Obvykle doporučuji stavové záležitosti typu databáze nebo fronta nedávat do Kubernetes clusteru, ale využít plně spravované PaaS řešení v Azure. Je spolehlivé, bezpečné, bez práce a hlavně udržitelné (nemusím nic patchovat, upgradovat ani si stále zkoušet, že moje provisioning skripty fungují i s novější verzí). Ale mám postupovat tak, že si to v Azure naklikám a přes schránku nakopíruju do příkazu pro Kubernetes Secret? To v rámci CI/CD není tak pohodlné. A co to nějak naskriptovat? To rozhodně jde, ale musím to vymyslet a připravit. Jenže přesně na tohle už řešení je - projekt Open Service Broker, který to dělá jak pro Kubernetes, tak Cloud Foundry, Open Shift nebo Service Fabric. Pojďme se dnes podívat na kombinaci Kubernetes, Service Catalog a Open Service Broker for Azure.
Proč vznikla potřeba pro service brokering
PaaS platformy pro deployment aplikací byly vždy velmi silně zaměřené na maximální jednoduchost pro vývojáře. Vezmete svůj kód a ten do platformy jednoduše pošlete. Možná ho máte v GitHub a chcete při změnách automaticky tyto nasadit s Azure Application Services. Nebo chcete vzít Visual Studio a nasadit otevřený projekt do Service Fabric. Možná potřebujete vzít vaši Javu a Spring Boot a zavolat cf push pro nasazení do vašeho Cloud Foundry clusteru od Pivotalu v Azure. Ve všech těchto případech se vývojář nechce trápit s provozem podpůrných technologií, které jeho kód využívá. A sem patří i různé databáze nebo fronty.
Jak to tedy udělat tak, aby vývojář dostal bez dlouhého čekání svou databázi aniž by musel chodit mimo svou platformu, něco někde vytvářet a connection stringy si kopírovat k sobě? Můžete namítnou, že u některých PaaS platforem lze stejnými postupy nasadit i databázi, přecijen ta je taky ve finále kód a třeba pod OpenShift běží Kubernetes, který v tomto směru má dostatek infrastrukturních konstruktů k realizaci. Jenže vývojář nechce být specialistou na nasazování a provoz databáze v kontejnerech a řešit zásadní otázky bezpečnosti, dostupnosti, konzistence dat či zálohování a patchování. Tak jak jsou aplikační platformy v cloudu tak existují i datové platformy v cloudu. Proč tedy nesáhnout po něčem specializovaném. Třeba po Azure SQL, Azure MySQL, Azure PostgreSQL, Cosmos DB s Mongo API, Cassandra API, Azure Redis či storage technologie typu blob nebo messaging systému jako je Service Bus.
PaaS aplikační platformy tedy přinesly potřebu nabídnout vývojářům přímo z platformy samotné možnost jednoduše a rychle získat podpůrné služby s využitím existujících robustních řešení datových platforem.
Open Service Broker a jeho Azure implementace
Za projektem Open Service Broker historicky stála platforma Cloud Foundry, ale myšlenka se později začala šířit i do dalších projektů a to zejména Kubernetes (což není úplně PaaS, protože do něj nedáváte kód, ale hotový kontejner, nicméně potřeba získávat nativními Kubernetes prostředky datové zdroje třeba v cloudu tu rezonuje rovněž), OpenShift a v prototypu i Service Fabric.
Implementace Open Service Broker pro Azure služby je open source projekt. Informace o něm jsou na https://osba.sh/ a zdrojáky na https://github.com/Azure/open-service-broker-azure. Projekt je ve fázi, kdy tři základní relační databáze podporuje stabilním způsobem a to konkrétně SQL, MySQL a PostgreSQL. Zatím experimentálně (ale funguje to) nabízí další služby jako je Cosmos DB, Key Vault, Service Bus, Event Hub, Redis a blob storage.
Použití s Kubernetes Service Catalog
Pojďme si to vyzkoušet. Neprve potřebujeme do Kubernetes přidat projekt Service Catalog, což je komponenta, která pak následně bude volat OSB implementace (ty budou fungovat jako něco na způsob driveru). Protože Service Catalog ještě není nativní součástí kubectl CLI, nainstalujeme si na hraní speciální CLI (pro provoz řešení to ale není nutné, zdroje vytváříte jako Kubernetes objekty v YAML předpisech).
curl -sLO https://download.svcat.sh/cli/latest/linux/amd64/svcat
chmod +x ./svcat
sudo mv ./svcat /usr/local/bin/
svcat version --client
Projekt Service Catalog bude do AKS nejlepší nainstalovat Helm šablonou.
helm repo add svc-cat https://svc-catalog-charts.storage.googleapis.com
helm install svc-cat/catalog --name catalog \
--namespace services \
--set controllerManager.healthcheck.enabled=false
Následně opět Helm šablonou nainstalujeme OSBA, tedy implementaci “driveru” pro Azure. V tento moment musíte zadat login do Azure, tedy účet service principal (lze předpokládat, že někdy v budoucnu bude možné využít Managed Service Identity, ale v době psaní článku zadáme účet takhle ručně).
helm repo add azure https://kubernetescharts.blob.core.windows.net/azure
helm install azure/open-service-broker-azure --name azurebroker --namespace services \
--set azure.subscriptionId=$subscription \
--set azure.tenantId=$tenant \
--set azure.clientId=$principal \
--set azure.clientSecret=$client_secret
Vypište si Pody v namespace services a počkejte, až budou všechny nahoře. Pak už si můžeme vypsat brokery (máme tam osba) a v něm jednotlivé třídy.
$ svcat get brokers
NAME NAMESPACE URL STATUS
+------+-----------+--------------------------------------------------------------------------+--------+
osba https://azurebroker-open-service-broker-azure.services.svc.cluster.local Ready
$ svcat get classes
NAME NAMESPACE DESCRIPTION
+-------------------------------+-----------+---------------------------------+
azure-postgresql-9-6-database Azure Database for PostgreSQL
9.6-- database only
azure-sql-12-0-database Azure SQL 12.0-- database only
azure-mysql-5-7-dbms Azure Database for MySQL 5.7--
DBMS only
azure-mysql-5-7-database Azure Database for MySQL 5.7--
database only
azure-mysql-5-7 Azure Database for MySQL 5.7--
DBMS and single database
azure-sql-12-0-dbms Azure SQL 12.0-- DBMS only
azure-postgresql-9-6 Azure Database for PostgreSQL
9.6-- DBMS and single database
azure-postgresql-9-6-dbms Azure Database for PostgreSQL
9.6-- DBMS only
azure-sql-12-0 Azure SQL Database 12.0-- DBMS
and single database
Jak vidíte ve výchozím stavu máme k dispozici jen ty služby, které jsou v rámci projektu OSBA ve stavu stable. To mi ale zatím stačí.
Proč tam je třeba MySQL třikrát? Když si v Azure vytvoříte Azure Database for MySQL, vznikne platformní MySQL server a jedna databáze. Tomu odpovídá třída azure-mysql-5-7. Jenže vy také můžete na jednom serveru vytvořit databází několik s tím, že tyto sdílí zdroje. Zejména pro testovací potřeby v rámci CI/CD je to cenově efektivní varianta. Pak můžete použít azure-mysql-5-7-dbms pro vytvoření serveru a pak už jen azure-mysql-5-7-database pro přidání DB do existujícího serveru.
U třídy si můžeme vypsat plány.
$ svcat get plans --class azure-postgresql-9-6
NAME NAMESPACE CLASS DESCRIPTION
+------------------+-----------+----------------------+--------------------------------+
basic azure-postgresql-9-6 Basic Tier-- For workloads
that require light compute and
I/O performance.
general-purpose azure-postgresql-9-6 General Purpose Tier-- For
most business workloads that
require balanced compute
and memory with scalable I/O
throughput.
memory-optimized azure-postgresql-9-6 Memory Optimized Tier-- For
high-performance database
workloads that require
in-memory performance for
faster transaction processing
and higher concurrency.
V rámci konkrétní třídy a plánu je obvykle k dispozici poměrně dost různých nastavení. Třeba počet vCore, velikost nebo nastavení pravidel na firewallu. Celý seznam parametrů získáte takhle:
svcat describe plan azure-postgresql-9-6/general-purpose
Podstatně přehlednější to ale bude tady v dokumentaci: https://github.com/Azure/open-service-broker-azure/blob/master/docs/modules/postgresql.md.
Vytvořme si teď DB s využitím CLI.
svcat provision myfirstdb --class azure-postgresql-9-6 \
--plan general-purpose \
-p location=westeurope \
-p resourceGroup=aksgroup
svcat get instances
NAME NAMESPACE CLASS PLAN STATUS
+-----------+-----------+----------------------+-----------------+--------------+
myfirstdb default azure-postgresql-9-6 general-purpose Provisioning
Pohledem do portálu skutečně zjistíme, že databázový stroj i databáze jsou hotové.
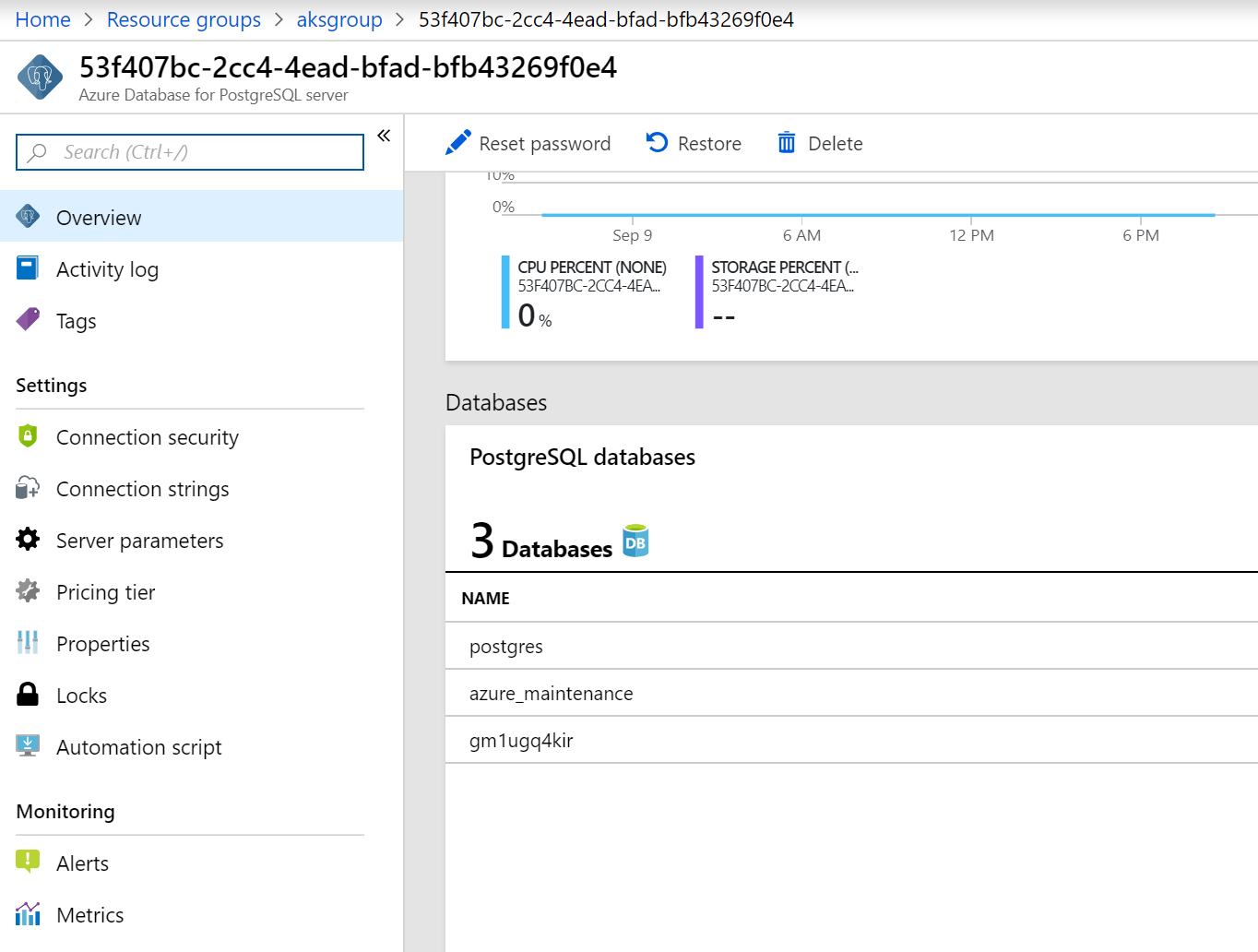
Výborně. Jak se teď k databázi připojit? Service Katalog má koncept bindingu a to je o vytvoření loginu a connection stringu a uložení těchto informací do Kubernetes Secret tak, aby to třeba aplikační kontejner mohl načíst.
Vyzkoušejme si to.
$ svcat bind myfirstdb
Name: myfirstdb
Namespace: default
Status:
Secret: myfirstdb
Instance: myfirstdb
Parameters:
No parameters defined
Podívejme se, co v tom secret bude.
$ printf 'Host: ' && kubectl get secret myfirstdb -o json | jq -r .data.host | base64 --decode && echo && \
> printf 'DB: ' && kubectl get secret myfirstdb -o json | jq -r .data.database | base64 --decode && echo && \
> printf 'User: ' && kubectl get secret myfirstdb -o json | jq -r .data.username | base64 --decode && echo && \
> printf 'Password: ' && kubectl get secret myfirstdb -o json | jq -r .data.password | base64 --decode && echo
Host: 53f407bc-2cc4-4ead-bfad-bfb43269f0e4.postgres.database.azure.com
DB: gm1ugq4kir
User: j3quoupdwm@53f407bc-2cc4-4ead-bfad-bfb43269f0e4
Password: 6y9kUwXWigwQNdWz
Pojďme udělat druhý (jiný) binding na tu stejnou instanci.
$ svcat bind myfirstdb --name myfirstdb2 --secret-name myfirstdb2
Name: myfirstdb2
Namespace: default
Status:
Secret: myfirstdb2
Instance: myfirstdb
Co bude v Secret?
$ printf 'Host: ' && kubectl get secret myfirstdb2 -o json | jq -r .data.host | base64 --decode && echo && \
> printf 'DB: ' && kubectl get secret myfirstdb2 -o json | jq -r .data.database | base64 --decode && echo && \
> printf 'User: ' && kubectl get secret myfirstdb2 -o json | jq -r .data.username | base64 --decode && echo && \
> printf 'Password: ' && kubectl get secret myfirstdb2 -o json | jq -r .data.password | base64 --decode && echo
Host: 53f407bc-2cc4-4ead-bfad-bfb43269f0e4.postgres.database.azure.com
DB: gm1ugq4kir
User: wzqg5lf6tj@53f407bc-2cc4-4ead-bfad-bfb43269f0e4
Password: IgLwAmgojY7rOipv
Vidíte? Stejný hostitel (DB server), stejná DB, ale jméno a heslo je jiné.
To je velmi zajímavé. Můžeme tedy vytvořit velmi elegantně nad jednou databází hned několik účtů plně automatizovaně prostřednictvím bindingu. Můžeme ale také vytvořit novou instanci a to buď ve formě další databáze v existujícím serveru nebo úplně nový server. Velmi flexibilní.
Service broker přes YAML konstrukty
Zatím jsme si ukázili nějakou příkazovou řádku, ale to není ten způsob, pro který si něco takového nasadíte. To klíčové je schopnost integrovat tuto funkcionalitu do vašeho Kubernetes ekosystému, tedy YAML předpisů.
Mějme následující YAML soubor. V něm definujeme externí DB v Azure a současně startujeme kontejner, který má mít do této DB přístup.
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceInstance
metadata:
name: my-mysqldb-instance
namespace: default
spec:
clusterServiceClassExternalName: azure-mysql-5-7
clusterServicePlanExternalName: basic
parameters:
location: westeurope
resourceGroup: aksgroup
---
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceBinding
metadata:
name: my-mysqldb-binding
namespace: default
spec:
instanceRef:
name: my-mysqldb-instance
secretName: my-mysqldb-secret
---
kind: Pod
apiVersion: v1
metadata:
name: env
spec:
containers:
- name: ubuntu
image: tutum/curl
command: ["tail"]
args: ["-f", "/dev/null"]
env:
- name: "DB_HOST"
valueFrom:
secretKeyRef:
name: my-mysqldb-secret
key: host
- name: "DB_PORT"
valueFrom:
secretKeyRef:
name: my-mysqldb-secret
key: port
- name: "DB_DB"
valueFrom:
secretKeyRef:
name: my-mysqldb-secret
key: database
- name: "DB_USERNAME"
valueFrom:
secretKeyRef:
name: my-mysqldb-secret
key: username
- name: "DB_PASSWORD"
valueFrom:
secretKeyRef:
name: my-mysqldb-secret
key: password
Pošleme to do AKS.
kubectl apply -f serviceCatalogDemo.yaml
V průběhu vytváření databáze bude náš kontejner v tomto stavu:
NAME READY STATUS RESTARTS AGE
env 0/1 CreateContainerConfigError 0 2m
Nemůže nastartovat, protože ještě nemá potřebné údaje pro start, v našem případě heslo do hotové databáze uložené jako Secret. Jakmile bude DB připravena vytvoří se i Secret a náš kontejner se rozjede.
Ověřme si, že kontejner opravdu vidí na potřebné připojovací údaje.
$ kubectl exec env -- env | grep DB
DB_USERNAME=n0skdtgdyz@a60a7d35-ad65-424c-9afb-c8b58df2b220
DB_PASSWORD=mPJTalBm8EQGEz16
DB_HOST=a60a7d35-ad65-424c-9afb-c8b58df2b220.mysql.database.azure.com
DB_PORT=3306
DB_DB=aemumu6xam
Helm nasazení celé aplikace včetně vytvoření databáze v Azure
Tohle všechno můžeme dát dohromady a vytvořit nasazení celé aplikace, které se postará o vytvoření Podů, objektů typu Service a také získání databáze as a service z Azure. K tomu lze použít Helm šablonu.
V Azure Helm repozitáři je připraven kompletní příklad na deploymend Wordpress s Azure databází.
$ helm repo add azure https://kubernetescharts.blob.core.windows.net/azure
"azure" has been added to your repositories
$ helm install azure/wordpress --name wp --set wordpressUsername=tomas \
> --set wordpressPassword=Azure12345678 \
> --set mysql.azure.location=westeurope
Wordpress bude mít veřejnou IP.
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 192.168.4.1 <none> 443/TCP 12d
myweb-service-ext-public LoadBalancer 192.168.7.232 23.97.177.196 80:30803/TCP 4d
wp-wordpress LoadBalancer 192.168.5.136 23.97.188.215 80:32468/TCP,443:31300/TCP 1m
Nějakou dobu také bude trvat, než se databáze v Azure nasadí.
$ svcat get instances
NAME NAMESPACE CLASS PLAN STATUS
+-----------------------------+-----------+-----------------+-----------------+--------------+
wp-wordpress-mysql-instance default azure-mysql-5-7 general-purpose Provisioning
Pak už najede i Pod a náš Wordpress s databází jako služba v Azure je připraven.
$ kubectl get pods -w
NAME READY STATUS RESTARTS AGE
ubuntu 1/1 Running 0 3d
wp-wordpress-9c5d98bdf-2ds8g 0/1 CreateContainerConfigError 0 2m
wp-wordpress-9c5d98bdf-2ds8g 0/1 Running 0 8m
wp-wordpress-9c5d98bdf-2ds8g 1/1 Running 0 11m
Chcete pro vývojáře plně spravovanou databázi v Azure tak, že ji mohou získat přímo Kubernetes prostředky bez nutnosti odskakovat do Azure interface? Proč se trápit s něčím takovým v kontejnerech, když jsou krásné hotové PaaS služby, které díky Service Catalog a OSBA do Kubernetes jednoduše a elegantně naintegrujete. Vyzkoušejte si to.