V jednom z předchozích článků o Azure OpenAI jsem ukazoval, jak model skvěle zvládá sumarizaci tiskových zpráv ministerstva v češtině. Dnes zkusíme vytáhnout z textu klíčové informace a to dokonce strukturovanou formou ve formě JSON. Co je na tom úžasné je hlavně to, že je to pořád stejný model. Na co dosud byla specializovaná služba typu entity extraction, jiná na sumarizaci apod., tak tady “pouhý” jazykový model zvládá všechno najednou. Stačí se prostě zeptat. Zkusme si to.
První text a využití Azure Open AI studia
Vezmeme si nedávnou tiskovou zprávu v tomto znění:
Stav České pošty není dobrý, Ministerstvo vnitra proto připraví její transformaci Jednou z priorit Ministerstva vnitra pro letošní rok bude příprava transformace České pošty. Státní podnik se díky tomu změní v životaschopnou instituci. Poštu od 1. března 2023 dočasně povede dosavadní statutární zástupce generálního ředitele Miroslav Štěpán.
Ministerstvo vnitra letos připraví návrh transformace České pošty, která státnímu podniku umožní adekvátně reagovat na vývoj na poštovním trhu a stát se moderní institucí nabízející občanům moderní služby. Plány dalšího směřování České pošty dnes, 1. února 2023, představil ministr vnitra Vít Rakušan. Transformaci připraví meziresortní pracovní skupina. Cílem bude najít politickou shodu na tom, jakou podobu má státní podnik mít, jak se má dále rozvíjet, jak reagovat na digitalizaci a jaké služby nabízet. Jedním z hlavních předpokladů však je, že základní poštovní služby zůstanou zachovány a pobočky se nebudou rušit v malých městech a vesnicích. „Nutnou transformaci předchozí politické vedení léta odkládalo. Já si ji však beru za svou prioritu. Pošta se musí přizpůsobit novým trendům a my najdeme takové řešení, které poštu změní v moderní životaschopný podnik,“ uvedl ministr vnitra Vít Rakušan s tím, že je otázkou politické i odborné diskuse, zda se pošta např. rozdělí na část, která bude zajišťovat nutné a neziskové listovní služby, a na část, která je schopná generovat zisk. Podle ministra vnitra je politická shoda na tom, že transformace musí proběhnout co nejdříve a Ministerstvo vnitra nebude její přípravu odkládat.
Ministr vnitra také informoval o tom, že z výběrového řízení nevzešel vhodný kandidát na nového generálního ředitele. Současný generální ředitel proto skončí posledního února letošního roku a od 1. března poštu povede jeho statutární zástupce, ředitel divize státní poštovní služby Miroslav Štěpán. „Je skvělé, že poštu v době přípravy transformace povede manažer, který na poště řídí pro poštu i občany stěžejní pobočkovou síť,“ dodal Vít Rakušan. Teprve v době, až bude vytvořený konkrétní návrh transformace, vypíše Ministerstvo vnitra řádné výběrové řízení na generálního ředitele.
Diskuse se také povede o větší efektivitě pobočkové sítě, např. o tom, zda pošta opravdu potřebuje vlastnit velké a neúsporné pobočky nebo kolik poboček je třeba mít v jednom městě. Zásadní součástí této diskuse však bude komunikace s regiony, místními samosprávami a odbory. Platí také, že v malých městech a vesnicích se pobočky rušit nebudou.
Za tento text připojím svůj “dotaz”, tedy dost volnou formou řeknu, že bych chtěl vytáhnout nějaké informace a ještě z nich udělat JSON, ať se mi s tím později dobře pracuje v kódu.
Vytáhni následující informace ve formátu JSON:
Hlavní předmět textu as topic, osoby as persons, instituce as institutions, abstract o délce 100 znaků.
Myslíte, že takhle “lidsky” formulovaný OpenAI pochopí a vrátí strukturovaný výsledek? Nahodil jsem ve grafickém studiu.
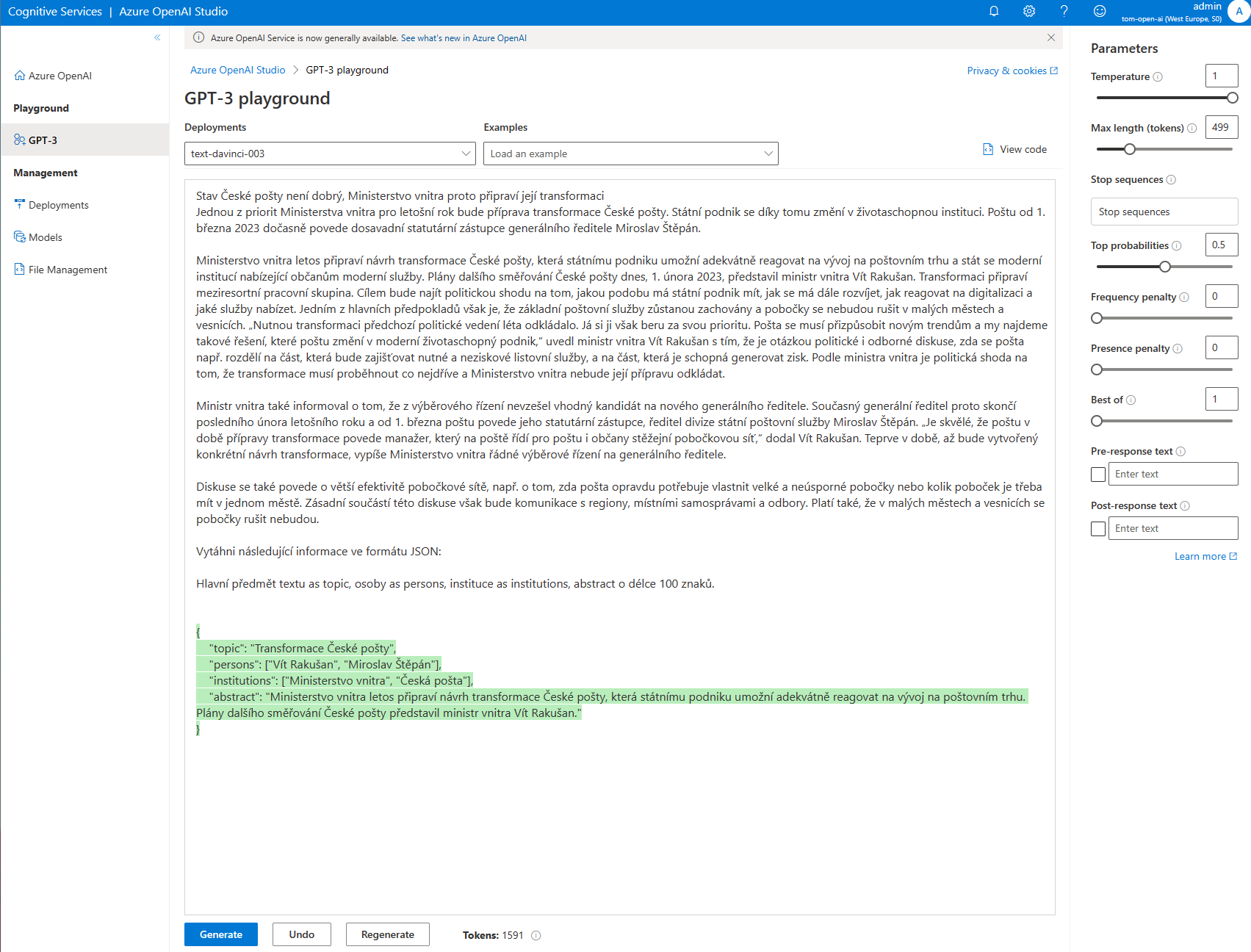
Tohle je výsledný JSON. Za mě - skvělé!
{
"topic": "Transformace České pošty",
"persons": ["Vít Rakušan", "Miroslav Štěpán"],
"institutions": ["Ministerstvo vnitra", "Česká pošta"],
"abstract": "Ministerstvo vnitra letos připraví návrh transformace České pošty, která státnímu podniku umožní adekvátně reagovat na vývoj na poštovním trhu. Plány dalšího směřování České pošty představil ministr vnitra Vít Rakušan."
}
Abstrakt je defacto totéž co sumarizace v minulém článku, jen jsem ji chtěl takhle stručnější. Title opravdu vytáhl to podstatné a určitě se to dá považovat za takový nadpis. Osoby a instituce to našlo taky dobře. A teď si vezměte, že výsledkem je validní JSON. Není to naprogramované na vracení JSON, není to zaměřené na extrakci entit. Jazykový model je tak mocný, že to pochopil a validní JSON zvládl jen tak sám od sebe.
20 tiskových zpráv
Není to jen náhoda? Zkusme napsat trochu kódu a udělat to pro 20 tiskových zpráv tohoto ministerstva. Zdrojáky jsou u mě na GitHubu: https://github.com/tkubica12/ai-demos/tree/main/openai/src/parsing
Tady je kód - nic složitého. Načtu obsah souborů z adresáře (mám tam co txt file, to tisková zpráva) do Pandas DataFrame, připravím si lambda funkci, která k textu přidá můj volně napsaný “příkaz” co chci dosáhnout a provolám ji přes apply na DataFrame. Jediná možná nezvyklost je, že potřebuji vrátit/vytvořit vícero sloupečků, ale to není problém.
import os
import openai
import csv
import json
import pandas as pd
openai.api_type = "azure"
openai.api_base = os.getenv("OPENAI_API_URL")
openai.api_version = "2022-12-01"
openai.api_key = os.getenv("OPENAI_API_KEY")
# Exit if the environment variables are not set
if "OPENAI_API_URL" not in os.environ or "OPENAI_API_KEY" not in os.environ:
raise Exception("Please set OPENAI_API_KEY and OPENAI_API_URL environment variable")
# Input folder
input_folder = "../../datasets/press_releases_ministry_cz"
# Read content of all files in the input folder into Pandas DataFrame
df = pd.DataFrame()
for file in os.listdir(input_folder):
with open(os.path.join(input_folder, file), 'r') as f:
content = f.read()
df = df.append({"file": file, "content": content}, ignore_index=True)
# Define lambda function calling OpenAI API and returning parsed information
def openai_parse(text, file):
print(f"Processing {file}")
prompt = text + "\n\nVytáhni následující informace ve formátu JSON:\n\nHlavní předmět textu as topic, osoby as persons, instituce as institutions, abstract o délce 100 znaků.\n\n"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=1,
max_tokens=500,
top_p=0.5,
frequency_penalty=0,
presence_penalty=0,
stop=None)
# Try parse response as JSON
try:
data = json.loads(response.choices[0].text)
except:
print("Not valid JSON")
return data['topic'], data['persons'], data['institutions'], data['abstract']
# Use OpenAI to parse content
df['topic'], df['persons'], df['institutions'], df['abstract'] = zip(*df.apply(lambda x: openai_parse(x["content"], x["file"]), axis=1))
# Write output files
print("Writing output files")
df.to_json("output_full.json", orient="records")
df.drop(['content'], axis = 1, inplace = False).to_json("output.json", orient="records")
df.to_csv("output.csv", index=True)
Výsledky jsou podle mého názoru naprosto úžasné. Kromě výstupů na GitHubu jsem je nahnal i do tabulky a udělal pár screenů (je to malinkaté, ale snad to uvidíte - chtěl jsem tam mít všechno včetně původního textu, ať můžete sami posoudit, jak moc se OpenAI zadařilo). Nebo se mrkněte přímo do souborů zde: https://github.com/tkubica12/ai-demos/tree/main/openai/src/parsing
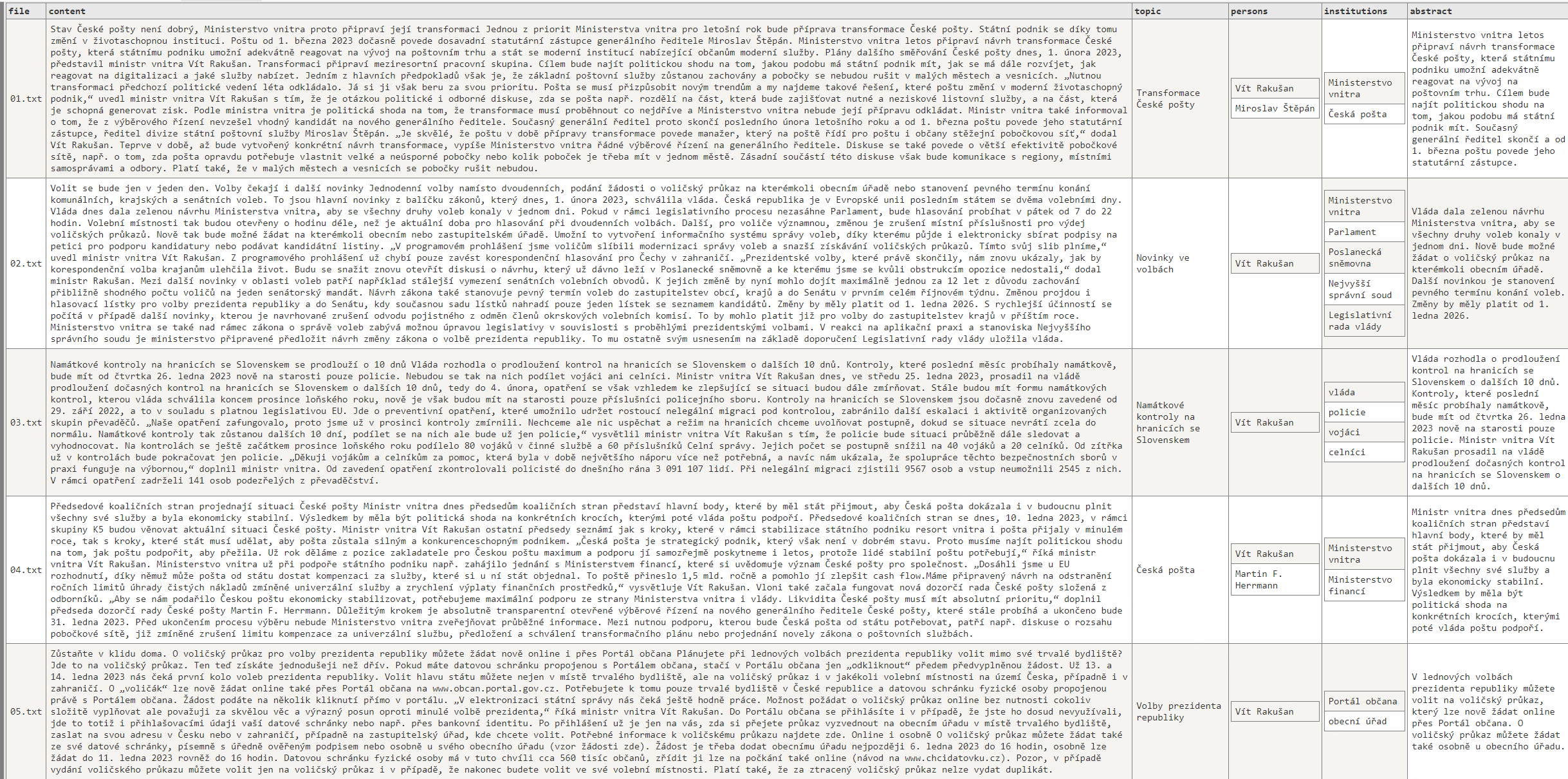


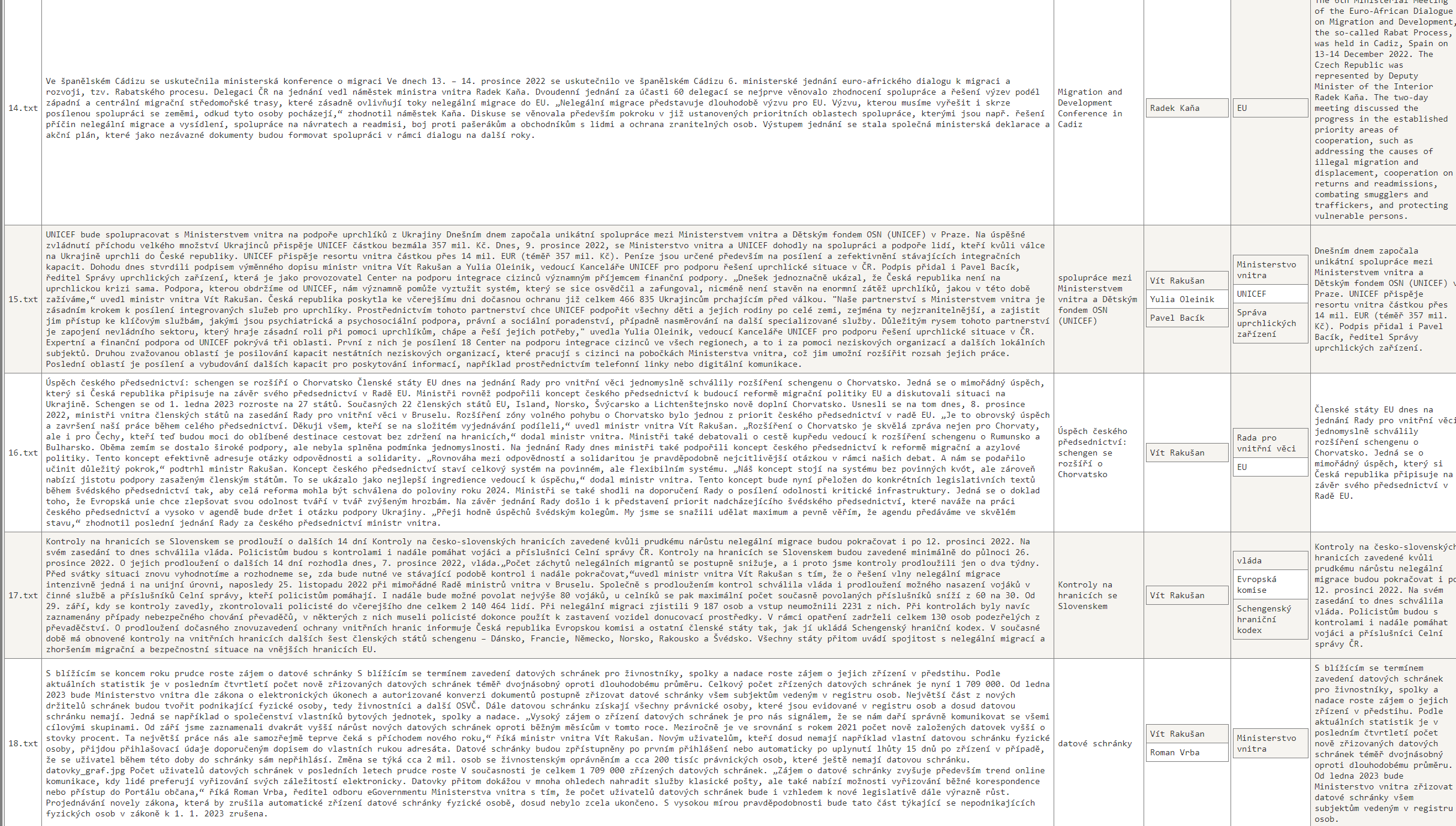

Podle mě tohle zafungovalo skvěle. A co náklady? Vstupy jsou asi 25 000 tokenů, výstup do 500 (ale v průměru vrací tak 200) takže 10 000 maximálně na výstupy. To by mělo být nějakých 0,014 USD za dvacet tiskových zpráv.
Ještě nekončíme - příště mě bude zajímat jestli dává smysl tenhle model použít i pro překládání a jak dobré výsledky dosáhnu v porovnání se specializovanými službami Microsoftu a Googlu. Bude OpenAI dávat čitelnější, ale méně přesné překlady? Jak moc bude zásadní možnost ladit specializované modely, která u OpenAI asi bude pro tyto účely chybět (třeba přidání vlastního žargonu)?