V rámci přípravy na certifikaci Azure Data Scientist Associate jsem si udělal praktické hřišťátko na pipeline s využitím CLI v2, MLFlow, komponent, hledání hyperparametrů i zřízení vlastních environmentů ve formě Docker kontejnerů. Rád bych se podělil o pár postřehů.
Jako vždy automatizovanou infrastrukturu a všechny potřebné podklady najdete na mém GitHubu zde.
Základní myšlenka - co krok, to Docker kontejner
Pod kapotou každého kroku je prostě Docker image spuštěný v orchestrátoru jako je Kubernetes - pro mě díky prostředí, z kterého pocházím, skvělá a moderní varianta. Přestože svoje experimenty se Sparkem v rámci Azure Databricks si velmi užívám, balit kroky do kontejnerů a neřešit orchestrátor je prostě univerzální a může potenciálně fungovat od Raspberry Pi, edge zařízení, Kubernetes v cloudu až po nějaké platformní služby, kde infrastrukturní blbinky typu Kubernetes vůbec nemusíte řešit. Jinak řečeno pro zapouzdření a spuštění třeba trénovacího jobu s jeho verzemi Pythonu a různých knihoven nemáte jinou dependenci než řekněme Docker - a stejně jako v aplikacích to co spustíte na svém notebooku pak běží i v produkci (samozřejmě pro orchestrovanou pipeline už budete potřebovat Kubernetes). O tom, jak Azure Machine Learning využívá libovolný Kubernetes cluster (přes Arc) nebo Azure Kubernetes Service pro běh ML záležitostí, tedy rozšíření Kubernetes o lepší orchestraci batch workloadů díky projektu Volcano, jsem psal zde.
Slon v místnosti aneb v1 vs. v2
Než se dostaneme k těm příjemným věcem musím zmínit něco, co mi vadí - Azure ML se vydalo za mě rozhodně správnou cestou, ale protože je to oblíbená služba a mnoho už bylo vytvořeno, tak ta nová cesta je v2, jenže hodně školících materiálů, návodů ale i přímo Microsoft technologií (produkční verze AutoML, grafický designer) stále stojí na v1. To je nepříjemné a velmi matoucí. Všechno co budu popisovat dnes je postaveno na v2.
CLI vs. SDK vs. GUI
Azure ML je nástroj, který vlastně bere kousky kódu, které dělají různé operace typu trénování modelu a zajišťuje jejich spuštění (managed compute, Kubernetes, Spark jako je Databricks nebo Synapse) v nějakém pořadí, stromu a s namapovanými daty a parametry, vytažení výsledných metrik či modelů. Ať už jste si kód napsali sami (to je případ dnešního článku) nebo ho pro vás vygeneroval přímo nástroj (v případě grafického designeru nebo AutoML, kde se mimochodem na výsledný kód můžete podívat). Téma CLI vs. SDK vs. GUI se tak netýká trénování samotného, ale toho control plane a management plane - jaké operace jak za sebou řetězit, jak a kam uložit data, výsledné modely, jak nasadit model pro inferencing apod.
Historicky bylo základem SDK, kdy jste vycházeli z předpokladu, že vědec tak jako tak sedí v programovacím jazyce typu Python, Scala nebo R, takže dává největší smysl, aby napsal kód tak jako před tím, ale přes SDK ho spustil ve formě jobu v cloudu (a pak se pustil do složitějších věcí jako pipeline apod.). Tak například nadstavba do populárního sklearn umožňuje jednoduše při vytvoření estimátoru říct “jo… ale to zpracování udělej tady v AzureML, ne na mém počítači”. Z pohledu nějaké automatizace a DevOps to ale podle mě vede na sněhové vločky, kterým rozumí už jen ten vědec, takže pro svoje účely tento přístup nepreferuji.
CLI se sice jmenuje jakože jde o příkazovou řádku, ale za mně to tak vlastně není. Ve skutečnosti to CLI jen pošle YAML soubor s předpisem do API. Třeba Azure CLI vám v přepínačích umožní definovat všechny parametry vašeho VM, ale Azure ML CLI nic takového neumí - jen pošle YAML nahoru. Je to tedy trochu podobné kubectl apply -f v Kubernetu (mimochodem kubectl je nejen posílač, ale historicky obsahuje i plné imperativní cli typu kubectl run nginx --image-nginx --port=5701 jen ho naštěstí v době příčetnosti a deklarativních přístupů už nikdo moc nepoužívá). Všechny objekty jsou tedy nějaký YAML soubor, který se dá dobře verzovat v Gitu a automatizovat v CI/CD a to mi velmi vyhovuje. Je hrozná škoda, že svět dat pořád ještě není na úrovni aplikačního vývoje a hodně mi chybí GitOps nástroje (tlačit YAMLy přes CLI notabene když musíte volit CLI příkaz podle typu objektu je trochu prehistorické … kde je Flux nebo Argo pro ML prosím?) nebo třeba i obyčejné semantické verzování (ve světě ML je velká událost, že dokážete modely verzovat a to je určitě dobře … nicméně verze 1..2..3..4 mě tedy neuspokojují tolik, jako nějaké major.minor.patch, kdy budu vědět jestli změna jen vylepšuje model bez změny rozhraní nebo vrací nová data navíc nebo jestli je to přepracované a má to jiné vstupy a výstupy). Ale hlavní feedback za mě - prosím ať je něco jako az ml apply - proč musím použít pro každý objekt jiný příkaz, když tam pokaždé stejně vkládám YAML v jehož schématu je jasně napsáno o jaký objekt se jedná.
GUI je v AzureML skvělé pro monitoring a dá se v něm dobře i registrovat nebo nasazovat model, zakládat data a tak podobně. Nicméně jsou tam viditelné mezery - graficky si pipeline z vlastních komponent zatím nepřipravíte, to co jde graficky je pro v1 věci a tak podobně. Nicméně - UI studio, byť má pod kapotou v1, je určitě výborný studijní materiál, pokud chcete sami postavit ML aniž byste lezli do Pythonu. AutoML taky zařídíte krásně graficky… ale třeba fakt, že na vstupu potřebujete Data objekt v tabulárním formátu (v1) a novější MLTable (v2) v GUI nejde a v YAMLu asi ano, ale dokumentace k tomu prakticky není, je rozhodně škoda. Ale to je myslím všechno jen otázkou času.
Komponenty a jejich znovupoužitelnost
V grafickém designeru (v1 záležitost) si berete kostičky s různými funkcemi, vstupy a výstupy a ty mezi sebou propojujete. Třeba nějaká příprava dat (ubrání nebo vybrání sloupce, normalizaci, one hot encoding kategorických features apod.), trénování, scoring, vyhodnocení modelů apod. Něco podobného si můžete sami připravit ve formě komponent, tedy vlastního kódu, u kterého definujete vstupy a výstupy.
Takhle vypadá YAML předpis pro mojí komponentu split, jejímž úkolem je rozdělit data na trénovací a testovací podle zadaného poměru. Vstupem je dataset ve formě CSV souboru, výstupem jsou 4 CSV soubory pro trénovací a testovací data a jejich labely.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: split
display_name: split
is_deterministic: true
code: ./src/
inputs:
data:
type: uri_folder
file_name:
type: string
label_name:
type: string
test_size:
type: number
outputs:
train:
type: uri_folder
test:
type: uri_folder
environment: azureml:AzureML-sklearn-0.24-ubuntu18.04-py37-cpu@latest
command: >-
python run.py --data $/$ \
--output-path-train $ \
--output-path-test $ \
--label-name $ \
--test-size $;
Zdrojový kód run.py pak zpracovává vstupy a generuje výstupy - všechno jsou to adresáře, které platforma dovnitř kontejneru umí namountovat.
import argparse
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
parser = argparse.ArgumentParser("prep")
parser.add_argument("--data", type=str, help="Data file")
parser.add_argument("--label-name", type=str, help="Name of label column")
parser.add_argument("--output-path-train", type=str, help="Path where to save train output files")
parser.add_argument("--output-path-test", type=str, help="Path where to save test output files")
parser.add_argument("--test-size", type=float, help="Percentage of data for test set")
args = parser.parse_args()
print(f"Data file: {args.data}",)
print(f"Label name: {args.label_name}",)
print(f"Output train path: {args.output_path_train}",)
print(f"Output test path: {args.output_path_test}",)
# Load data
df = pd.read_csv(args.data)
# Get features and labels
X = df.drop(args.label_name,axis=1).values
y = df[args.label_name].values
# Split data into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
# Save outputs
np.savetxt(args.output_path_train+"/X_train.csv", X_train, delimiter=",")
np.savetxt(args.output_path_test+"/X_test.csv", X_test, delimiter=",")
np.savetxt(args.output_path_train+"/y_train.csv", y_train, delimiter=",")
np.savetxt(args.output_path_test+"/y_test.csv", y_test, delimiter=",")
Tuto a další komponenty pak budeme volat v rámci pipeline.
Vlastní environment pro případ, že potřebujete speciální knihovny
V rámci komponent, které jsem si připravil, byla i oversampling funkce SMOTE s využitím knihovny imbalance-learn. Ta se používá v situacích, kdy je klasifikační problém značně nevyrovnaný, tedy máte label “true” třeba jen v 0.1% případů a zbytek je “false” (což pak vede na přecitlivělost modelu a tím jeho horší výsledky). Podstatné je, že příslušná knihovna není v žádném z Microsoftem spravovaných image (environmentů), takže bylo potřeba si vytvořit vlastní. Jsou v zásadě tři metody:
- Přinést si vlastní Docker image vybudovaný kdekoli jakkoli
- Přinést si vlastní Dockerfile
- Přinést si vlastní Conda environment
Já jsem zvolil vlastní Dockerfile (AzureML ho pro mě zbuilduje a image si uloží), který vypadá takto:
FROM mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20220930.v1
ENV AZUREML_CONDA_ENVIRONMENT_PATH /azureml-envs/sklearn-0.24.1
# Create conda environment
RUN conda create -p $AZUREML_CONDA_ENVIRONMENT_PATH \
python=3.7 pip=20.2.4
# Prepend path to AzureML conda environment
ENV PATH $AZUREML_CONDA_ENVIRONMENT_PATH/bin:$PATH
# Install pip dependencies
RUN pip install 'matplotlib>=3.3,<3.4' \
'psutil>=5.8,<5.9' \
'tqdm>=4.59,<4.60' \
'pandas>=1.1,<1.2' \
'scipy>=1.5,<1.6' \
'numpy>=1.10,<1.20' \
'ipykernel~=6.0' \
'azureml-core==1.47.0' \
'azureml-defaults==1.47.0' \
'azureml-mlflow==1.47.0' \
'azureml-telemetry==1.47.0' \
'scikit-learn==1.0.2' \
'debugpy~=1.6.3' \
'imbalanced-learn==0.10.1'
# This is needed for mpi to locate libpython
ENV LD_LIBRARY_PATH $AZUREML_CONDA_ENVIRONMENT_PATH/lib:$LD_LIBRARY_PATH
A tohle je YAML přepis.
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: imbalanced-learning
build:
path: .
description: Environment for imbalanced learning preparation

Díky tomu jsem pro svou komponentu mohl použít toto prostředí a zajistit tak, že v něm knihovna imbalance-learn funguje.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: oversample
display_name: oversample
is_deterministic: true
code: ./src/
inputs:
train_input:
type: uri_folder
outputs:
train:
type: uri_folder
environment: azureml:imbalanced-learning@latest
command: >-
python run.py --output-path-train $ \
--input-x-train $/X_train.csv \
--input-y-train $/y_train.csv;
import argparse
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
parser = argparse.ArgumentParser("prep")
parser.add_argument("--output-path-train", type=str, help="Path where to save train output files")
parser.add_argument("--input-x-train", type=str, help="File where to expect train input files")
parser.add_argument("--input-y-train", type=str, help="File where to expect train input files")
args = parser.parse_args()
print(f"Output train path: {args.output_path_train}",)
print(f"Input x train file: {args.input_x_train}",)
print(f"Input y train file: {args.input_y_train}",)
# Load data
X_train = np.loadtxt(args.input_x_train, delimiter=",", dtype=float)
y_train = np.loadtxt(args.input_y_train, delimiter=",", dtype=float)
# Oversample train data to get more balanced label
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state = 2)
X_train, y_train = sm.fit_resample(X_train, y_train.ravel())
# Save outputs
np.savetxt(args.output_path_train+"/X_train.csv", X_train, delimiter=",")
np.savetxt(args.output_path_train+"/y_train.csv", y_train, delimiter=",")
MLflow jako otevřený standard pro sbírání modelů, logů, parametrů i registraci
Databricks, fantastická platforma pro zpracování dat ve Sparku, ale v poslední době i v oblasti strojového učení, dal světu MLFlow - otevřený standard a Azure ML ho ve v2 implementaci plně využívá. Váš kód i znalosti tak mohou být opravdu univerzální a to, co použijete v rámci Azure ML vám bude fungovat i na vlastním Raspberry Pi nebo v Azure Databricks. Co mi nefungovalo je kombinace autologu s vlastními metrikami, tak jsem si instrumentaci udělal sám.
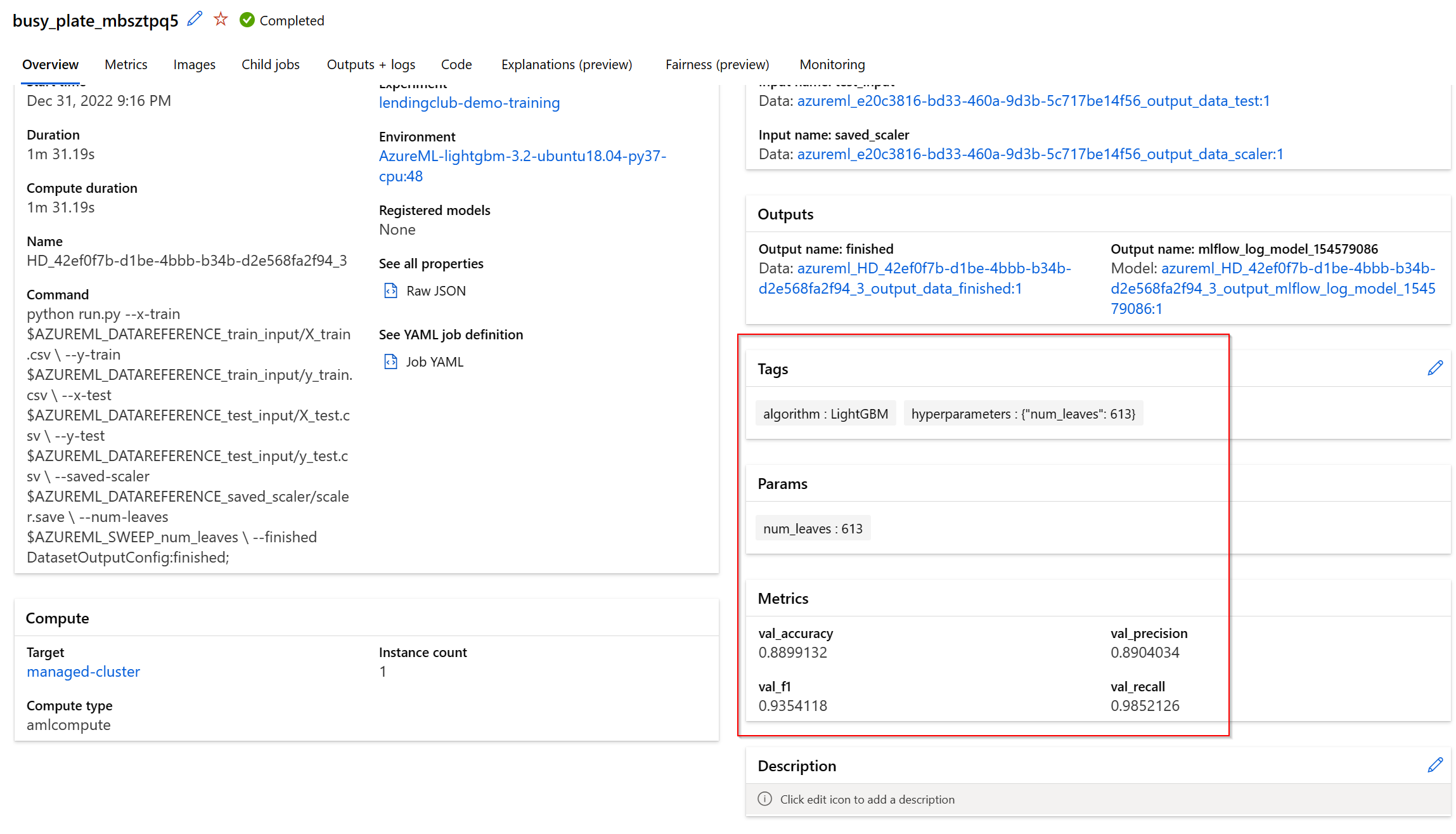
Tady je příklad kódu pro jeden z modelů, který v rámci pipeline počítám - LightGBM. Všimněte si, že používám naprosto standardní MLFlow příkazy:
- Přidávám tag, ve kterém si ukládám použitý algoritmus
- Přidávám vlastní artefakt (soubor), ve kterém mám uložen MixMaxScaler z předchozího kroku (když pak budu dělat inferencing, najdu ho přímo u modelu)
- Zaloguji model jako takový
- Udělám scoring výsledného modelu proti testovacím datům, vyhodnotím metriky a zaloguji je přes MLFlow
import argparse
import pandas as pd
import numpy as np
import mlflow
parser = argparse.ArgumentParser("prep")
parser.add_argument("--x-train", type=str, help="Training features file")
parser.add_argument("--x-test", type=str, help="Testing features file")
parser.add_argument("--y-train", type=str, help="Training labels file")
parser.add_argument("--y-test", type=str, help="Testing labels file")
parser.add_argument("--saved-scaler", type=str, help="SSaved scaler file to log with model as artefact")
parser.add_argument("--num-leaves", type=int, help="Number of leaves hyperparameter")
parser.add_argument("--finished", type=str)
args = parser.parse_args()
# Load data
X_train = np.loadtxt(args.x_train, delimiter=",", dtype=float)
X_test = np.loadtxt(args.x_test, delimiter=",", dtype=float)
y_train = np.loadtxt(args.y_train, delimiter=",", dtype=float)
y_test = np.loadtxt(args.y_test, delimiter=",", dtype=float)
# Set tag
mlflow.set_tag("algorithm", "LightGBM")
# Log scaler artefact
mlflow.log_artifact(args.saved_scaler, "model")
# Fit model
from lightgbm import LGBMClassifier
classifier = LGBMClassifier(num_leaves=args.num_leaves)
classifier.fit(X_train, y_train)
# Log model
mlflow.lightgbm.log_model(classifier, "model")
# Log parameters
mlflow.log_param("num_leaves", classifier.num_leaves)
# Make predictions
y_pred = classifier.predict(X_test)
# Log metrics
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, auc
mlflow.log_metric("val_accuracy", accuracy_score(y_test, y_pred))
mlflow.log_metric('val_precision',precision_score(y_test, y_pred))
mlflow.log_metric('val_recall',recall_score(y_test, y_pred))
mlflow.log_metric('val_f1',f1_score(y_test, y_pred))
print(f"val_accuracy: {accuracy_score(y_test, y_pred)}")
# Finished
from pathlib import Path
Path(args.finished).touch()
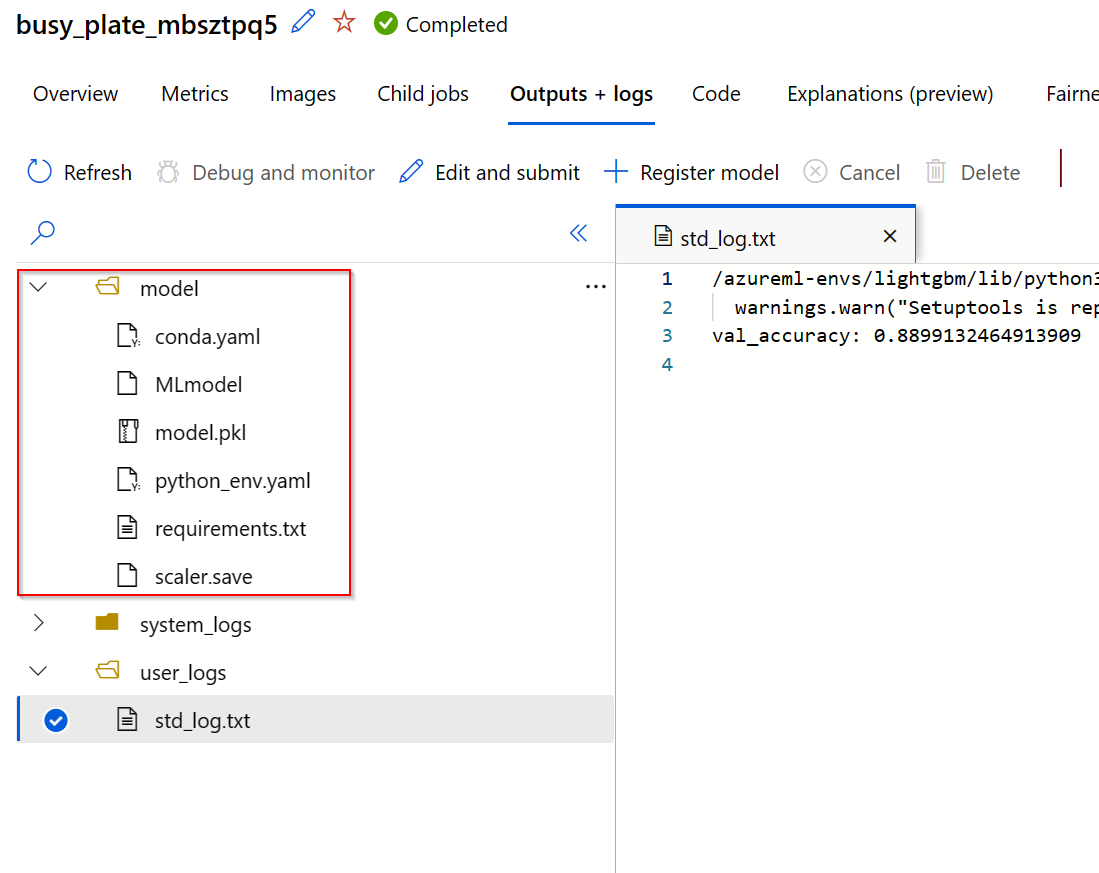
Tohle všechno pak u příslušného běhu v Azure ML najdu.
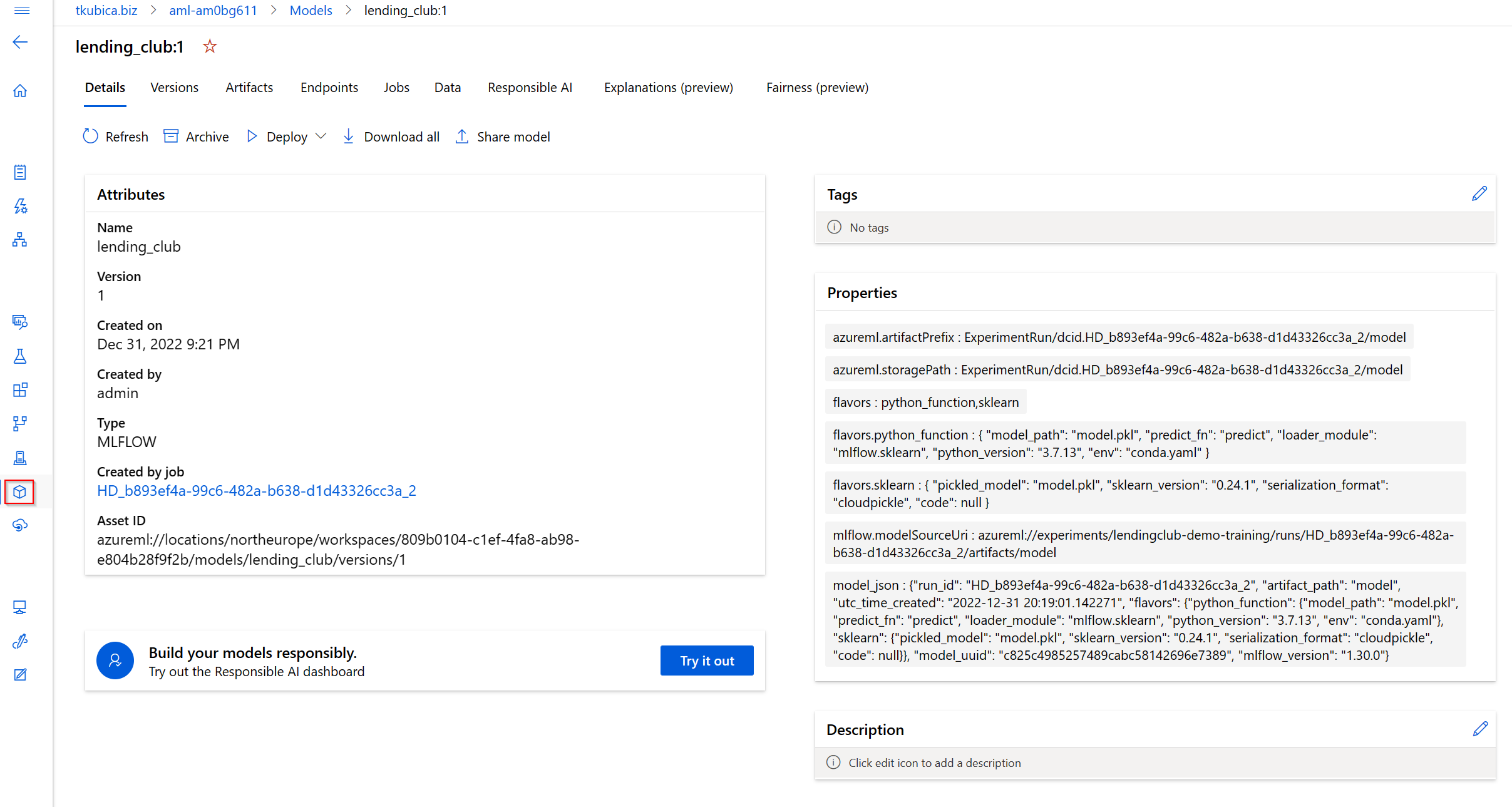
MLFlow jsem použil i pro výběr nejlepšího modelu a jeho registraci.
import argparse
from pathlib import Path
import pickle
import mlflow
from azureml.core import Run, Experiment
# Get current experiment and root run ID
experiment_name = Run.get_context().parent.experiment.name
root_run_id = Run.get_context().parent.id
print(f"Experiment name: {experiment_name}")
print(f"Root run id: {root_run_id}")
# Find all runs with the same root run ID
filter_string = f"tags.mlflow.rootRunId='{root_run_id}'"
runs = mlflow.search_runs(experiment_names=experiment_name, filter_string=filter_string)
# Print all models
print(runs[["metrics.val_accuracy", "tags.algorithm", "tags.hyperparameters"]].sort_values(by="metrics.val_accuracy", ascending=False))
print("-------------------")
# Find best model
best_model = runs[["run_id", "metrics.val_accuracy", "tags.algorithm", "tags.hyperparameters"]].sort_values(by="metrics.val_accuracy", ascending=False).head(1)
best_run_id = best_model["run_id"].iloc[0]
best_metric = best_model["metrics.val_accuracy"].iloc[0]
best_algorithm = best_model["tags.algorithm"].iloc[0]
best_hyperparameters = best_model["tags.hyperparameters"].iloc[0]
print(f"Best run id: {best_run_id}")
print(f"Best metric: {best_metric}")
print(f"Best algorithm: {best_algorithm}")
print(f"Best hyperparameters: {best_hyperparameters}")
# Register model
model_name = "lending_club"
model_path = f"runs:/{best_run_id}/model"
model = mlflow.register_model(model_uri=model_path, name=model_name)
Pipeline
Celá pipeline jak je vidět v GUI vypadá takto.
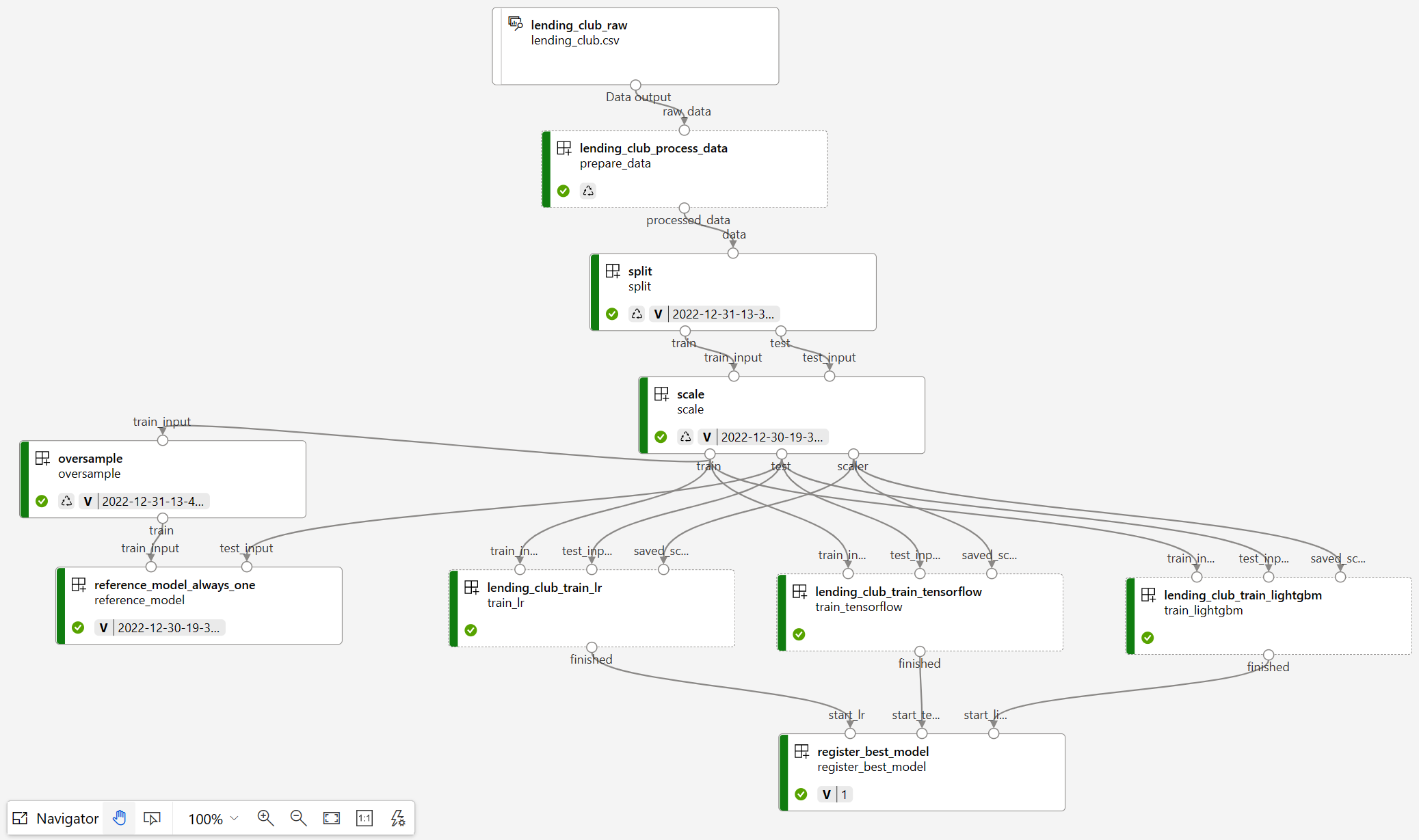
Všechno je to v následující YAML definici. Většina je myslím přímočará a dobře pochopitelná, tak okomentuji jen pár věcí.
Potřeboval bych, aby komponenta pro registraci nejlepšího modelu běžela až po té, co jsou všechny spočítané. Z v1 produkt evidentně počítal s tím, že se vždycky něco předává, konkrétně model je na výstupu a na vstupu, jenže tohle já chci samozřejmě dělat přes MLFlow. Nic si tedy předávat nepotřebuji, jen na sebe počkat - registrační komponenta si přes MLFlow projde výsledky všech jobů v právě běžícím experimentu. Zřejmě ale nic takového udělat nejde - tedy definovat návaznost komponent bez skutečného předávání, takže jsem musel jako workaround předávat obsah adresáře, kde udělám jen touch, aby vznikl prázdný soubor. Díky tomu komponenta register_best_model počká, než jsou hotové všechny modely v Logistic Regression, LightGBM a TensorFlow.
V pipelne používám svoje komponenty split, scale, oversample, register_best_model a reference_always_one (komponenta, která použije model, který jednoduše vždycky vrátí hodnotu 1 - základ pro odvzození kvality dalších modelů). Aktuálně využívám verzi “latest”, což určitě není dobře (ale pro demo je to nejjednodušší). Třeba vlastník komponenty oversample může později udělat konfigurovatelnou metodu místo natvrdo využívat SMOTE. V nové verzi komponenty tak může přidat parametr zda zvolit SMOTE nebo RandomOverSampler. Možná budou některé tyto změny dokonce “breaking”, tedy budou vyžadovat změnu v parametrech (tedy ve způsobu použití). Díky použití verzování ve své pipeline budu používat konkrétní verzi a nikdo mě nenutí přejít na vyšší, dokud nebudu připraven. Zkrátka - to co je běžné u vývojé mikroslužeb v software se postupně dostává i do oblasti strojového učení.
Komponenty mají ve své definici jednu velmi zajímavou volbu - is_deterministic. To způsobí, že pokud je to true a nedošlo k žádné změně kódu nebo vstupních dat, pipeline použije výsledky z předchozího běho, pokud ten existuje. Zejména pokud něco ladíte je to výborná věc - nemusíte pořád čekat. V jobu můžete i přímo odkázat na kód (místo komponenty), pak ale o tuhle možnost přijdete. Na druhou stranu - publikovaná komponenta by měla být znovupoužitelná a ne specifická pro konkrétní pipeline. Našel jsem ale jeden výborný kompromis - můžete použít komponentu, ale ne z “registru”, ale přímo odkazem na soubor. Tím využíváte příjemných vlastností komponent a přitom se neverzují a nedrží zvlášť, což pokud jsou specifické pro vaši pipeline je přesně co chceme. Mým příkladem je job prepare_data, který dělá specificky čištění a přípravu dat pro konkrétní úlohu.
Všimněte si, že přímo pipeline dokáže dělat hyperparameter tuning díky typu jobu sweep. V případě jobu train_lr a train_tensorflow jsem použil klasický grid, tedy chci projít určité konkrétní možnosti nastavení (u LR je nastavení solveru a u TensorFlow takhle zkouším různé varianty hodnot dropout mezi vrstvami). U train_lightgbm jsem použil náhodný výběr, kdy zkouším náhodné hodnoty 0-1000 pro hyperparametr num_leaves).
Tak - a tady už slíbený YAML.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
description: Tomas lendingclub demo pipeline
display_name: lendingclub-demo-training
experiment_name: lendingclub-demo-training
settings:
default_datastore: azureml:workspaceblobstore
default_compute: azureml:managed-cluster
jobs:
prepare_data:
inputs:
raw_data:
type: uri_file
path: azureml:lending_club_raw:1
mode: ro_mount
type: command
component: file:../components/lending_club_process_data/component.yaml
outputs:
processed_data:
split:
inputs:
data:
type: uri_file
path: $
mode: ro_mount
label_name: loan_repaid
file_name: lending_club.csv
test_size: 0.2
type: command
component: azureml:split@latest
outputs:
train:
test:
scale:
inputs:
train_input:
type: uri_file
path: $
mode: ro_mount
test_input:
type: uri_file
path: $
mode: ro_mount
type: command
component: azureml:scale@latest
outputs:
train:
test:
scaler:
oversample:
inputs:
train_input:
type: uri_file
path: $
mode: ro_mount
type: command
component: azureml:oversample@latest
outputs:
train:
reference_model:
inputs:
train_input:
type: uri_file
path: $
mode: ro_mount
test_input:
type: uri_file
path: $
mode: ro_mount
type: command
component: azureml:reference_model_always_one@latest
train_lr:
inputs:
train_input:
type: uri_file
path: $
mode: ro_mount
test_input:
type: uri_file
path: $
mode: ro_mount
saved_scaler:
type: uri_file
path: $
mode: ro_mount
outputs:
finished:
type: sweep
objective:
goal: maximize
primary_metric: training_accuracy_score
sampling_algorithm: grid
search_space:
solver:
type: choice
values: ['lbfgs', 'sag', 'saga', 'newton-cg']
trial: ../components/lending_club_train_lr/component.yaml
limits:
max_total_trials: 10
max_concurrent_trials: 10
timeout: 7200
train_lightgbm:
inputs:
train_input:
type: uri_file
path: $
mode: ro_mount
test_input:
type: uri_file
path: $
mode: ro_mount
saved_scaler:
type: uri_file
path: $
mode: ro_mount
outputs:
finished:
type: sweep
objective:
goal: maximize
primary_metric: training_accuracy_score
sampling_algorithm: random
search_space:
num_leaves:
type: randint
upper: 1000
trial: ../components/lending_club_train_lightgbm/component.yaml
limits:
max_total_trials: 5
max_concurrent_trials: 10
timeout: 7200
train_tensorflow:
inputs:
train_input:
type: uri_file
path: $
mode: ro_mount
test_input:
type: uri_file
path: $
mode: ro_mount
saved_scaler:
type: uri_file
path: $
mode: ro_mount
outputs:
finished:
type: sweep
objective:
goal: maximize
primary_metric: val_accuracy
sampling_algorithm: grid
search_space:
dropout:
type: choice
values: [0.01, 0.1, 0.2, 0.5]
trial: ../components/lending_club_train_tensorflow/component.yaml
limits:
max_total_trials: 20
max_concurrent_trials: 10
timeout: 7200
register_best_model:
inputs:
start_lr: $
start_tensorflow: $
start_lightgbm: $
type: command
component: azureml:register_best_model@latest
Infrastruktura jako kód s Terraform
Pochopitelně všechny infrastrukturní zálěžitosti řeším přes Infrastructure as Code, v tomto případě s Terraform. Složitější to bylo spíš jen s AKS a jeho extension pro Azure ML, kdy jsem musel použít AzApi (ale o tom už jsem psal - vše je na GitHubu), ostatní standardní věci jsou jednoduché.
resource "azurerm_application_insights" "demo" {
name = "appi-${random_string.random.result}"
location = azurerm_resource_group.demo.location
resource_group_name = azurerm_resource_group.demo.name
application_type = "web"
}
resource "azurerm_key_vault" "demo" {
name = "kv-${random_string.random.result}"
location = azurerm_resource_group.demo.location
resource_group_name = azurerm_resource_group.demo.name
tenant_id = data.azurerm_client_config.current.tenant_id
sku_name = "standard"
purge_protection_enabled = false
enable_rbac_authorization = true
}
resource "azurerm_storage_account" "demo" {
name = "store${random_string.random.result}"
location = azurerm_resource_group.demo.location
resource_group_name = azurerm_resource_group.demo.name
account_tier = "Standard"
account_replication_type = "LRS"
}
resource "azurerm_container_registry" "demo" {
name = "acr${random_string.random.result}"
location = azurerm_resource_group.demo.location
resource_group_name = azurerm_resource_group.demo.name
sku = "Basic"
admin_enabled = true
}
// Machine Learning workspace
resource "azurerm_machine_learning_workspace" "demo" {
name = "aml-${random_string.random.result}"
location = azurerm_resource_group.demo.location
resource_group_name = azurerm_resource_group.demo.name
application_insights_id = azurerm_application_insights.demo.id
key_vault_id = azurerm_key_vault.demo.id
storage_account_id = azurerm_storage_account.demo.id
container_registry_id = azurerm_container_registry.demo.id
primary_user_assigned_identity = azurerm_user_assigned_identity.aml.id
public_network_access_enabled = true
identity {
type = "UserAssigned"
identity_ids = [
azurerm_user_assigned_identity.aml.id,
]
}
depends_on = [
azurerm_role_assignment.aml
]
}
Compute instance a cluster.
resource "azurerm_machine_learning_compute_instance" "demo" {
count = var.deploy_managed_instance ? 1 : 0
name = "demo"
location = azurerm_resource_group.demo.location
machine_learning_workspace_id = azurerm_machine_learning_workspace.demo.id
virtual_machine_size = "Standard_D2as_v4"
authorization_type = "personal"
local_auth_enabled = false
identity {
type = "UserAssigned"
identity_ids = [
azurerm_user_assigned_identity.aml.id,
]
}
}
resource "azurerm_machine_learning_compute_cluster" "demo" {
count = var.deploy_managed_cluster ? 1 : 0
name = "managed-cluster"
location = azurerm_resource_group.demo.location
vm_priority = "Dedicated"
vm_size = "Standard_D2a_v4"
machine_learning_workspace_id = azurerm_machine_learning_workspace.demo.id
ssh_public_access_enabled = true
local_auth_enabled = true
ssh {
admin_username = "tomas"
admin_password = "Azure12345678"
key_value = "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQDNN/xTE/WrpgK5nROtHupBqlHHVXQAP3c2wcvDz8PO/xLIawd8bPtrbKTmJX3TEVYe+WwQAc5K2XZrzaVGmiZeZSsHhiG3lX9kh2BbxZ9WLtLwta5gmkby4HTdk4sD3yeFFfrrdqHip5+DGl/OijUZC4ihMV6bS9P8jmugxtQKMkIeUC41HaShkXM44rnTRAvQoDr9iJZrAuuKDIZwhIv3ax8J0eu8WaRAVa5t8uZjL2Tv2QmMyK4oZtj89aVsSQyn26T3omNXfJVC/0kltM/Iu3jYXoRZz+8zAOhpTk4C6IsquM0FYsjkNBiip7/9rQCVArNMK6/Hojdl04UvVbi/QZRh4wAc9Ii49ZvD6bIxa0fc3uNl0I/EHN+BknkfzyKXuZ31roTn6xtWLcGrNN9zU+pX9Y69BvRaz2rIeYTGkQ//N7XZRV+Iv4cCEOwOrDxA61xcNDQVMLzW79Q1gQp2vD5Mybn0/LD5hb1TlAxkJfZXfdabDh/BnEEOuZFZLrgMU4c39OeQMWMV/c1gctytmLiIg4LcjhLzyzYwAShFwo+Ajkb46GWyYJD5tVnaqtf5AC6oY6C0linO6UbmpBqoWuUvM+Z6biTEP+qrUhxQ+4XVC4DwPz9Tf+YuKRvxMS5bhVxEcAFdwi1NAwfOXRMNdHRp730uslHz69gR9s3pIw=="
}
scale_settings {
min_node_count = 0
max_node_count = 5
scale_down_nodes_after_idle_duration = "PT30M"
}
identity {
type = "UserAssigned"
identity_ids = [
azurerm_user_assigned_identity.aml.id,
]
}
}
Tolik tedy k praktickému úvodu do Azure Machine Learning služby. Když to shrnu z mého pohledu - moderní přístup, velmi pěkné zpracování, univerzálnost (například díky možnosti zmocnit se libovolného Kubernetes clusteru klidně i v on-prem nebo zavolání Databricks pro joby připravující data) a bohaté služby okolo (deployment modelů, labeling služba, AutoML, grafický designér). Historickým limitem je stále trvající přechod z v1 na v2, není zabudovaný feature store a osobně bych rád viděl ještě víc směrování k GitOps. Pokud chcete jen využívat AI, jděte do kognitivních služeb včetně třeba Azure OpenAI Service a AzureML přenechejte šťouralům. Jestli tomu chcete víc rozumět a dělat si vlastní modely, pohrajte si s designérem, zkuste AutoML a koukněte co vám vygeneruje pod kapotou a pak se vrhněte na vlastní kód. A pokud už kód píšete dávno jak o život, nezapomínejte, že sněhové vločky možná vyhovují vám, ale ne organizaci, která chce růst a na ML postavit zásadní produkční aplikace. AzureML je nástroj, který udělá rozdíl mezi šmudlením na notebooku a enterprise nasazením strojového učení v organizaci - a poslední humbuk kolem velkých modelů jednoznačně ukazuje, že na ML bude muset stavět svou budoucnost doslova každý byznys. Tak se do toho vrhněte hned.