Před nějakou dobou jsem popsal svůj přechod z Wordpress na statický web kenerovaný Jekyllem servírovaný z kombinace Azure Storage a Azure CDN. Náklady na web v Azure jsem dostal pod 2 Eura, ale přišel jsem o schopnost vyhledávání na webu. To typicky vyžaduje backend a to pro mě řešil Wordpress. Problém, abych stále neměl žádné servery, jsem se rozhodl vyřešit s Azure Cognitive Search. Výsledek rozhodně není bůh ví jak krásný a zdaleka jsem z něj nedostal všechno, co tato služba umí. Ale moje základní požadavky jsem si splnil. Jak?
Azure Cognitive Search
Tato služba vypadá velmi zajímavě. Dokáže natahávat různé datové zdroje a tyto indexovat a umožňovat nad nimi dělat sofistikovaná vyhledávání. Může mít různé atributy a typy indexů včetně těch hodně chytrých a nabízí tak například klasický search, ale i sémantické vychytávky včetně češtiny nebo funkci pro implementaci autocomplete (napovídá, když vypisujete do políčka). Datové zdroje mohou být různé databáze jako je Azure SQL, Cosmos DB nebo Blob Storage a pak si Search tahá data sám, ale pokud ho integrujete push způsobem přes API, jste schopni do něj dostat naprosto cokoli. Provede vám i indexaci souborových formátů typu DOC nebo PDF a ve spolupráci s ML službami udělá třeba OCR, kategorizaci obrázku a tak podobně.
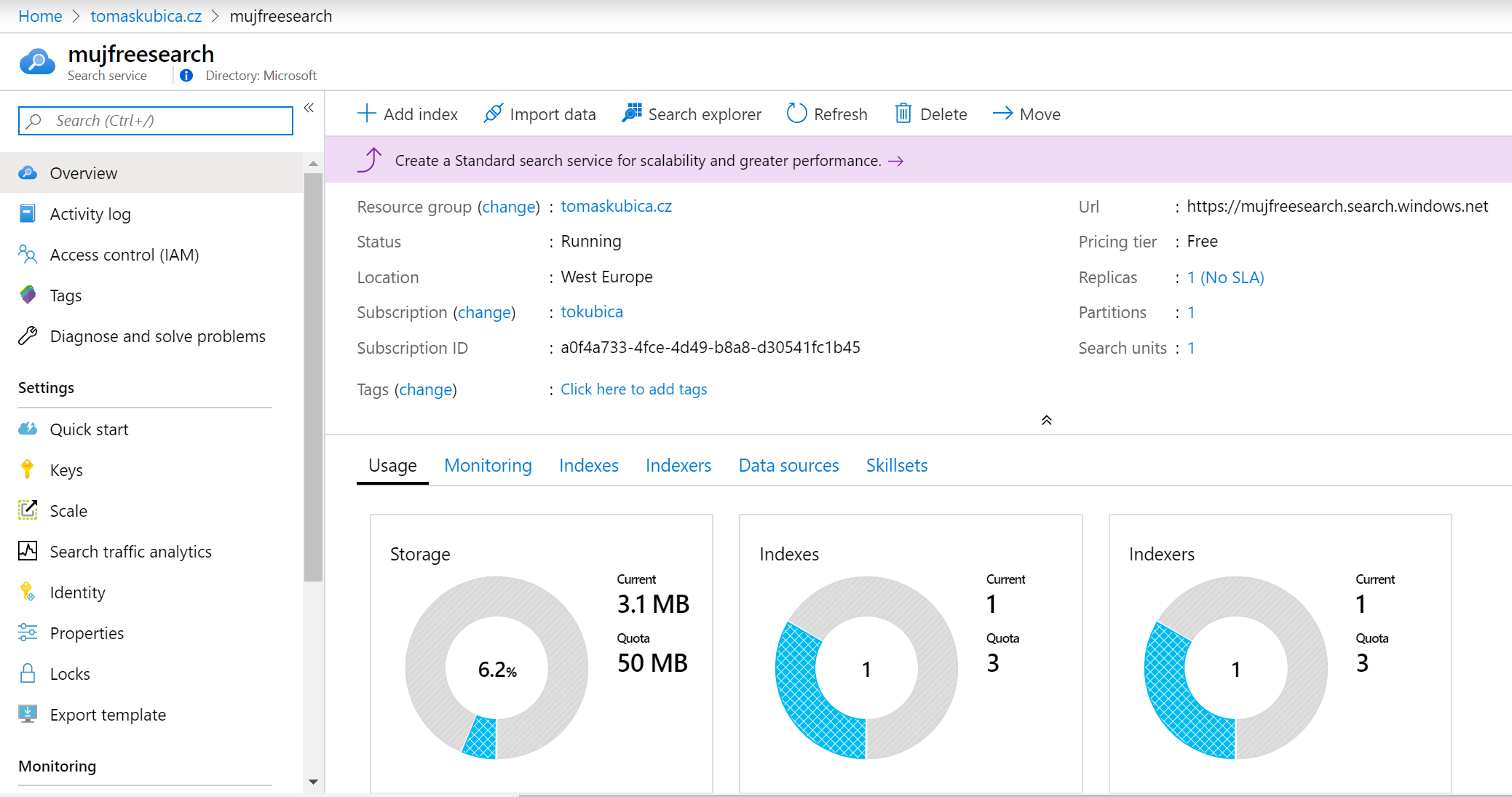
Můj statický blog a Azure Cognitive Search
Připomínám, že tento blog je plně statický. Obsah generuji softwarem Jekyll a ten nahrávám do Azure Blob Storage, která může fungovat jako “serverless web server” pro statický obsah. Abych mohl použít svou vlastní doménu a získal certifikát, mám před tím Azure CDN.
Nevýhodou je, že nemám funkci vyhledávání a tu musím udělat přímo v browseru. Javascript v něm běžící může využít Azure Cognitive Search a přes něj to udělám.
Co se týče zdroje dat, nejlepší by bylo, abych v rámci buildu blogu přes Jekyll zavolal Search napřímo a narkmil ho daty. Díky tomu bych tam mohl přidat políčka jako datum uvedení článku, ale nemám čas to moc řešit, tak jsem na začátek chtěl jít jednodušší cestou. Napojil jsem tedy Azure Cognitive Search přímo na blob storage a namířil ho do adresářů, ve kterých HTML stránky jsou.
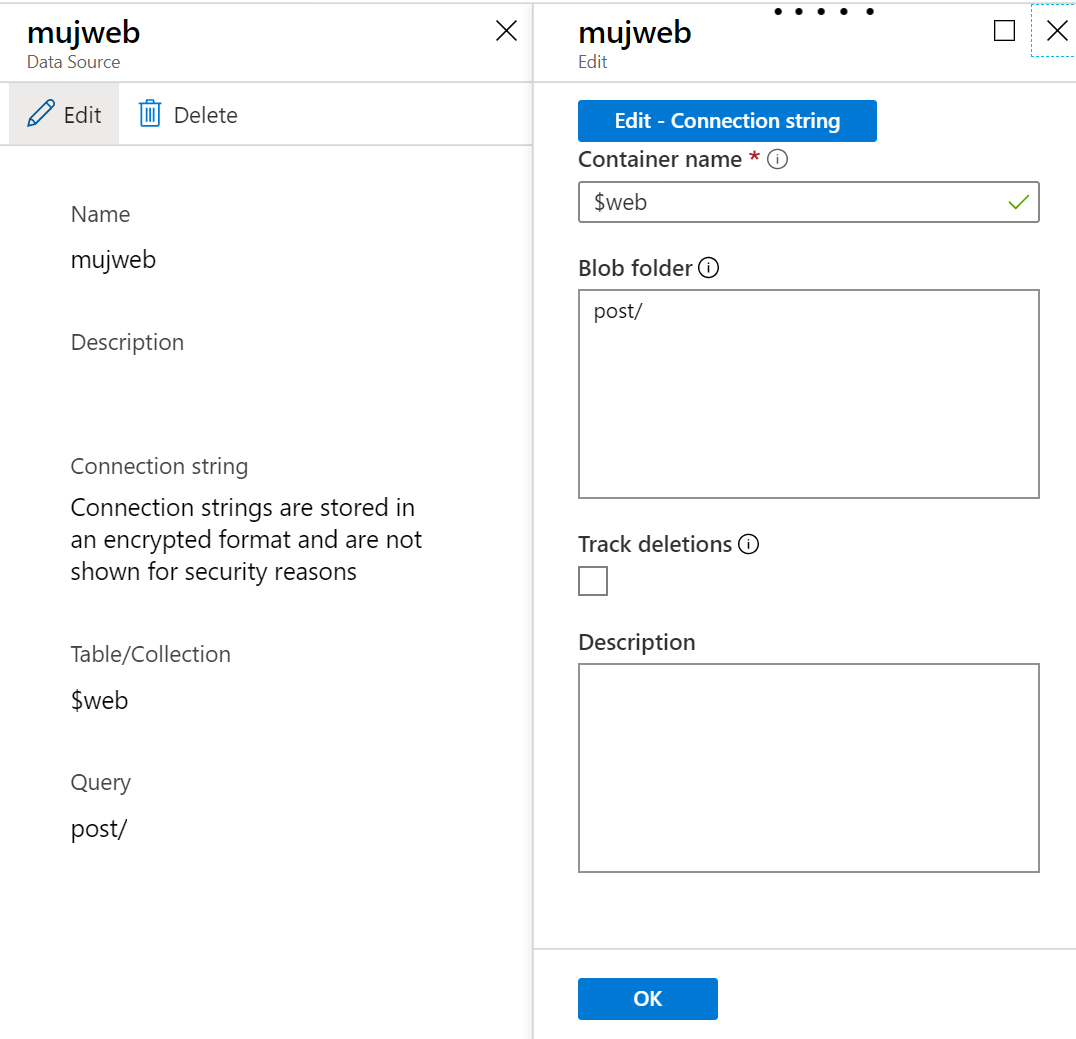
Indexer nechávám sáhnout do storage jednou denně.
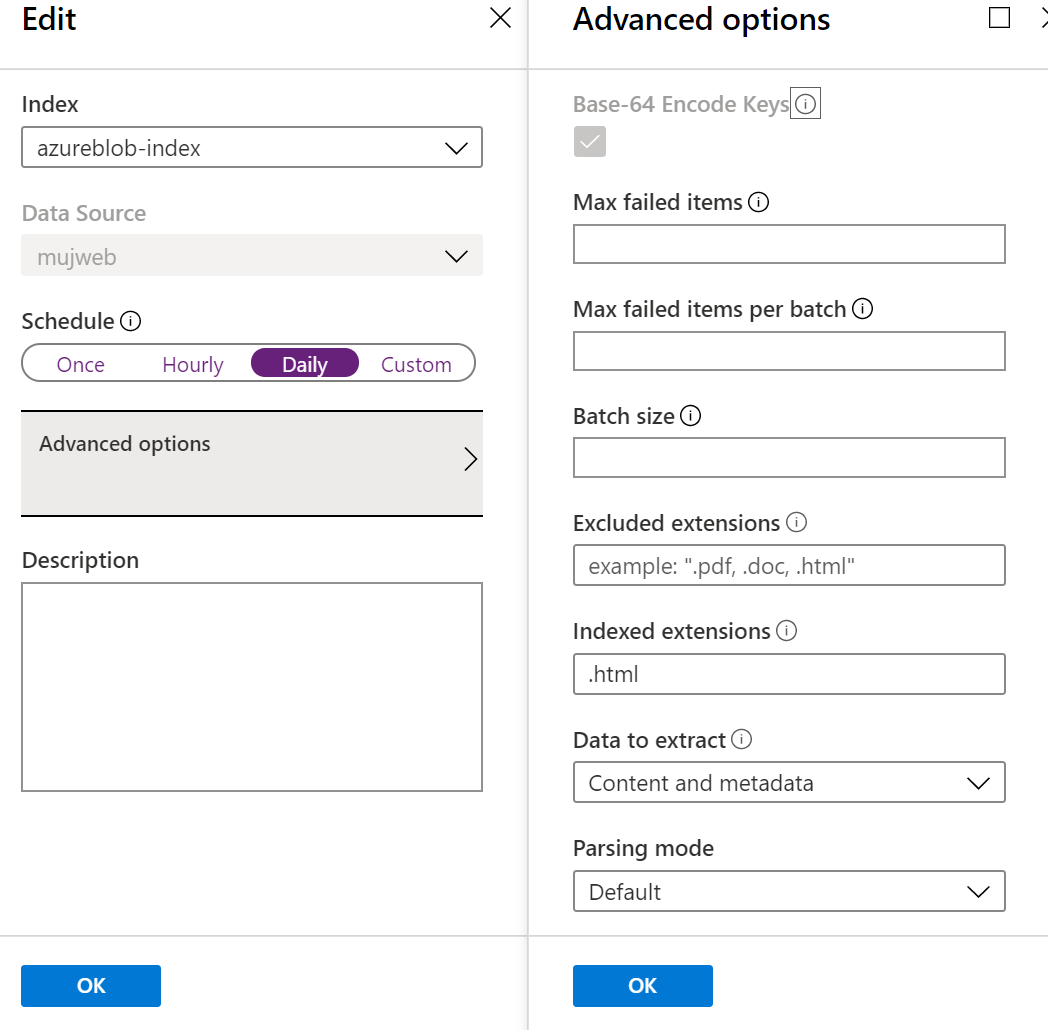
Pro HTML soubory dokáže index rovnou vytáhnout další informace a pro mě zásadní je HTML značka title, takže ve výstupu dostanu přímo název článku. Dále mě zajímá URL ve storage (abych mohl později vybudovat odkaz) a celé HTML je v políčku content, ve kterém chci mít fulltext index. Ještě je tu jedna věc. Původně jsem měl jako klíč nastavenu metadata_storage_content_md5, ale zjistil jsem, že při publikování přes Jekyll se MD5 změnila. Výsledkem bylo, že byl jeden článek naindexován několikrát. Řešením tedy bylo jako identifikátor konkrétního článku použít metadata_storage_path, ale ta obsahuje symbol “/”, který být v klíči nesmí. Zapnul jsem tedy konverzi klíče do base64 a v aplikaci při zobrazování musím provést překódování zpět.
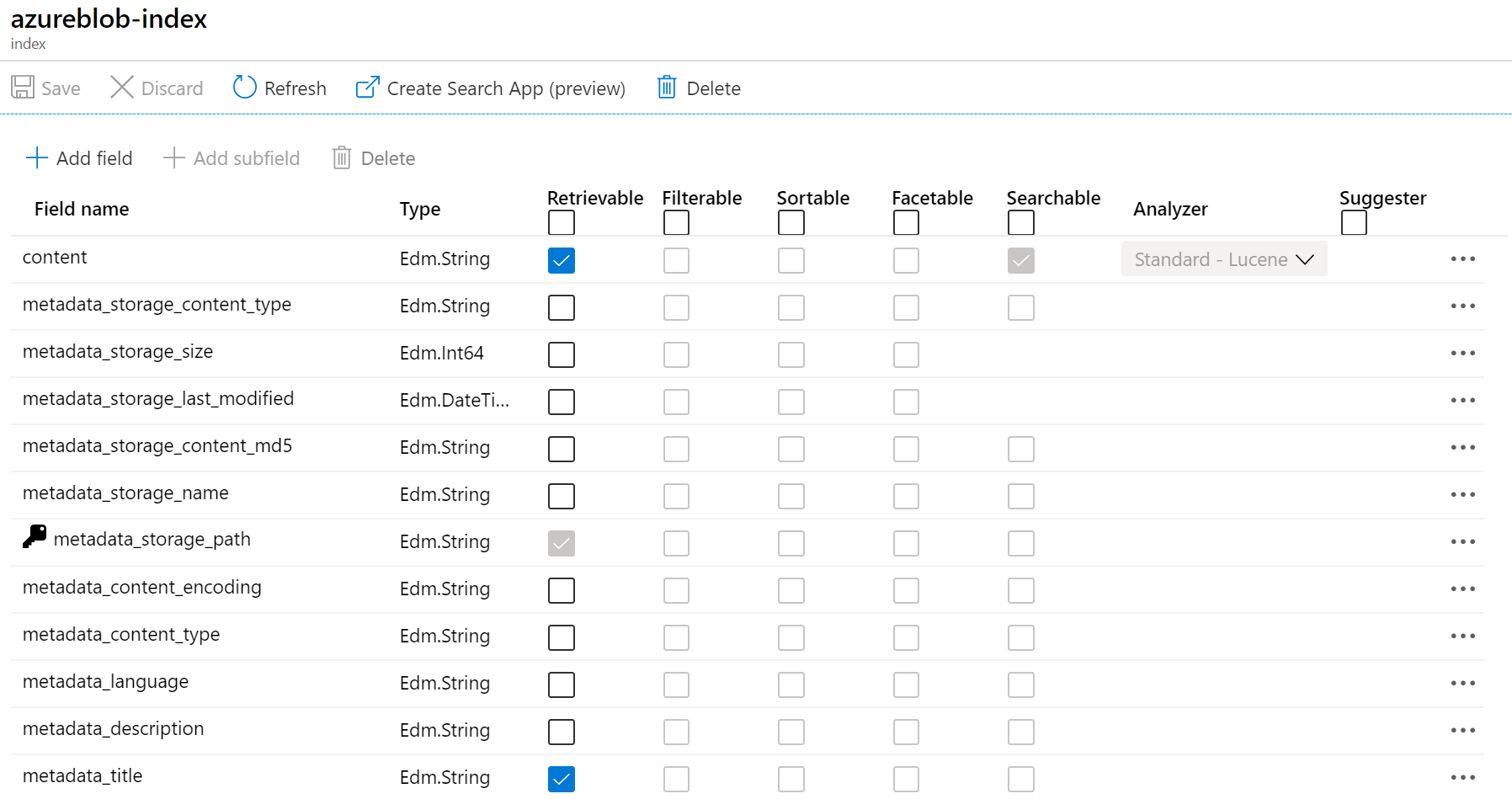
Celá moje skoro tříletá práce se v indexech vejde do 3 MB, což je skvělé, protože free tier Azure Cognitive Search mi nabízí 50 MB.
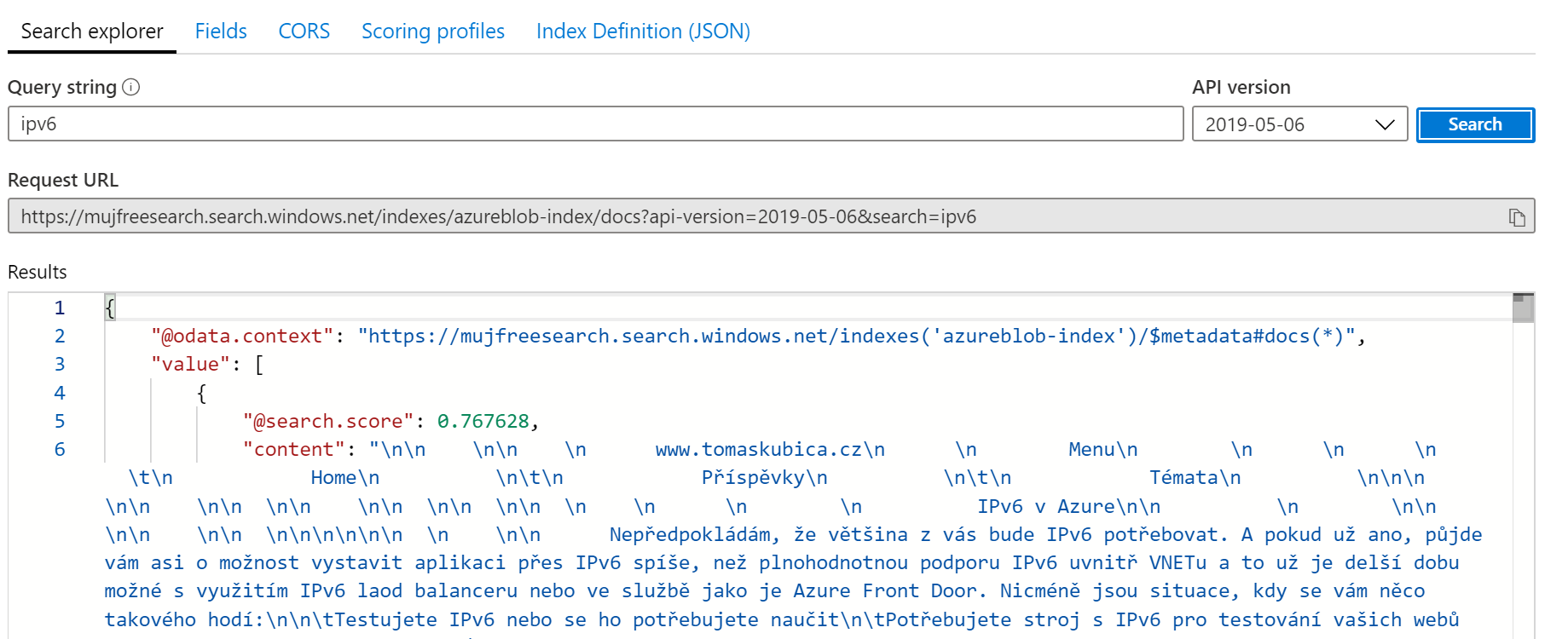
Query je velmi jednoduché, mě stačí jen naprostý základ.
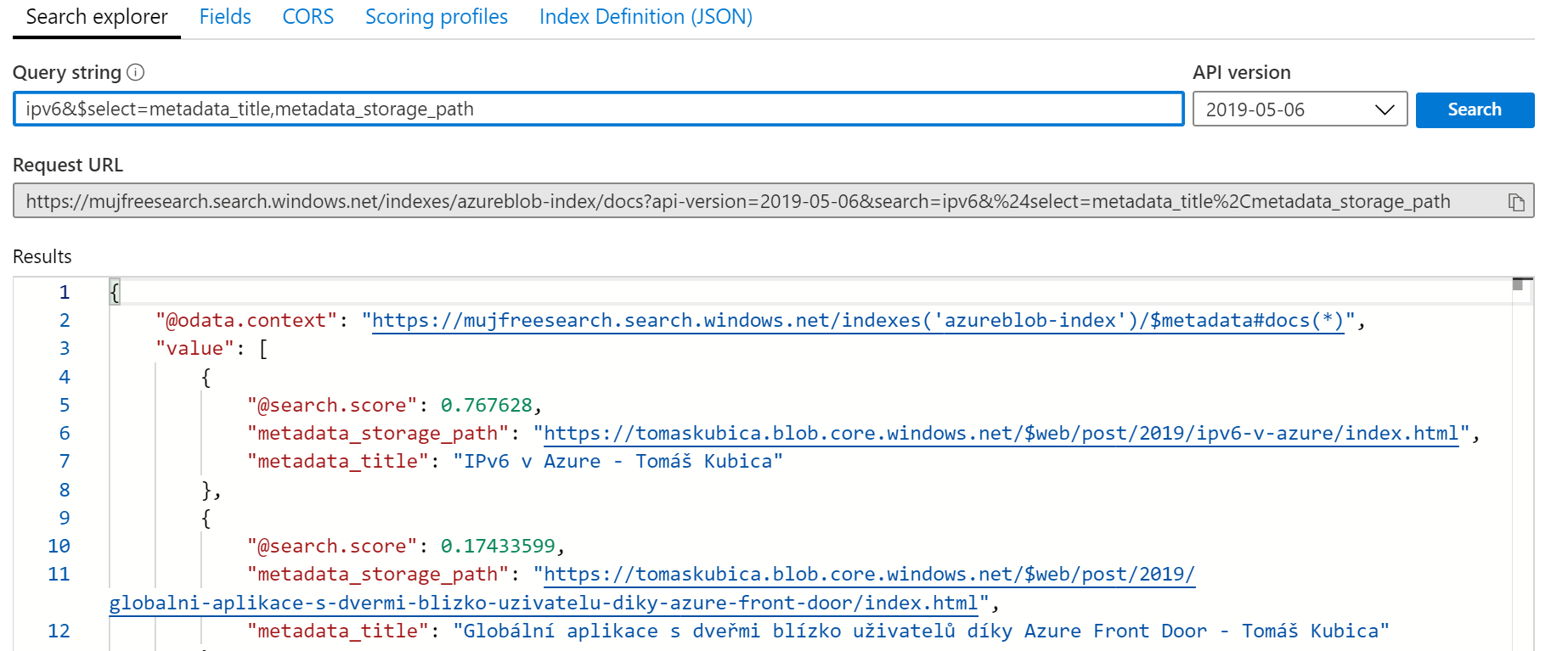
Nicméně ve výstupu políčko content vůbec nepotřebuji, stačí mi název a URL.
V Javascriptu browseru mě čeká jedna prácička - URL mám absolutní vzhledem ke storage, ale blog je na custom doméně a potřebuji z toho vyrobit relativní odkaz. Navíc to mám v base64, nicméně s tím vším se dalo rozumně poprat.
Azure Cognitive Search mám připravený.
Využití search ze statického blogu
Vůbec neumím programovat, takže vytvořit stránku, která se dotazuje mého Azure Cognitive Search je pro mě dost těžké. Naštěstí ale existuje jednoduchá hotová knihovna a přímo služba pro mě může vygenerovat příklad takové stránky.
Skvělé. Teď už jen tohle vzít a dát do do mého layoutu v Jekyll. Nakonec se to nějak povedlo.
A to je všechno. Použil jsem free tier služby Azure Cognitive Search a dostal na svůj statický blog vyhledávání. Určitě bych rád doplnil autocomplete a graficky to vylepšil - uvidíme, co se mi povede. V každém případě můžu říct, že tato služba mě hodně zaujala. Znám mnoho komerčních stránek, kde search buď není nebo nefunguje jak bych si představoval. To, že různé datové zdroje včetně databází, obrázků a PDF souborů dostanete do jednoho inteligentního indexovaného systému, mi přijde jako výborná věc pro všechny alespoň trochu složitější webové projekty. Zkuste si to taky.