Jak se postavit k zálohování a DR vašeho AKS clusteru?
Pokud to jde, doporučoval bych následující. Vytáhnout veškerý state z clusteru ven například do služeb typu Azure SQL, které mají přímo jako součást služby zálohování i disaster recovery vyřešené (ať už pomalejší a levnější geo-restore nebo živou asynchronní repliku do jiného regionu). Co se týče stateless služeb tak mít připravené veškeré deployment objekty jako jsou Helm šablony a procesy jako je Azure DevOps nebo jiný CI/CD systém a aplikace nemigrovat, ale spíše přenasadit.
Nicméně jsou situace, kdy potřebujete state držet uvnitř clusteru na perzistentních Volumech a tam už musíme pořešit přesun dat z Volume. Nebo máte situaci, kdy ne všechno je krásně automatizované co do nasazování a operations potřebuje nějaký způsob přenesení clusteru jinam bez ručního přenasazování. Nebo hledáte způsob jak celé prostředí přenést na jiný cluster pro účely testování. No a nebo máte situaci, kdy na clusteru pracuje několik aplikačních týmů a každý má svou pipeline v něčem jiném a některé infrastrukrnější věci typu Ingress kontroler nebo servisní účty (nebo nějaké složitosti nad Kubernetem - třeba Istio) si řeší operations a orchestrovat všechny tyto týmy pro rychlý zásah je náročné.
Pro tyto účely se dá velmi zajímavě použít open source projekt Heptio Ark. Přestože jsem zastáncem první varianty chápu, že někdy to prostě nejde. Pojďme se tedy na Heptio Ark podívat.
Podrobný scénář a hotové šablony najdete u mě na GitHubu
Instalace Heptio Ark
Heptio Ark je projekt zaměřený na automatizaci zálohování celého clusteru nebo jeho části (třeba konkrétního namespace) a to včetně obsahu jednotlivých Volume. To následně umožňuje cluster nebo namespace obnovit a to buď v existujícím clusteru (situace kdy to někdo omylem smazal nebo došlo k poškození dat na Volume) nebo v jiném clusteru z důvodů migrace, disaster recovery nebo vytvoření kopie pro ad-hoc testování.
Ark si bude ukládat metainformace a jednotlivé předpisy Kubernetes objektů na storage v Azure. Musíme mu ji tedy připravit.
AZURE_BACKUP_RESOURCE_GROUP=aks-backups
az group create -n $AZURE_BACKUP_RESOURCE_GROUP --location westeurope
AZURE_STORAGE_ACCOUNT_ID="aksbackupsva4ai"
az storage account create \
--name $AZURE_STORAGE_ACCOUNT_ID \
--resource-group $AZURE_BACKUP_RESOURCE_GROUP \
--sku Standard_GRS \
--encryption-services blob \
--https-only true \
--kind BlobStorage \
--access-tier Hot
az storage container create -n ark --public-access off --account-name $AZURE_STORAGE_ACCOUNT_ID
Heptio Ark si přidává spoustu interních custom resource definic, tak je musíme nejdřív nasadit. Všechny yaml soubory jsou z jejich stránek sekce pro Azure, ale už připravené a upravené je najdete na mém GitHubu viz výše.
cd ark
kubectl apply -f 00-prereqs.yaml
Dále musíme připravit Secret s některými údaji.
AZURE_RESOURCE_GROUP=MC_aks_aks_westeurope
kubectl create secret generic cloud-credentials \
--namespace heptio-ark \
--from-literal AZURE_SUBSCRIPTION_ID=$subscription \
--from-literal AZURE_TENANT_ID=$tenant \
--from-literal AZURE_CLIENT_ID=$principal \
--from-literal AZURE_CLIENT_SECRET=$client_secret \
--from-literal AZURE_RESOURCE_GROUP=${AZURE_RESOURCE_GROUP}
V dalším kroku nasadíme samotné komponenty Ark.
kubectl apply -f 00-ark-deployment.yaml
Následně musíme vytvořit objekty s informacemi o mém storage accountu a kontejneru v něm, takže si předpisy upravíme a pošleme to tam.
kubectl apply -f 05-ark-backupstoragelocation.yaml
kubectl apply -f 06-ark-volumesnapshotlocation.yaml
Pak si stáhneme Ark CLI.
wget https://github.com/heptio/ark/releases/download/v0.10.0/ark-v0.10.0-linux-amd64.tar.gz
sudo tar xvf ./ark-v0.10.0-linux-amd64.tar.gz -C /usr/local/bin ark
rm ark-v0.10.0-linux-amd64.tar.gz
Celé to budu zkoušet na stateful aplikaci Wordpress, která má jeden kontejner blogu s Volume pro obrázky a podobné věci a druhý kontejner s Maria DB s Volume pro databázi.
kubectl create namespace wp
helm install --namespace wp \
--name myblog stable/wordpress \
--set persistence.storageclass=default
Záloha s Volume snapshot
První způsob, který vyzkoušíme, je nativní integrace s Azure. Ark použije snapshot technologii pro Azure Disk. To má výhodu v tom, že je to velmi rychlé a efektivní z hlediska použitého prostoru (Copy on Write). Nevýhodou ale je, že pokud při restore potřebujeme ze snapshotu znovu vyrobit disk a potažmo Kubernetes Volume, musí to být ve stejném Azure regionu.
Vytvořme si zálohu. Můžeme filtrovat podle typu objektů, labelu nebo namespace. Já udělám zálohu jen svého wp namespace.
ark backup create --include-namespaces wp --snapshot-volumes -w mybackup
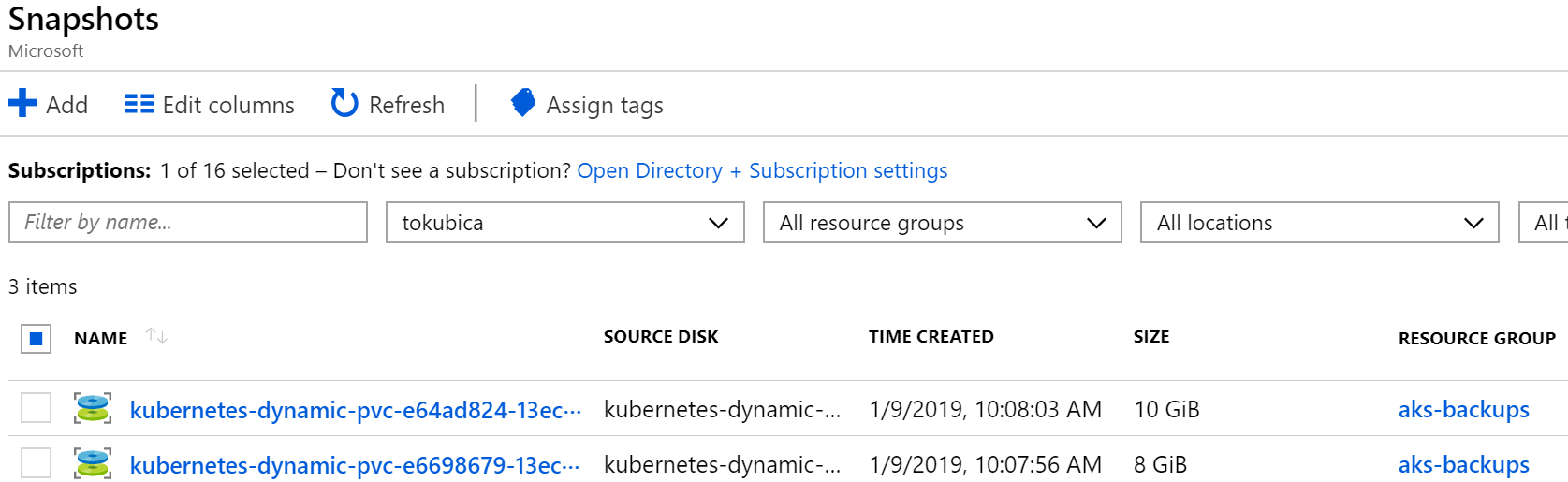
Co se vlastně stalo? V Azure se mi objeví snapshoty disků.
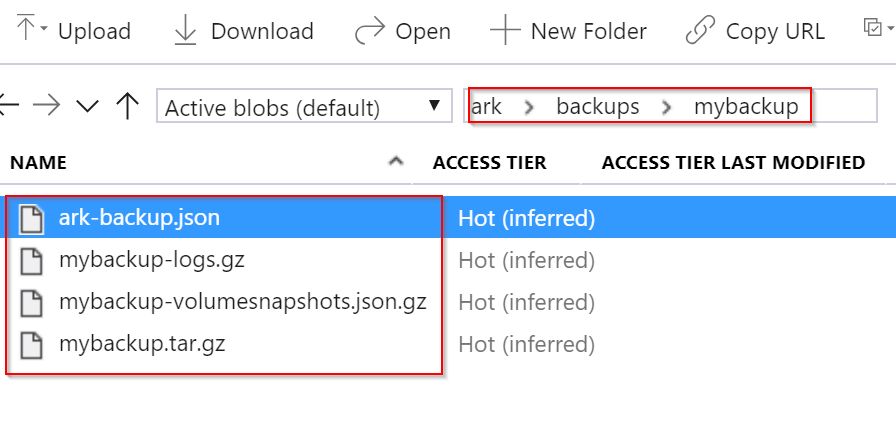
Pokud se podíváme do Blob storage, najdeme tam adresář backups a v něm nějaké soubory. Jsou to některé metainformace pro Ark včetně jak se jmenují vzniklé snapshoty a také záloha všech aktuálních objektů v namespace.
Vyzkouším si scénář, kdy mi kolega omylem smazal namespace s aplikací a všemi úžasnými příspěvky ve WordPress.
kubectl delete namespace wp
Jejda. Obnovme to s Heptio Ark.
ark restore create myrestore --from-backup mybackup -w
Povedlo se - jsme znova nahoře. Nepotřebujeme přenasazovat (na CI/CD pipeline jsem nesáhl) a Volume vznikly znova ze snapshotů.
Vyzkoušejme deployment do jiného clusteru - třeba potřebujeme udělat kopii původního. V novém AKS clusteru jsem opakoval postup pro instalaci Ark viz výše, jen jsem použil 00-ark-deployment-read-only.yaml, kde je přidaný argument při spouštění procesu s –restore-only. Jde mi o to, aby tato instance nemohla dělat backupy, jen restore. Pokud to celé dělám z důvodu vytvoření testovací kopie tak nechci, aby někdo omylem rozbil existující zálohu.
Následně provedu recovery.
ark backup get
ark restore create mytransfer --from-backup mybackup -w
A co recovery v clusteru v jiném regionu? A co Volume z Azure Files?
Snapshot technologie disků je omezena tím, že recovery se dá jednoduše udělat jen ve stejném regionu (Ark by musel vzít snapshot, vyexportovat ho jako VHD do blobu, ten v jiném regionu nahrát do Disku a tuto orchestraci v sobě zatím nemá). Nicméně Ark to má na své roadmapě.
Kromě toho ale ještě Ark podporuje implementaci přes open source zálohovadlo Restic. To umí vzít data, nasekat je na kousíčky a někam nahrát. Pokud jsem správně pochopil dělá to tak, že DaemonSet běží na každém nodu. Node má připojené disky pro své Pody v nějakém adresáři, který servíruje dovnitř Podu. DaemonSet si je tedy může číst a udělat zálohu. Pokud vím Restic nezastavuje aplikaci, jen file system. U transakčních databází bych tedy stále výrazně doporučoval externalizovat do PaaS v Azure. DB žurnál se s tím asi většinou vyrovná, ale jsou i čistší metody a neukončené transakce budou předpokládám pryč. Nicméně Volume obsahující nějaký statický content, soubory nebo něco takového by nemusel mít jakýkoli problém.
Zjednodušeně řečeno Restic by mě měl odstínit od storage implementace, což se ale zatím plně nedaří (byť je to na roadmapě). Nepodařilo se mi obnovit v jiném regionu a není podporována obnova na jinou storage (například přenos mezi cloudy), ale to je jen dočasný stav, Ark na tom intenzivně pracuje.
Do řešení tedy přidám Restic DaemonSet.
kubectl apply -f 20-restic-daemonset.yaml
Ark bude ve výchozím stavu používat snapshot a musíme mu přes anotaci říct, které Volume chceme řešit přes Restic. Měl bych to vyřešit na úrovni Helm šablony a Deployment objektu, ale pro ukázku to přemlaskněme nad běžícími Pody.
kubectl annotate pods -n wp -l app=mariadb backup.ark.heptio.com/backup-volumes=data
kubectl annotate pods -n wp -l app=myblog-wordpress backup.ark.heptio.com/backup-volumes=wordpress-data
Uděláme zálohu.
ark backup create --include-namespaces wp --snapshot-volumes -w resticbackup
Když nahlédnu do storage najdu tam adresář restic a v něm jsou nabalíčkovaná moje data.
Zrušil jsem wp namespace a provedl obnovení ze zálohy. Ark to udělá tak, že založí Volume i Pody, ale do Podů vloží init kontejner, který čeká, než Restic dokončí obnovu dat na nové Volumy. Teprve pak se spustí aplikační kontejnery v Podu.
ark restore create newregionrecovery --from-backup resticbackup -w
Implementace přes Restic umožňuje abstrahovat od storage technologie. S verzí 0.10.1 se mi sice nepodařilo recovery v jiném regionu a pro přenos mezi cloudy je explicitně zmíněno, že podpora zatím není, ale je v plánu. Zkrátka na scénáře DR do jiného regionu nebo přenos celého clusteru třeba z VMware postředí do Azure se mi zatím Ark rozběhat nepodařilo, ale technologické základy jsou a je to v plánu.
Co tedy Heptio Ark řeší?
Aktuálně vidím tyto situace:
- DR celého stateless clusteru do stejného či jiného regionu
- Přenos stateless clusteru mezi cloudy
- Vytvoření lokální kopie stateless i stateful clusteru pro účely testování
- Záloha a obnovení stateful aplikací v rámci regionu
V tuto chvíli nefunguje, ale doufejme brzy bude:
- DR či přenos stateful clusteru do jiného regionu stejného cloudu
- DR či přenos stateful clusterů mezi cloudy
S datovou perzistencí je to vždycky těžké a doporučuji ji přenechat platformním službám, kde se o ni perfektně postarají. Pokud z nějakého důvodu nemůžete nebo potřebujete infrastrukturnější postup pro přenesení clusteru než redeploy z CI/CD, mrkněte na Heptio Ark a jeho integraci s Azure Kubernetes Service.