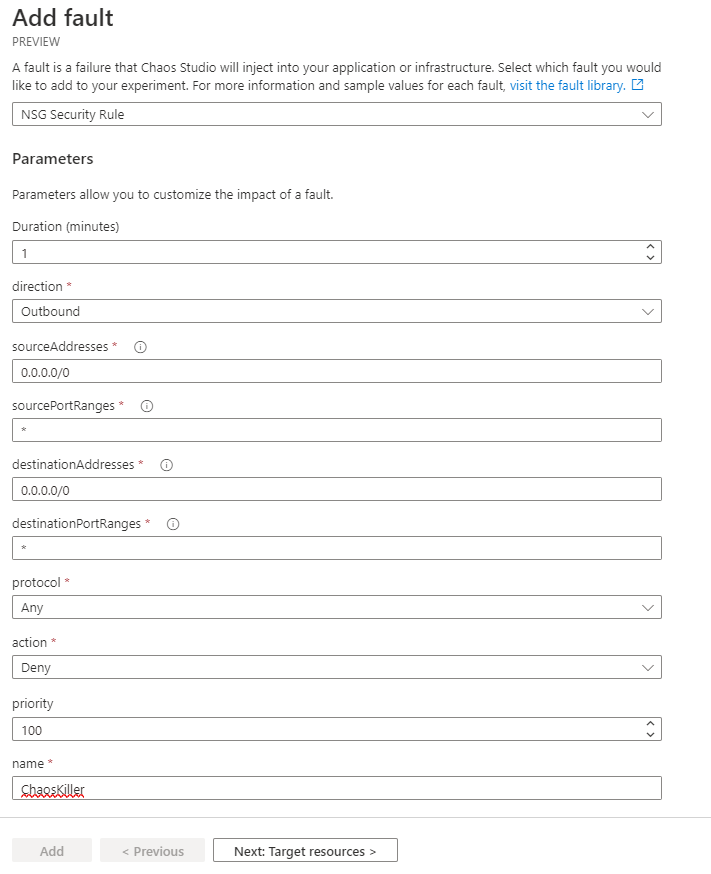
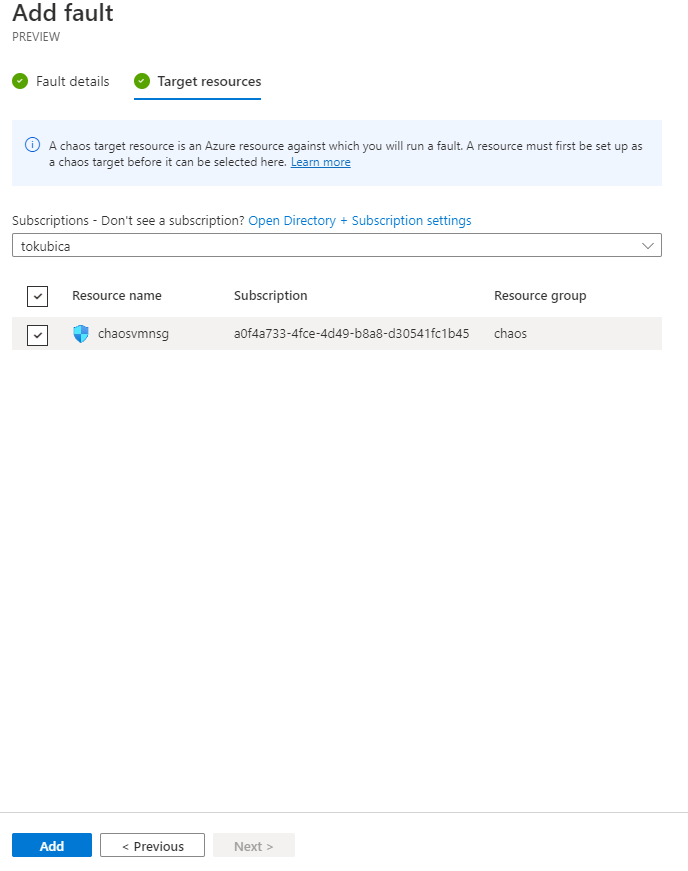
Každý experiment má svou identitu a ve výchozím stavu samozřejmě nemůže vůbec nic. Musím mu proto aktivně přiřadit práva. Nemusím se tedy být - i kdyby byl někdo Contributor mé produkce, nemůže omylem vytvořit experiment, který ji sestřelí - musí být Owner nebo User Access Manager, aby mohl taková práva experimentu dát.
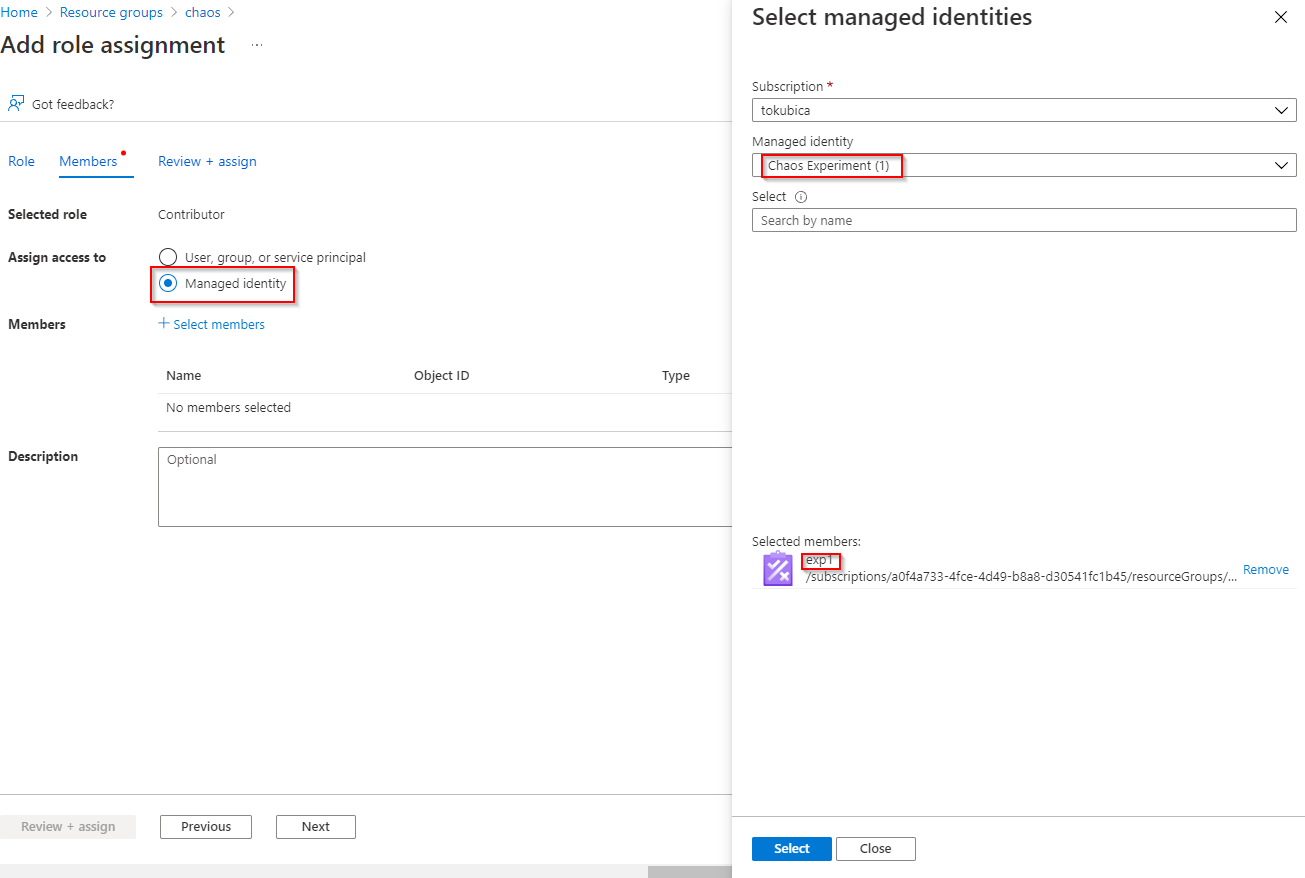
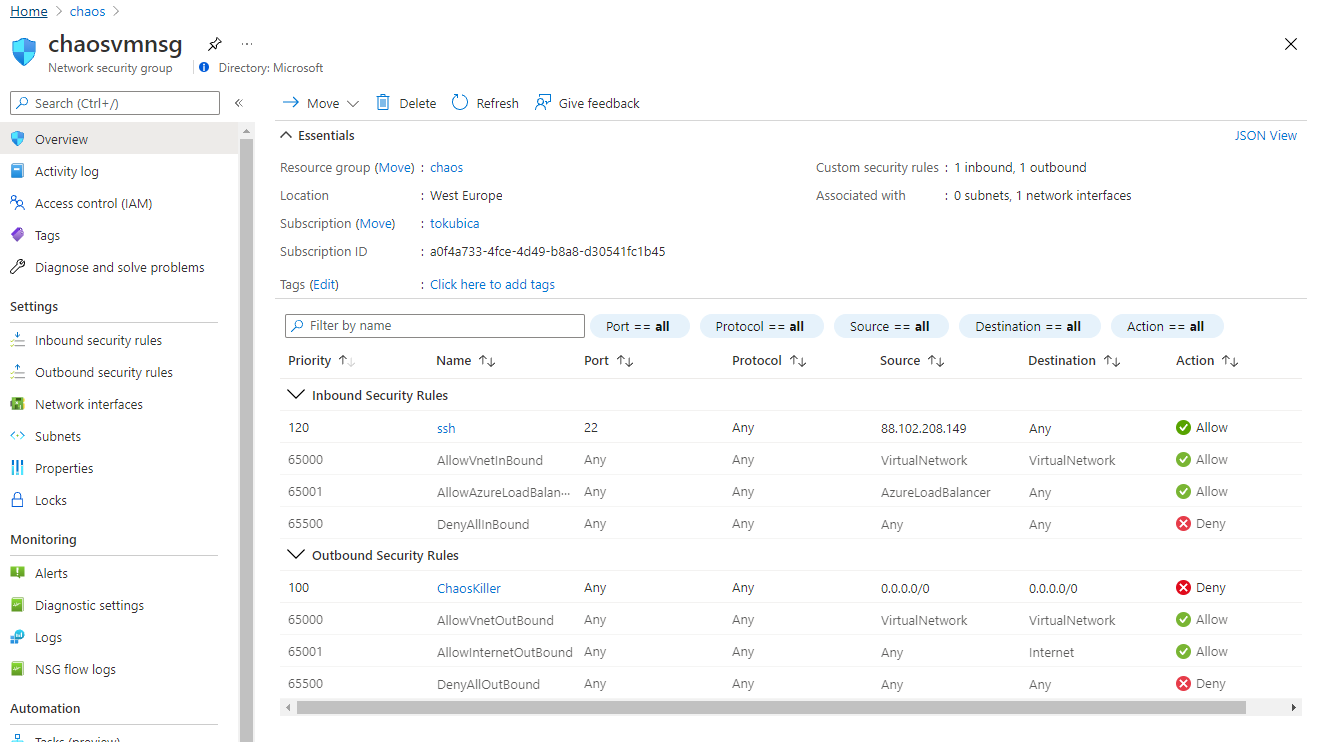
Takhle vypadá moje NSG před zásahem záškodníků.
Spusťme experiment.
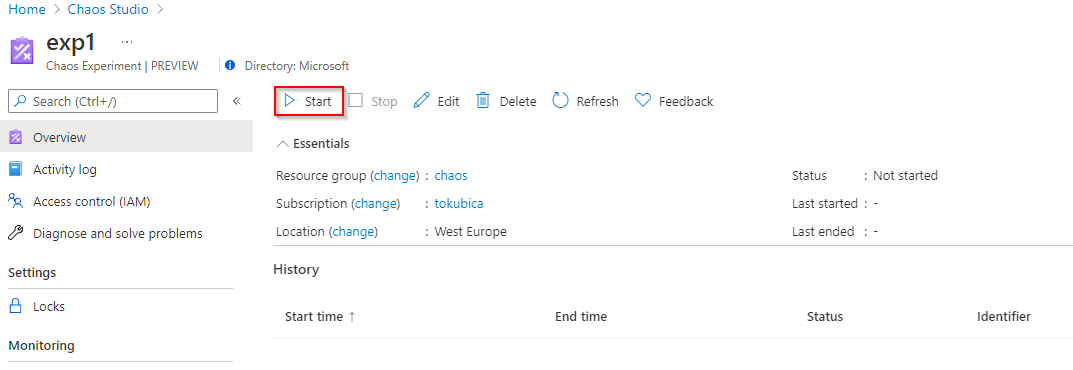
Po chvilce se NSG změní … škodíme. Po nastaveném čase (1 minuta) se vrátíme do normálu.
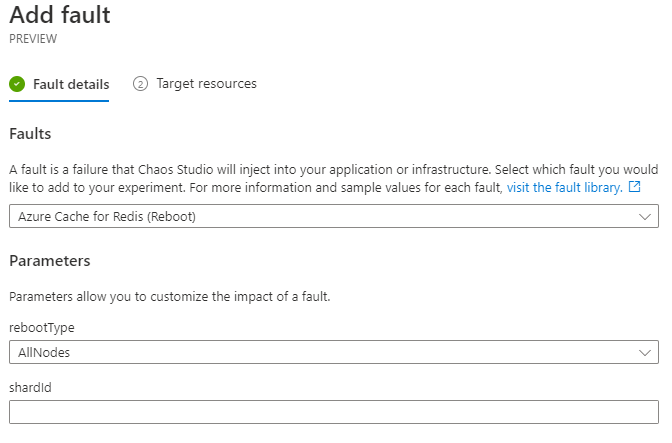
Restart Azure Redis
Zkusme teď další další sabotáž - restart Azure Redis, což by nám mohlo v aplikaci sestřelit Redis spojení a propláchnou cache.

Podíval jsem se do Activity Log o mé Azure Redis a vidím, že identita exp1 tam skutečně byla a provedla restart - mrška.

Necháme Azure ubližovat mašinkám
Pojďme teď jednoduše vypnout VM, protože hardware může umřít, VM nám na chvíli zmizí (než se spustí jinde) a jak se s tím vypořádáme? Ten cluster co máme nastaven - funguje vůbec?
Vypnutí provedeme na dvě minuty.
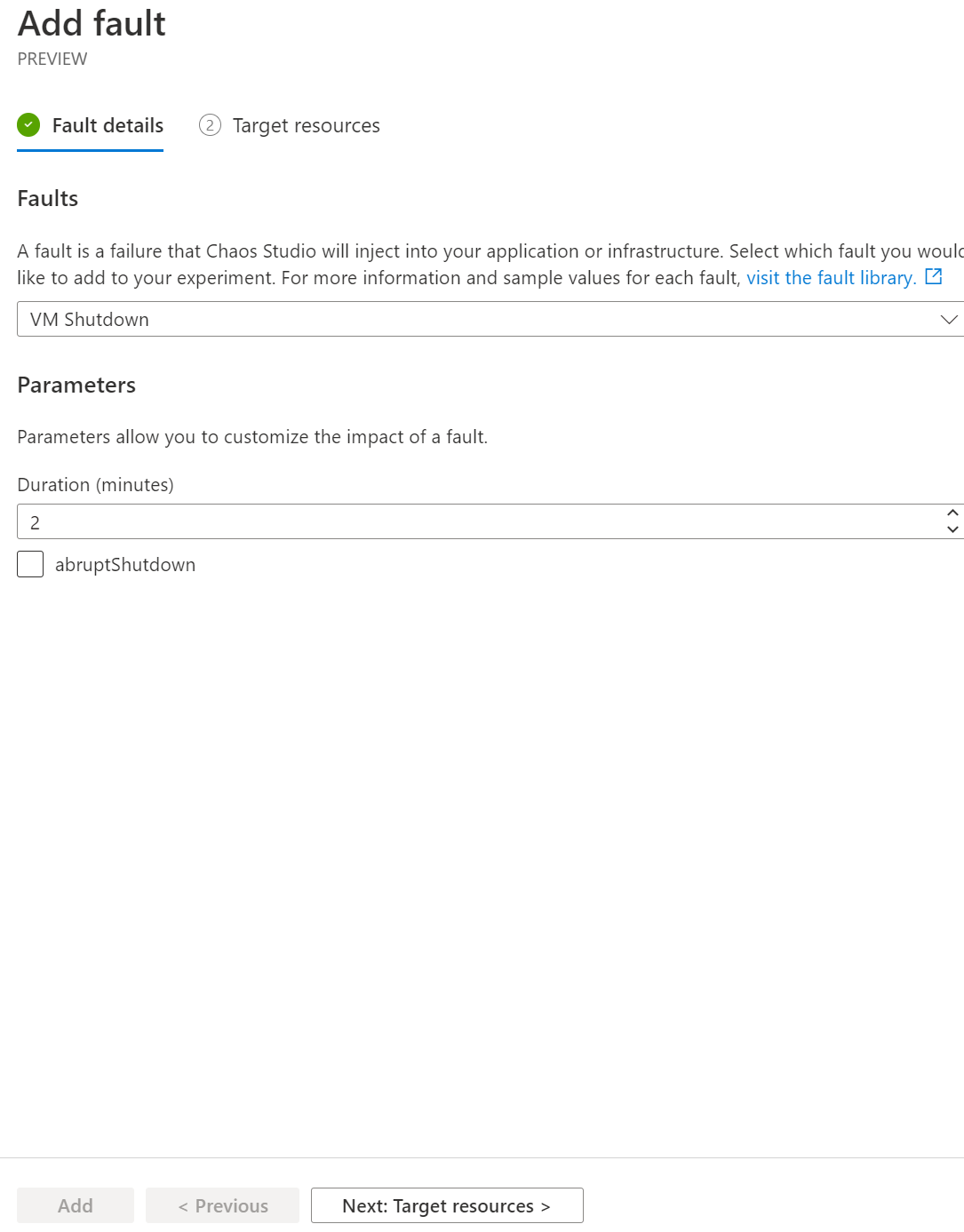

Pouštím experiment. A jejda, VMko jde dolu.
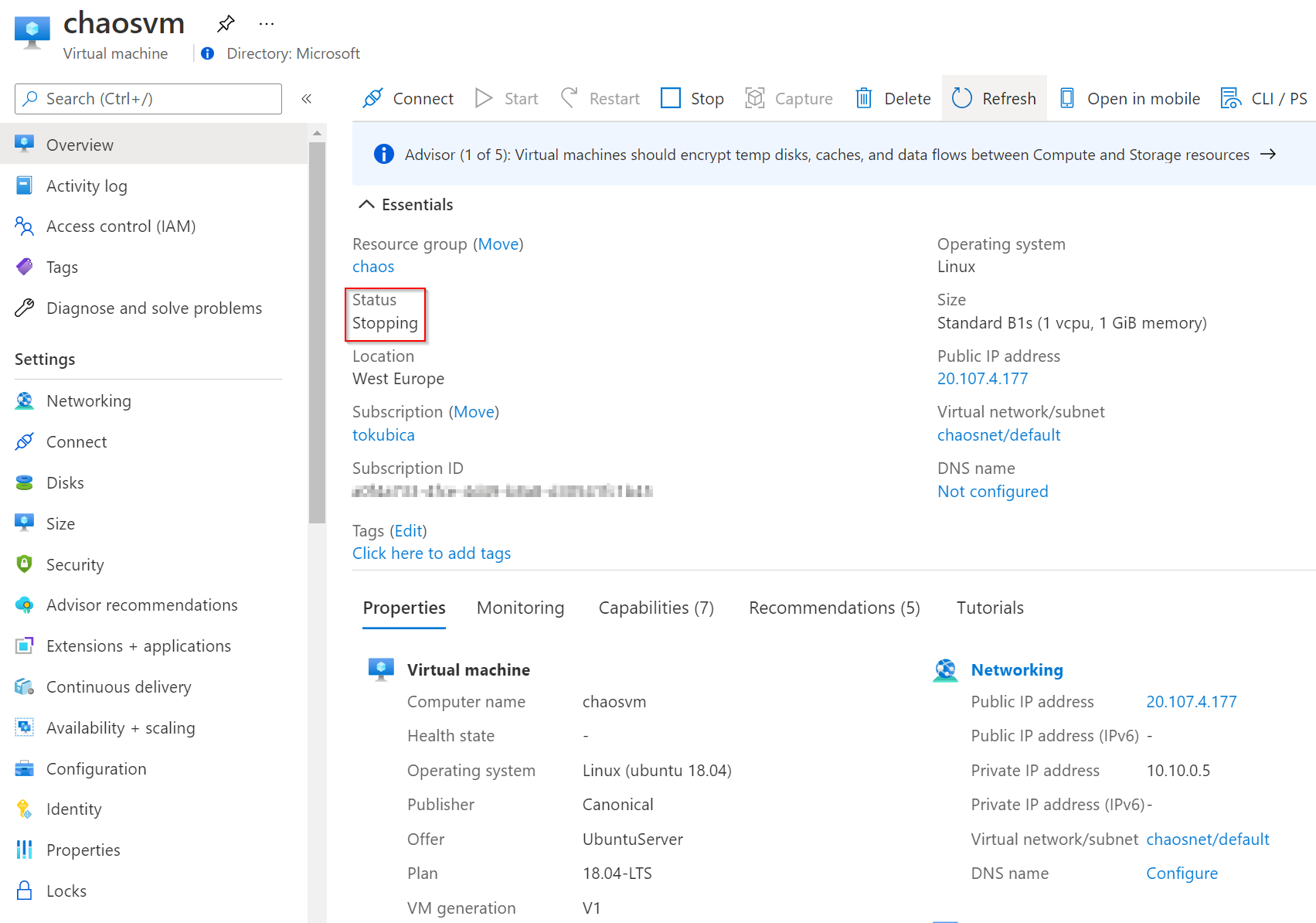
Po dvou minutách znovu startuje.
Záškodnictví přímo ve VM
Dalším typem generování chaosu je využití agenta ve VM, který na základě příkazů z Chaos Studio bude provádět patřičné akce. Tady se podpora různí podle OS - ve Windows například umí simulovat i síťovou latenci, v Linux zatím ne. Já použiji přetížení procesoru a aby to fungovalo, musím dle dokumentace mít v mašině balíček stress-ng. To jsem udělal, pojďme na to.
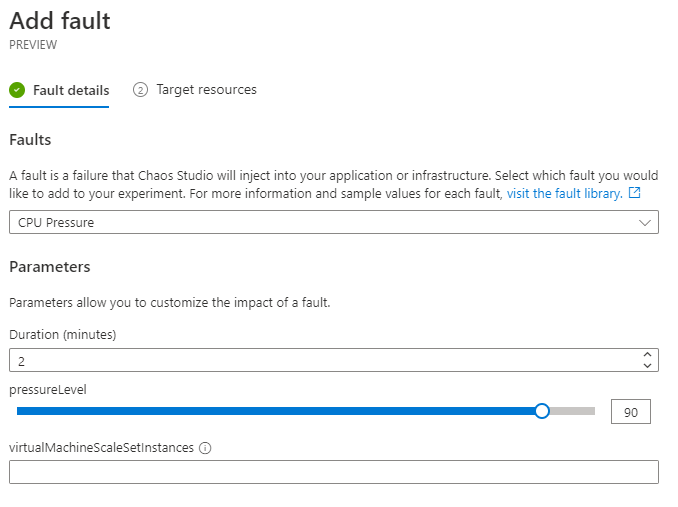
Spustím experiment a skutečně ve stroji pozoruji stress-ng proces a velkou zátěž CPU.
top - 18:39:45 up 3 min, 1 user, load average: 1.31, 0.97, 0.43
Tasks: 134 total, 2 running, 67 sleeping, 1 stopped, 0 zombie
%Cpu(s): 90.7 us, 0.3 sy, 0.0 ni, 8.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 939060 total, 202568 free, 281788 used, 454704 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 498828 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
16186 root 20 0 89256 8324 4024 R 90.7 0.9 0:57.05 stress-ng-cpu
1459 root 20 0 2954316 56760 22960 S 0.3 6.0 0:01.87 AzureChaosAgent
1489 root 20 0 186888 6272 4624 S 0.3 0.7 0:00.26 omiagent
2097 omsagent 20 0 265504 42516 8424 S 0.3 4.5 0:00.50 omsagent-26e203
17211 tomas 20 0 44548 4048 3420 R 0.3 0.4 0:00.04 top
Zkusíme teď něco ve Windows a nejvíc mě láká zpomalit některé síťové requesty. Stažení stránky ipconfig.io mi vychází na nějakých 263 milisekund.
PS C:\Users\tomas> measure-command {invoke-webrequest http://ipconfig.io}
Days : 0
Hours : 0
Minutes : 0
Seconds : 0
Milliseconds : 263
Ticks : 2630618
TotalDays : 3.04469675925926E-06
TotalHours : 7.30727222222222E-05
TotalMinutes : 0.00438436333333333
TotalSeconds : 0.2630618
TotalMilliseconds : 263.0618
Pojďme teď po dobu pěti minut zavařit všem destinacím na portu 80 navýšením latence o jednu vteřinu.
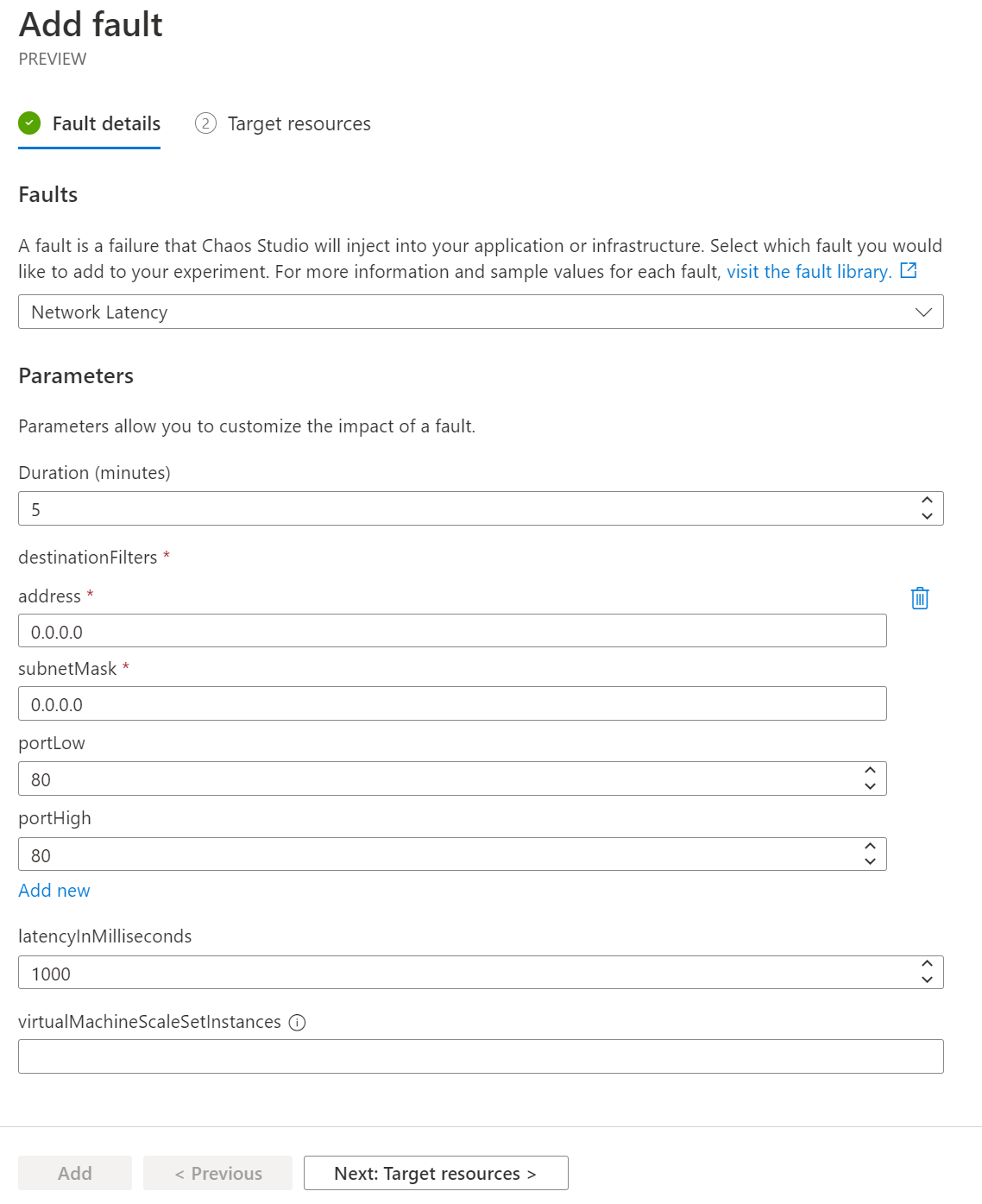

Spustíme experiment a ejhle - už request netrvá čtvrt vteřiny, ale vteřinu a čtvrt, jak jsme čekali.
PS C:\Users\tomas> measure-command {invoke-webrequest http://ipconfig.io}
Days : 0
Hours : 0
Minutes : 0
Seconds : 1
Milliseconds : 249
Ticks : 12492932
TotalDays : 1.4459412037037E-05
TotalHours : 0.000347025888888889
TotalMinutes : 0.0208215533333333
TotalSeconds : 1.2492932
TotalMilliseconds : 1249.2932
Tohle se myslím opravdu hodí - jak se moje aplikace začne chovat, když se najednou přístupy do databáze zpomalí? Nestane se náhodou, že řetězcem událostí tahle komponenta začne být pomalá, jiná kvůli tomu taky, následně se na nějaké třetí začnou hromadit nevyřízené požadavky až ta to neustojí a odumře?
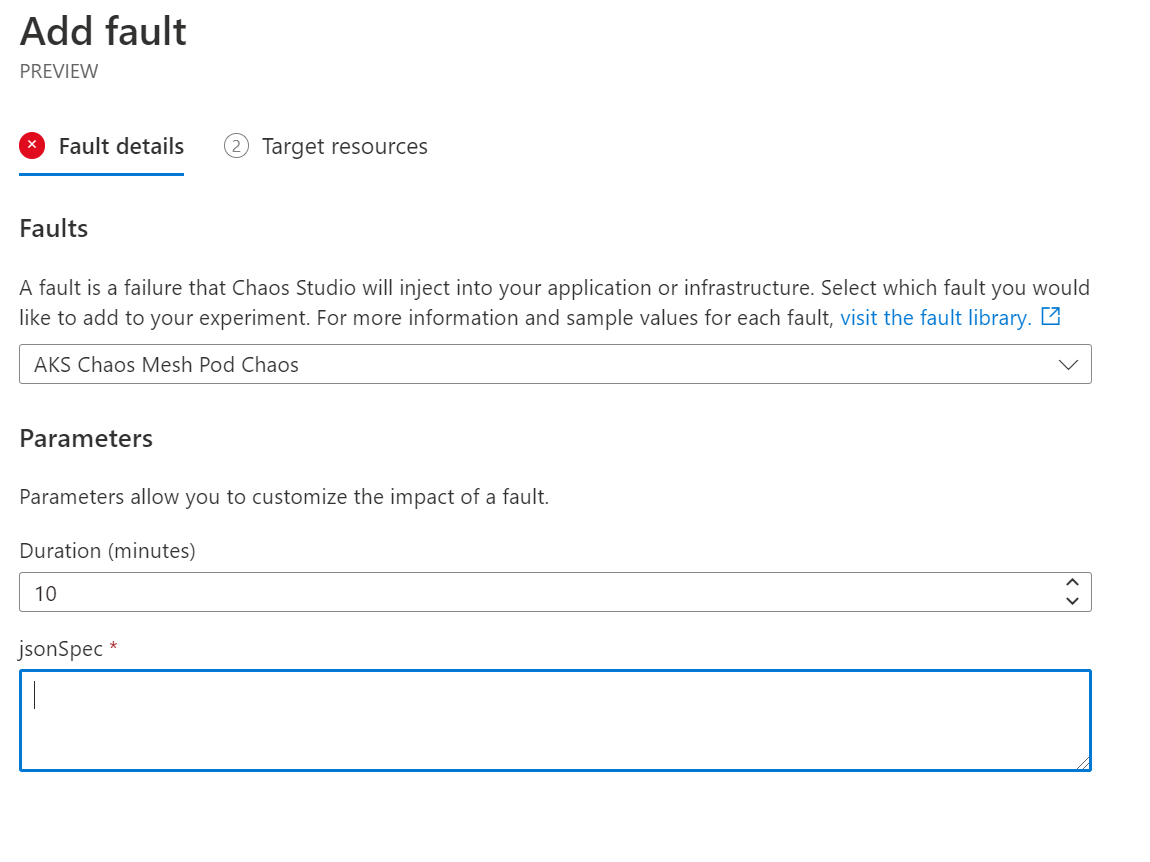
Kouzla v Kubernetes s Chaos Mesh
Azure Chaos Studio dokáže ovládat Chaos Mesh projekt v Kubernetes, o kterém jsem psal v samostatném článku
Jednoduše přidáte další krok a Chaos Mesh parametry mu předáte.
Za mě je Azure Chaos Studio výborné a slibuji si hodně i od dalšího rozvoje, zejména v oblasti monitoringu. Zajímá mě i integrace do CI/CD s GitHub Actions … to zkusím jetě prozkoumat.