Než se pustíme do Istio, opět připomenu, že jsem nejprve psal o tom, proč Service Mesh ano, ale také proč ne. Nemyslím si, že je pro každého a jsou i jiné, v některých případech lepší, varianty. Také připomínám svůj hodně zjednodušený pohled na tři nejznámější zástupce:
- Istio, které je zaměřeno na maximální množství funkcí, umí toho strašně moc, ale znamená velký overhead, spotřebu zdrojů a zvýšenou latenci - trochu riskantní se může jevit, že to není oficiální CNCF projekt (může zavánět vendor tlačenou záležitostí)
- Linkerd, které je zaměřeno na maximální efektivitu a rychlost, nízkou zátěž, nízkou přidanou latenci, ale umí toho o dost méně - nicméně je to jediný z těchto tří, který je oficiálním CNCF projektem
- Consul Connect, který nejen marketingově, ale i prakticky dobře funguje v propojení Kubernetes a VM-based technologií, clusterů a service discovery přes všechny platformy a cloudy pro distribuované aplikace (pokud chcete jednu “síť nad všemi cloudy a onpremises od fyzických serverů po kontejnery, tohle může být řešení)
- Service Mesh Interface (SMI) není žádná implementace, jen vrstva abstrakce (API) přinášející společného jmenovatele pro potenciálně všechny implementace (něco jako Ingress pro L7 balancing, CNI pro síťové implementace apod.)
Dnes se vrhneme na ten funkčně nejbohatší - Istio. Protože už máme za sebou Linkerd, nebudu nutně opakovat všechny scénáře, které umí Istio taky, ale víc se zaměřím na speciality, které Istio posouvají před ostatní. Nezapomínejme ale na overhead v podobě spotřeby zdrojů a přidané latence - zkrátka jako vždy je tu něco za něco.
Všechny soubory použité v tomto článku najdete na mém GitHubu
Instalace a GUI
Istio je výrazně složitější, než Linkerd nebo Consul, ale pokud nechceme nic speciálního a všechno jde dobře, není instalace samotná nijak komplikovaná. Podobně jako u mnoha dalších nadstaveb Kubernetu si stáhneme speciální CLI (Linkerd, DAPR nebo Azure Functions na to jdou stejně).
cd ./istio
wget https://github.com/istio/istio/releases/download/1.4.3/istioctl-1.4.3-linux.tar.gz
tar -xvf istioctl-1.4.3-linux.tar.gz
sudo mv ./istioctl /usr/local/bin/
rm -rf istioctl-1.4.3-linux.tar.gz
Pro Istio si vytvořím namespace a pro instalaci GUI potřebujeme Secret s loginem. Pro zjednodušení použiji soubory ze svého GitHubu s loginem user/Azure12345678.
kubectl create namespace istio-system --save-config
kubectl apply -f grafanaSecret.yaml
kubectl apply -f kialiSecret.yaml
Istiu předhodíme konfigurační soubor. V něm říkám, že chci nasadit i GUI komponenty, že pro ně chci ověřování a prozatím nebudu vyžadovat mTLS mezi službami. Co je ale pro moje zkoušení také důležité je snížit výchozí nároky Istio na zdroje, jinak se mi do levného testovacího clusteru nevejde. Na produkci to nedělejte, Istio je skutečně známé tím, že potřebuje hodně.
apiVersion: install.istio.io/v1alpha2
kind: IstioControlPlane
spec:
# Use the default profile as the base
# More details at: https://istio.io/docs/setup/additional-setup/config-profiles/
profile: default
traffic_management:
components:
pilot:
k8s:
resources:
limits:
cpu: 800m
memory: 500Mi
requests:
cpu: 500m
memory: 250Mi
values:
global:
# Ensure that the Istio pods are only scheduled to run on Linux nodes
defaultNodeSelector:
beta.kubernetes.io/os: linux
# Enable mutual TLS for the control plane
controlPlaneSecurityEnabled: true
mtls:
# Require all service to service communication to have mtls
enabled: false
grafana:
# Enable Grafana deployment for analytics and monitoring dashboards
enabled: true
security:
# Enable authentication for Grafana
enabled: true
kiali:
# Enable the Kiali deployment for a service mesh observability dashboard
enabled: true
tracing:
# Enable the Jaeger deployment for tracing
enabled: true
Pošleme do clusteru.
istioctl manifest apply -f istioConfig.yaml
Istio si nahodí několik CRD a svoje komponenty ať už pro Istio samotné (Citadel, gateway, Pilot, Policy, Sidecar Injector, …) nebo volitelný monitoring a GUI (Prometheus, Grafana, Kiali).
$ kubectl get crd
NAME CREATED AT
adapters.config.istio.io 2020-01-14T19:18:25Z
attributemanifests.config.istio.io 2020-01-14T19:18:25Z
authorizationpolicies.security.istio.io 2020-01-14T19:18:25Z
clusterrbacconfigs.rbac.istio.io 2020-01-14T19:18:25Z
destinationrules.networking.istio.io 2020-01-14T19:18:26Z
envoyfilters.networking.istio.io 2020-01-14T19:18:26Z
gateways.networking.istio.io 2020-01-14T19:18:26Z
handlers.config.istio.io 2020-01-14T19:18:26Z
healthstates.azmon.container.insights 2020-01-14T19:00:59Z
httpapispecbindings.config.istio.io 2020-01-14T19:18:26Z
httpapispecs.config.istio.io 2020-01-14T19:18:26Z
instances.config.istio.io 2020-01-14T19:18:26Z
serviceentries.networking.istio.io 2020-01-14T19:18:27Z
servicerolebindings.rbac.istio.io 2020-01-14T19:18:27Z
serviceroles.rbac.istio.io 2020-01-14T19:18:27Z
sidecars.networking.istio.io 2020-01-14T19:18:27Z
templates.config.istio.io 2020-01-14T19:18:27Z
virtualservices.networking.istio.io 2020-01-14T19:18:28Z
$ kubectl get pods -n istio-system
NAME READY STATUS RESTARTS AGE
grafana-6bc97ff99-768pl 1/1 Running 0 12h
istio-citadel-655bcc5ff-zsv87 1/1 Running 0 12h
istio-galley-864c4dfb4f-fjrlt 2/2 Running 0 12h
istio-ingressgateway-7cd748f5d7-cpcbr 1/1 Running 0 12h
istio-pilot-5fd5cd748f-8vqxf 2/2 Running 0 12h
istio-policy-b8597df85-72jhz 2/2 Running 2 12h
istio-sidecar-injector-f6c874dd9-gdlzk 1/1 Running 0 12h
istio-telemetry-8676d96986-qf4g4 2/2 Running 2 12h
istio-tracing-557f5dcd8c-vs8cz 1/1 Running 0 12h
kiali-59b7fd7f68-p7tvf 1/1 Running 0 12h
prometheus-7c7cf9dbd6-d6w79 1/1 Running 0 12h
Ke GUI se můžeme protunelovat přes Istio CLI, například Kiali (GUI pro Istio), Grafana (vizualizace telemetrie), Jaeger (distribuovaný tracing), Prometheus (monitoring) nebo GUI jednotlivých Envoy proxy v sidecar.
istioctl dashboard grafana
istioctl dashboard prometheus
istioctl dashboard jaeger
istioctl dashboard kiali
istioctl dashboard envoy <pod-name>.<namespace>
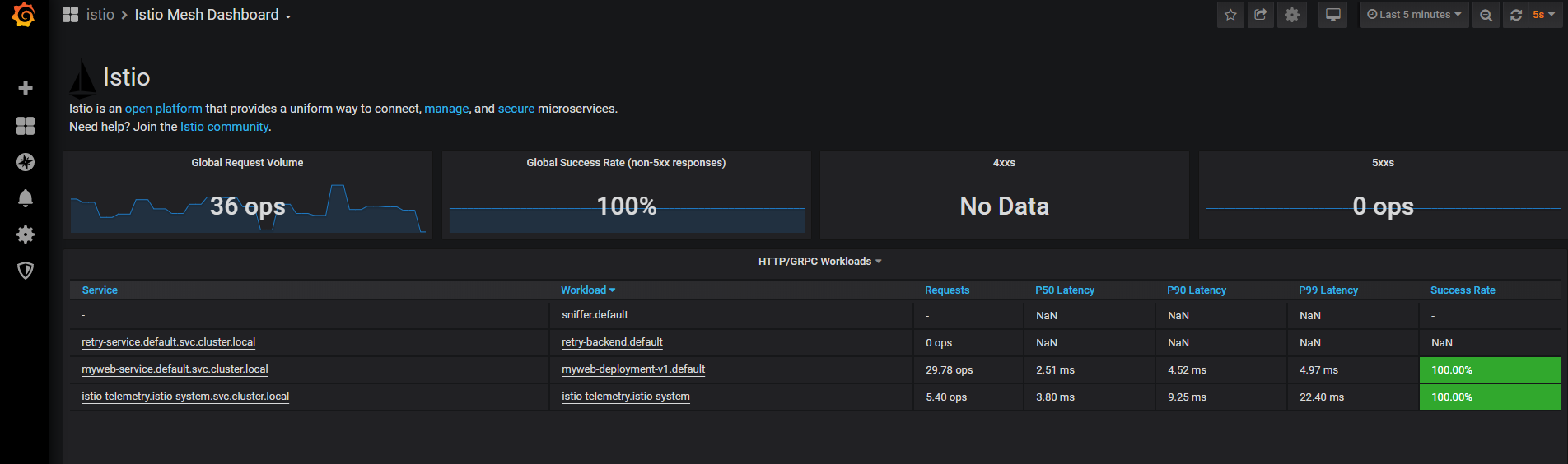
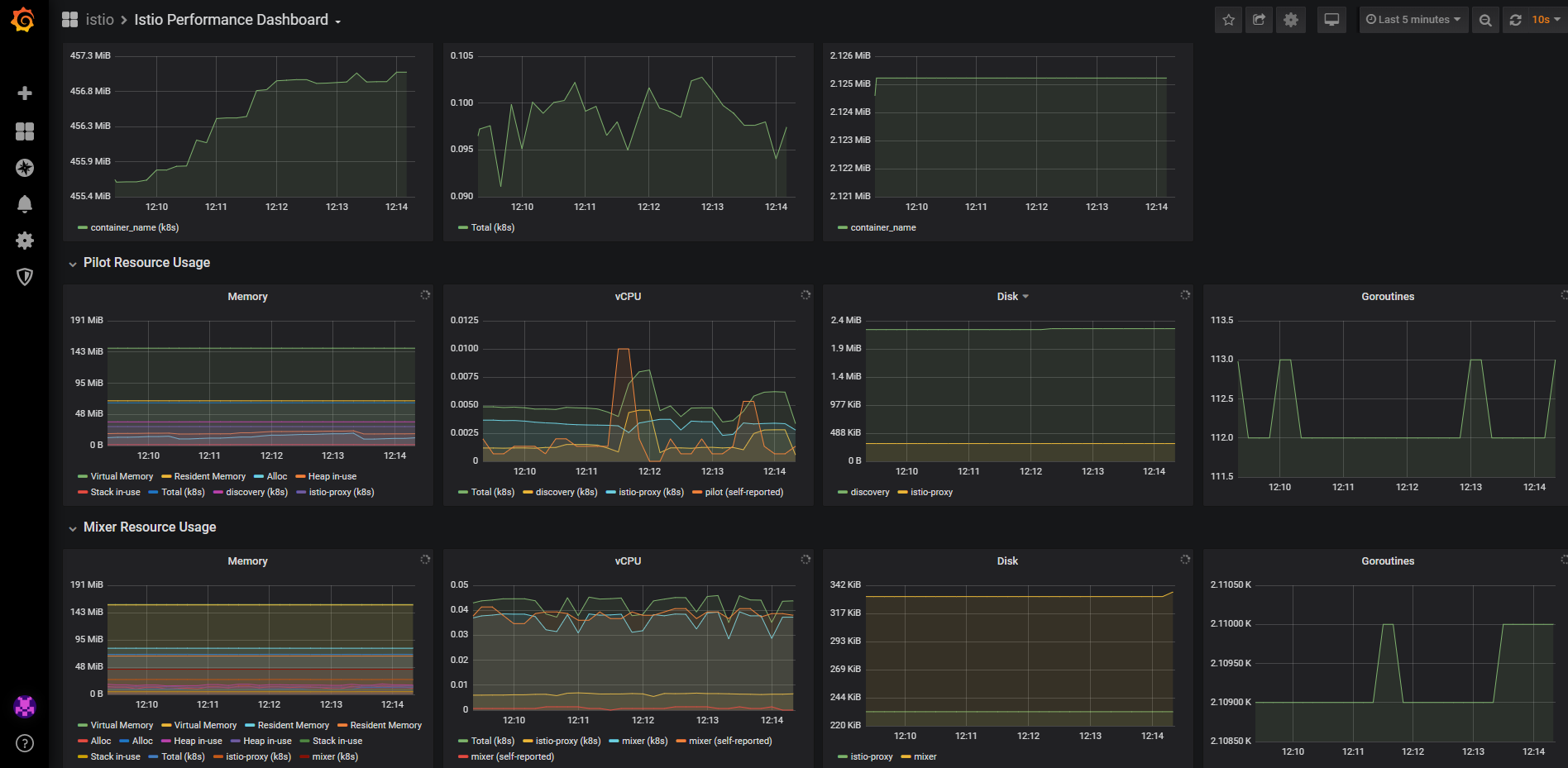
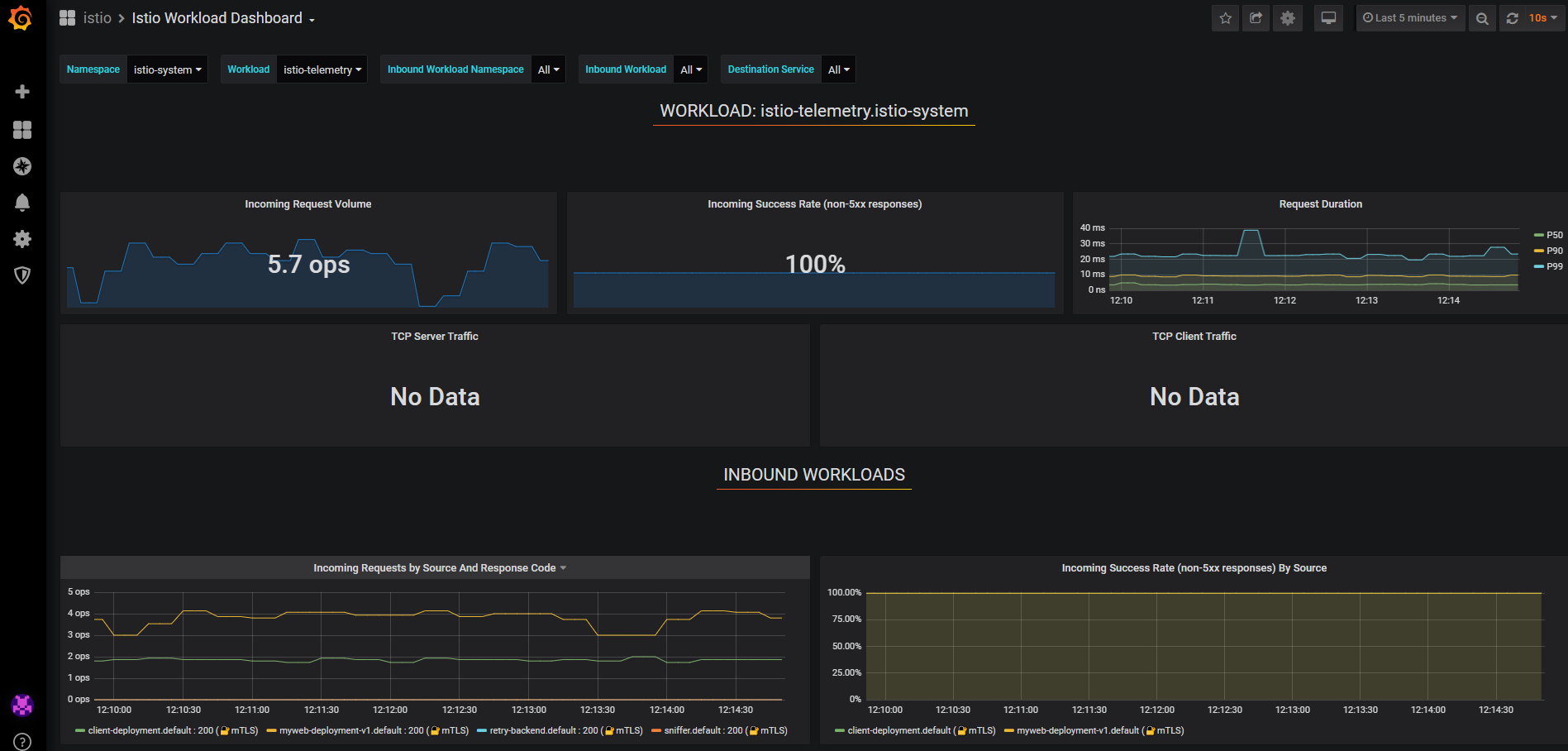
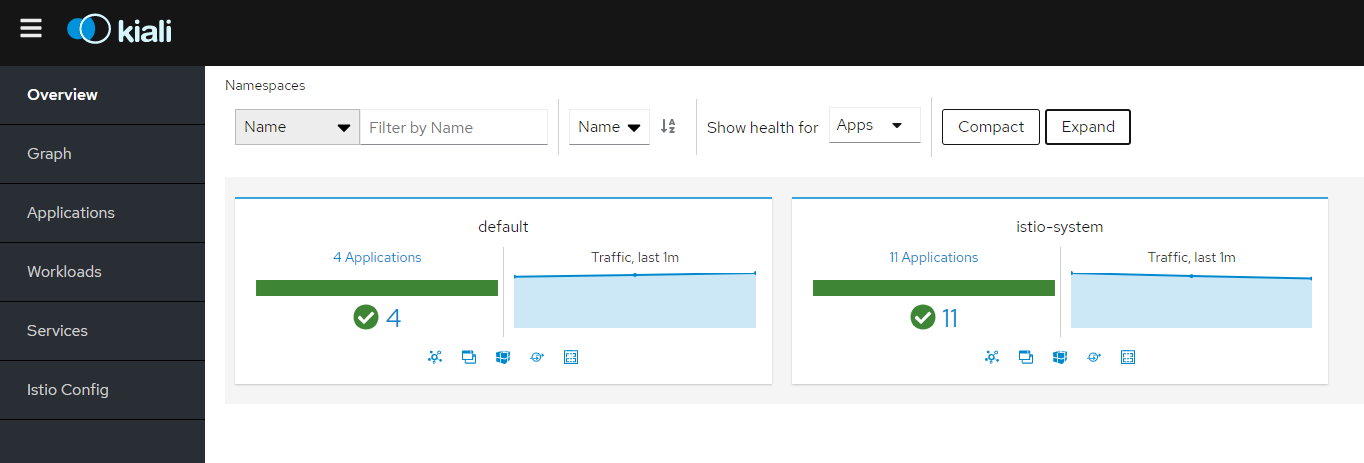
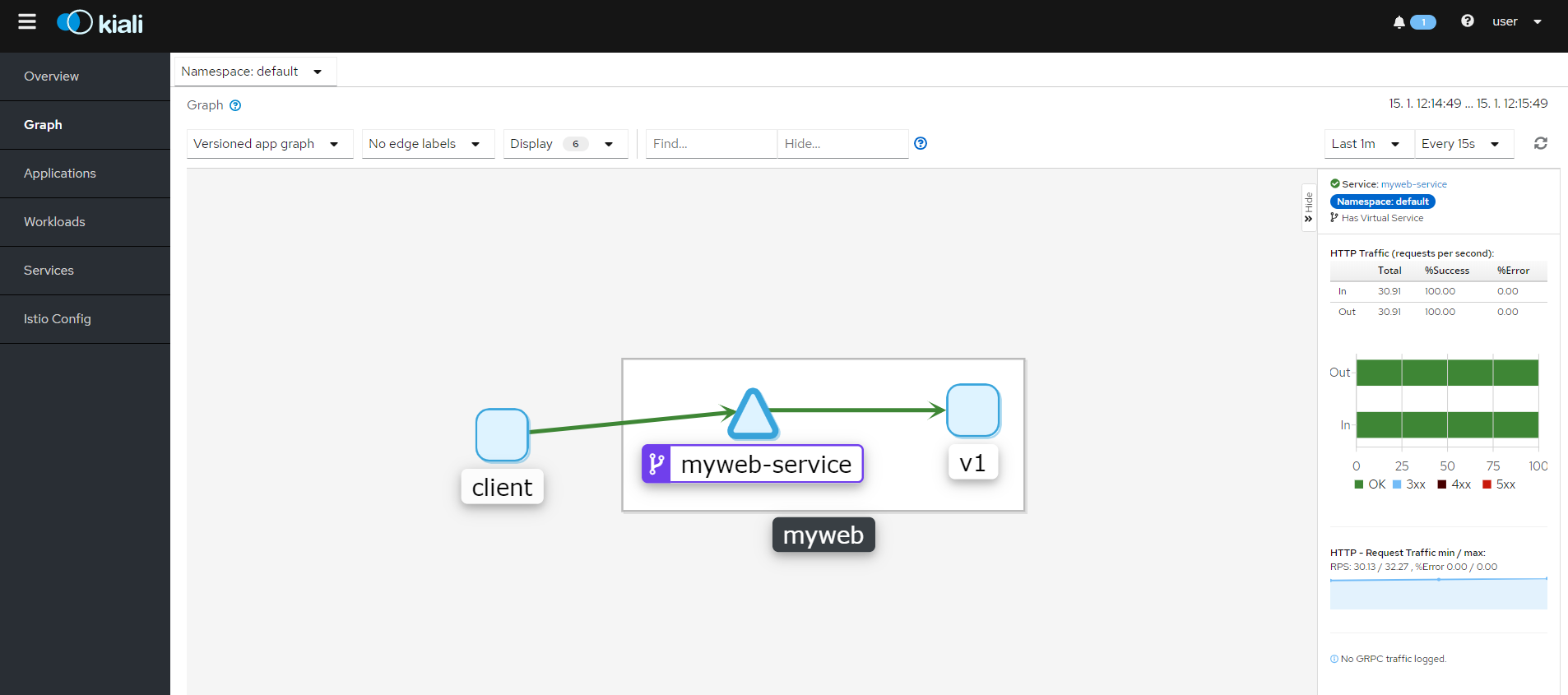
V rámci nastavení uděláme ještě jednu věc - zapneme si automatické vstřikování sidecar v namespace default (totéž můžete nastavovat i na úrovni jednotlivých objektů).
kubectl label namespace default istio-injection=enabled
Retry
Podobně jako u Linkerd nabízí Istio implementace retry logiky tak, že ji nemusíme dělat v aplikaci. Nasaďme si dvě služby - jednu client (z té to budeme zkoušet) a jednu jako backend.
kubectl apply -f client.yaml
kubectl apply -f retryBackend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 1
selector:
matchLabels:
app: client
template:
metadata:
labels:
app: client
spec:
containers:
- name: client
image: tkubica/mybox
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: retry-backend
spec:
replicas: 3
selector:
matchLabels:
app: retry
template:
metadata:
labels:
app: retry
spec:
containers:
- name: retry-backend
image: tkubica/retry-backend
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: retry-service
spec:
selector:
app: retry
ports:
- protocol: TCP
name: http
port: 80
targetPort: 80
Všimněte si, že po nasazení mám kromě hlavního kontejneru vytvořenu i sidecar s proxy. Stejně jako u Linkerd je nejdřív spuštěn privilegovanější Init kontejner, který připraví síťařinu tak, aby aplikace vůbec nepoznala, že komunikuje přes proxy (Istio má i CNI implementaci, která to řeší jinak).
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
client-deployment-7dcf76fc94-qzgk5 0/2 Pending 0 4s
retry-backend-8bc48b6fd-9vc79 0/2 Init:0/1 0 3s
retry-backend-8bc48b6fd-nsfhd 0/2 Init:0/1 0 3s
retry-backend-8bc48b6fd-sx74k 0/2 Pending 0 3s
kubectl get pod retry-backend-8bc48b6fd-9vc79 -o yaml
spec:
containers:
- image: tkubica/retry-backend
imagePullPolicy: Always
name: retry-backend
...
- name: istio-proxy
args:
...
env:
...
image: docker.io/istio/proxyv2:1.4.3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 15090
name: http-envoy-prom
protocol: TCP
resources:
limits:
cpu: "2"
memory: 1Gi
requests:
cpu: 100m
memory: 128Mi
securityContext:
readOnlyRootFilesystem: true
runAsUser: 1337
...
volumeMounts:
- mountPath: /etc/istio/proxy
name: istio-envoy
- mountPath: /etc/certs/
name: istio-certs
readOnly: true
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-x8q7k
readOnly: true
initContainers:
- command:
- istio-iptables
- -p
- "15001"
- -z
- "15006"
- -u
- "1337"
- -m
- REDIRECT
- -i
- '*'
- -x
- ""
- -b
- '*'
- -d
- "15020"
image: docker.io/istio/proxyv2:1.4.3
imagePullPolicy: IfNotPresent
name: istio-init
...
securityContext:
capabilities:
add:
- NET_ADMIN
runAsNonRoot: false
runAsUser: 0
Istio má výchozí retry politiku, ale já si ji raději rovnou trochu přizpůsobím.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: retry-vs
spec:
hosts:
- retry-service
http:
- route:
- destination:
host: retry-service
timeout: 15s
retries:
attempts: 15
perTryTimeout: 1s
retryOn: gateway-error,reset,5xx
kubectl apply -f retryVirtualService.yaml
Moje retry aplikace nechá Pod umřít (navíc s dvouvteřinovým zaseknutím) s pravděpodobností, kterou jí předáme.
export clientPod=$(kubectl get pods -l app=client -o jsonpath="{.items[0].metadata.name}")
kubectl exec $clientPod -c client -- curl -vs -m 30 "retry-service?failRate=50&mode=crash"
Někdy máme odpověď rychle, někdy trochu pomaleji. To je tím, že nám na pozadí jeden z Podů umřel a Istio to zkoušelo znova a znova, dokud nějaký z Podů neodpověděl. Všimněte si, že některé Pody byly restartovány.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
client-deployment-7dcf76fc94-qzgk5 2/2 Running 0 18m
retry-backend-8bc48b6fd-9vc79 2/2 Running 0 18m
retry-backend-8bc48b6fd-nsfhd 2/2 Running 1 18m
retry-backend-8bc48b6fd-sx74k 2/2 Running 1 18m
Uděláme ještě jeden pokus. Služba teď nebude končit brutální smrtí, ale v rámci dané pravděpodobnosti odpoví chybou 503. Zvýšíme chybovost na 90%, ale necháme fail v režimu vrácení 503 (místo crash). Pošleme request a v druhém okně sledujte logy ze všech retry-backend podů. Měli bychom vidět několik pokusů, než se konečně podaří Istiu dostat rozumnou odpověď.
$ kubectl exec $clientPod -c client -- curl -vs -m 30 "retry-service?failRate=90&mode=busy"
$ kubectl logs -l app=retry -c retry-backend -f
127.0.0.1 - - [15/Jan/2020:09:05:24] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:05:24] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:05:24] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:05:24] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:05:25] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:05:25] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:05:25] "GET /?failRate=90&mode=busy HTTP/1.1" 200 2 "" "curl/7.58.0"
Circuit breaker
Podívejme se na pokročilejší funkci, kterou jednodušší service mesh technologie často neumožňují. V předchozím případě máme službu, která má pravděpodobnost selhání 90% a to je hodně. Možná bychom mohli mít následující myšlenky:
- Pokud je celá služba v takovémto stavu, tak je tak nespolehlivá, že místo retry a točícího se kolečka pro uživatele bude možná lepší službu vyhlásit za mrtvou a tlačítko v GUI třeba nechat zašednout nebo alespoň bez čekání dát uživateli vědět, že máme nějaký problém.
- Pokud se nějaké instanci (Podu) začíná dělat špatně, možná je přetížená, protože má třeba smůlu a dostává náročné requesty. Jakmile začne vracet chyby, můžeme ji nechat se vzpamatovat a přestat jí třeba na pár minut posílat traffic. Jasně - něco podobného se dá získat přes readiness probe, ale pokud už se v Istiu stejnak hrabeme, tak proč toho nevyužít a získat větší kontrolu. Tak například Kubernetes readiness probe bude odebírat a odebírat až klidně vypne všechno a možná to není, co chcete. Co když jste ochotni odebírat kulhající Pody, ale pokud už jich je 30% mimo hru, tak ty ostatní raději necháte žít i kulhající, protože je pro vás lepší, když fungují špatně, než vůbec.
- Možná chcete výhybku přehodit v okamžiku, kdy nějaký Pod dostává hodně zabrat a má hodně aktivních spojení. Víte-li, že jakmile Pod dostane víc jak 10 requestů současně, půjde dolu a nedokončí práci, můžete Istiu říct, ať na něj v takovém případě už neposílá nic dalšího. Může se vám zdát, že tohle přece vyřeším autoškálováním přes Horizontal Pod Autoscaler, nebo ne? Ano, ale za předpokladu, že máte optimálně rozloženou zátěž a nedochází k tomu, že se 5 Podů fláká a 1 dostává strašně naložíno. Pokud máte nedostatečnou entropii v hlavičkách (málo IP adres, málo spojení protože jedete s HTTP/2 ala gRPC) tak se to bez service mesh klidně může stát.
Vyzkoušíme si následující. Nastavíme politiku, že pokud Pod selže dvakrát během 10 vteřin, přestaneme na něj po dobu jedné minuty posílat provoz. Je pro nás lepší řízená smrt služby, než kulhání, tak dovolíme Istio odebrat klidně Pody všechny a rovnou vracet 503 bez dalšího zkoušení. Takhle taková definice vypadá a pošleme ji do clusteru.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: retry-vs
spec:
hosts:
- retry-service
http:
- route:
- destination:
host: retry-service
timeout: 30s
retries:
attempts: 30
perTryTimeout: 1s
retryOn: gateway-error,reset,5xx
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: retry-service
spec:
host: retry-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
outlierDetection:
consecutiveErrors: 2
interval: 10s
baseEjectionTime: 1m
maxEjectionPercent: 100
kubectl apply -f circuitBreaker.yaml
V jednom okně si opět otevřeme logy ze všech backendů.
kubectl logs -l app=retry -c retry-backend -f
[15/Jan/2020:09:04:33] ENGINE Bus STARTED
127.0.0.1 - - [15/Jan/2020:09:05:24] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:21] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:21] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:21] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:21] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:22] "GET /?failRate=90&mode=busy HTTP/1.1" 200 2 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:27] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:27] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:27] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:27] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:27] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:21:27] "GET /?failRate=90&mode=busy HTTP/1.1" 200 2 "" "curl/7.58.0"
... tady nic není, pokusy končí na Istiu, obvod je rozpojen ....
... po minutě se přepínač vrátil do polohy otevřeno ....
127.0.0.1 - - [15/Jan/2020:09:23:06] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:23:06] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:23:06] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:23:06] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:23:06] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
127.0.0.1 - - [15/Jan/2020:09:23:06] "GET /?failRate=90&mode=busy HTTP/1.1" 503 1461 "" "curl/7.58.0"
Pošleme dvákrát či třikrát dotaz s 90% šancí neúspěchu.
kubectl exec $clientPod -c client -- curl -vs -m 30 "retry-service?failRate=90&mode=busy"
Co vidíme z předchozích logů? Nejdřív se doboucháme na odpověď 200, podruhé ještě taky, ale to už každý Pod selhal dvakrát během 10 vteřin a byl odpojen. Další requesty už do Podů nepřichází a dostávám 503 přímo od Istia rovnou. Když počkám minutu, traffic zase bude chodit i na backend. To je příklad circuit breaker.
Load balancing
Stejně jako v případě Linkerd nám může Istio pomoci s lepší balancingem provozu v rámci clusteru. Potíž standardního balancingu v Kubernetes je, že je postavena na L4 implementaci, takže pro dobré rozdělení zátěže potřebujete dobrou entropii v IP/TCP/UDP hlavičkách - hodně adres, hodně TCP spojení. Ne vždy je ale jednoduché toho dosáhnout, například pokud máte na jedné straně singleton (službu, která má jen jednu aktivní instanci) a z ní chcete balancovat provoz na backend službu nebo ta první služba není singleton, ale má málo instancí a dělá proxy (například NGINX Igress). Tím máte malou entropii v IP adresách. Teď do toho přidejte optimalizaci na straně klientů jako je použití HTTP/2 u gRPC komunikace (to efektivně snižuje množství TCP spojení, tedy různorodost TCP hlaviček v paketech) a máte problém s rozumným balancováním. Istio vám ho pomůže vyřešit, protože funguje na L7 a session si rozbaluje, takže dokáže rozhazovat zátěž.
Nasadíme si Deployment a Service. Neděste se, jsou to dva Deploymenty v různých verzích, což je příprava na příště, až budeme řešit traffic split - prozatím ignorujme.
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: myweb-deployment-v1
spec:
replicas: 3
selector:
matchLabels:
app: myweb
version: v1
template:
metadata:
labels:
app: myweb
version: v1
spec:
containers:
- name: myweb
image: tkubica/web:1
env:
- name: PORT
value: "80"
ports:
- containerPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myweb-deployment-v2
spec:
replicas: 3
selector:
matchLabels:
app: myweb
version: v2
template:
metadata:
labels:
app: myweb
version: v2
spec:
containers:
- name: myweb
image: tkubica/web:2
env:
- name: PORT
value: "80"
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: myweb-service
labels:
app: myweb
spec:
selector:
app: myweb
ports:
- protocol: TCP
name: http
port: 80
targetPort: 80
kubectl apply -f canary.yaml
Nastavme si Istio na jednoduchý balancing podle náhody. K dispozici jsou ale i další metody jako je podle počtu spojení, sekvenčně v round robin a tak podobně.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: istio-lb
spec:
hosts:
- myweb-service
http:
- route:
- destination:
host: myweb-service
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: istio-lb
spec:
host: myweb-service
trafficPolicy:
loadBalancer:
simple: RANDOM
subsets:
- name: v1
labels:
version: v1
kubectl apply -f lbRandom.yaml
Vyzkoušíme provoz a měli bychom dostávat odpověď od různých backendů.
$ kubectl exec $clientPod -c client -- bash -c 'while true; do curl -s myweb-service; echo; sleep 0.2; done'
Version 1: server id 2b1960d8-bf7d-47cb-bf4a-eb3ca464a6dd
Version 1: server id e307911d-5f12-47ec-a158-cb828fbe418a
Version 1: server id b47cb71c-6fda-47d7-8a51-5648b9572179
Version 2: server id d4f8f350-543d-4d82-af84-da75766931dc
Version 2: server id d4f8f350-543d-4d82-af84-da75766931dc
Version 2: server id c285cc5d-f18d-4403-8149-42328f16af08
Version 1: server id 2b1960d8-bf7d-47cb-bf4a-eb3ca464a6dd
Version 2: server id c2e141cb-ae05-41e0-bcf8-c250e83c351d
Představme si teď, že v Kubernetu provozuje například nějakou starší komponentu, která není bezestavová a state si drží v paměti (nebo to dělá protože má extrémní požadavky na výkon a držet state externě je pomalejší). Potřebujeme tedy zajistit, abychom si sice vybrali nějaký backend, ale následná komunikace probíhala stála přes něj a neskákali jsme na různé Pody. Pokud jsem správně četl, tak to Envoy (potažmo Istio) zatím nepodporuje přes Cookie, ale dá se použít Header. V zásadě nějaké políčko na základě kterého se použije konzistentní hash ring, takže příště vyjde stejně (jednoduchý příklad na vysvětlení by byl převod řetězce na číslo a následné modulo na počet živých backend serverů a tím dostaneme pořadové číslo serveru … reálný použitý mechanismus je jiný, ale konceptuálně podobný).
Nastavení změníme takhle:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: istio-lb
spec:
hosts:
- myweb-service
http:
- route:
- destination:
host: myweb-service
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: istio-lb
spec:
host: myweb-service
trafficPolicy:
loadBalancer:
consistentHash:
httpHeaderName: User
subsets:
- name: v1
labels:
version: v1
Pošleme do clusteru. Nejdřív zkusíme bez headeru, pak s headerem.
$ kubectl apply -f lbHeaderHash.yaml
$ kubectl exec $clientPod -c client -- bash -c 'while true; do curl -s myweb-service; echo; sleep 0.2; done'
Version 1: server id 2b1960d8-bf7d-47cb-bf4a-eb3ca464a6dd
Version 1: server id e307911d-5f12-47ec-a158-cb828fbe418a
Version 1: server id b47cb71c-6fda-47d7-8a51-5648b9572179
$ kubectl exec $clientPod -c client -- bash -c 'while true; do curl -H "User: tomas" -s myweb-service; echo; sleep 0.2; done'
Version 1: server id 2b1960d8-bf7d-47cb-bf4a-eb3ca464a6dd
Version 1: server id 2b1960d8-bf7d-47cb-bf4a-eb3ca464a6dd
Version 1: server id 2b1960d8-bf7d-47cb-bf4a-eb3ca464a6dd
Kopírování provozu
Na závěr si ukážeme ještě jedno kouzlo. Někdy se může objevit problém, který se vám nedaří replikovat v testovacím prostředí. Zkoušet si to na produkci (například tam zapnout kompletní trasování requestů a debug logy dost možná způsobí omezení služby) nemusí být vhodné, ale zkopírování databází, sjednocení verzí, generování zátěže - nic z toho nevedlo k cíli. Musí tam být něco ve způsobu komunikace služeb mezi sebou nebo něco v requestu uživatele, těžko říct. Bylo by možná užitečné zachytit kopii tohoto provozu ale tak, abychom nijak nesahali do produkčního kontejneru (ve světě VM bychom mohli vzlézt na server a pustit tcpdump, ale i to může být výkonnostně riskantní a v kontejneru to je ještě horší, protože tcpdump asi nemáme v kontejnerovém obrazu a pokud ano, neměli bychom, když není pro provoz potřeba a i pokud tam je, potřebuje root nebo NET_ADMIN/NET_RAW capability a takový Pod byste rozhodně preferovat neměli). Pro situace typu nečekaná odpověď, nějaký neošetřený vstup, který službu sestřeluje nebo jiné než očekávané síťové chování (leze to z jiné adresy nebo to neleze vůbec) se může hodit.
Založím si službu sniffer, což je jednoduchý kontejner se spuštěným tcpdump.
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: sniffer
spec:
replicas: 1
selector:
matchLabels:
app: sniffer
template:
metadata:
labels:
app: sniffer
spec:
containers:
- name: sniffer
image: tkubica/sniffer
env:
- name: args
value: "tcp port 80"
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: sniffer
spec:
selector:
app: sniffer
ports:
- protocol: TCP
name: http
port: 80
targetPort: 80
Změníme si teď VirtualService pro službu retry, kterou jsme dnes využívali. Přidáme mirror a kopie provozu tak půjde do snifferu.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: retry-vs
spec:
hosts:
- retry-service
http:
- route:
- destination:
host: retry-service
mirror:
host: sniffer
Nahodíme a pošleme z client 20 dotazů na retry službu. Očekáváme, že budeme dostávat kopii provozu do snifferu, což uvidíme v jeho logu.
kubectl apply -f sniffer.yaml
kubectl apply -f copyVirtualService.yaml
export clientPod=$(kubectl get pods -l app=client -o jsonpath="{.items[0].metadata.name}")
kubectl exec $clientPod -c client -- bash -c 'for x in {0..20}; do curl -s retry-service?failRate=1&mode=busy; done'
export snifferPod=$(kubectl get pods -l app=sniffer -o jsonpath="{.items[0].metadata.name}")
kubectl logs $snifferPod -c sniffer
$ kubectl logs $snifferPod -c sniffer
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
11:06:28.703034 IP sniffer-86f57f7576-5fmt2.37916 > 169.254.169.254.80: Flags [S], seq 1214248727, win 29200, options [mss
1460,sackOK,TS val 1772460481 ecr 0,nop,wscale 7], length 0
11:06:28.704283 IP 169.254.169.254.80 > sniffer-86f57f7576-5fmt2.37916: Flags [S.], seq 1221788184, ack 1214248728, win 8192, options [mss 1460,nop,wscale 8,sackOK,TS val 2737481901 ecr 1772460481], length 0
11:06:28.704301 IP sniffer-86f57f7576-5fmt2.37916 > 169.254.169.254.80: Flags [.], ack 1, win 229, options [nop,nop,TS val
1772460482 ecr 2737481901], length 0
11:06:28.704417 IP sniffer-86f57f7576-5fmt2.37916 > 169.254.169.254.80: Flags [P.], seq 1:96, ack 1, win 229, options [nop,nop,TS val 1772460482 ecr 2737481901], length 95: HTTP: GET / HTTP/1.1
11:06:28.706250 IP 169.254.169.254.80 > sniffer-86f57f7576-5fmt2.37916: Flags [P.], seq 1:150, ack 96, win 8211, options [nop,nop,TS val 2737481903 ecr 1772460482], length 149: HTTP: HTTP/1.1 400 Bad Request
11:06:28.706268 IP sniffer-86f57f7576-5fmt2.37916 > 169.254.169.254.80: Flags [.], ack 150, win 237, options [nop,nop,TS val 1772460484 ecr 2737481903], length 0
11:06:28.706342 IP sniffer-86f57f7576-5fmt2.37916 > 169.254.169.254.80: Flags [F.], seq 96, ack 150, win 237, options [nop,nop,TS val 1772460484 ecr 2737481903], length 0
11:06:28.706719 IP 169.254.169.254.80 > sniffer-86f57f7576-5fmt2.37916: Flags [F.], seq 150, ack 97, win 8211, options [nop,nop,TS val 2737481903 ecr 1772460484], length 0
11:06:28.706726 IP sniffer-86f57f7576-5fmt2.37916 > 169.254.169.254.80: Flags [.], ack 151, win 237, options [nop,nop,TS val 1772460485 ecr 2737481903], length 0
11:06:57.171776 IP 10.240.0.232.54628 > sniffer-86f57f7576-5fmt2.80: Flags [S], seq 3851720429, win 29200, options [mss 1460,sackOK,TS val 2671513308 ecr 0,nop,wscale 7], length 0
11:06:57.171799 IP sniffer-86f57f7576-5fmt2.80 > 10.240.0.232.54628: Flags [S.], seq 4269784310, ack 3851720430, win 28960, options [mss 1460,sackOK,TS val 2882202838 ecr 2671513308,nop,wscale 7], length 0
11:06:57.171868 IP 10.240.0.232.54628 > sniffer-86f57f7576-5fmt2.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 2671513308 ecr 2882202838], length 0
11:06:57.171967 IP 10.240.0.232.54628 > sniffer-86f57f7576-5fmt2.80: Flags [P.], seq 1:844, ack 1, win 229, options [nop,nop,TS val 2671513308 ecr 2882202838], length 843: HTTP: GET /?failRate=1 HTTP/1.1
11:06:57.171973 IP sniffer-86f57f7576-5fmt2.80 > 10.240.0.232.54628: Flags [.], ack 844, win 240, options [nop,nop,TS val 2882202838 ecr 2671513308], length 0
11:06:57.173172 IP sniffer-86f57f7576-5fmt2.80 > 10.240.0.232.54628: Flags [P.], seq 1:232, ack 844, win 240, options [nop,nop,TS val 2882202839 ecr 2671513308], length 231: HTTP: HTTP/1.1 503 Service Unavailable
11:06:57.173190 IP 10.240.0.232.54628 > sniffer-86f57f7576-5fmt2.80: Flags [.], ack 232, win 237, options [nop,nop,TS val 2671513309 ecr 2882202839], length 0
11:06:57.173821 IP 10.240.0.232.54628 > sniffer-86f57f7576-5fmt2.80: Flags [P.], seq 844:1687, ack 232, win 237, options [nop,nop,TS val 2671513310 ecr 2882202839], length 843: HTTP: GET /?failRate=1 HTTP/1.1
11:06:57.176912 IP sniffer-86f57f7576-5fmt2.80 > 10.240.0.232.54628: Flags [P.], seq 232:463, ack 1687, win 253, options [nop,nop,TS val 2882202843 ecr 2671513310], length 231: HTTP: HTTP/1.1 503 Service Unavailable
11:06:57.178624 IP 10.240.0.232.54628 > sniffer-86f57f7576-5fmt2.80: Flags [P.], seq 1687:2530, ack 463, win 245, options [nop,nop,TS val 2671513314 ecr 2882202843], length 843: HTTP: GET /?failRate=1 HTTP/1.1
11:06:57.178995 IP sniffer-86f57f7576-5fmt2.80 > 10.240.0.232.54628: Flags [P.], seq 463:694, ack 2530, win 266, options [nop,nop,TS val 2882202845 ecr 2671513314], length 231: HTTP: HTTP/1.1 503 Service Unavailable
11:06:57.185819 IP 10.240.0.232.54650 > sniffer-86f57f7576-5fmt2.80: Flags [S], seq 2212653296, win 29200, options [mss 1460,sackOK,TS val 2671513322 ecr 0,nop,wscale 7], length 0
11:06:57.185833 IP sniffer-86f57f7576-5fmt2.80 > 10.240.0.232.54650: Flags [S.], seq 2692512746, ack 2212653297, win 28960, options [mss 1460,sackOK,TS val 2882202852 ecr 2671513322,nop,wscale 7], length 0
11:06:57.185848 IP 10.240.0.232.54650 > sniffer-86f57f7576-5fmt2.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 2671513322 ecr 2882202852], length 0
Dnes jsme si ukázali první část zajímavých funkcí Istio, konkrétně retry, circuit breaker, balancing a kopírování provozu. Už z toho je vidět, že Istio je funkčně hodně vpředu, ale je to vyváženo složitostí a spotřebou zdrojů. Příště si ukážeme traffic split a také to, že Istio může nahrazovat Ingress (Linkerd to záměrně nedělá a s Ingress se kombinuje, Istio jde cestou umožňit alternativu přímo v sobě). Někdy po tom všem se zaměříme i na exporty a vizibilitu jako je distribuovaný tracing možná s napojením na Application Insights přes OpenTelemetry standard. Určitě bychom se měli pustit i do tématu služeb v ruzných clusterech, cloudech nebo technologiích, což některé Service Mesh implementace umožňují.