Jak už jsem na tomto blogu několikrát říkal, stavové služby se snažím v Kubernetes neprovozovat a využít platformní nabídky v Azure. Pokud přecijen potřebuji robustní a výkonné řešení storage pod databázi nebo něco podobného, správná cesta je určitě StatefulSet a drivery pro Azure Disk. Co když ale jde spíše o potřebu sdílet nějaké soubory, například pro worker, který bude zpracovávat nějaké obrázky či CSV soubory, webová farma, která si bude sahat do obsahu (přece nebudu mít obrázky jako součást Docker image) nebo nějaká Git platforma, která si bude držet někde objekty. Často budu potřebovat současný přístup z několika instancí (nejčastěji pro čtení dat) a nebo dokonce i pro zápis (neběží nad tím nějaký vysoce transakční systém typu databáze, jsou to třeba malé soubory bez paralelních přístupů). Tyto situace se dají elegantně řešit vzdáleným souborovým systémem. Velkou výhodou je, že ten si vezmu jako platformní službu v Azure, takže se nemusím starat o podvozek, patchovat nebo řešit redundanci. Rád bych vyzkoušel tři následující varianty a stejně jako minule použiji CSI driver tam, kde to jde (v preview - v praxi zatím použijte in-tree implementaci, která je součást AKS, funkčně je teď shodná):
- Azure Files - souborový systém jako služba postavený na SMB/CIFS protokolu včetně zónové redundance či dokonce regionální redundance a základní (standard) i zvýšeným výkonem (premium)
- Azure Blob - velmi levný typ uložení dat s podporou moderní API, tierování a často používaný i pro datově zaměřené aplikace
- Azure NetApp Files - plně spravovaná služba ze spolupráce Microsoft a NetApp pro SMB/NFS souborovou službu s možností velmi vysokých výkonů
Vytvořím si cluster a nastavím managed identitě, kterou použije CSI driver, přístup do resource group.
az group create -n kubefiles -l westeurope
az aks create -n kubefiles -g kubefiles --enable-managed-identity -k 1.18.6 -c 1 -s Standard_B2s -x --network-plugin azure
az aks get-credentials -n kubefiles -g kubefiles --admin
rg=$(az aks show -n kubefiles -g kubefiles --query nodeResourceGroup -o tsv)
identity=$(az aks show -n kubefiles -g kubefiles --query identityProfile.kubeletidentity.objectId -o tsv)
az role assignment create --role Contributor --assignee-object-id $identity --resource-group $rg
Připomenu tedy co mají společného všechny varianty, které budeme zkoušet:
- Platformní služby, které mají vždy redundanci v sobě a často jdou ještě dál (i do synchronizace mezi regiony, nejen zónami dostupnosti)
- Jejich připojení je přes síť a mimo hypervisor, takže je velmi rychlé (pokud se například Pod musí pustit na jiném Node, připojení storage je do vteřiny hotové na rozdíl od disků)
Azure Files
Azure Files nabízí základní výkon (Standard) vhodný pro sdílení souborů nebo obsahu webu, ale i SSD uložení s nižší latencí a IOPS podle rezervované kapacity (každý zaplacený GB dává 1 IOPS garantovaného výkonu s burstingem až na 3), což je vhodné pro náročnější situace i jednodušší databáze. Pojďme si nainstalovat příslučný CSI driver (nebo použijte in-tree implementaci v AKS dle návodu na webu). K dispozici jsou různé varianty redundance od lokální replikace (3 kopie v rámci datového centra), přes zónové kopie (3 kopie každá v jiné zóně dostupnosti, tedy řekněme budově) až ke globálním řešením s šesti kopiemi ve dvou regionech vzdálených od sebe stovky kilomentrů.
curl -skSL https://raw.githubusercontent.com/kubernetes-sigs/azurefile-csi-driver/v0.8.0/deploy/install-driver.sh | bash -s v0.8.0 snapshot --
Ovladače jsou nainstalované, vyzkoušejme si StorageClass pro automatické vytváření share.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: azurefile-csi
provisioner: file.csi.azure.com
allowVolumeExpansion: true
parameters:
skuName: Standard_LRS # available values: Standard_LRS, Standard_GRS, Standard_ZRS, Standard_RAGRS, Premium_LRS
reclaimPolicy: Delete
volumeBindingMode: Immediate
Založím PVC.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azurefile
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
storageClassName: azurefile-csi
Driver pro mne automaticky vytvořil storage account a v něm share.
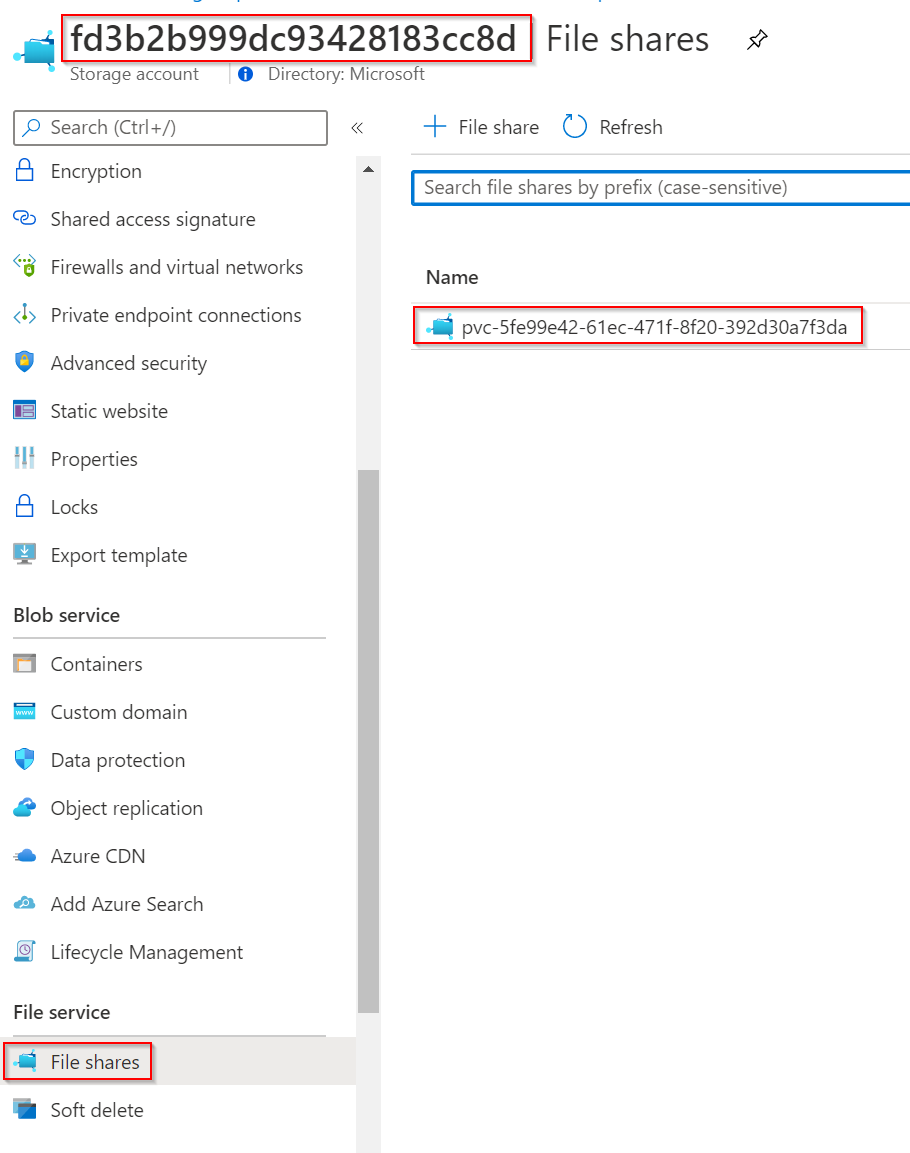
Vytvořím teď Pod s NGINX, který bude mít obsah webu namapovaný na tento volume a bude generovat index.html, který si pak ve storage prohlédneme.
kind: Pod
apiVersion: v1
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azurefile
mountPath: "/usr/share/nginx/html"
volumes:
- name: azurefile
persistentVolumeClaim:
claimName: pvc-azurefile
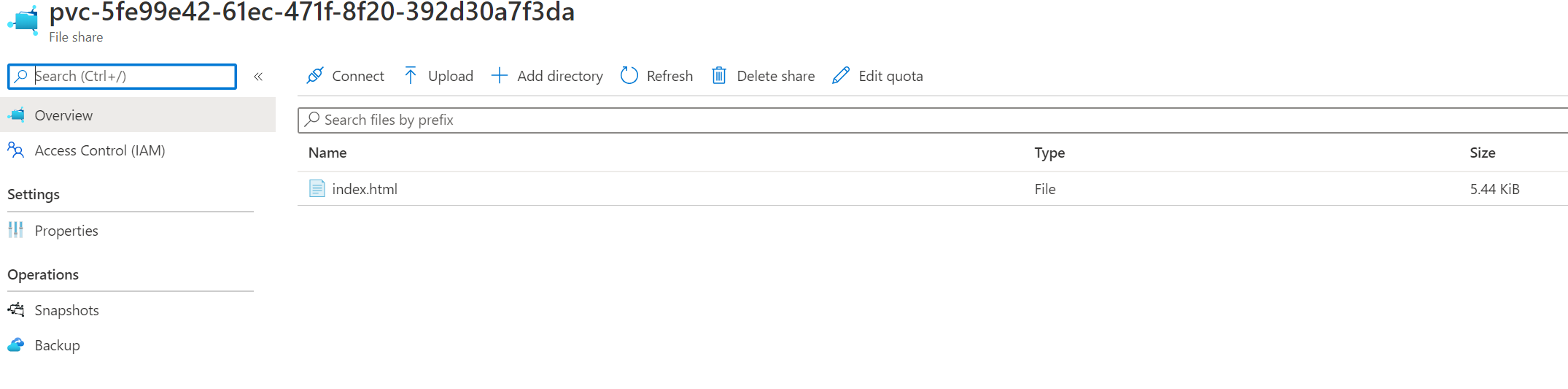
Jakmile Pod naběhne vidím, že skutečně zapisuje do mých Azure Files.
CSI implementace má i driver pro snapshot. Vytvořím si snapshot třídu.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshotClass
metadata:
name: csi-azurefile-vsc
driver: file.csi.azure.com
deletionPolicy: Delete
Následně si nechám udělat snapshot1.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: azurefile-volume-snapshot1
spec:
volumeSnapshotClassName: csi-azurefile-vsc
source:
persistentVolumeClaimName: pvc-azurefile
Pak jsem vytvořil ještě druhý snapshot a podívám se na výsledek.

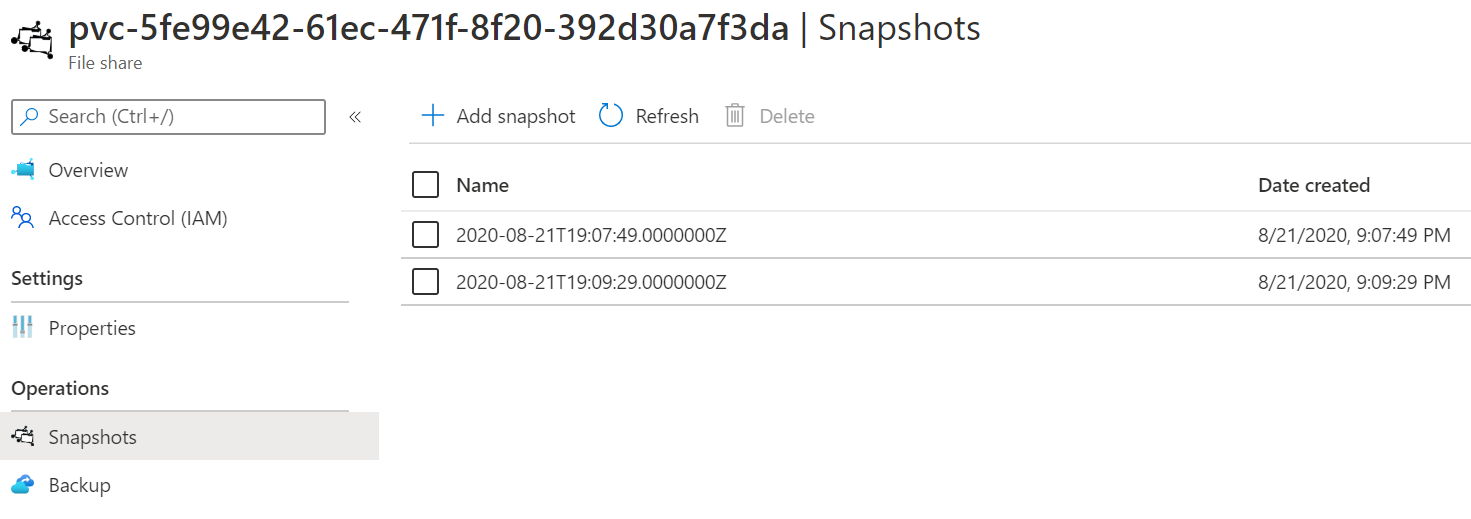

Použití dynamického PVC má pro mnoho případů určitě smysl, ale na rozdíl od třeba disků očekávám, že daleko častěji budu chtít konkrétní už existující share. Tak například chci mít třeba obrázky nějakého webu uloženy v této storage jednuduše ji připojit k webu (preferoval bych servírovat obsah rovnou z blob storage a dát před to Azure CDN, ale to může vyžadovat zásah do aplikace).
Vytvořím tedy storage account, share, soubor s mým index.html, který tam nahraji.
az storage account create -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope
az storage share create -n mujshare --account-name mojerucneudelanastorage --account-key \
$(az storage account keys list -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope --query [0].value -o tsv)
echo Ahojky! > index.html
az storage file upload -s mujshare --source ./index.html --account-name mojerucneudelanastorage --account-key \
$(az storage account keys list -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope --query [0].value -o tsv)
rm index.html
Jak namapuji tento share do Podů? Nepotřebuji tady StorageClass, protože se připojuji ručně, ale díky tomu také driver musí vědět jak se do share připojit (nevytváří si ho sám). Potřebujeme tedy připravit příslušný secret.
kubectl create secret generic storage-secret --from-literal accountname=mojerucneudelanastorage --from-literal accountkey="$(az storage account keys list -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope --query [0].value -o tsv)" --type=Opaque
Teď si ručně vytvoříme PersistentVolume, kterému předáme v secret potřebná hesla a následně nad ním už nastavíme Persistent Volume Claim. Nad ním už přijde na řadu Pod, tentokrát jednoduše s nginx kontejnerem s tím, že adresář webu je z našeho volume a měl by tam být můj index.html.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-azurefileexisting
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
mountOptions:
- mfsymlinks
csi:
driver: file.csi.azure.com
readOnly: false
volumeHandle: mujshare
volumeAttributes:
shareName: mujshare
nodeStageSecretRef:
name: storage-secret
namespace: default
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-azurefileexisting
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
volumeName: pv-azurefileexisting
storageClassName: ""
---
kind: Pod
apiVersion: v1
metadata:
name: nginx2
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: azurefile
mountPath: "/usr/share/nginx/html"
volumes:
- name: azurefile
persistentVolumeClaim:
claimName: pvc-azurefileexisting
Připojím se na svůj web a měl bych tam najít index.html ze storage.
kubectl port-forward pod/nginx2 12345:80
curl 127.0.0.1:12345
Ahojky!
Na závěr si ještě pojďme ukázat některé limity dané použitým souborovým systémem SMB/CIFS v Azure Files.
kubectl exec -ti nginx2 -- bash
cd /usr/share/nginx/html
ln -s index.html symbolic.html
ls -lah
total 6.5K
drwxrwxrwx 2 root root 0 Aug 21 19:25 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rwxrwxrwx 1 root root 7 Aug 21 19:28 index.html
lrwxrwxrwx 1 root root 10 Aug 24 07:11 symbolic.html -> index.html
ln index.html hardlink.html
ln: failed to create hard link 'hardlink.html' => 'index.html': Operation not supported
useradd user1
touch file
ls -lah
total 6.5K
drwxrwxrwx 2 root root 0 Aug 21 19:25 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rwxrwxrwx 1 root root 7 Aug 21 19:28 index.html
lrwxrwxrwx 1 root root 10 Aug 24 07:11 symbolic.html -> index.html
-r-xr-xr-x 1 root root 5 Aug 23 09:08 file
chown user1:user1 ./file
ls -lah
total 6.5K
drwxrwxrwx 2 root root 0 Aug 21 19:25 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rwxrwxrwx 1 root root 7 Aug 21 19:28 index.html
lrwxrwxrwx 1 root root 10 Aug 24 07:11 symbolic.html -> index.html
-r-xr-xr-x 1 root root 5 Aug 23 09:08 file
chmod +t ./file
ls -lah
total 6.5K
drwxrwxrwx 2 root root 0 Aug 21 19:25 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rwxrwxrwx 1 root root 7 Aug 21 19:28 index.html
lrwxrwxrwx 1 root root 10 Aug 24 07:11 symbolic.html -> index.html
-r-xr-xr-x 1 root root 5 Aug 23 09:08 file
Podporu pro symbolické linky jsem specificky zapnul v ovladači, ale hard linky jsou pevně svázané s Linux file systémem a na SMB/CIFS nejsou podporované. Dále se mužeme přesvědčit, že nastavování atributů jako je vlastník souboru nebo setuid či sticky bit nefungují. Za běžné situace u vaší aplikace to myslím nebude problém, ale můžete mít aplikaci třetí strany, která má nějaký instalátor či jinou závislost na těchto vlastnostech. Napadá mě například relační databáze, kdy s některými nemusíte pochodit, pokud je budete chtít provozovat proti Azure Files v tomto režimu.
VHD z Azure Files
CSI driver umožňuje ještě jednu specialitu fungující jen s Premium verzí Azure Files a to je napojení disku ve formě VHD souboru uloženého v Azure Files. To má některé zásadní výhody i nevýhody.
Výhody:
- Virtuální disk je připojen po síti a nemá tak omezení na počet disků připojených k VM (při běžných Azure Disk je počet připojitelných disků závislý na typu použitého VM a může v jednotkách či nižších desítkách), takže můžete mít na Node klidně 20 malých Podů a každý s vlastním diskem.
- Připojení virtuálního disku trvá méně jak jednu vteřinu, takže pokud máte singleton a nechcete nebo nemůžete řešit replikaci dat v software, tato varianta může fungovat i jako rozumné HA.
- Premium Files podporují i tier ZRS, takže data jsou ve více zónách - to aktuálně s disky nedokážete.
- Na rozdíl od běžných Azure Files tady máte ext4 file system se všemi jeho vlastnostmi, takže kompatibilita s různým software je vyšší, než u CIFS připojení.
Nevýhody:
- Azure Files Premium vs. Premium SSD? Výkonnost je podobná, ale cena je 2x větší.
- Pokud potřebujete jít výkonnostně hodně vysoko, potřebujete hodně nízkou latenci nebo musíte mít vysoký výkon při malém prostoru (Azure Files mají 1 IOPS per GB, takže víc výkonu = víc prostoru), bude Azure Disk s Ultra SSD výrazně lepší volbou.
Nasadíme storage class pro VHD řešení s SKU Premium_ZRS (zónová redundance).
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: azurefile-vhd
provisioner: file.csi.azure.com
parameters:
skuName: Premium_ZRS
fsType: ext4
Teď už můžeme vytvořit StatefulSet.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
labels:
app: nginx
spec:
serviceName: nginx-statefulset
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- image: nginx
name: nginx-azuredisk
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azuredisk
mountPath: "/usr/share/nginx/html"
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 16M
limits:
cpu: 500m
memory: 64M
volumeClaimTemplates:
- metadata:
name: azuredisk
annotations:
volume.beta.kubernetes.io/storage-class: azurefile-vhd
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
Ve storage vidím, že mám VHD soubor.
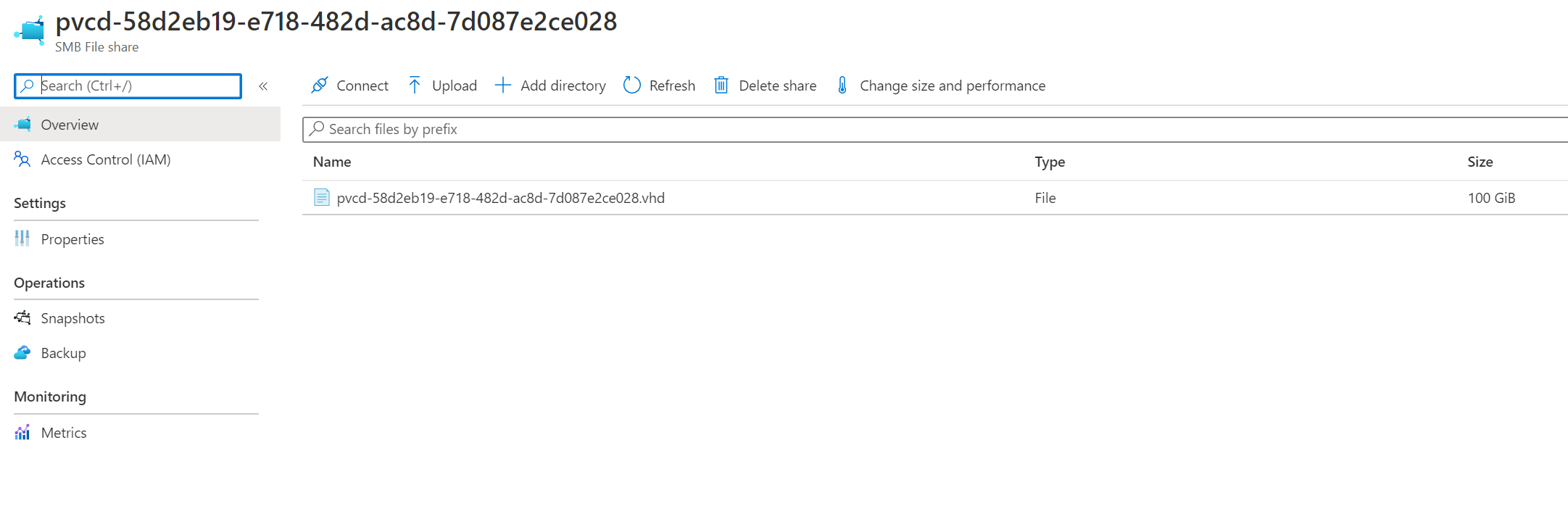
kubectl exec -ti nginx-statefulset-0 -- bash
cd /usr/share/nginx/html
ln -s index.html symbolic.html
ls -lah
total 52K
drwxr-xr-x 3 root root 4.0K Aug 24 10:04 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rw-r--r-- 2 root root 26K Aug 24 10:04 index.html
drwx------ 2 root root 16K Aug 24 09:49 lost+found
lrwxrwxrwx 1 root root 10 Aug 24 10:04 symbolic.html -> index.html
ln index.html hardlink.html
ls -lah
total 80K
drwxr-xr-x 3 root root 4.0K Aug 24 10:04 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rw-r--r-- 2 root root 26K Aug 24 10:04 hardlink.html
-rw-r--r-- 2 root root 26K Aug 24 10:04 index.html
drwx------ 2 root root 16K Aug 24 09:49 lost+found
lrwxrwxrwx 1 root root 10 Aug 24 10:04 symbolic.html -> index.html
useradd user1
touch file
ls -lah
total 80K
drwxr-xr-x 3 root root 4.0K Aug 24 10:05 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rw-r--r-- 1 root root 0 Aug 24 10:05 file
-rw-r--r-- 2 root root 27K Aug 24 10:05 hardlink.html
-rw-r--r-- 2 root root 27K Aug 24 10:05 index.html
drwx------ 2 root root 16K Aug 24 09:49 lost+found
lrwxrwxrwx 1 root root 10 Aug 24 10:04 symbolic.html -> index.html
chown user1:user1 ./file
ls -lah
total 80K
drwxr-xr-x 3 root root 4.0K Aug 24 10:05 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rw-r--r-- 1 user1 user1 0 Aug 24 10:05 file
-rw-r--r-- 2 root root 28K Aug 24 10:05 hardlink.html
-rw-r--r-- 2 root root 28K Aug 24 10:05 index.html
drwx------ 2 root root 16K Aug 24 09:49 lost+found
lrwxrwxrwx 1 root root 10 Aug 24 10:04 symbolic.html -> index.html
chmod +t ./file
ls -lah
total 88K
drwxr-xr-x 3 root root 4.0K Aug 24 10:05 .
drwxr-xr-x 3 root root 4.0K Aug 14 00:36 ..
-rw-r--r-T 1 user1 user1 0 Aug 24 10:05 file
-rw-r--r-- 2 root root 29K Aug 24 10:06 hardlink.html
-rw-r--r-- 2 root root 29K Aug 24 10:06 index.html
drwx------ 2 root root 16K Aug 24 09:49 lost+found
lrwxrwxrwx 1 root root 10 Aug 24 10:04 symbolic.html -> index.htm
Jak vidno, jedná se skutečný Volume s plnou podporou Linux vlastností. Symbolické i hard linky, permissions včetně speciálních atributů, změny vlastnictví souborů. Zkrátka je to totéž, jako připojit Azure Disk z pohledu software, který namapovaný disk používá.
Azure Blob
Nejlevnějším způsobem uložení dat v cloudu je objektová storage jako Azure Blob. Je to dáno především tím, že přístup k nim je velmi zjednodušený a garance co do POSIX vlastností jsou omezené. Výsledkem je velmi levná storage, která už v samém základu nabízí lepší ceny než disky nebo POSIX compliant Azure Files (ty musí v rámci POSIX nabíze session garance, takže nad nimi musí sedět nějaká nadstavba, compute, který přijímá vaše requesty a dodržuje POSIX pravidla). A teď považte, že storage můžete přepnout do tieru Cool a snížit náklady na uložení na polovinu (za cenu zvýšení nákladů na přístup k datům) nebo dokonce přejít na offline uložení s tierem Archive. Kromě toho podporu Azure Blob storage i režim s hierarchickým namespace určeným pro Data Lake (HDFS přístup) optimalizovaný na současné čtecí přístupy z několika nodů do jediného objektu a nově také podporují bezestavové NFSv3. Pokud tedy mám nějakou logiku, která má přimárně zpracovávat velké množství nestrukturovaných dat, blob je na to ideální.
Typický scénář bude, že data se nějakým mechanismem dostanou na blob (třeba z Event Hub je přes Stream Analytics nasypete do blobu nebo děláte pravidelné rxporty do CSV apod.) a tam se dále zpracovávají. Dost možná je nacucne datová pumpa typu Data Factory nebo si na ně posvítí Azure Databricks nebo si je namapuje jako vzdálený zdroj třeba Azure Synapse. Někdy ale potřebujete nějakou logiku ve formě kódu a dává vám symsl ji mít v Kubernetes. Možná máte v blobech multimediální audio a video soubory, které potřebujete zpracovávat aplikačně. Ideální samozřejmě bude k nim přistupovat přes storage API, ale existující kód to musíte nejdřív naučit. Co když máte aplikaci, která to umí jen z lokálních souborů? Pak by se hodilo namapovat bloby jako Volume v Kubernetes.
Ukažme si jak na to s CSI driverem a připomínám, že tím, že systém není POSIX compliant se určitě nehodí jako náhrada běžného souborového systému třeba pro instalaci aplikace nebo databáze! Příklad použití bude spíše zpracování dat, zejména jejich načítání a zpracování.
Nainstalujeme CSI driver pro blob.
curl -skSL https://raw.githubusercontent.com/kubernetes-sigs/blob-csi-driver/v0.7.0/deploy/install-driver.sh | bash -s v0.7.0 --
Typicky očekávám tento scénář s použitím Blob storage, která je už předem připravena a píše do ní data nějaký jiný proces, takže nasadíme statický volume. Podobně jako u Azure Files bych mohl přímo vytvořit Persistent Volume a v Secret mu řpedat jméno a heslo, ale já budu chtít využít managed identitu svého clusteru. Proto založím StorageClass přímo pro konkrétní storage account, což mi umožní se do něj hlásit přes zabezepčenou managed identitu a nemusím používat klíče.
az storage account create -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope
az storage container create -n mujkontejner --account-name mojerucneudelanastorage --account-key \
$(az storage account keys list -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope --query [0].value -o tsv)
echo Ahojky! > index.html
az storage blob upload -c mujkontejner -f ./index.html -n index.html --account-name mojerucneudelanastorage --account-key \
$(az storage account keys list -n mojerucneudelanastorage -g MC_kubefiles_kubefiles_westeurope --query [0].value -o tsv)
rm index.html
Blob storage je připravena. Založíme tedy StorageClass namířenou přímo na náš hotový account (abychom mohli využít přihlášení přes managed identitu) a vytvoříme PVC a Pod.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: tomasblob
provisioner: blob.csi.azure.com
parameters:
resourceGroup: MC_kubefiles_kubefiles_westeurope
storageAccount: mojerucneudelanastorage
containerName: mujkontejner
reclaimPolicy: Retain
volumeBindingMode: Immediate
mountOptions:
- -o allow_other
- --file-cache-timeout-in-seconds=120
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-blob
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: tomasblob
---
kind: Pod
apiVersion: v1
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: azureblob
mountPath: "/usr/share/nginx/html"
volumes:
- name: azureblob
persistentVolumeClaim:
claimName: pvc-blob
Vyzkoušíme, že ve náš web sahá do obsahu v Blobu.
kubectl port-forward pod/nginx 12345:80
curl 127.0.0.1:12345
Ahojky!
Funguje. Blob driver určitě nepoužívejte, pokud potřebujete nějakým způsobem zapisovat současně z víc Podů a tak podobně. Nicméně pro případ jako je ten náš, tedy primárně čtení a to klidně z několika instancí, je blob dobrý kandidát a cenově velmi příjemný. Navíc vezměte v potaz, že podporuje možnosti redundance, které třeba uz disků k dispozici nejsou jako je zónová redunance či dokonce globální zónová redundance s podporou čtení v obou regionech.
Azure NetApp Files
Potřebujete velmi vysoký výkon, ale vaše aplikace není připravena na replikaci v software nebo na to nemáte licenci, která by byla příliš drahá? Nemyslím, že je to ideální stav, ale doporučoval bych ho řešit s Azure NetApp Files. Proč?
- Řešení se připojuje přes NFSv3 nebo NFSv4.1 a je tak velmi nativní pro Linux aplikace.
- Na výběr máte 3 výkonnostní kategorie, které se uvádí v propustnosti (throttling není na IOPS nebo jiné parametry). Ta je 128 MiB/s za každý 1TB storage v tieru Ultra. To při velikosti bloku 4KB dává 32 768 IOPS na každý TB storage (tedy o dost víc, než Azure Files Premium nebo Premium SSD disk při stejné velikosti - nicméně nedokáže se propustností přiblížit maximu UltraSSD, které jsou ale finančně o dost náročnější).
- V jiných cloudech není NetApp technologie tak nativně integrovaná do prostředí, ale je k dispozici v AWS i GCP a můžete tak storage pro stavové kontejnery standardizovat na technologii třetí strany.
- Azure NetApp Files jsou plně managed služba a s výkonem nativního hardware (služba na pozadí využívá přímého přístupu do železa pro některé své komponenty) - nemusíte se starat o VM, patching nebo výkonnostní ladění ONTAP na vlastních VMkách.
Azure NetApp Files si vytvoříme tak, že zřídíme account, následně storage pool (minimální velikost k je 4TB) a v něm následně Volume, který bude namapovaný do dedikovaného subnetu ve VNETu, kde mám AKS (každý Volume stejného poolu můžete dát jinam).
Volume připojíme přes nativní NFS driver, takže netřeba nic instalovat, pokud vám stačí statické napojení (mě teď ano). Pokud toužíte po plnokrevném driveru včetně vytváření Volume automaticky na základě PVC šablony, musíte si nainstalovat NetApp driver.
Jedním ze scénářů by mohla být situace, kdy je Volume sdílen vícero Pody z nichž třeba jeden je zapisovací a ostatní mohou číst a mezi sebou si nějakým způsobem volí kdo je zapisovací. Jak se to dozví klient? Můžete v praxi najít řekněme tři řešení:
- Uděláte Service objekt bez balancování, takže jde pouze o to, že DNS vrátí všechny živé nody a klient (SDK) si samo zjistí, kdo má roli zapisovače nějakým svým protokolem.
- Uděláte Service s tím, že u Podů liveness probe říká, který node žije, ale na readiness probe bude kladně odpovídat jen ten, kdo nejen žije, ale je hlavním uzlem (zapisovač). Aplikačně se pak ptáte na Service a jste nasměrování do správného uzlu.
- Uděláte jednu Service pro čtení a jinou pro zápis a použijete přímo v aplikaci Kubernetes API pro správu toho, který node je zapisovací (vyplníte mu seznam endpointů ručně).
Ale jak už jsem říkal mnohokrát - stavové věci jsou složité, raději to přenechejte platformní službě. Podívejme se spíše na scénář, kdy vícero aktivních nodů je příliš komplexní (ať už s replikací dat v software nebo nějakém sdílení přístupu do stejného Volume) a vy potřebujete je singleton s rozumnou reakční dobou na výpadek nebo upgrade v clusteru. Pak tedy nemůžeme použít Deployment (tam reálně po krátký čas poběží víc než jedna instance, na což nejsme v primitivním scénáři připraveni v software), půjdeme do StatefulSetu s jedinou replikou. Měli bychom ještě nastavit toleranci tak, že v případě havárie Node nebudeme čekat 5 minut, ale kratší dobu (ale o tom už jsem psal, jak jistě dohledáte). To mi umožní při havárii Node nebo jeho upgrade pustit Pod jinde ale tak, že bude zajištěno, že nepoběží ani chvilku dvakrát (tedy kromě situace kdy node jen odpodane z control plane - o tom už jsem psal v článku o discích a může to být velký průšvih, protože do disku může pořád vidět a buď vás nepustí k failover přes zámky, což není dobré, nebo vám dovolí zapisovat ze dvou míst, což je ještě horší). Nic ideálního, ale určitě příjemnější, než singleton s diskem (jak si za chvilku připomeneme).
Nasadíme si tento PV, PVC a StatefulSet:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nfs
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.0.0.4
path: /tomasVolume
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-nfs
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 100Gi
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx
labels:
app: nginx
spec:
serviceName: nginx-statefulset
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
command:
- "/bin/sh"
- "-c"
- nginx & chmod 755 /usr/share/nginx/html; while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: nfsvolume
mountPath: "/usr/share/nginx/html"
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 16M
limits:
cpu: 500m
memory: 64M
volumes:
- name: nfsvolume
persistentVolumeClaim:
claimName: pvc-nfs
Pod naběhne a začne každou vteřinu přidávat rádek do index.html.
kubectl port-forward pod/nginx-0 12345:80
curl 127.0.0.1:12345
Tue Aug 25 08:34:59 UTC 2020
Tue Aug 25 08:35:00 UTC 2020
Tue Aug 25 08:35:01 UTC 2020
Tue Aug 25 08:35:02 UTC 2020
Tue Aug 25 08:35:03 UTC 2020
Tue Aug 25 08:35:04 UTC 2020
Výborně. Teď necháme Pod vypnout. Kubernetes mu pošle sigterm a počká, až se korektně ukončí (v mém případě se tak nestane, protože nginx pouštím ze skriptu bez ošetření propagace signálu, takže po 30 vteřin, což lze nastavit i jinak, dostane sigkill, ale mezitím normálně funguje). Teprve až je Pod jednoznačně pryč se nahodí nový a disk se připojí. Jak velký výpadek zaznamenáme?
kubectl delete pod nginx-0
kubectl port-forward pod/nginx-deployment-76978f8fdb-88t82 12345:80
curl 127.0.0.1:12345
Tue Aug 25 08:35:00 UTC 2020
Tue Aug 25 08:35:01 UTC 2020
Tue Aug 25 08:35:02 UTC 2020
Tue Aug 25 08:35:03 UTC 2020
Tue Aug 25 08:35:04 UTC 2020
Tue Aug 25 08:35:05 UTC 2020
Tue Aug 25 08:35:06 UTC 2020
...
Tue Aug 25 08:35:41 UTC 2020
Tue Aug 25 08:35:42 UTC 2020
Tue Aug 25 08:35:43 UTC 2020
<nedostupnost>
Tue Aug 25 08:35:48 UTC 2020
Tue Aug 25 08:35:49 UTC 2020
Tue Aug 25 08:35:50 UTC 2020
Tue Aug 25 08:35:51 UTC 2020
Tue Aug 25 08:35:52 UTC 2020
Tue Aug 25 08:35:53 UTC 2020
5 vteřin. To není vůbec špatné. V porovnání s diskem:
- NetApp Files sice nejsou zónově redundantní, ale mají SLA 99,99% a jsou dostupné ze všech zón, takže havárie compute vrstvy v celé zóně mi nevadí.
- Disk se přepojí prakticky okamžitě, vidíte, že 5 vteřin to trvá celkem od finálního ukončení jednoho Podu do nastartování nového (za předpokladu, že je image v cache Node, jinak připočítejte čas na stažení).
- Multi-mount je možný (u disků jen v Preview v určitých regionech a s některými omezeními)
Na druhou stranu, disky jsou pro plně stavové náročně aplikace typu databáze kdy to s dostupností myslíte opravdu vážně lepší volba -> použijete replikaci dat v software, plná zónová redundance, možnost opravdu ultra výkonů (UltraSSD disky), nižší latence (pod jednu milisekundu u UltraSSD).
Tolik k dnešnímu tématu perzistence storage v Kubernetes.
- Pokud můžete, vždy pro stavové věci použijte hotovou službu.
- Pokud už musíte (třeba jste v onprem), prozkoumejte kdy bude k dispozici Azure Arc for Data Services, ať to někdo udělá za vás (ale u vás).
- Pokud musíte a nejde použít nic plně spravovaného, rozhodujte se podle typu aplikce: a. Potřebujete přistupovat ke sdíleným datům nebo implementovat méně náročné singleton řešení? Jděte do souborových variant z dnešního článku. b. Potřebujete vysoce výkonnou a konzistentní datovou službu typu relační databáze nebo nějaké distribuované řešení (Cassandra, Gluster)? Jděte do disků, dosáhnete většího výkonu (hlavně v oblasti latence), robustnosti na aplikační úrovni a při srovnatelné kvalitě (SLA/výkon) řešení to bude asi levnější.