Monitoring vašeho Kubernetes prostředí a aplikací v něm je velikánské téma. Dnes bych se chtěl věnovat úvodu a promyslet si co vlastně chci monitorovat a jaké možnosti se mi nabízí. Neberte to jako výčet všech možností, kterých je obrovské množství, ale spíš těch, které mi osobně dávají největší smysl z pohledu Azure architekta. Nicméně budu se zamýšlet i nad clustery běžícími mimo Azure a jak je do něj pro monitoring můžete napojit. Z druhé strany také kouknu na open source prostředky, kterými může dávat smysl obohatit nativní nástroje standardního prostředí Azure Kubernetes Service. Zkrátka dneska se budeme zamýšlet a od příště “klikat” (nebo spíš yamlovat).
Kde má monitoring žít
Někomu to připadá jako zbytečná otázka, ale já ji považuji za dost zásadní. Často vídám nasazení monitorovacího systému přímo uvnitř clusteru a ptám se pak, kde máte černou skříňku? Kde najdete všechno potřebné, abyste přišli na příčinu katastrofálního rozpadu vašeho clusteru?
Také stále ještě, a to zejména v on-premises, vídám snahu vybudovat si jeden megacluster pro všechny a pro všechno. To nevnímám jako z mnoha pohledů ideální. Musíte se dobře naučit řídit zdroje - NodeAffinitu, PodAffinitu, Pod priority, Tainty, resource/limits, namespaces. Pokud s Kubernetes začínáte, budete mít co dělat s tím ostatním natož se pak pouštět do pokročilé práce se schedulerem. Navíc cluster typicky izoluje kontejnery jen v Kernelu (pokud nepoužíváte ClearContainers nebo neřeší oddelení navíc gVisorem) a to je rozhodně méně, než VT-X instrukce procesoru (VM izolace), takže nepovažuji za skvělý nápad mít na jednom clusteru vaši nejtajnější aplikaci hned vedle vašeho veřejného webíku. Upgrade clusteru může představovat riziko - malé, kdy to provás v cloudu někdo dělá, velké, když si stavíte sami a nevíte dokonale co děláte. Určitě bych chtěl oddělit clustery pro prostředí pro zjednodušení RBAC a práce se zdroji - jasně, uděláte to i na jednom, ale komplexita dramaticky vzroste a pravděpodobnost chyby (= provozního nebo bezpečnostního průšvihu) výrazně roste. Zkrátka - v cloudu je pro vás cluster nahoře za 10 minut, takže je lepší pravidelně nahazovat a shazovat nové místo oprašování jednoho clusteru. Mimochodem všimněte si ten paradox některých on-premises instalací - používáte Kubernetes, abyste získali agilitu a schopnost mít všechno automatizované a farmářské (pet vs. cattle) a nakonec je Kubernetes tou sněhovou vločkou, kolem které se musí chodit potichu, protože to nějak funguje, ale raději se na to nesmí moc šahat, protože by mohlo přestat. Uf, ale proč o tom mluvím - pokud máte několik clusterů a v každém separátní monitoring a vytváříte/mažete je, jak zajistit historická data? Monitoring aby se rozsvítilo něco červeně, když je něco dole je fajn. Nicméně to nevede k tomu, aby to svítilo červeně co nejméně. Historický pohled, dlouhodobá analýza a neustálé zlepšování - to vede ke snížení červených situací. To já základ Site Reliability Engineeringu.
Je výhodné dostat monitoring do co nejmenšího počtu míst, aby bylo možné provádět analýzu a korelace jak logů tak telemetrie. Ideální je něco, kam se dají jednoduše dostat vstupy ze všeho - z různých cloudů i z on-premises, z Kubernetu, ale hlavně i dalších služeb typu databáze apod. a to zejména ty spravované v cloudu (PaaS).
Z těchto důvodů jsem zastánce následujícího:
- Monitorovací systém je samostatný a oddělený od provozního prostředí (není uvnitř clusteru)
- Používá push model (agenty) a běží v cloudu, jde tak na něj napojit jakýkoli zdroj a všechno je outbound 443 (neotvírá se nic do systémů samotných)
- Je vysoce dostupný a nemusím se o něj starat
- Všechna data a to jak logy tak telemetrii z infra, clusteru, aplikace i databáze jsou na místě a lze dělat mezi nimi query a joiny
- Nabízí flexibilní metodu vizualizace dat
- Nabízí jazyk pro ad-hoc query - aktivní vyhledávání
- Má zabezpečení s RBAC k datům - nejen, že je přístup ověřovaný, ale je minimálně per-cluster kontrola z kterých systémů kdo co smí vidět, takže někdo má data jen z jednoho clusteru, ale centrální tým vidí všechny a stále může dělat korelační query mezi nimi
- Nad daty může podle různých pravidel včetně třeba analýzy časové řady (detekce anomálie) spouštět akce - email, SMS, zpráva do Teams nebo Slack apod.
Tohle perfektně splňuje Azure Monitor - pokud máte cokoli společného s Azure, velmi doporučuji jít touhle cestou. Neznamená to, že ji nemůžete nebo nechcete ošperkovat open source nástroji okolo, k tomu se dostanu. Azure Monitor funguje pro clustery běžící kdekoli.
Co monitorovat
Při zamýšlení se nad monitoringem je myslím dobré kategorizovat co vlastně chceme sbírat.
Telemetrie clusteru a kontejnerů
Prvním aspektem je telemetrie samotného clusteru. Jsem přesvědčen, že pokud to chcete hlavně z důvodu červenání přetíženého clusteru pro účely vyběhnutí podpory s přídavným diskem přes chodbu, máte špatný cluster nebo jiné nastavení. Zkrátka očekávám, že většina těchto věcí se řeší samo - HPA a KEDA uvnitř, cluster autoscaler a tak podobně. Nicméně ne vždy všechno zafunguje nebo je správně nastaveno, takže tato kategorie je hodně důležitá:
- Kapacitní plánování a optimalizace - chci vědět svou dlouhodobu zátěž a potřeby, korelovat je s potřebami byznysu, hledat neoptimálně využité zdroje
- Zblázněné komponenty - chyba vývojáře může vyžrat zdroje, chci vědět co se jak chová a to zejména v historickém kontextu aneb proč po upgrade mikroslužby productCatalog tato najdenou potřebuje daleko víc zdrojů? V clusteru samotném se taky může něco rozbít, třeba se zblázní service mesh nebo tak něco.
- Škálování a jeho korelace s aplikační telemetrií (viz dále) - mám scaling nastaven na správnou metriku a se správnou agresivitou?
Nad to pak patří governance, politiky a další věci, které nepovažuji za monitoring v kontextu dnešního článku, ale jsou také velmi zásadní (na Azure Arc for Kubernetes a Azure Policy s využitím Gatekeeper v3 se podíváme jindy).
Tady jednoznačně doporučuji Azure Monitor for Containers. Ten funguje jak pro Azure Kubernetes Service, tak pro libovolný Kubernetes (nebo OpenShift) cluster běžící kdekoli. Součástí je nejen sběr, ale i myslím velmi zdařilá vizualizace.
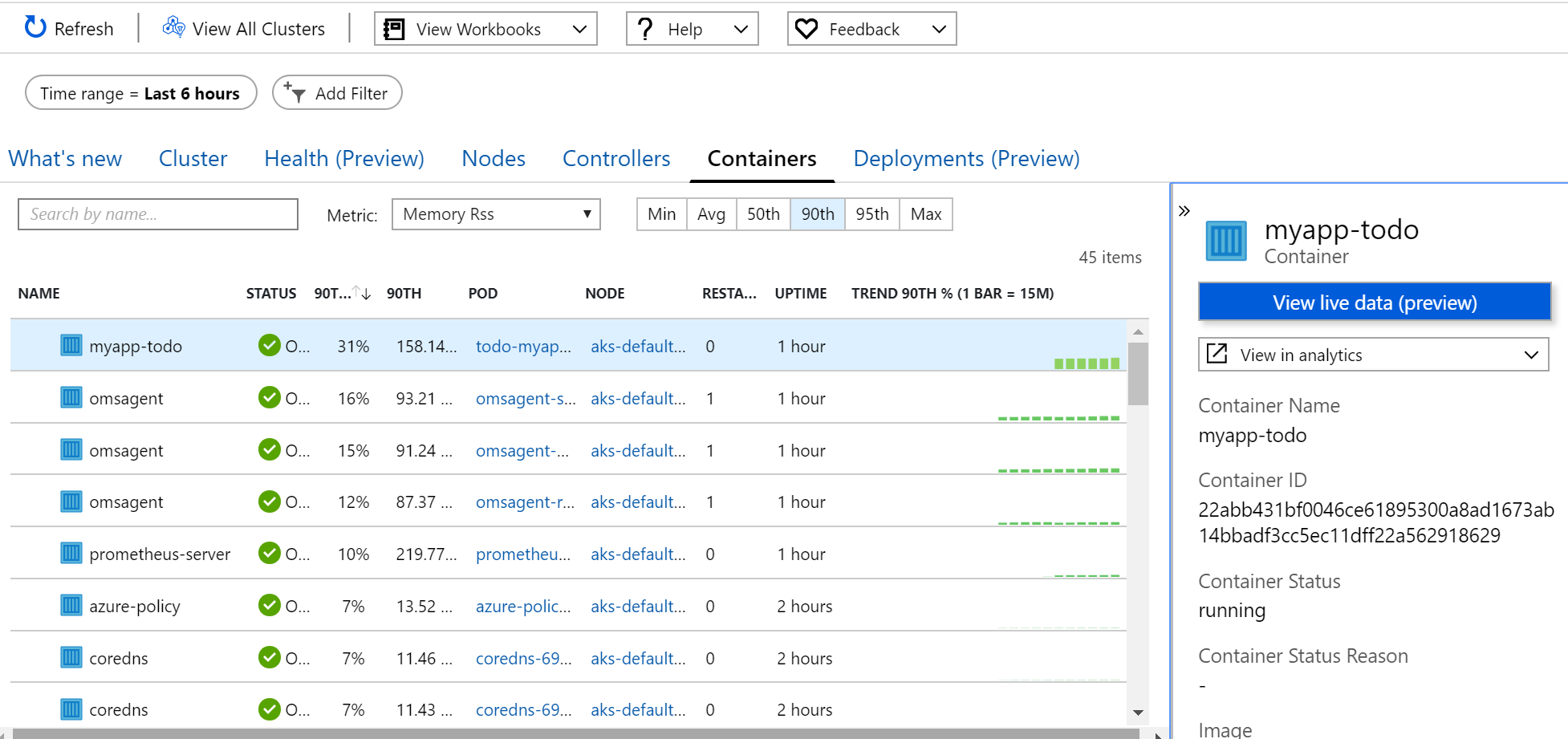
Nicméně můžete mít důvody pro vizualizaci v Grafana. Například už tam máte jiné dashboardy a dává smysl to ukazovat v jednom systému nebo chcete obejít RBAC model Azure (například ukázat i lidem bez loginu do Azure - ale opatrně s tím, RBAC v Azure Monitor je jedna z primárních výhod pro enterprise svět, ale u dashboardu na stěnu chápu, že bez toho to neudělám). Azure Monitor má připravený kontektor pro Grafana a je tam i hotový dashboard.
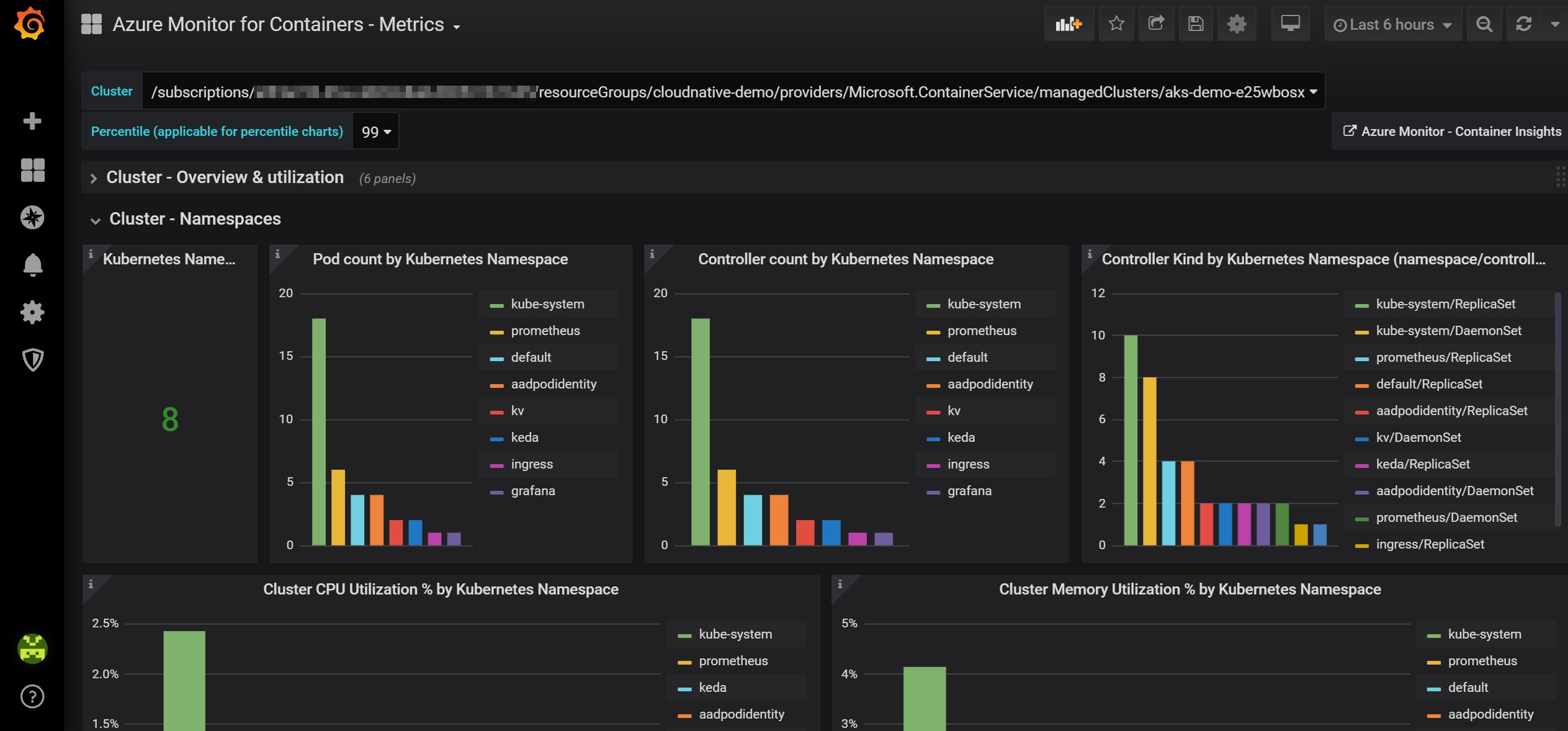
Logy z control plane clusteru
Sbírat operační log typu Pod nastartoval, nenastartoval, user X upravil deployment apod. je určitě vhodné pro bezpečnost (potažmo třeba až do Azure Sentinel - do SIEMu), ale i provoz. Určitě je dobré mít schopnost koukat se na kontejnery s častými restarty, kontejnery v nějaké crash smyčce a na základě nějakých pravidel reagovat alertem - například spuštěním nějakého workflow, informace do Teams/Slack, do emailu apod.
Azure Monitor for Containers tohle splňuje, doporučuji použít. Logy se hledají Kusto jazykem a vizualizaci můžete provádět s custom Workbooks v Azure Monitor.
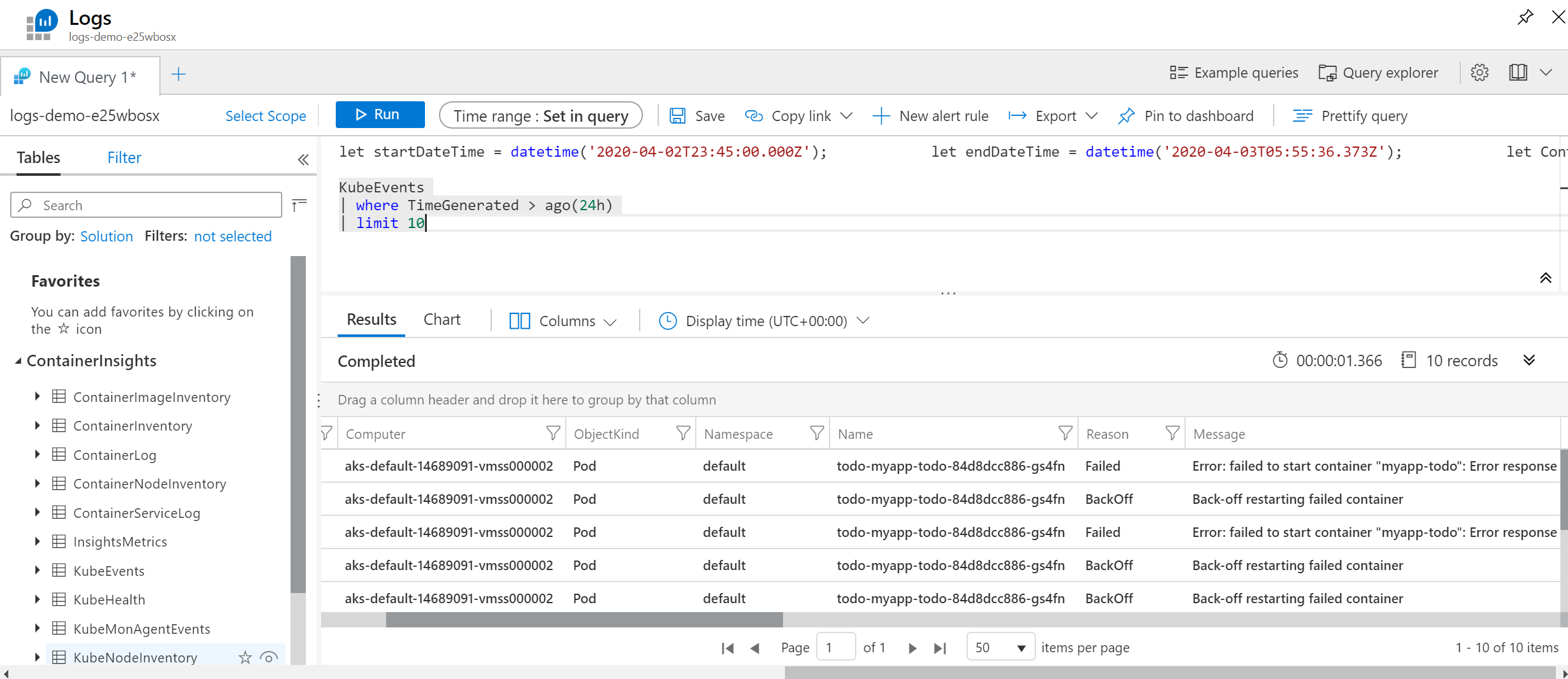
Opět platí, že tohle funguje pro Kubernetes kdekoli - můžete agenta nainstalovat do svého clusteru v jiném cloudu či on-premises.
Komukační telemetrie aplikací
Po čem toužíme z pohledu pochopení komunikace mezi komponentami? Já po tomhle:
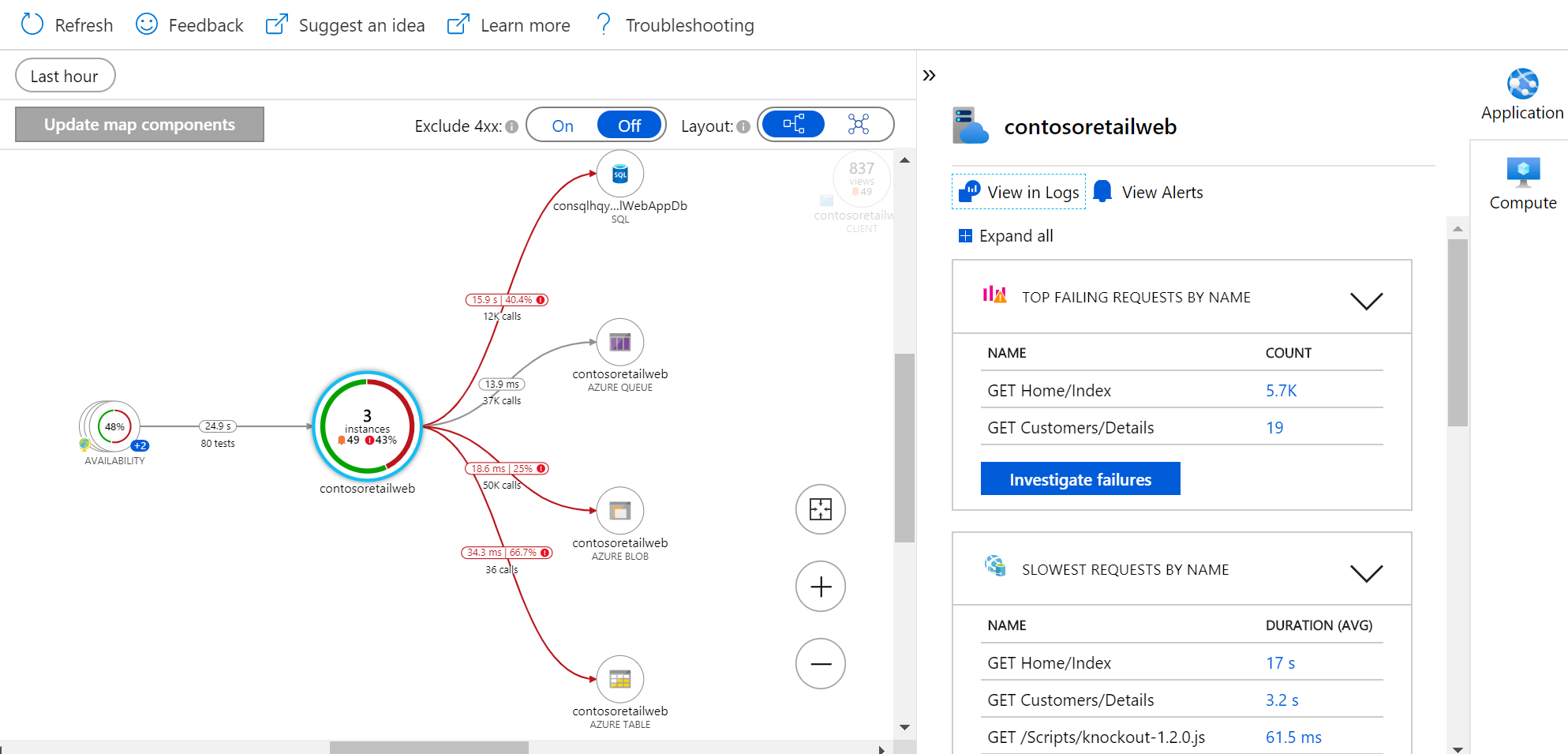
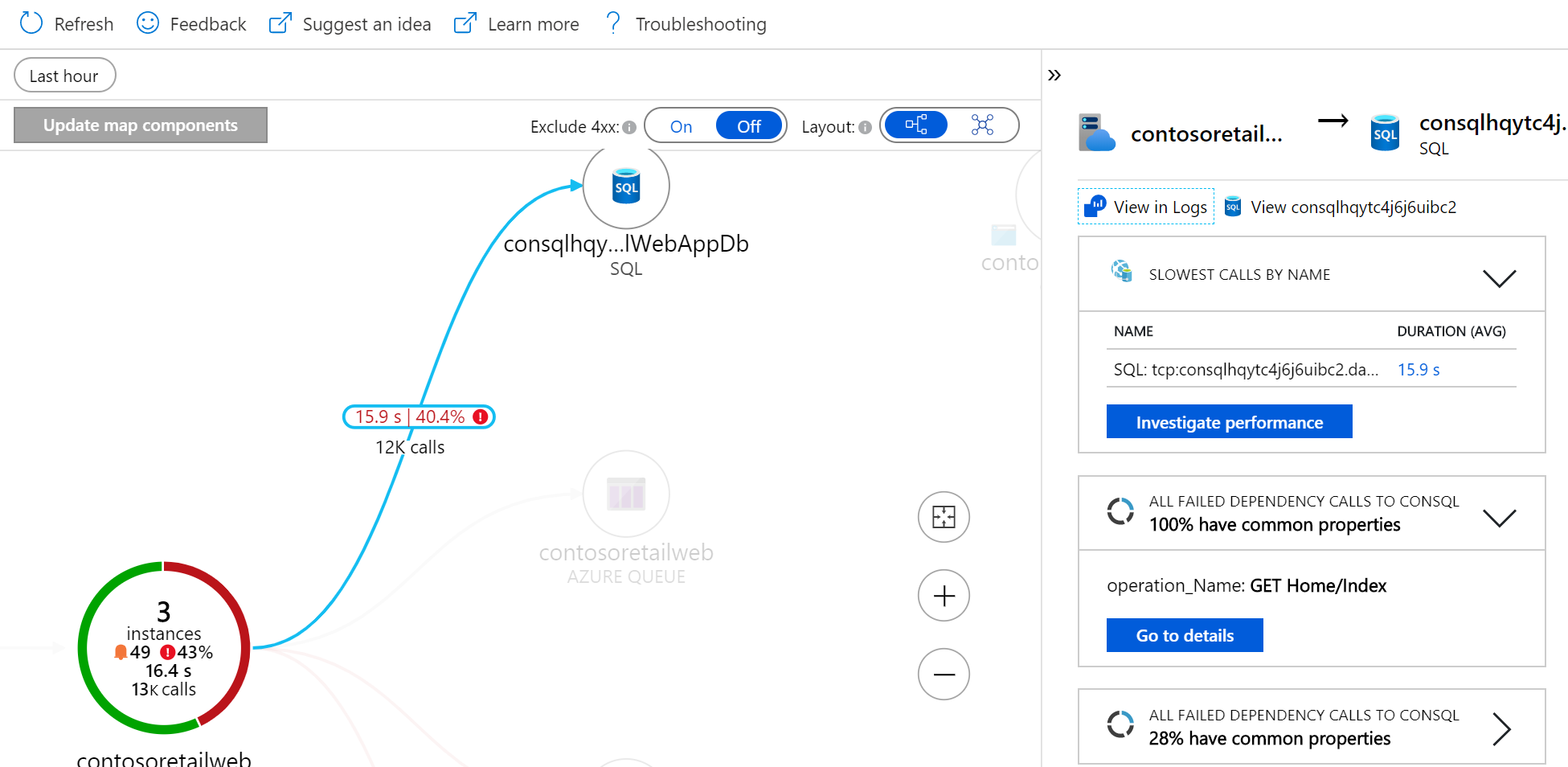
To jsou infomace z Azure Monitor Application Insights, tedy jsou v nich nejen komunikační data, ale i kompletní aplikační telemetrie. Opět koncept agenta, který je v tomto případě reprezentován SDK. To přilinkuje do své aplikace a monitoring se tak stane defacto součástí kódu a můžete aplikaci rozsvítit doslova kdekoli. A to včetně kódu, který běží v browseru nebo v mobilu, což u jiných řešení postavených na backend sbírání mimo aplikaci samotnou nenajdete. Nevýhodou ale je, že potřebujete dostat SDK do kódu. Nicméně pracuje se na možnosti data získávat i bez úpravy kódu! Lze přenastavit podporované prostředí (Java, .NET, Node) tak, že posílá telemetrii - některé věci budou chybět (třeba konkrétní znění SQL dotazu), ale hodnota je velmi vysoká. V detailnějších dílech určitě tyto možnosti zkusíme.
Druhou variantou je odchytit komunikaci mezi komponentami mimo aplikaci samotnou na nějaké sidecar proxy a to je typicky role Service Mesh nebo DAPR. Istio i Linkerd umí telemetrii poskytovat a standardy typu OpenTelemetry a OpenCensus umožňují se konečně trochu sjednotit na formátu a následné vizualizaci (ideální třeba bude mít schopnost vizualizace v App Insights z dat získaných ze Service Mesh) a DAPR (aplikačně laděný framework pro distribuované aplikace) také umí telemetrii sbírat (a to i pro asynchronní operace - něco co Service Mesh nezachytí tak dobře). V příštích dílech se podíváme na podrobnosti - takhle třeba vypadá vizualizace v Kiali:
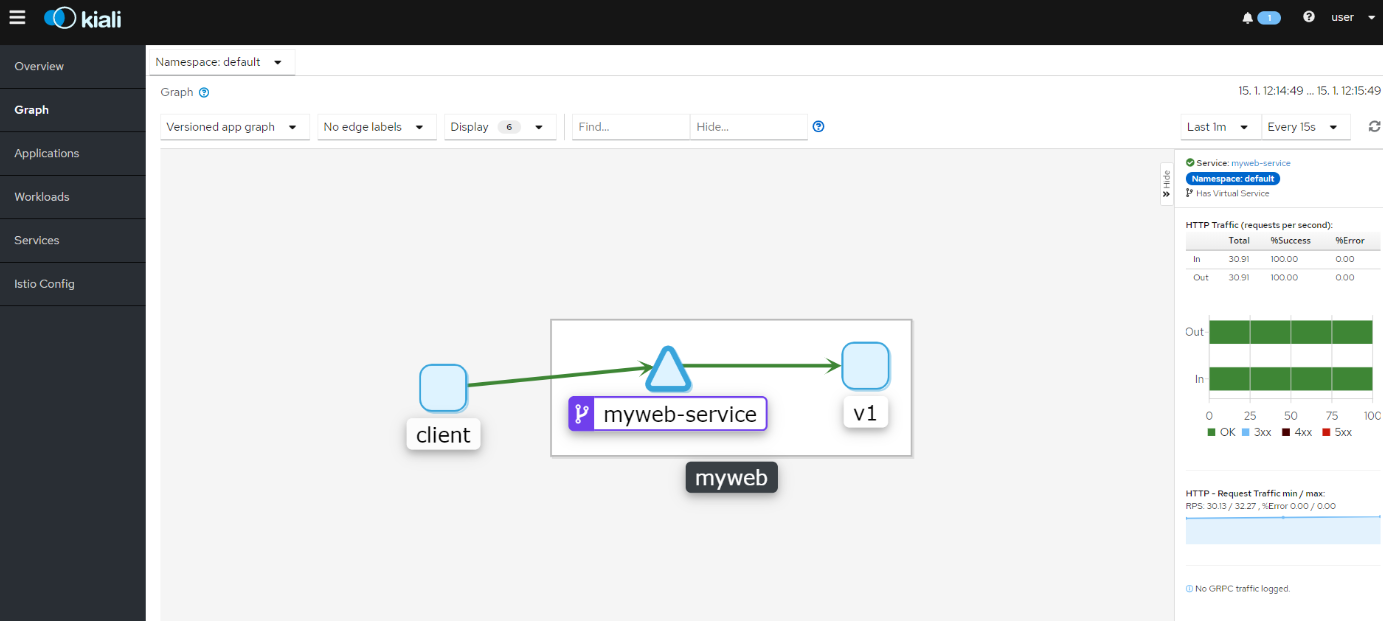
V této oblasti moje doporučení zní, pokud to jde, použijte Application Insights. Díky připravované podpoře nasazení bez změny kódu se okruh využitelnosti určitě ještě zvětší. Pokud jdete do DAPR, proč toho nevyužít i pro získání těchto dat. Důvody pro Service Mesh jsou komplexní a jen kvůli telemetrii bych to nedělal, ale pokud už máte, určitě jsou ta data velmi užitečná ať už je vizualizujete v Kiali nebo je přes otevřené standardy doženete do Application Insights.
Aplikační telemetrie
Jak se daří aplikaci? Kolik uživatelů odbavila, kolik lidí je online, jak dlouhá je fronta požadavků, jaké je průměrná odezva, jak dlouho typicky trvá získat data ze SAPu? Pokud na něčem stavět korelaci s byznys daty, modelovat SLA a uživatelskou zkušenost nebo dělat chytrý scaling, tak tohle jsou ty správná data. Jak je v Kubernetes získat?
Budu se opakovat - jakmile to jde, použijte Azure Monitor Application Insights. Získáte totiž nejen telemetrická data z backendu, ale totéž z mobilní aplikace nebo Javascriptového klienta. Znamená to ale upravit kód a je to specifické pro App Insights. Nevýhody? Nutnost přidat podporu do aplikace (ať už kódem nebo vstříknutím do podporovaného prostředí), takže nějaký kontejner stažený z webu to asi nemá. Další nevýhoda - na backendu musí být jen Application Insights (zatím - ale standardizace rychle pokračuje směrem k univerzálním klientům/SDK).
Hodně komponent má nativně podporu pro Prometheus a vaše aplikace ji mohou získat taky. Je široká nabídka různých konvertorů (jak dostat z proprietárního Apache2 řešení do Prometheus). Pokud hledáte co nejuniverzálnější export telemetrie, tak to je asi on. Navíc na data v Prometheu lze reagovat pro škálování velmi jednoduše a s minimálním zpožděním ať už z HPA nebo KEDA.
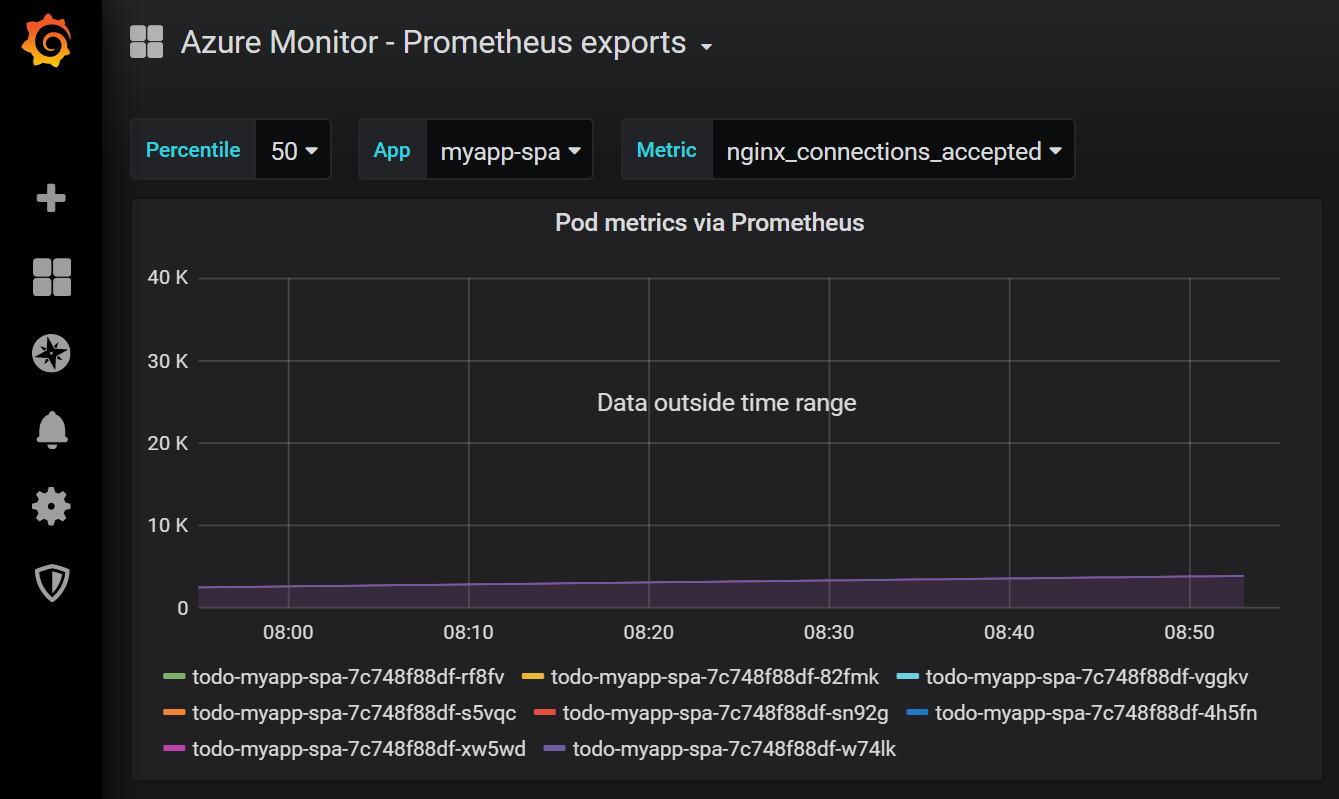
Ale starat se o Prometheus aby byl plně dostupný je hodně práce a znalostí. Nabízí se velmi zajímavé řešení - použít Azure Monitor pro sběr dat stylem Prometheus. Využijete defacto standard exportování telemetrie z vašich aplikací i těch třetích stran a přitom stále zůstává plně spravovaný vysoce dostupný backend enterprise kategorie. Azure Monitor agent prostě bude dělat to co Prometheus v clusteru a data sbírat, ale posílat do Azure Monitoru. Myslím výborné řešení. No a jak data v Azure Monitor budete vizualizovat už je zase na vás - Azure Monitor query či workbook nebo Grafana.
Aplikační logy
Velké téma. Vidím dvě zásadní varianty.
- Posíláte strukturované logy přímo z aplikace do cílového místa
- Zachytáváte logy v Kubernetes z stdout/stderr
Pro lidi od aplikací je jednoznačně lepší první varianta. Doporučuji, a omlouvám se, že to stále opakuji, Application Insights. Sbírají logy a ještě máte v jednom workspace všechno kolem aplikace včetně telemetrie a komunikačních událostí, frontend, mobil a tak podobně. Můžete ale také posílat logy do Azure Monitor Log Analytics Workspace, existují třeba pluginy pro log4j. Výhodou je vysoká strukturovanost logů.
Jenže v rámci provozu je lepší mít rychle k dispozici informace co se děje. Nejde mi o dlouhodobou analýzu nebo zkoumání zákoutí efektivity kódu, ale situace, kdy kontejner prostě nenabíhá nebo něco nefunguje, protože se nepodařilo správně předat secret. Tyto údaje je potřeba mít co nejrychleji dostupné a pokud možno bez velkého zpoždění. Chci použít Azure Monitor live view nebo kubectl logs a to bych řešil zapnutím sbírání stdout/stderr. Navíc tato data se dají jednoduše korelovat se situací v clusteru (je to vhodné na infrastrkturní zkoumání). Jenže data jsou méně strukturovaná a vaší noční můrou se stanou například víceřádkové výpisy (jedna zpráva obsahující znak konce řádku - to v Azure Monitor bude co řádek to zpráva a špatně se bude hledat pokud neuděláte chytřejší query).
Co bych tady doporučil?
Aplikační data sbírejte aplikačním způsobem a to do Applicaiton Insights. To je místo pro analýzu chování aplikace, dlouhodobé zkoumání chování a tak podobně. Polaďte si ovšem sbírání stdout/stderr.
- Pro aplikace napojené na Application Insights sbírejte do Azure Monitor pouze stderr. Hlášek nebude moc (cenově v pohodě) a umožníte přímo z portálu sledovat co se kde nepovedlo z infra pohledu (za kontejnery apod.). Tedy provozní tým kouká na infra a k tomu má aplikační chyby, nemusí se prohrabávat plným aplikačním logem v App Insights, který pro něj nemusí být důležitý.
- Pro aplikace nenapojené nebo nenapojitelné na Application Insights sbírejte stdout i stderr. Granularita nastavení Azure Monitor agenta je na úrovni namespace, nikoli per Pod, tak s tím počítejte.
- Pokud někde nechcete opravdu vůbec nic (například máte v jednom clusteru prostředí Dev s nulovým požadavekm na Azure Monitor a prostředí Test, kde už to chcete), udělejte na to speciální namespace a na něm řekněte Azure Monitor agentovi, ať nesbírá nic.
- V aplikaci posílejte na stdout rozumnou úroveň detailu. Nesbíral bych je do Azure Monitor (totéž mám přes aplikační logování), ale chci vidět v kubectl logs. Mějte ale oddělené nastavení podrobnosti mezi stdout a do App Insights. Jinak řečeno debug si chci třeba přes env zapínat nezávisle.
Tolik k zamýšlení a příště jdeme implementovat.