To, že můžete spustit kontejner přímo v Azure díky ACI má i jedno zajímavé použití. Lze to nasadit pro spuštění nějakého skriptu s tím, že platíte jen za jeho běh, po ukončení skriptu se ukončí i kontejner. Uvnitř může běžet cokoli - v jakémkoli jazyce, Linux i Windows, binárky. Pokud to zakomponujeme do ARM šablony můžeme dokonfigurovat naše prostředí. Ukažme si to na příkladu vytvoření Azure Database for PostgreSQL a nahrání sady testovacích dat do DB.
Proč potřebuji imperativní skript na dokonfigurování prostředí
Prostředí pro vaši aplikaci není jen o infrastruktuře, které je doménou desired state automatizačních nástrojů jako jsou Azure Resource Manager šablony nebo Terraform. Pro nasazení aplikace nebo vytvoření prostředí pro její testování pravděpodobně potřebuji i konfiguraci nějakého OS, pokud jedu na IaaS (nástroje jako Ansible, Puppet, Chef, PowerShell DSC). Imperativní řešení dává ale smysl i při použití PaaS. Častým příkladem bude nutnost nejen vytvořit PaaS databázi, ale naplnit ji testovacími či startovacími daty.
Jasně - můžete mít stanici, která nejprve provede deployment IaaS/PaaS a pak třeba do databáze nahraje potřebná data. Pro účely CI/CD máte třeba VSTS nebo Jenkins a příslušné operace můžete naskriptovat tam. Ale co když pro release proces nemůžete nebo nechcete Jenkins použít? Typicky co když vyrábíte software pro zákazníky a ti při jeho nasazování nebudou mít vaše CI/CD? Nebylo pro ně jednodušší mít ARM šablonu, kterou mohou spustit ve svém Azure a ta sama o sobě udělá všechno potřebné včetně třeba nahrání dat?
Azure Container Instances a skriptování
Kdykoli jsem potřeboval něco řešit skriptem vedlo to pokaždé na nutnost mít nějaký deployment server nebo to bušit ze své stanice. Pro zajištění opakovatelnosti jsem musel automatizovat vznik deployment serveru a řešit problém vejce a slepice nebo (a to je horší případ) se o deployment server dlouhodobě starat. Jednorázové úlohy ale přece můžu spouštět v kontejneru, který je dobře zapouzdřený, rychle startuje a dobře se s ním pracuje. No jo - ale abych mohl nahodit kontejner se skriptem, potřebuji místo, kde ho můžu nastartovat - třeba nějakou VM s Dockerem. Hmm... a ten musím taky nějak vytvořit a jsme u problému vejce a slepice.
Azure Container Instances mi to elegantně řeší, protože kontejner můžu pustit přímo v Azure. Nepotřebuji hostitele a kontejner samotný se může stát součástí ARM šablony.
Příklad nasazení s Azure PostgreSQL a ACI
Vezměme si tedy následující situaci. Potřebuji provést deployment PostgreSQL databáze v PaaS Azure. Na to můžu krásně použít ARM šablonu. Jenže výsledná databáze je prázdná a já ji potřebuji naplnit nějakými daty. Třeba pro účely testování nebo jen založit příslušné databázové struktury pro produkční aplikaci nebo vytvořit demo prostředí s demo daty pro školení nebo předvedení svého software. Jak to dostat do ARM šablony?
Data mám ve formě SQL skriptu připravena a uložil jsem je do Blob storage (nebo na GitHub apod.). Stačí mi tedy po vytvoření PostgreSQL použít psql na vytvoření databáze a spustit SQL import. Potřebuji tedy něco v čem takovou operaci udělám a podotýkám, že nevím jak dlouho operace pojede (u velké databáze to může být klidně hodina, takže věci jako Azure Functions jsou mimo hru). Ten skript bude mít jednotky řádek v Bash - kde ho ale spustit. Tím místem pro mě bude Azure Container Instance.
Udělal jsem tedy následující ARM šablonu a pojďme si ji okomentovat.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"postgresqlPassword": {
"type": "securestring",
"defaultValue": "Azure12345678",
"metadata": {
"description": "postgresql database password"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
}
},
"variables": {
"cpuCores": "1",
"memoryInGb": "1.5",
"postgresqlServerName": "[concat('postgresql-', uniquestring(resourceGroup().id))]",
"postgresqlVersion": "9.6",
"postgresqlLogin": "tomas",
"postgresqlPassword": "Azure12345678",
"postgresqlStorage": 5120,
"postgresqlBackupRetentionDays": 7,
"postgresqlGeoBackup": "Disabled",
"postgresqlSkuName": "B_Gen5_1",
"postgresqlSkuTier": "Basic",
"postgresqlSkuCapacity": 1,
"postgresqlSkuFamily": "Gen5",
"dbConnectionHost": "[concat(variables('postgresqlServerName'), '.postgres.database.azure.com')]",
"dbConnectionUser": "[concat(variables('postgresqlLogin'), '@', variables('postgresqlServerName'))]"
},
"resources": [
{
"apiVersion": "2017-12-01-preview",
"kind": "",
"location": "[parameters('location')]",
"name": "[variables('postgresqlServerName')]",
"properties": {
"version": "[variables('postgresqlVersion')]",
"administratorLogin": "[variables('postgresqlLogin')]",
"administratorLoginPassword": "[variables('postgresqlPassword')]",
"storageProfile": {
"storageMB": "[variables('postgresqlStorage')]",
"backupRetentionDays": "[variables('postgresqlBackupRetentionDays')]",
"geoRedundantBackup": "[variables('postgresqlGeoBackup')]"
},
"sslEnforcement": "Disabled"
},
"sku": {
"name": "[variables('postgresqlSkuName')]",
"tier": "[variables('postgresqlSkuTier')]",
"capacity": "[variables('postgresqlSkuCapacity')]",
"size": "[variables('postgresqlStorage')]",
"family": "[variables('postgresqlSkuFamily')]"
},
"type": "Microsoft.DBforPostgreSQL/servers",
"resources":[
{
"type":"firewallrules",
"apiVersion":"2017-12-01-preview",
"dependsOn":[
"[concat('Microsoft.DBforPostgreSQL/servers/', variables('postgresqlServerName'))]"
],
"location":"[parameters('location')]",
"name":"allowAll",
"properties":{
"startIpAddress":"0.0.0.0",
"endIpAddress":"255.255.255.255"
}
}]
},
{
"name": "psql-script",
"type": "Microsoft.ContainerInstance/containerGroups",
"apiVersion": "2018-02-01-preview",
"location": "[parameters('location')]",
"dependsOn": [
"[variables('postgresqlServerName')]"
],
"properties": {
"containers": [
{
"name": "psql-script",
"properties": {
"image": "tutum/curl",
"ports": [
{
"protocol": "tcp",
"port": 80
}
],
"environmentVariables": [
{
"name": "PGPASSWORD",
"value": "[variables('postgresqlPassword')]"
},
{
"name": "PGUSER",
"value": "[variables('dbConnectionUser')]"
},
{
"name": "PGHOST",
"value": "[variables('dbConnectionHost')]"
},
{
"name": "PGSSLMODE",
"value": "require"
}
],
"command": [
"/bin/bash",
"-c",
"apt-get update && apt-get install wget postgresql-client -y && wget 'https://tomuvstore.blob.core.windows.net/sdilna/world.sql?st=2018-05-22T05%3A59%3A00Z&se=2020-05-24T05%3A59%3A00Z&sp=rl&sv=2017-04-17&sr=b&sig=1Uh7nH6KfO8sPW9qLpWKpevLrqCkaR%2FBxt7mcF56oqk%3D' -O world.sql && psql -d postgres -c 'CREATE DATABASE mydata;' && psql -d mydata -f world.sql"
],
"resources": {
"requests": {
"cpu": "[variables('cpuCores')]",
"memoryInGb": "[variables('memoryInGb')]"
}
}
}
}
],
"ipAddress": {
"ports": [
{
"protocol": "tcp",
"port": 80
}
],
"type": "Public"
},
"restartPolicy": "OnFailure",
"osType": "Linux"
}
}
],
"outputs": {
}
}
V šabloně se vytváří Azure Database for PostgreSQL - nic objevného. Zajímavější je ACI. To má dependenci na PostgreSQL, takže se spustí až když to bude připravené. Naběhnu image tutum/curl (je to holé Ubuntu s doinstalovaným curl). Do kontejneru přes environmentální proměné vložím connection informace pro PostgreSQL (standardní formát, který používá psql). Ano - tohle není nejbezpečnější cesta, protože hodnoty budou v Azure portálu vidět. Samozřejmě se to dá řešit lépe, ale pro jednoduchost nechme takhle. Důležitá je také restart politika, kterou dávám na OnFailure. Jinak řečeno pokud skript havaruje, chci ho pustit znovu. Ale pokud úspěšně doběhne, chci nechat kontejner vypnutý (pokud bych tam nechal Always bude ACI neustále skript spouštět dokola a já budu platit).
Postatná část tedy je co se vlastně v kontejneru spustí. Nechtěl jsem vytvářet svůj vlastní image se svým zabudovaným skriptem. Je velmi jednoduchý, tak ho můžu rovnou spustit bez nutnosti dělat si svůj image. Kontejner spustí bash a předá mu následující příkaz:
apt-get update && apt-get install wget postgresql-client -y && wget 'https://tomuvstore.blob.core.windows.net/sdilna/world.sql?st=2018-05-22T05%3A59%3A00Z&se=2020-05-24T05%3A59%3A00Z&sp=rl&sv=2017-04-17&sr=b&sig=1Uh7nH6KfO8sPW9qLpWKpevLrqCkaR%2FBxt7mcF56oqk%3D' -O world.sql && psql -d postgres -c 'CREATE DATABASE mydata;' && psql -d mydata -f world.sql
Co se děje? Nejprve nainstaluji wget a postgresql klienta. Následně si stáhnu backup (SQL skript). Pak se připojím do postgresql a založím novou databázi a následně do ní pošlu SQL skript a provedu obnovení dat. Jednoduché, ne?
Deployment ARM šablony pošlu do Azure a uvidíme co se bude dít.
az group create -n postgresql -l westeurope az group deployment create -g postgresql --template-file postgresql-with-data.json
V Resource Group po chvilce vidím vytvořenou DB a ACI.
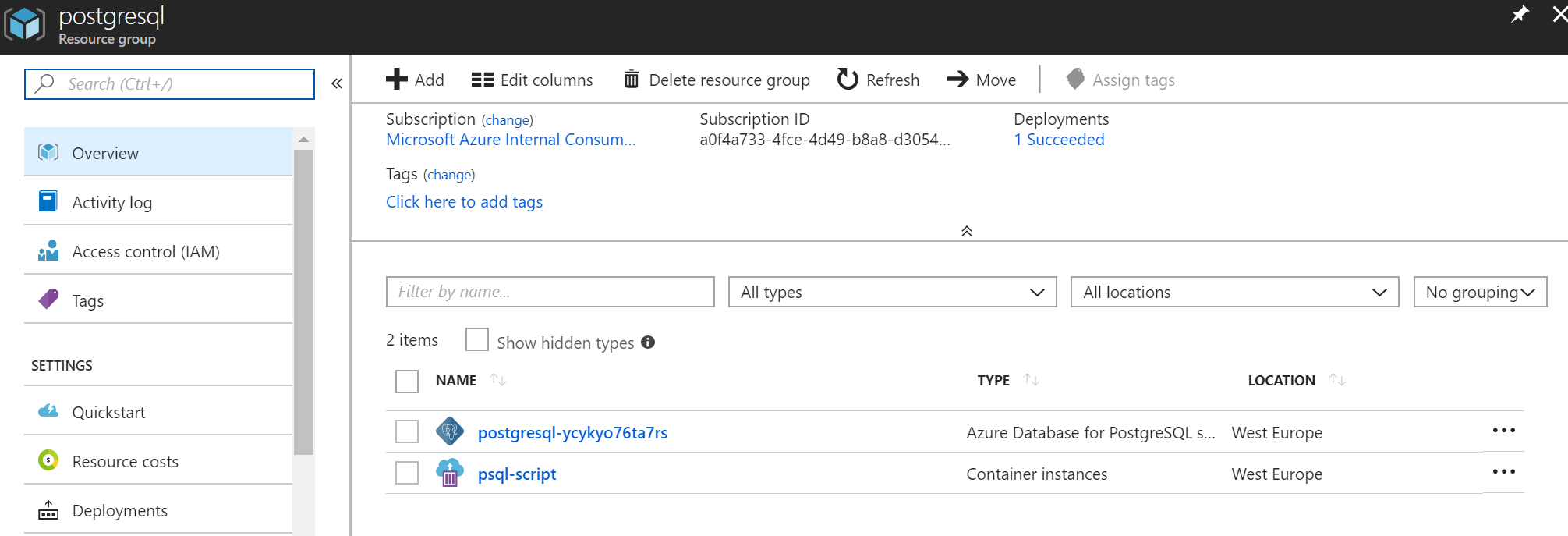
A skutečně - je tam moje databáze s daty.
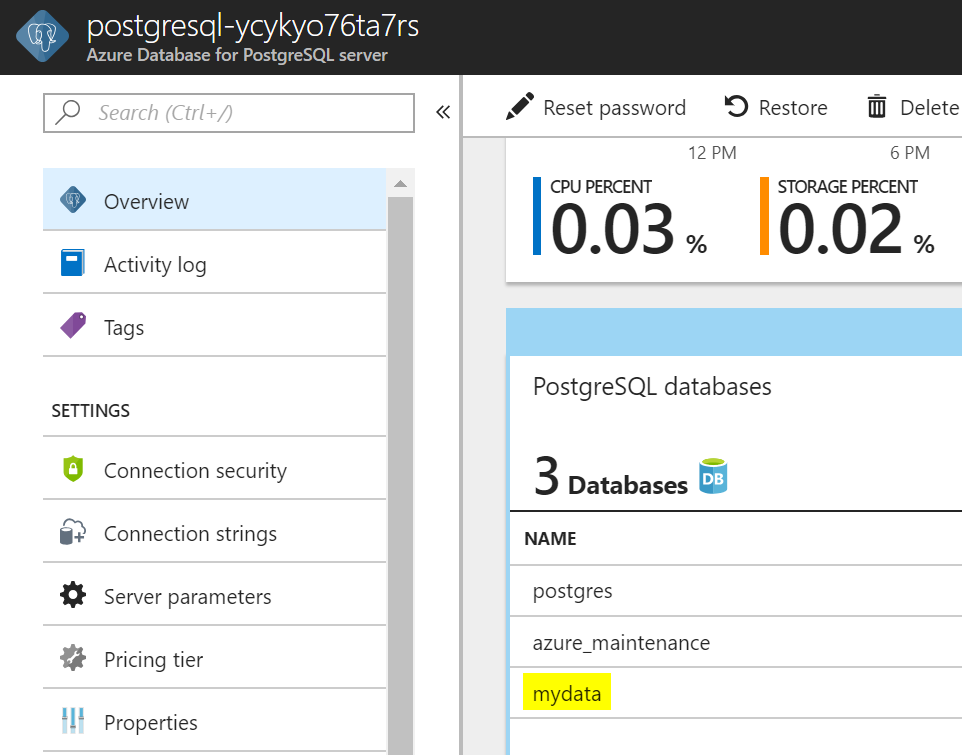
Připojím se do DB ze své stanice a data tam opravdu jsou.
psql (10.3 (Ubuntu 10.3-1), server 9.6.7)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-SHA384, bits: 256, compression: off)
Type "help" for help.
mydata=> \d
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+-----------------
public | city | table | tomas
public | country | table | tomas
public | countrylanguage | table | tomas
public | pg_buffercache | view | azure_superuser
public | pg_stat_statements | view | azure_superuser
(5 rows)
Podívejme se na stav našeho kontejneru. Všimněte si, že je ve stavu Terminated, takže za něj už neplatím. Z logu je zřejmé, že jsem zaplati za asi 80 vteřin běhu.
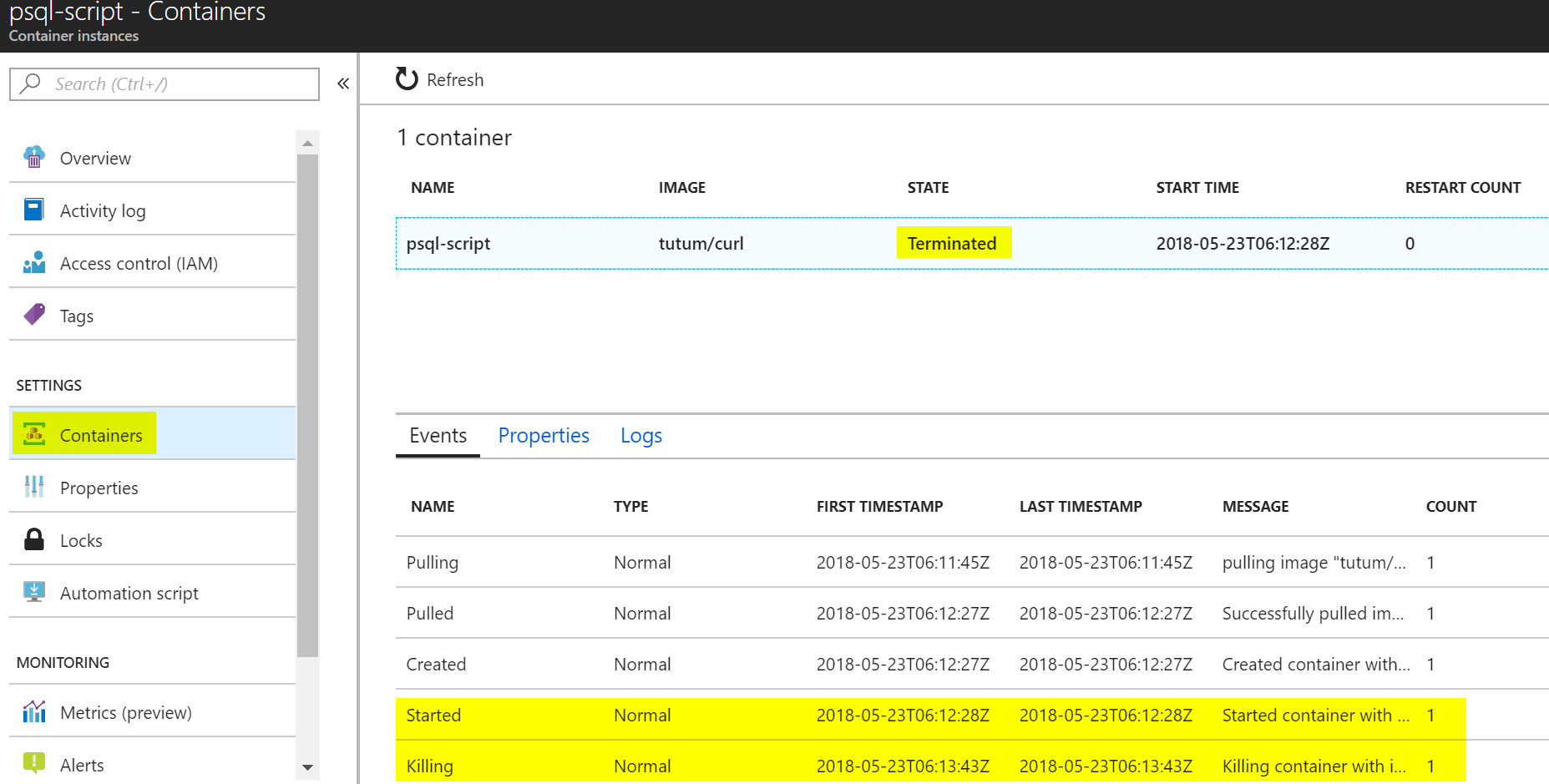
V logu vidím, že kontejner si postahoval psql klienta.
Stáhnul SQL data z Blob storage.
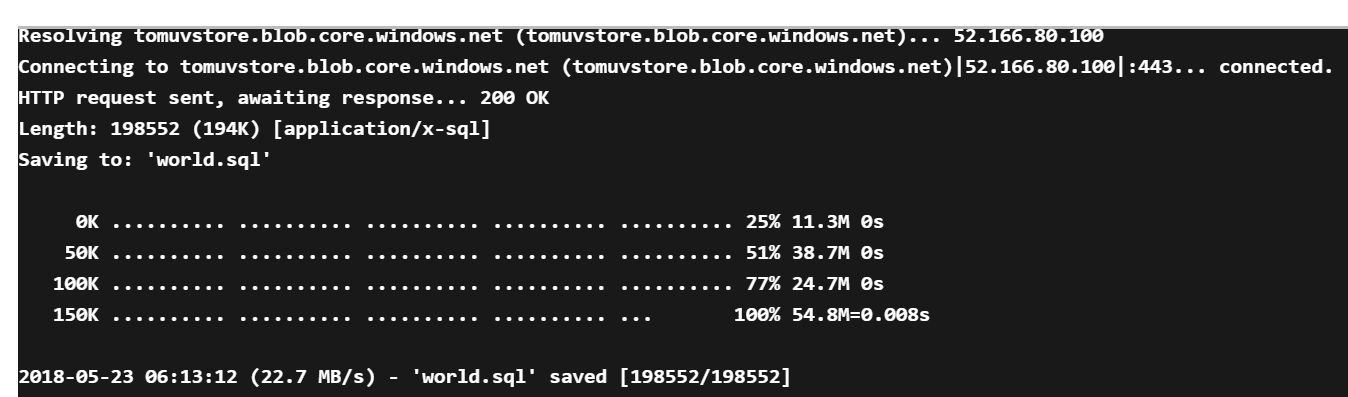
Založil databázi a nahrál data.

A to je přesně co jsme potřebovali :)
A teď si představme co dalšího se dá takhle řešit. Tak například Azure CLI prostředí existuje jako kontejner, takže může z ARM vyvolat CLI skript a namířit ho třeba na jiný Azure. V kontejneru existuje Jenkins, takže CI/CD server může být součástí ARM šablony. K dispozici jsou image automatizačních nástrojů - třeba Ansible, takže pro účely konfigurace VM si můžeme ARM šablonou vydeployovat vlastní server s Ansible a z něj provést nastavení OS v IaaS. A co když používáte Redis cache a vaší strategií je si ji rovnou předvyplnit z on-prem SQL při deploymentu řešení? Nebo z Internetu postahovat nějaká open data a uložit je do Azure Files tak, aby byla k dispozici pro aplikaci?
Kontejnery mohou elegantně řešit spouštění jednorázových nebo plánovaných úloh jako je třeba import dat. ACI zase dokáže spouštět kontejnery rovnou nad Azure bez nutnosti vytvářet Docker hostitele. To všechno vede na to, že moje ARM šablona může obsloužit celý proces včetně nahrání dat. Zkuste si ACI, stojí to za to.