Před dvěma lety jsem psal o stavových aplikacích a storage v Kubernetes a je na čase se podívat co je nového a jít do větší hloubky. Než se tak ale stane: snažte se veškerý stav externalizovat do cloudové služby a storage v Kubernetes pro něj nepoužívat. Stavové věci v libovolném distribuovaném systému jsou velmi náročné a je lepší je přenechat někomu jinému - cloudovému poskytovateli. Proč?
- Jsou to data. Nemůžete je jen tak zahodit a začít znova jako u aplikačních instancí.
- V cloudu je triviální usídlit se ve vícero datových centrech aplikačně (zóna dostupnosti), ale disky jsou jen v jedné.
- Infrastruktura (např. disk) sice data ukládá redundantně, ale navenek je to stále jeden objekt. Redundance je tedy OK (resp. uvnitř zóny dostupnosti viz předchozí bod), ale pokud vám vypadne aplikační část (Pod/Node), musí se disk přepojit jinam a to trvá docela dlouho. Pro vysokou dostupnost tedy stejně skončíte u replikace v software (AlwaysOn na SQL apod.). Druhým důvodem pro něco takového je možné poškození dat při nekorektním ukončení kódu.
- A co DR do jiného regionu? Aktivní asynchronní replika je OK, ale drahá, možná pro vaše RTO/RPO požadavky stačí obnova. Jakákoli asynchronní činnost bez porozumění datové struktuře (tedy dělaná “netransakčně” z pohledu databáze) vám nezajistí konzistenci, takže stejně budete řešit nějaký databázový export a obnovu místo přesouvání disků (ty už nemusí být dostupné, když budova hoří nebo mohou poškozená data).
Ve finále služba v Azure bude spolehlivější, robustnější, bude mít větší dostupnost, dostanete SLA na službu jako celek, support a dost možná to v celkových nákladech bude o dost levnější. Můžete mít různé formy databází (SQL, MySQL, MariaDB, PostgreSQL, MongoDB API, Cassandra API, …), analytických platforem (Synapse, Databricks), frontování/zprávy/události (Event Hub, Service Bus, Event Grid), soubory (Azure Storage), API Management, stavové workflow s Logic App a hromadu dalších komponent.
Ale dobře - jsou situace, kdy storage potřebujete, chápu. Dnes se zaměřím na Azure Disk a příště na Azure Files. Oboje vnímám jako cílené na odlišné situace (zhruba řečeno):
- Disky jsou skutečné stavové systémy jako jsou databáze, nabízí maximální výkon, dobrou cenu, ale ideálně byste měli přidat replikaci v software.
- Soubory jsou perfektní pro sdílení obsahu, zpracování dat nebo ukládání jednoduchých objektů.
Nové CSI drivery vs. tradiční storage implementace
Jako skoro každý open source projekt má Kubernetes v historii vytrhávání střev do samostatných projektíků. Kubernetes je od začátku modulární distribuovaný systém, ale ovládání storage (implementace objektů Persistent Volume a Persistent Volume Claim viz můj dřívější článek) bylo součást core Kubernetes kódu. Jakákoli změna, třeba oprava chyby, znamenala dotlačit to do celého Kubernetes a to vzhledem k velikosti komunity a složitosti testování rozhodně není dnes udržitelný koncept. Tato funkcionalita je nově vytržena do samostatných “driverů” - CSI (Container Storage Interface) podobně jako třeba CNI řeší integraci do síťového prostředí (drivery pro komunikaci mezi Pody, ovládání LoadBalanceru v infrastruktuře) nebo Ingress implementace spravují L7 routing. Tedy i dost nízkoúrovňové součástky Kubernetes jsou dnes modulární a jejich kód pro daného providera může z pohledu vývoje žít mimo Kubernetes samotný, což znamená daleko větší agilitu jak pro hlavní projekt tak drivery.
Azure Kubernetes Service dnes v základu přichází s nativními drivery, ale Azure současně nabízí velmi stabilní implementaci CSI. Komunita plánuje doporučovat CSI jako default ve verzi 1.21 a to už je za chvilku. V dnešním článku tedy využiji už CSI implementaci, byť v tuto chvíli to není nutné (nativní implementace umí zatím totéž). Je ale jedna výjimka - v rámci CSI implementace můžete mít Azure Key Vault, který jako in-tree implementace není (těm co se v oblasti pohybujete - ano, CSI je náhrada pro FlexVolume, který posloužil jako “vycpávka” mezi světem vázaných implementací a dnešního CSI).
Příprava prostředí a instalace CSI
Jak už padlo CSI není default, takže si ho nainstalujeme. Nejdřív vytvořím AKS cluster se 4 nody přes 2 zóny dostupnosti.
az group create -n kubedisk -l westeurope
az aks create -n kubedisk -g kubedisk --enable-managed-identity -k 1.18.6 -c 4 -z 1 2 -s Standard_B2s -x
az aks get-credentials -n kubedisk -g kubedisk --admin
Použil jsem managed identitu, v dnešní době už bych nepreferoval jet přes service principal. Kubernetes identitě musím dát právo vytvářet v Azure disky a to v resource group, kde jsou jeho zdroje. Toto právo pojďme přiřadit.
rg=$(az aks show -n kubedisk -g kubedisk --query nodeResourceGroup -o tsv)
identity=$(az aks show -n kubedisk -g kubedisk --query identityProfile.kubeletidentity.objectId -o tsv)
az role assignment create --role Contributor --assignee-object-id $identity --resource-group $rg
Můžeme se pustit do instalace CSI ovladače pro Azure Disk.
curl -skSL https://raw.githubusercontent.com/kubernetes-sigs/azuredisk-csi-driver/v0.8.0/deploy/install-driver.sh | bash -s v0.8.0 snapshot --
Všechno naskočilo a lze poslat do Kubernetes novou StorageClass.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-csi-standard-ssd
provisioner: disk.csi.azure.com
parameters:
skuname: StandardSSD_LRS
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
Povedlo se. Kromě výchozích StorageClass mám svojí novou.
kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Delete Immediate true 112m
azurefile-premium kubernetes.io/azure-file Delete Immediate true 112m
default (default) kubernetes.io/azure-disk Delete Immediate true 111m
managed-csi-standard-ssd disk.csi.azure.com Delete Immediate true 18s
managed-premium kubernetes.io/azure-disk Delete Immediate true 111m
Základní vytvoření disku s Persistent Volume Claim
Vytvořme teď Persistent Volume Claim (detaily konceptu jsem rozebíral minule), tedy žádost o disk. Ten nám na pozadí vytvoří samotný disk (objekt Persistent Volume) v Azure.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-csi-standard-ssd
Dle CLI Volume existuje.
kubectl describe pvc/pvc-azuredisk
Name: pvc-azuredisk
Namespace: default
StorageClass: managed-csi-standard-ssd
Status: Bound
Volume: pvc-ba46140c-1ed3-4666-bed8-5ea428945d57
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
volume.beta.kubernetes.io/storage-provisioner: disk.csi.azure.com
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 1Gi
Access Modes: RWO
VolumeMode: Filesystem
Mounted By: <none>
Events: <none>
kubectl get pv pvc-ba46140c-1ed3-4666-bed8-5ea428945d57
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-ba46140c-1ed3-4666-bed8-5ea428945d57 1Gi RWO Delete Bound default/pvc-azuredisk managed-csi-standard-ssd 146m
Podívám se do Azure a disk tam najdu. Je v nepřipojeném stavu, protože ještě nemám žádný Pod, který ho používá (samozřejmě v případě Azure Disk tento není připojen přímo do Podu, ale do Nodu, na kterém Pod běží).
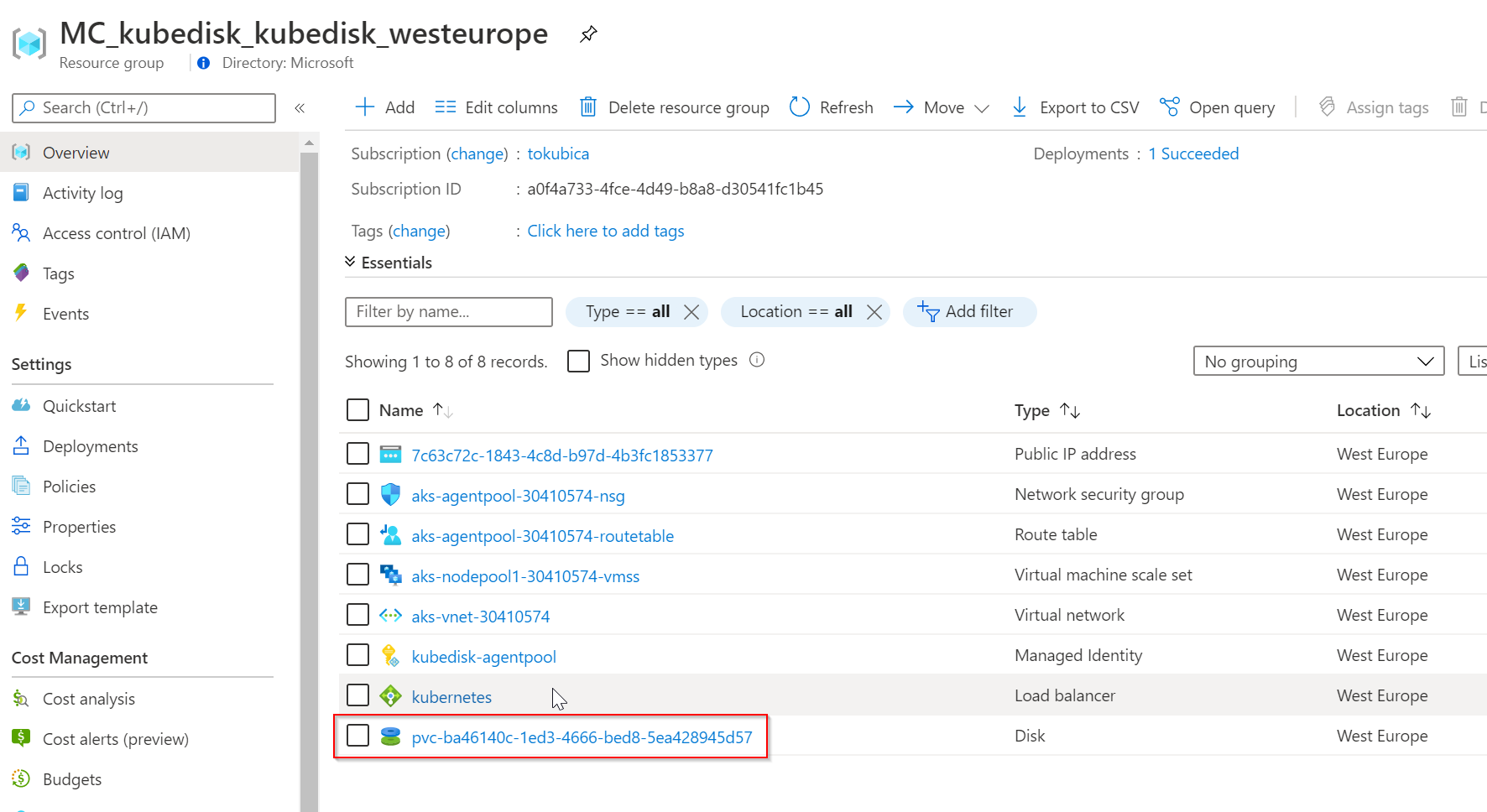
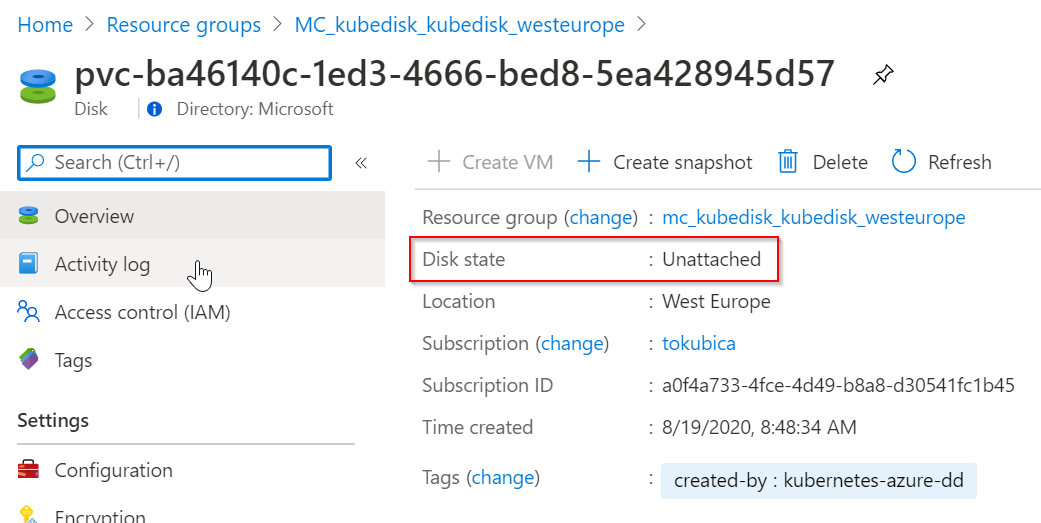
Všechno vypadá dobře, až na jednu drobnost. Disk je v Availability Zone 2 a to jsem nikde neurčoval.
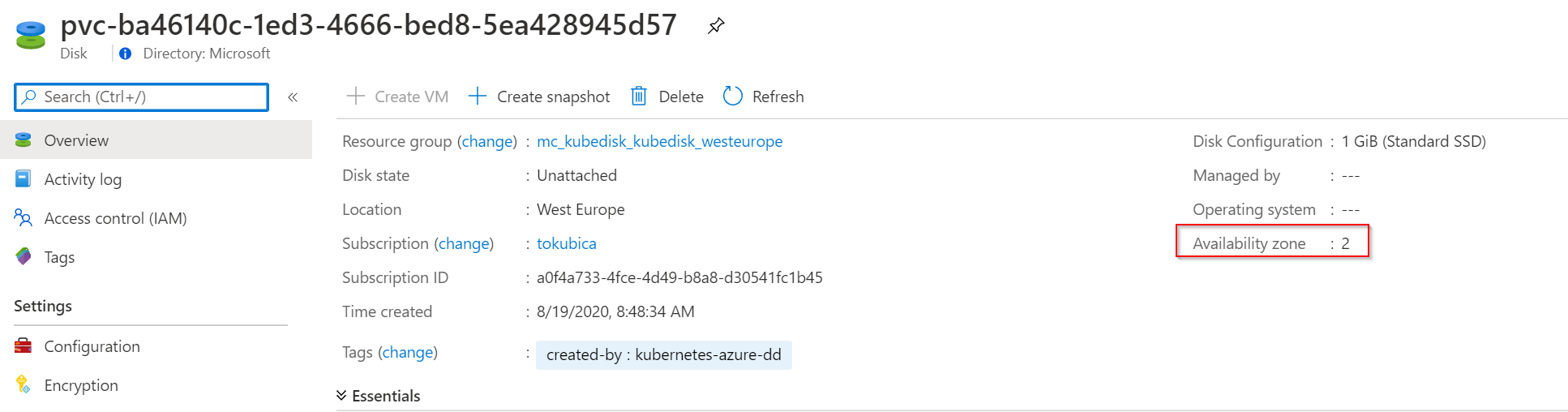
Tohle v mém případě není dobré. Pokud udělám druhý disk a plánuju nad tím běžet databázi s replikací dat, potřebuju přece, aby to bylo v jiných zónách. Tohle nesmí být náhodný proces. Režim, který jsem zvolil je tedy zcela v pořádku, pokud je vaše AKS v jedné zóně dostupnosti, ale já ho dal do dvou. To potřebujeme změnit.
Možná vás napadne fajn, někam se to ručně dopíše, ne? To není úplně pohodlné a dobře přenositelné mezi prostředími. Pro Pody existuje koncept, jak je zaručeně rozhodit mezi zóny dostupnosti - Pod Antiafinity, ale pro disky ne. Navíc můžu mít dvě instance aplikace a přitom mám tři zóny dostupnosti - to mám všechno dělat ručně, když ještě nevím, kde aplikace poběží? To nedává smysl. Chtělo by to, aby se zóna pro disk zvolila až v okamžiku, kdy scheduler rozhodne o aplikační komponentě (Podu) a jeho umístění. Potřebujeme tedy disk vytvořit opožděně, ne dopředu. Tedy teprve až ho bude Pod potřebovat ho vytvořit tam, kde ten Pod je. Samozřejmě pak ho nikam šoupat nebudeme, jde o iniciální řešení (btw. disky samozřejmě můžeme udělat i ručně v Azure a jen je připojovat, ale o tom později).
PVC a StorageClass smažu a změním její nastavení volumeBindingMode.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-csi-standard-ssd
provisioner: disk.csi.azure.com
parameters:
skuname: StandardSSD_LRS
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
Pokud teď vytvořím PVC, v jeho událostech najdu zprávu o tom, že se samotným vytvořením disku se čeká na topologickou informaci, tedy prvního konzumenta Pod, díky kterému pochopíme v jaké zóně disk udělat.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal WaitForFirstConsumer 0s (x4 over 36s) persistentvolume-controller waiting for first consumer to be created before binding
Pod bude ve stavu Pending a na pozadí se PVC postará o vytvoření Persistent Volume, tedy Azure připojí na Kubernetes Node, na kterém má běžet Pod a ten pak může nastartovat.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal WaitForFirstConsumer 2m8s (x42 over 12m) persistentvolume-controller waiting for first consumer to
be created before binding
Normal Provisioning 14s disk.csi.azure.com_aks-nodepool1-30410574-vmss000002_9606c1b4-1f1c-4930-8782-0ae950414609 External provisioner is provisioning volume for claim "default/pvc-azuredisk"
Normal ProvisioningSucceeded 12s disk.csi.azure.com_aks-nodepool1-30410574-vmss000002_9606c1b4-1f1c-4930-8782-0ae950414609 Successfully provisioned volume pvc-6720e448-fcf8-4261-b4ba-970a55ce556f
Toto opožděné vytvoření disku teprve až bude jasné, v které zóně Pod poběží, nám umožní nasadit stavový zónově redundantní cluster naší aplikace.
Skutečně stavová aplikace se StatefulSet
Vyzkoušíme si teď stavovou aplikaci, jak reaguje na havárii a proč pro potřebu vysoké dostupnosti bychom měli mít softwarovou repliku, třeba AlwaysOn se SQL kontejnery. V mém clusteru jsou 4 nody rozprostřené přes dvě zóny dostupnosti.
kubectl get nodes -L failure-domain.beta.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION ZONE
aks-nodepool1-30410574-vmss000000 Ready agent 8h v1.18.6 westeurope-1
aks-nodepool1-30410574-vmss000001 Ready agent 8h v1.18.6 westeurope-2
aks-nodepool1-30410574-vmss000002 Ready agent 8h v1.18.6 westeurope-1
aks-nodepool1-30410574-vmss000003 Ready agent 8h v1.18.6 westeurope-2
Jak si to vyzkoušíme? Nasadíme “aplikaci” NGINX, tedy webový server, kdy jeho obsah (stránka) bude právě na perzistentním volume a bude se do ní každou vteřinu připisovat obsah. Díky tomu můžeme do instance šťouchnout a ubezpečit se, že o už zapsaná data nepřijdeme a také krásně uvidíme ty vteřiny, ve kterých se nic nezapsalo (takže změříme čas na vyřešení havárie jedné instance). V tomto příkladě neděláme replikaci dat, to není účelem ukázky, tak si to jen představte.
Použiji tedy StatefulSet, Pody s webem a skriptem pro zapisování a také šablonu pro PVC. To je zásadní rozdíl oproti Deploymentu. Ten by každý Pod namířil na stejnou storage (což u Azure Disk jde s pohledu mutli-reader jen v rámci preview a jen v jedné zóně), třeba právě sdílený obsah pro instance webové farmy. My ale reprezentujeme stavovou aplikaci, třeba SQL, takže každá instance by měla mít svou storage a AlwaysOn zajišťuje konzistentní replikaci dat mezi nimi. To je jeden z několika důvodů pro StatefulSet.
Zbývá dořešit ještě jednu věc. AKS bude u Deployment preferovat rozházení replik do zón dostupnosti, ale u stavové aplikace tohle chci mít rozhodně sám pod kontrolou - tedy použít pod anti-affinitu (takže už jsem o tom na tomto blogu psal v článku o pokročilém nastavení scheduleru). Ta má dvě formy - predicate (required neboli hard neboli podmínka nutná) a priority (prefered neboli soft). U bezestavových aplikací, kdy se rozkládá zátěž na všechny instance, dává smysl z pohledu zón jít po preferenci. Chci 6 replik a preferuji je roztažené přes všechny zóny dostupnosti, takže třeba když používám dvě zóny, tak variantu 3+3. Ale co když v nodech v jedné ze zón už nemám místo? Nevadí, tak tedy 4+2 a nebo klidně i 6+0. Preferuji to jinak, ale když není zbytí, fajn - pořád lepší, než mít replik málo a nechat uživatele trpět na výkonu. U stavové služby to ale dost možná chci jinak. Mám tu 2 nebo 3 instance, ale stejně jen jedna je zapisovací (pokud nejde o nějaký eventuálně konzistentní multi-write scénář typu Cassandra - všechny relační databáze nebo třeba Mongo či Etcd se budou chovat takhle). Co když se nepovede dát to do všech zón a volno je jen v jedné, mám klidně holt dát všechny tři repliky do jediné zóny? Určitě ne - výkon tady pro mě není hlavní kritérium, já musím řešit dostupnost. Žádné ústupky, hoď raději “error” (třeba se na to konto probere cluster autoscaler a místo mi za pár minut vyrobí). Půjdu tedy do varianty required - hard omezení. Nezapomeňte totiž ještě na jednu klíčovou vlastnost dnešního Kubernetes - nedělá rebalancing! Všechna tato pravidla se aplikují jen při schedulingu a dokud to nepřenasadíte nebo Pody nepopadají, nikdo se k tomu nebude vracet (a zůstane to neoptimální - proto u StatefulSetu jedu raději na přísnost a vyhození chyby).
Tahle tedy náš objekt vypadá:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
labels:
app: nginx
spec:
serviceName: nginx-statefulset
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- image: nginx
name: nginx-azuredisk
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azuredisk
mountPath: "/usr/share/nginx/html"
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 16M
limits:
cpu: 500m
memory: 64M
volumeClaimTemplates:
- metadata:
name: azuredisk
annotations:
volume.beta.kubernetes.io/storage-class: managed-csi-standard-ssd
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Nasadím a podívám se. Měl bych mít dvě repliky, každou nejen na jiném nodu, ale na nodech, které mají odlišný label failure-domain.beta.kubernetes.io/zone (tedy zónu dostupnosti). Určitě najdu i svoje dva PVC a PV.
wsl$ k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-statefulset-0 1/1 Running 0 79s 10.244.3.9 aks-nodepool1-30410574-vmss000002 <none> <none>
nginx-statefulset-1 1/1 Running 0 54s 10.244.2.3 aks-nodepool1-30410574-vmss000003 <none> <none>
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
azuredisk-nginx-statefulset-0 Bound pvc-359bd055-a258-487b-ad56-24548002e152 1Gi RWO managed-csi-standard-ssd 109s
azuredisk-nginx-statefulset-1 Bound pvc-7b5b3815-890a-4343-86b3-873ce9c40d29 1Gi RWO managed-csi-standard-ssd 84s
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-359bd055-a258-487b-ad56-24548002e152 1Gi RWO Delete Bound default/azuredisk-nginx-statefulset-0 managed-csi-standard-ssd 2m4spvc-7b5b3815-890a-4343-86b3-873ce9c40d29 1Gi RWO Delete Bound default/azuredisk-nginx-statefulset-1 managed-csi-standard-ssd 99s
Zkusme to teď trochu potrápit a zatím budeme docela hodní. Jeden z nodů necháme vypustit a s co nejmenším výpadkem odstěhujeme Pod jinam. U Deploymentu a bezestavové služby brnkačka. Zabít tady, pustit jiný vedle a frčíme. Tentokrát ale máme na noze uvázaný state ve formě dat na disku, takže nestačí udělat to celé znova, ale ta data tam musíme dostat, tedy disk odpojit ze stávajícího Node, připojit na nějaký jiný a na něm Pod rozjet.
kubectl drain aks-nodepool1-30410574-vmss000002 --ignore-daemonsets --delete-local-data
Po nějaké době se mi stěhování provedlo.
wsl$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-statefulset-0 1/1 Running 0 2m22s 10.244.0.8 aks-nodepool1-30410574-vmss000000 <none> <none>
nginx-statefulset-1 1/1 Running 0 6m47s 10.244.2.3 aks-nodepool1-30410574-vmss000003 <none> <none>
Jak dlouho byl Pod mimo hru? Zůstala tam moje data? Stačí se kouknout na webovou stránku a budeme mít jasno. Svoje data tam vidím a nějakých 40 vteřin byla aplikace mimo hru. Je to hodně nebo málo? Těžko říct, každopádně tohle vás čeká u každého upgradu clusteru nebo OS nodu pokud vyžaduje restart. Co když je control plane Azure zrovna o něco zatíženější, image je velký a na cílovém nodu ještě není a musí se stáhnout a tak podobně. Tahle doba nemá SLA, není predikovatelná a klidně to mohou být minuty dvě. A to mluvíme o plánované situaci, k neplánované se ještě dostaneme. Pro maximální dostupnost je tedy zřejmé, že byste měli v software replikovat data na jinou instanci a uživatele na ni přepnout rychleji.
kubectl port-forward pod/nginx-statefulset-0 12345:80
...
Wed Aug 19 13:55:04 UTC 2020
Wed Aug 19 13:55:05 UTC 2020
Wed Aug 19 13:55:06 UTC 2020
Wed Aug 19 13:55:07 UTC 2020
Wed Aug 19 13:55:08 UTC 2020
Wed Aug 19 13:55:47 UTC 2020
Wed Aug 19 13:55:48 UTC 2020
Wed Aug 19 13:55:49 UTC 2020
...
Ukažme si něco dalšího - vystěhujme ještě druhý node v této zóně.
kubectl drain aks-nodepool1-30410574-vmss000000 --ignore-daemonsets --delete-local-data
Takhle teď vypadají moje Pody a nelepší se to.
wsl$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-statefulset-0 0/1 Pending 0 24s <none> <none> <none> <none>
nginx-statefulset-1 1/1 Running 0 8m47s 10.244.2.3 aks-nodepool1-30410574-vmss000003 <none> <none>
Co se stalo? No jasně - disky jsou jen v jedné zóně dostupnosti, já už v ní žádné nody nemám, takže jsme dohráli.
kubectl describe pod nginx-statefulset-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 62s (x2 over 62s) default-scheduler 0/4 nodes are available: 2 node(s) had volume node affinity conflict, 2 node(s) were unschedulable.
Teď se dostaneme k tomu hlavnímu důvodu, proč singleton nemůžete v realitě použít pokud máte velké požadavky na dostupnost. Co se stane, když vypadne Node ošklivě, tedy prostě se odpojí od control plane. Vrátil jsem nody zpět přes kubectl uncordon a zopakuji test s tím, že tentokrát v Azure vypnu VM konkrétního Node, takže Kubernetes to bere jako zmizení. Co se bude dít vás možná překvapí, ale když to promyslíte tak by vlastně nemělo.
Deployment, tedy bezestavové aplikace, udělá to, že jakmile Node přestane odpovídat začne běžet perioda, kdy to control plane ignoruje. Důvodem je, aby nějaké drobné zaškobrtnutí nezpůsobilo velké přerovnávání, což by mohlo napáchat víc škody než užitku. Nezapomeňte, že to, že control plane nevidí Node vůbec neznamená, že tento nefunguje a Pody na něm neběží! Ty totiž control plane nepotřebují, pojedou normálně dál. Výchozí nastavení je počkat 5 minut, ale jde o Toleration, kterou můžete v definici Deploymentu upravit pro svoje potřeby (třeba zkrátit). Ale výchozí hodnota dává velký smysl. Po těch pěti minutách (nebo dříve, pokud chcete) control plan nastaví stav u Podu na Terminating a v ten okamžik vytvoří jiný někde jinde. To je důležité - už ve stavu Terminating se vytváří nový! Terminating není Terminated, je to jen přání k ukončení, ale ještě mi Node nereportoval, že to tak skutečně je (nezapomeňte - pokud Node nevidí control plane, nechá všechno normálně puštěné). Potenciálně tedy může ve skutečnosti Pod běžet dvakrát. Pro bezestavové věci žádný problém.
Takové chování ale u stavé aplikace není přístupné. Dvě instance píšící do jedněch dat aniž by o sobě věděli = katastrofa a ztráta konzistence dat. Dvě instance každá s jinými daty a obě dostupné pro uživatele = rovněž katastrofa a nekonzistence (různá data v obou instancích, např. dvojité utracení stejné dvacetikoruny). StatefulSet tedy velmi správně nepřipustí takové riziko. To znamená, že pokud vám vypadne Node tak váš Pod zůstane ve stavu Terminating a jinde se nevytvoří, dokud nebude jistota, že opravdu neběží - a to by musel říct Node, který ale už neexistuje. Přesně tak, samo se to by default neopraví. Musíte ručně na svoje triko Pod natvrdo odmazat z control plane (s –force přepínačem) i bez potvrzení z Node. Pokud jde o vysokovu dostupnost, jste nahraní. Proto potřebujete udělat aplikační/databázový cluster.
Dá se s tím něco dělat? Trochu, ale nedporučuji:
- Můžete nastavit toleraci na node.kubernetes.io/not-ready a node.kubernetes.io/unschedule s periodou 10 vteřin, což odstraní 5 minut čekání, jestli se Node náhodou nevzpamatuje. Zvyšujete ale riziko, že Node se jen zaškobrtnul a ve svém Kubernetu “děláte vlny”.
- Pod ve stavu Terminating čeká na potvrzení ukončení. To můžete vypnout tak, že u Podu nastavíte terminationGracePeriodSeconds na 0. To má ale značné konsekvence. V podstatě tím říkáte, že při upgradování clusteru a nutnosti pustit Pod jinde se rovnou natvrdo ukončí místo SIGTERM, což může vést k poškození dat. Tak nevím, jestli tohle chcete riskovat.
- Následně začne CSI driver odmontovávat disk, ale pokud VM už vůbec neexistuje, nepůjde to a vytimeoutuje za 6 minut. S tím se aktuálně nedá nic dělat (ale pracuje se na tom jak z pohledu driveru tak Kubernetes uvažuje o přidání nového taintu pro Node - Shutdown).
- Pak už se nahodí jinde a automaticky.
Už jsem to říkal - state není jednoduchá věc. Předpoklady co máte z běhu stateless aplikací nebo těch se sdílenou storage tady neplatí. Proto:
- Singleton se reálně nedá použít s vysokou dostupností, protože StatefulSet bude bránit konzistenci dat a Deployment zas naopak ne a to nedopadne dobře (například u Azure Disk vám nahozený kontejner stejnak hodí chybu, protože disk už je připojen jinam). K tomu přidejte fakt, že disk je jen v jedné zóně dostupnosti.
- Řešením mohou být instance koukající do sdílené storage například s využitím Azure Files jako volume (o tom příště), ale to má také své limity, které si rozebereme (neškálujete výkon s čtecí replikou, je tu riziko při poškození datové struktury v důsledku havárie instance apod.). Nicméně pokud musíte jít singletonem, je to asi lepší volba (příště rozebereme).
- Dobrá cesta tedy je StatefulSet, instance a disky v každé zóně, softwarová synchronizace typu AlwaysOn v SQL.
Takže znova přípomínám - neřešte to, tady jde o vaše data a platformní služby vám dají klidně 99,995% SLA a bez práce. Ale pokud vás trápí otázka jak Azure Arc for Data Services nabídne vysoce redundantní SQL a PostgreSQL ve vašem vlastním DC ve vašem Kubernetes, tak vidíte, že prostředky k tomu jsou. Jen to není jednoduché vymyslet a provozovat, ale v cloudu to řeší PaaS a v on-prem v budoucnu třeba Azure Arc.
Klonování, změna velikosti, snapshoty
Kubernetes API dnes podporuje i základní storage operace s volume. Principiálně je z nich cítit, že jsou takové “jiné”, závání imperativním chováním a do krásného světa, kde je všechno deklarováno a nezáleží na časování ani pořadí se občas trochu nehodí. Ale tak to zkrátka je a kdo state v Kubernetes chce používat, využije jich.
Klonování
Klonování Volume je výborná věc. Když vytváříte PVC můžete si jako jeho zdroj odkázat jiné PVC a získat tak jeho kopii. Zdrojové PVC ani nemusí být odpojeno, ale nezapomeňte, že pak dostáváte kopii v crash-consistent stavu, tedy nemáte garantovánu aplikační konzistenci (databáze vám třeba nemusí nastartovat a bude se chtít opravovat).
Vytvořím si Pod s PVC.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-csi-standard-ssd
---
kind: Pod
apiVersion: v1
metadata:
name: nginx1
spec:
containers:
- image: nginx
name: nginx
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azuredisk
mountPath: "/usr/share/nginx/html"
volumes:
- name: azuredisk
persistentVolumeClaim:
claimName: pvc-azuredisk
Funguje a ukládá data.
kubectl port-forward pod/nginx1 12345:80
curl 127.0.0.1:12345
...
Thu Aug 20 04:19:41 UTC 2020
Thu Aug 20 04:19:42 UTC 2020
Thu Aug 20 04:19:43 UTC 2020
Thu Aug 20 04:19:44 UTC 2020
Thu Aug 20 04:19:45 UTC 2020
Thu Aug 20 04:19:46 UTC 2020
Thu Aug 20 04:19:47 UTC 2020
Thu Aug 20 04:19:48 UTC 2020
Thu Aug 20 04:19:49 UTC 2020
Teď si pro účely třeba troubleshootingu chci vytvořit jiný Pod, který si vezme kopii disku tohoto produkčního.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk-clone
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-csi-standard-ssd
dataSource:
kind: PersistentVolumeClaim
name: pvc-azuredisk
---
kind: Pod
apiVersion: v1
metadata:
name: nginx2
spec:
containers:
- image: nginx
name: nginx
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azuredisk
mountPath: "/usr/share/nginx/html"
volumes:
- name: azuredisk
persistentVolumeClaim:
claimName: pvc-azuredisk-clone
Skvělé. Když se podívám na webovku uvidím jak historická data tak samozřejmě i svoje nová.
kubectl port-forward pod/nginx1 12345:80
curl 127.0.0.1:12345
hu Aug 20 04:19:56 UTC 2020
Thu Aug 20 04:19:57 UTC 2020
Thu Aug 20 04:19:58 UTC 2020
Thu Aug 20 04:19:59 UTC 2020
Thu Aug 20 04:20:00 UTC 2020
Thu Aug 20 04:20:01 UTC 2020
[tady konci puvodni data]
Thu Aug 20 04:21:03 UTC 2020
Thu Aug 20 04:21:04 UTC 2020
Změna velikosti
Azure Disk CSI driver nepodporuje změnu velikosti v online režimu, musíme tedy disk odepnout. To znamená, že nestačí jen poslat změnu PVC, ta se nikdy neprovede. Musíme tedy bohužel být imperativní a dodržet pořadí - vypnout Pod, zvětšit disk, zapnout Pod.
Tady je pvc1G.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-csi-standard-ssd
A tady pod.yaml
kind: Pod
apiVersion: v1
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azuredisk
mountPath: "/usr/share/nginx/html"
volumes:
- name: azuredisk
persistentVolumeClaim:
claimName: pvc-azuredisk
Aplikujeme a podíváme se do souborového systému na jeho velikost.
kubectl apply -f pvc1G.yaml
kubectl apply -f pod.yaml
kubectl exec -it nginx -- df -h /usr/share/nginx/html
Filesystem Size Used Avail Use% Mounted on
/dev/sdc 976M 2.6M 958M 1% /usr/share/nginx/html
Připravím si modifikovaný soubor s PVC o velikosti 5G.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: managed-csi-standard-ssd
Pod zrušíme, disk zvětšíme a zase nahodíme.
kubectl delete -f pod.yaml
kubectl apply -f pvc5G.yaml
kubectl apply -f pod.yaml
kubectl describe pvc pvc-azuredisk
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal WaitForFirstConsumer 15m (x2 over 15m) persistentvolume-controller waiting for first consumer to be created before binding
Normal ExternalProvisioning 15m persistentvolume-controller waiting for a volume to be created, either by external provisioner "disk.csi.azure.com" or manually created by system administrator
Normal Provisioning 15m disk.csi.azure.com_aks-nodepool1-30410574-vmss000003_ae8afc94-3850-4752-b852-bf4e49dfe5ea External provisioner is provisioning volume for claim "default/pvc-azuredisk"
Normal ProvisioningSucceeded 15m disk.csi.azure.com_aks-nodepool1-30410574-vmss000003_ae8afc94-3850-4752-b852-bf4e49dfe5ea Successfully provisioned volume pvc-2fce3491-e346-4af4-8e15-51761ffceeb1
Warning ExternalExpanding 5m10s volume_expand Ignoring the PVC: didn't find a plugin capable of expanding the volume; waiting for an external controller to process this PVC.
Normal Resizing 5m10s external-resizer disk.csi.azure.com External resizer is resizing volume pvc-2fce3491-e346-4af4-8e15-51761ffceeb1
Normal FileSystemResizeRequired 5m7s external-resizer disk.csi.azure.com Require file system resize of volume on node
Normal FileSystemResizeSuccessful 7s kubelet, aks-nodepool1-30410574-vmss000000 MountVolume.NodeExpandVolume succeeded for volume "pvc-2fce3491-e346-4af4-8e15-51761ffceeb1"
kubectl exec -it nginx -- df -h /usr/share/nginx/html
Filesystem Size Used Avail Use% Mounted on
/dev/sdc 4.9G 4.1M 4.9G 1% /usr/share/nginx/html
Snapshoty
Z předchozích ukázek tu mám běžící NGINX s PVC. Vyzkoušíme si na něm teď udělat snapshot.
Uděláme si “snapshot třídu” a vytvoříme ho.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshotClass
metadata:
name: csi-azuredisk-vsc
driver: disk.csi.azure.com
deletionPolicy: Delete
parameters:
incremental: "true"
---
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: azuredisk-volume-snapshot
spec:
volumeSnapshotClassName: csi-azuredisk-vsc
source:
persistentVolumeClaimName: pvc-azuredisk
Jde skutečně o snapshot v Azure, jak můžeme vidět v GUI.
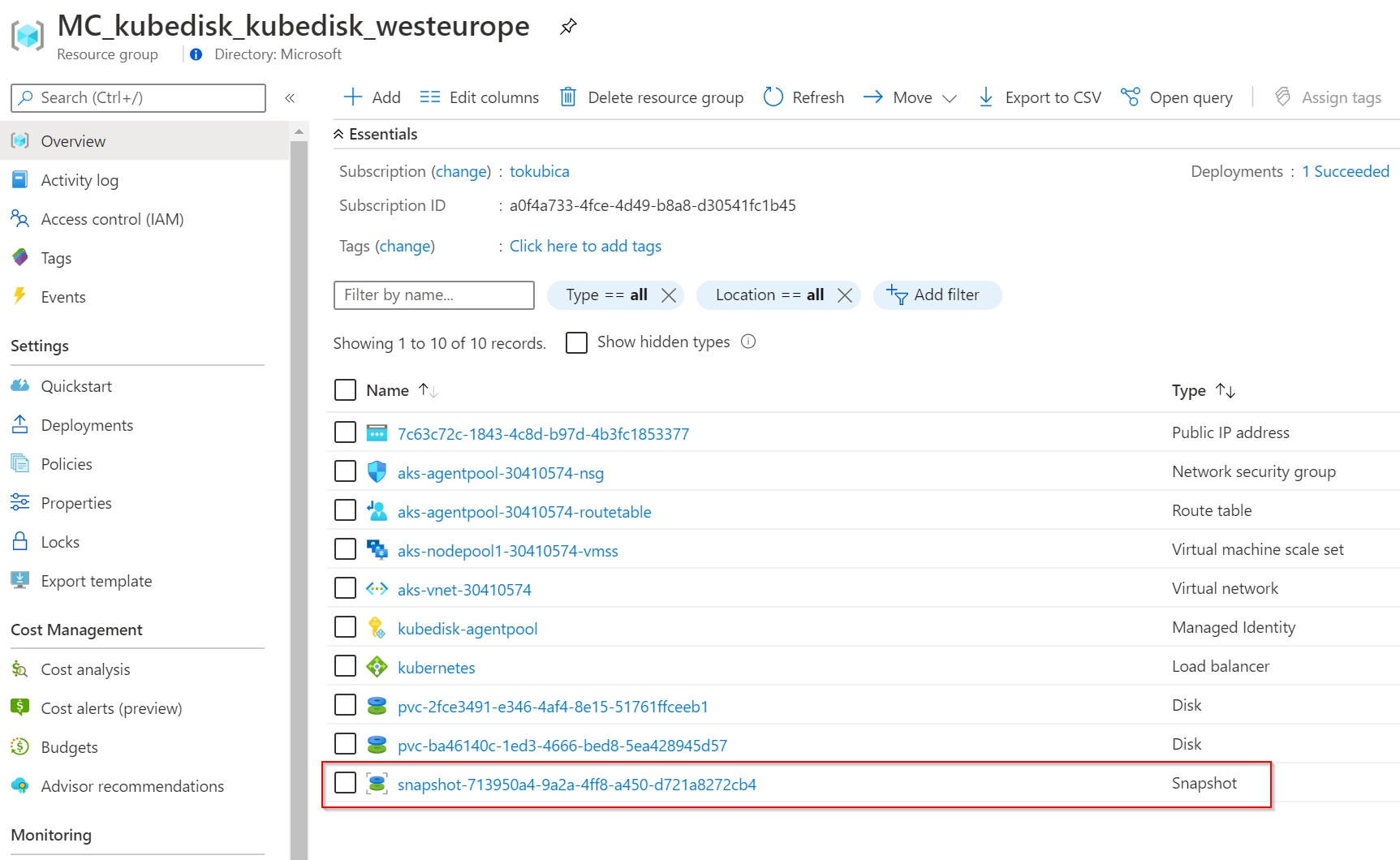
Snapshot na rozdíl od disku může být zónově redundantní, najdeme ho tedy v jakékoli zóně a přestojí i kompletní výpadek zóny.
Pokud tedy neumíte data replikovat aplikačně jste schopni si je přetáhnout z jedné zóny do druhé přes snapshot, který je vidět ve všech. Pokud byste ho chtěli do jiného regionu, tak i to lze udělat, nicméně musíte ho tam nakopírovat (nabo použít Azure Site Recovery pro automatickou replikaci disků).
Vytvoření PVC ze snapshotu je podobné jako u klonu, odkážeme se na něj.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk-fromsnap
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: managed-csi-standard-ssd
dataSource:
name: azuredisk-volume-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
---
kind: Pod
apiVersion: v1
metadata:
name: nginx2
spec:
containers:
- image: nginx
name: nginx
command:
- "/bin/sh"
- "-c"
- nginx & while true; do echo $(date) >> /usr/share/nginx/html/index.html; sleep 1; done
volumeMounts:
- name: azuredisk
mountPath: "/usr/share/nginx/html"
volumes:
- name: azuredisk
persistentVolumeClaim:
claimName: pvc-azuredisk-fromsnap
Blokové zařízení
Persistent Volume v Kubernetes funguje jako souborový systém. Disk se připojí k Node a ten ho naformátuje (ve výchozím stavu ext4, ale u CSI driveru máte na výběr i ext2, ext3 nebo xfs). Co když ale vaše aplikace opravdu potřebuje něco speciálního a chce vidět disk jako skutečné blokové zařízení? Například chce použít bfs, btrfs či zfs a má k tomu nějaký dobrý důvod nebo dokonce něco úplně proprietárního? I to je s PVC a CSI drivery pro Azure možné.
Vytvoříme si speciální typ PVC a v našem Podu nebudeme mapovat Volume do souborového systému, ale přidáme jako zařízení.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-azuredisk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
volumeMode: Block
storageClassName: managed-csi-standard-ssd
---
kind: Pod
apiVersion: v1
metadata:
name: nginx-raw
spec:
containers:
- image: nginx
name: nginx
volumeDevices:
- name: azuredisk
devicePath: /dev/xvda
volumes:
- name: azuredisk
persistentVolumeClaim:
claimName: pvc-azuredisk
Zařízení v Podu skutečně vidím a můžeme na něj psát nízkoúrovňově.
kubectl exec -ti nginx-raw -- bash
root@nginx-raw:/# ls /dev/x*
/dev/xvda
root@nginx-raw:/# dd if=/dev/zero of=/dev/xvda bs=1024k count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 0.0743379 s, 1.4 GB/s
Jsme na konci dnešního hutného tématu. Shrnutí?
- Pokaždé když to jde použijte platformní službu v Azure, po všech stránkách vás to vyjde lépe.
- Pokud vyloženě potřebujete běžet v jiném prostředí, než Azure, sledujte Azure Arc for Data Services, kdy pro vás Azure může zajistit SQL nebo PostgreSQL cloudovým způsobem, ale ve vašem clusteru.
- Pokud už musíte state uvnitř mít (například jste nenašli platformní službu, který splní vaše požadavky) a stačí vám sdílené řešení (nebo nemůžete jinak než použít singleton), použijte souborový systém typu Azure Files (premium verze nabízí i velmi slušný výkon) či Azure NetApp Files (výkonnostně ještě výš).
- Jestli skutečně potřebujete disky (pořádný HA cluster, raw zařízení, aplikace nekompatibilní s CIFS, potřebujete UltraSSD výkony), jde to, ale dobře to promyslete. Zatím používejte nativní in-tree storage implementaci, ale jestli přemýšlíte dopředu, klidně zkoušejte CSI (dnes jsou funkčně shodné), který bude default od 1.21 a dá se iterovat bez změny verze Kubernetes.
Příště se podíváme na state, který třeba nemá zas tak brutální nároky na konzistenci a replikaci. Možná zkrátka váš kód očekává file system a potřebujeme mu namapovat Azure Files nebo Azure Blob, aby data zpracovával. Nebo jsou to sdílené mutlimediální soubory, které vaše webová farma potřebuje a z nějakého důvodů je nechcete či nemůžete vystavit přímo ze storage nebo CDN. V takových případech nebude špatné vaše instance prostě namířit na vzdálenou souborovou storage a hotovo a PVC/PV může být způsob jak to udělat, aniž by to aplikace poznala a musela se upravovat. Můžete to být i dobré pro “skoro-HA pro chudé” se singletonem nebo nějaké metody vícero instancí koukajících do stejných dat (řekněme “HA classic” vs. dnes oblíbenější shared-nothing architektura).