Je vícero způsobů jak migrovat on-premise SQL databázi do Azure SQL (tedy do hostované PaaS verze, migrace do SQL v Azure VM je jiná kapitola). Většina z nich vyžaduje nějaký čas, kdy se on-premise vypne, udělá se záloha a ta se obnoví v Azure SQL - podle množství dat to může trvat docela dlouho. Pokud chcete migrovat postupně tak, že například čtecí část aplikací už pojede v cloudu a zapisovací zatím on-premise a celé finální překlopení nechť otázkou chvilky, můžete zvolit transakční replikaci. V tomto scénáři jsou data v cloudu stejná (resp. jen o pár vteřin starší) jako data on-premise (to je rozdíl oproti stretch databázi, kde to funguje jakou tiering - o tom jindy).
O co jde? V zásadě on-premise verze bude obsluhovat aplikace, ale každou transakci také asynchronně zopakuje v příslušné Azure SQL (resp. při úvodním nastavení se pošle snapshot a pak jednotlivé transakce). Takto dokážete průběžně držet Azure SQL téměř shodný s on-premise verzí (třeba jen o pár vteřin pozadu). V rozhodný okamžik tak on-premise vypnete a aplikace pošlete na Azure SQL. Celkově to může proběhnout během několika minut (v jednoduchých příkladech bych si uměl představit i desítky vteřin).
Transakční replikace do Azure SQL
SQL Server má mnoho vlastností replikace. Role typu distributor, publisher, subscriber a různé metody - kromě transakční třeba i merge (dvoucestjné slučování). Azure SQL tento engine nemá, ale to nevadí. Nemůže mít roli distributor nebo publisher, ale to jako příjemce nepotřebuje. Azure SQL musí být jako subscriber typu push, tedy SQL Server na něj bude data aktivně tlačit.
Namířil jsem SQL Server Management Studio na SQL Server, kde mám tuto jednoduchou tabulku.
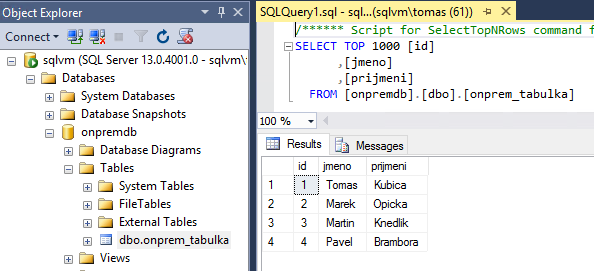
Budeme chtít tuto tabulku transakčně replikovat do Azure SQL. Nejprve vytvoříme distributora, kterým bude přímo ten stejný server. Současně budeme fungovat jako publisher.
V dalším kroku musíme říci co chceme replikovat, tedy vytvořit "publikaci".
Použijeme mojí onpremdb.
S Azure SQL potřebujeme transakční replikaci.
Můžeme si z databáze vybrat jen konkrétní tabulky a v nich dokonce jen některé sloupečky.
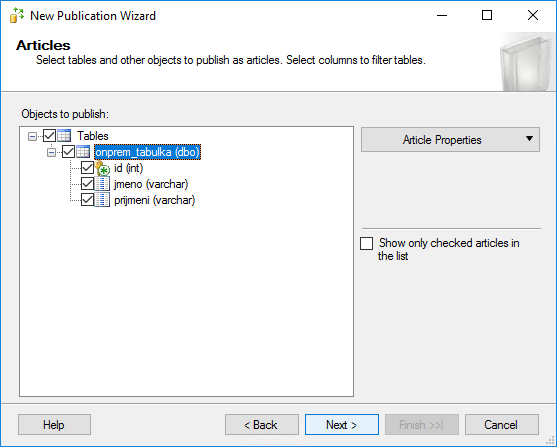
Stejně tak nemusíme replikovat všechny řádky. Můžeme použít nějaký filtr (já to dělat nebudu).
Na dalších stránkách průvodce jen vyřešíme bezpečnost (já pro jednoduchost použiji stejný account pro replikaci, což sice není ideální, ale je to jednoduché).
Teď už nám zbývá jen přidat odběratele, kterým bude naše Azure SQL databáze. Ta si neumí data stahovat sama, takže použijeme push z on-premise serveru. Přidejme subscribera.
Budeme posílat to, co jsme si před chvilkou vytvořili.
Použijeme push metodu.
Přidáme subscribera.
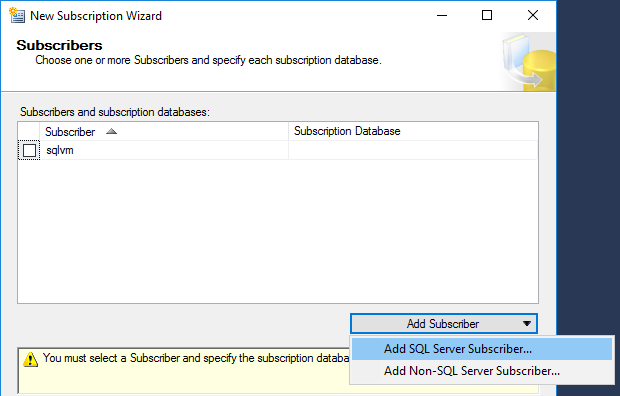
Namiřte na Azure SQL databázi, ale nezapomeňte, že IP adresa tohoto serveru musí být nastavena ve firewallu na Azure SQL virtuálním serveru.
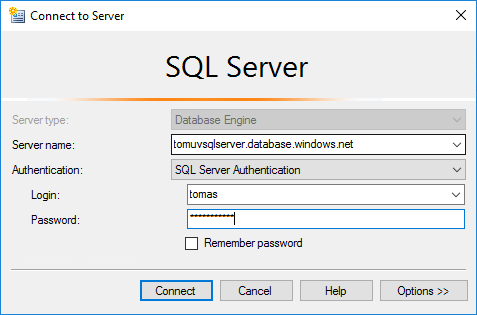
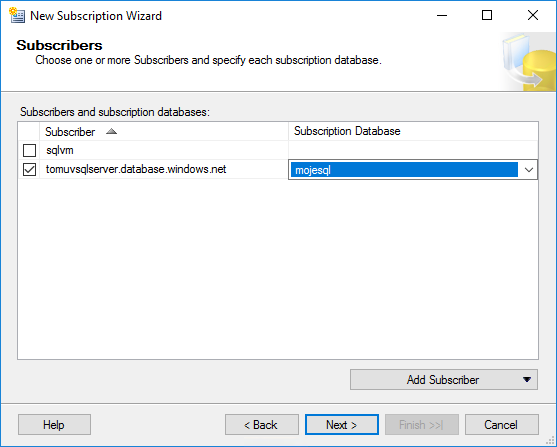
Pak už jen pořešíme bezpečnost (pod kterým accountem co provádět) a máme hotovo.
Můžeme se připojit do Azure SQL z management studia a uvidíte, že tabulka tam je.
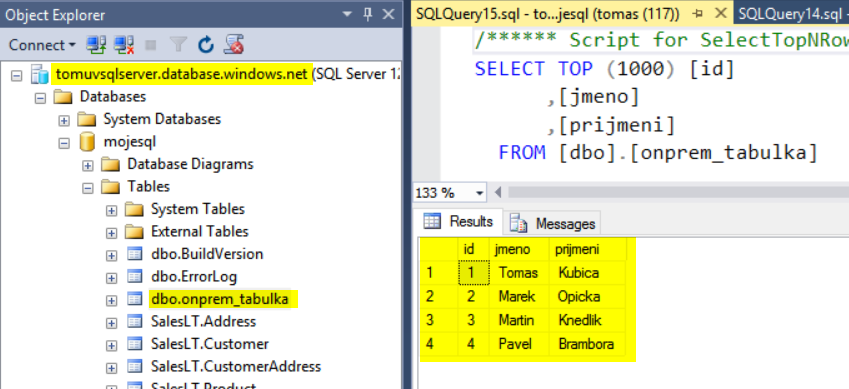
Šel jsem do on-premise serveru a přidal řádek a současně sledoval, kdy se objeví v Azure SQL databázi. V mém případě to trvalo asi 3 vteřiny. Samozřejmě to celé může záležet na objemu dat, kvalitě připojení, výkonu zdrojové serveru a tieru (DTU) Azure SQL, nicméně očekával bych hodnoty velmi příjemné.
Chcete velmi pozvolna a nenásilně migrovat on-premise SQL server do Azure SQL s nejkratší odstávkou? Replikace je myslím výborná volba!