Cloud poskytovatel jako je Azure nabízí velké množství služeb a to jak těch vlastních s otevřeným nebo standardizovaným API (například Cosmos DB, Event Hub, Service Bus), těch řešených jako managed open source (Azure Database for MySQL, HDInsights, Azure Kubernetes Service) tak těch vzniklých spoluprací se specializovanou firmou ale tak, že jsou nativní součástí Azure (Azure Databricks, Azure Cache for Redis Enterprise, Azure NetApp Files, Azure Red Hat OpenShift). Ale co když z nějakého důvodu chcete jiné řešení - něco specializovaného od třetí strany, ale aby to běželo v Azure jako spravovaná služba, kterou můžete integrovat do své sítě?
Vyzkoušel jsem takové řešení od Confluent Cloud - specialisty a největšího přispěvatele projektu Kafka. Zaměřil jsem se na způsob integrace do sítě v Azure.
Síťová integrace je dostupná jen u dedikovaných clusterů.
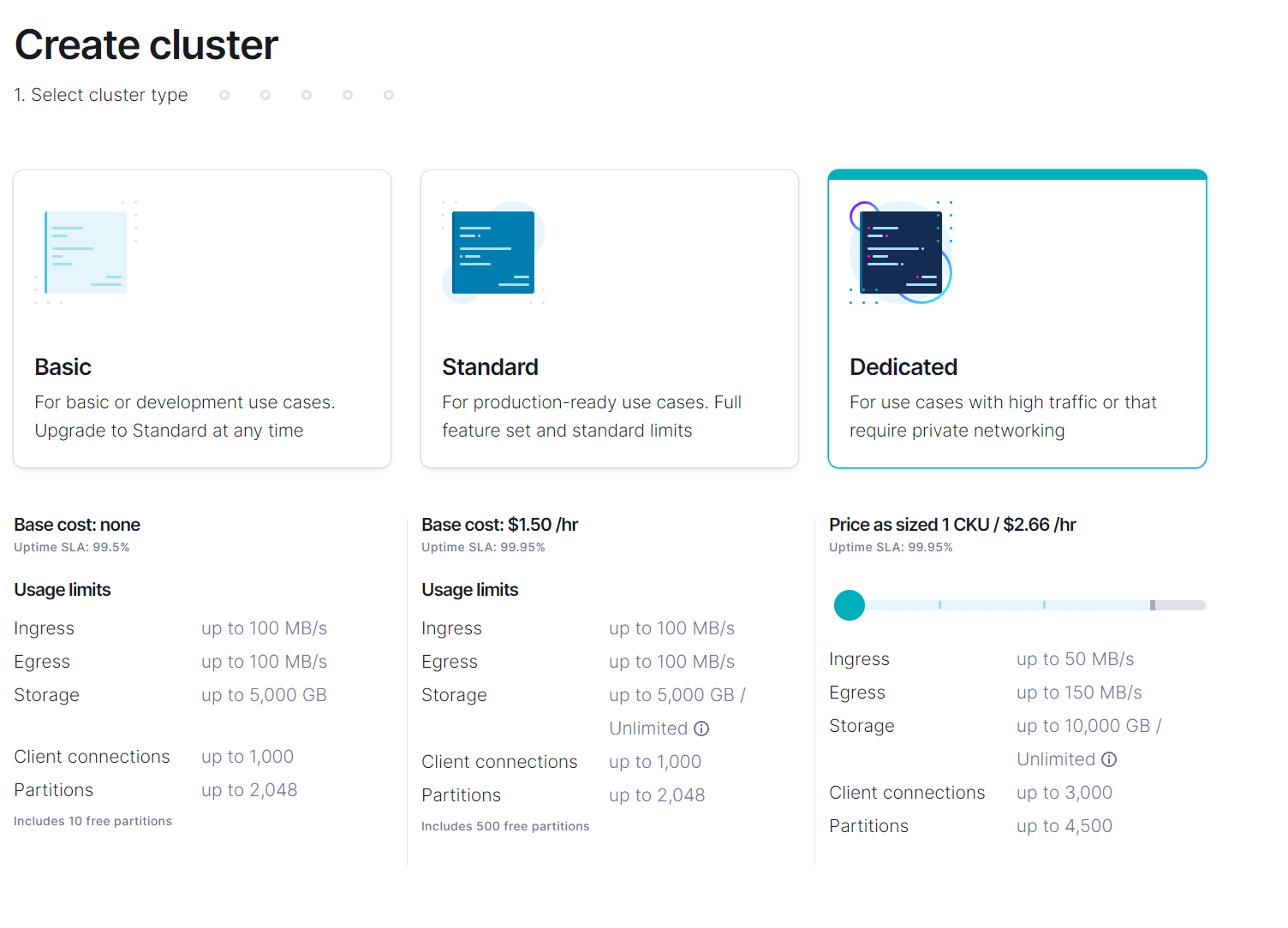
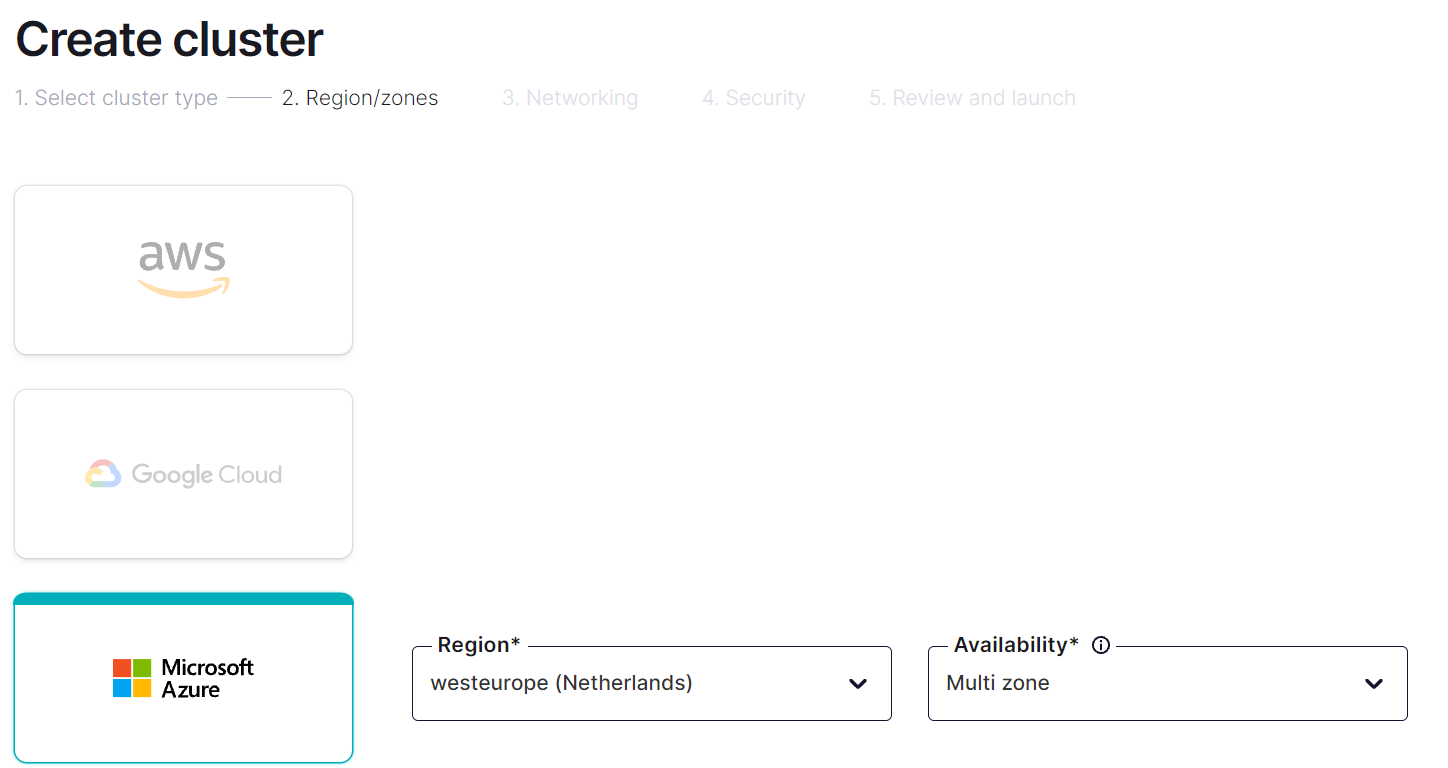
Pak už si vyberu, v kterém cloudu a regionu chci cluster mít.
Podívejme se na možnosti síťové integrace.
Public interface
První logická možnost je využití veřejné IP adresy.

Služba běží v subskripci poskytovatele (Confluent Cloud) na veřejném interface a vaše aplikace ho bude využívat. Samozřejmě bude vhodné nastavit si patřičný RBAC na úrovni Kafky a omezit přístup pouze pro vás. Pokud budete nastavovat nějaký push z Kafky, tak můžete určit jednu statickou egress adresu pro účely whitelistingu.
VNET peering
Druhý způsob už využívá integrace do vaší sítě a ta je plná - cluster v Confluent Cloud se stává součástí vaší soustavy VNETů s využitím peeringu.
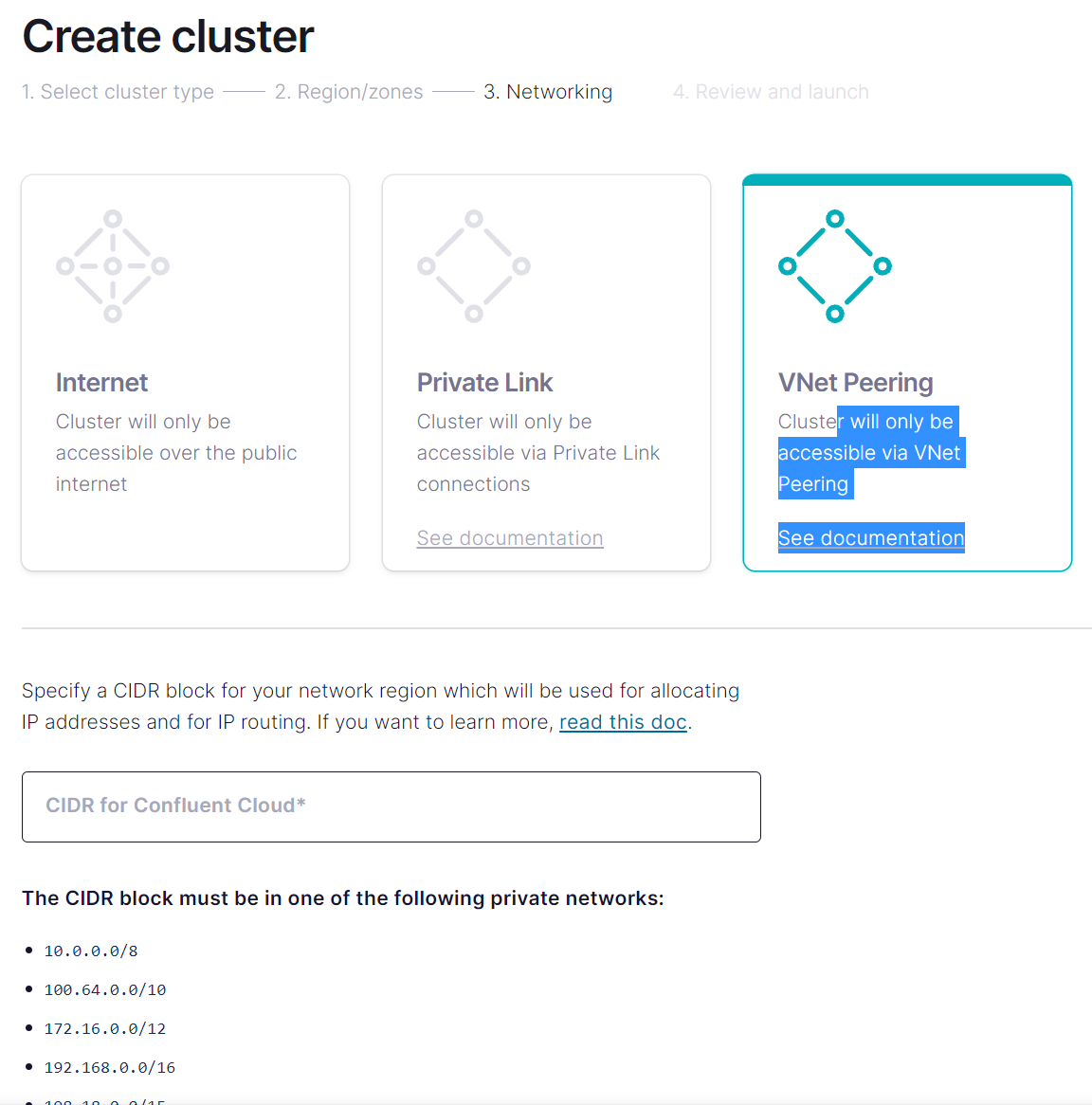
Funguje to tak, že Confluent Cloud ve své subskripci poběží ve VNETu, jehož rozsahy si můžete zvolit tak, aby seděly do vašeho adresního plánu. Následně si ve vašem tenantu zaregistrujete aplikaci Confluent Cloud (AAD aplikační registrace - řekněme Service Principal) a dáte jí minimální práva na to, aby mohla provést VNET peering do vašeho prostředí.
Obrovskou výhodou je, že jde o skutečně obousměrnou integraci a budou vám fungovat jak všechny pull záležitosti (což je většina využití Kafka), ale i případné push metody (například pokud potřebujete push/replikaci z cloudové Kafky do vašeho on-premises clusteru).
Nevýhod je ale dost. Dávat třetí straně práva ve vašem tenantu (byť velmi omezená) není jen tak a obvykle to bude vyžadovat zásah centrálního týmu. Síťařům se přímé síťové propojení na něco třetí strany nebude líbit, když nemají pod kontrolou co tam běží a jak je to zabezpečené. Určitě se tedy neobejdete bez konzultace s nimi a hromadou ručních kroků. Je také velmi pravděpodobné, že budou vyžadovat oddělení firewallem, takže v klasické hub and spoke architektuře určitě nebude Kafka napojena do vašeho spoke VNETu, ale do jiného a provoz bude procházet firewallem v centru (což přidá složitost, náklady i latenci). A teď si vezměte, že pokud chcete Confluent Cloud používat ve velkém, znamená to tyto kroky pořád a pořád opakovat pro každý tým.
Private Link
Třetí variantou je integrace přes Private Endpoint.
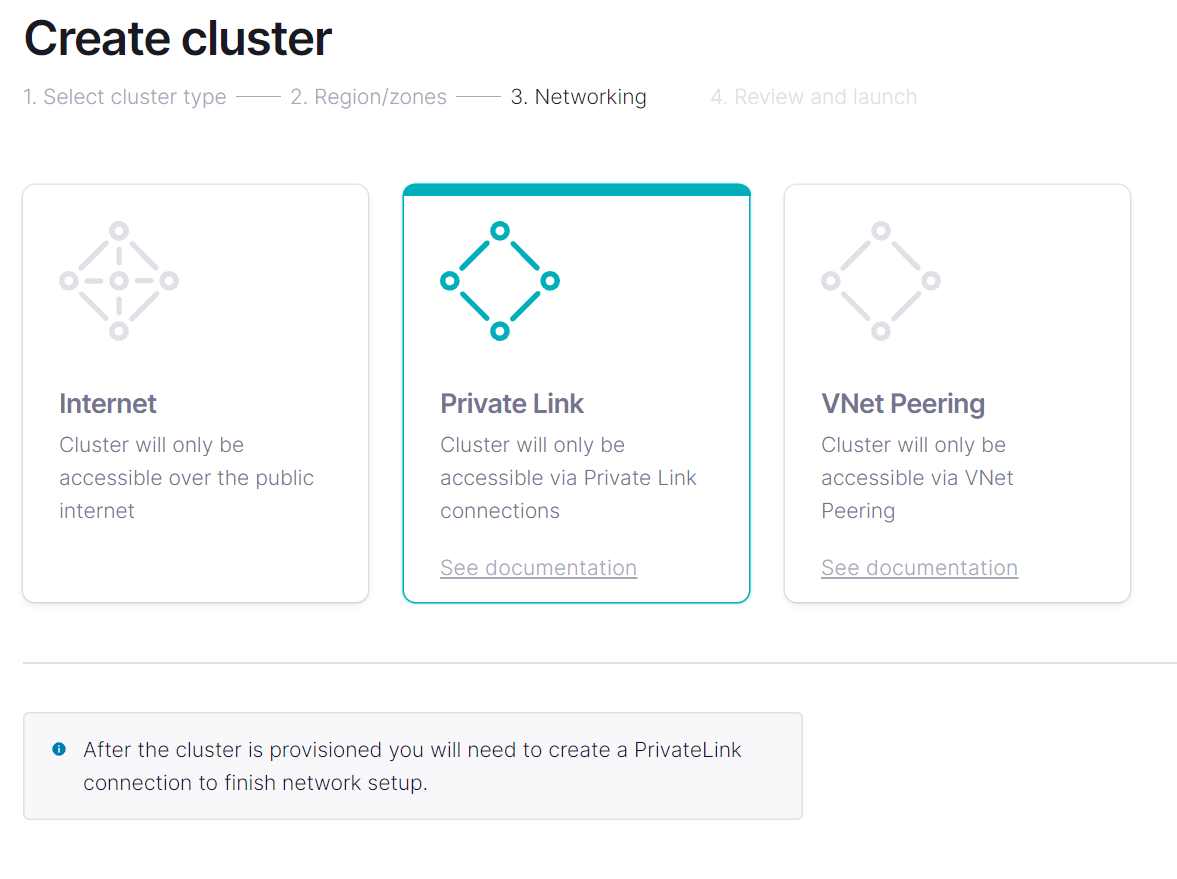
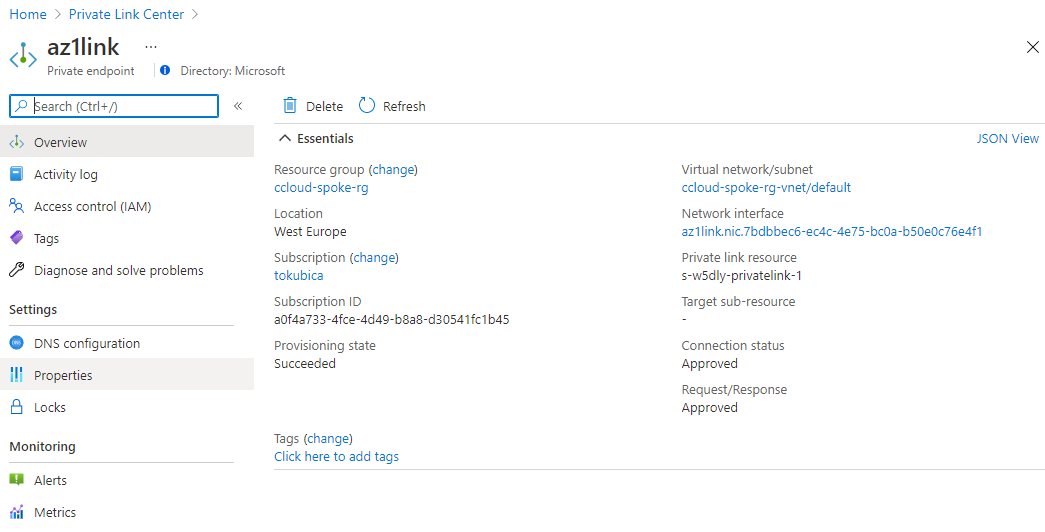
Po vytvoření clusteru jdu do sekce networking.
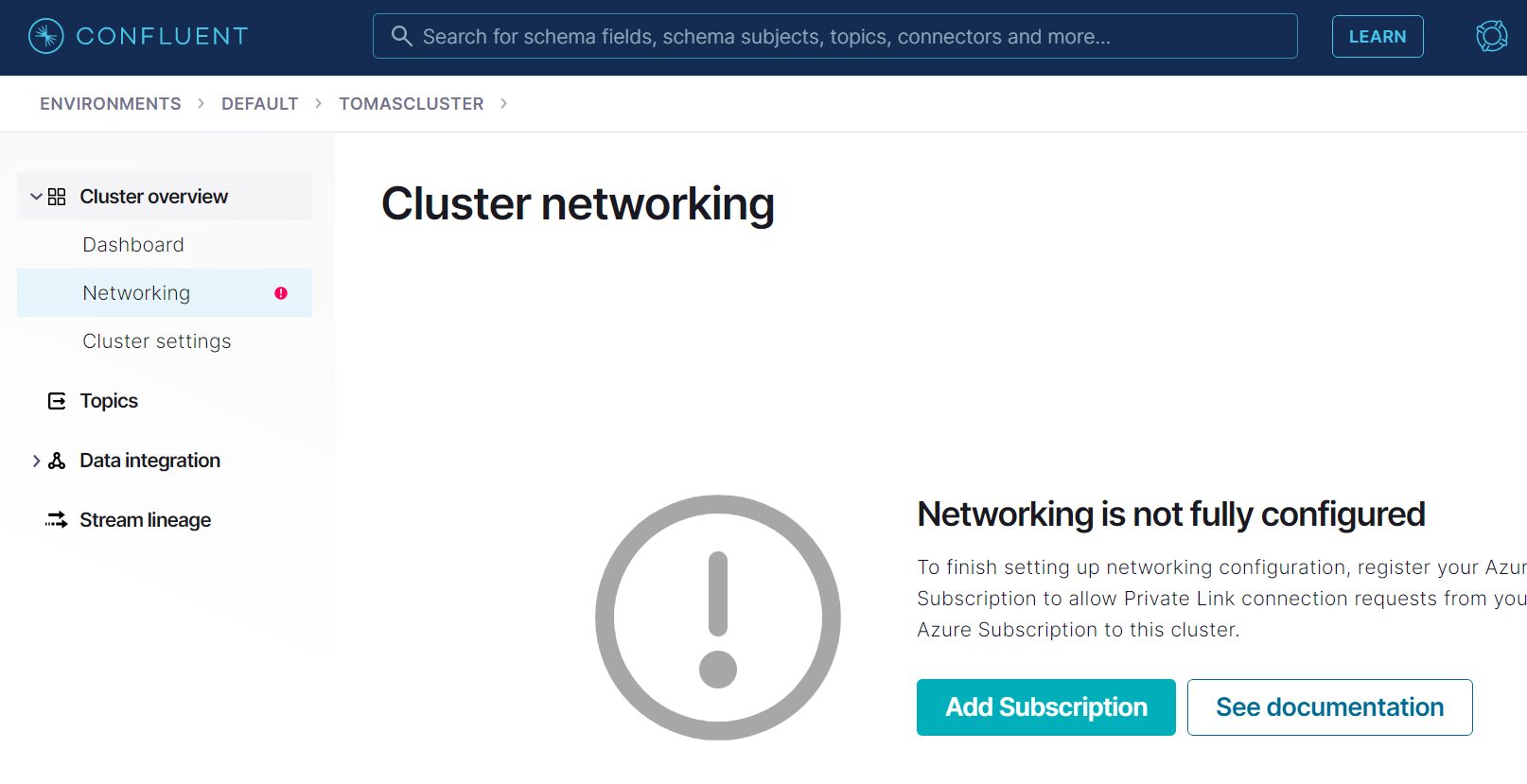
Confluent Cloud vytvoří Private Link Service s ID, které mi napíše na obrazovce. To je služba, vůči které mohu nasměrovat svůj Private Endpoint.
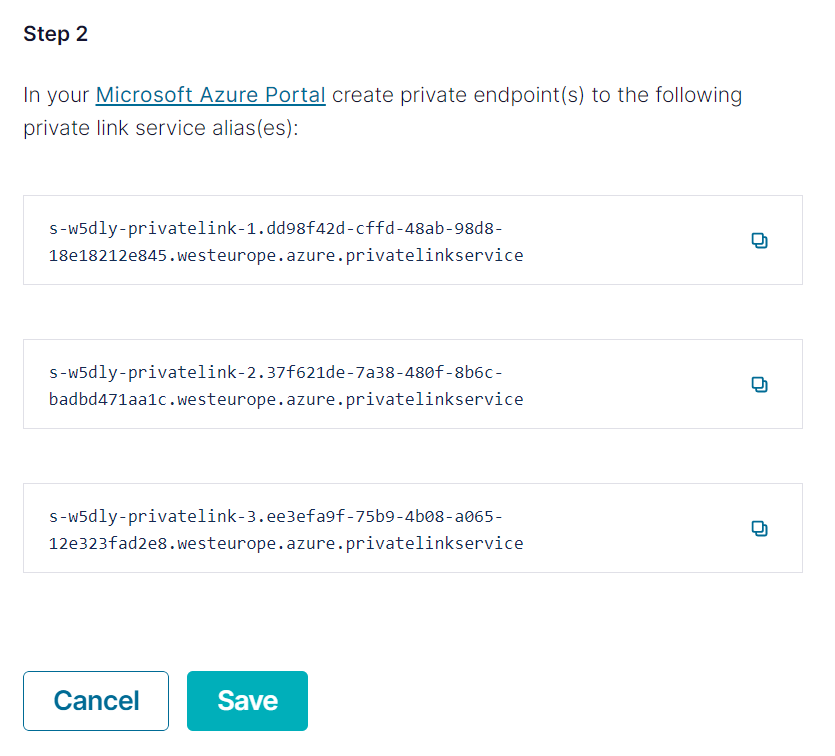
Vytvořím tedy Private Endpoint ve svém VNETu.
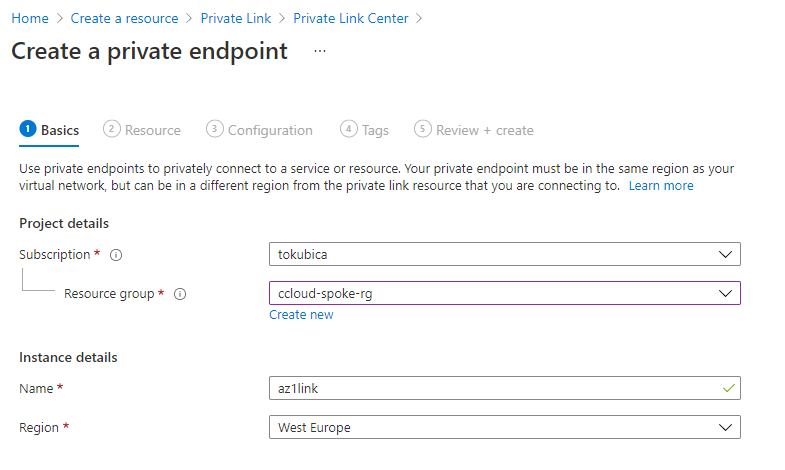
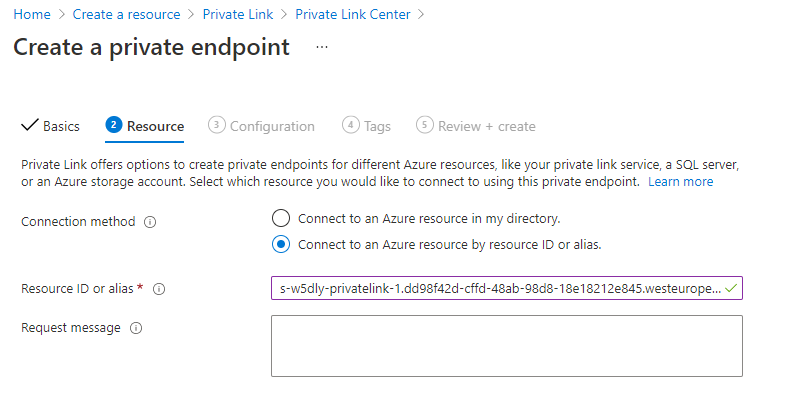
Po nějaké době je interface nahoře a vše je po síťové stránce připraveno.
Výhodou Private Link řešení je, že nemusíte synchronizovat adresní plány, dávat třetí straně práva, řešit firewally a složité síťové topologie. Ke službě se chováte stejně jako k PaaS v Azure, tedy jako k Azure SQL, Azure Storage Account a tak podobně. Není to tedy nic nového nebo neobvyklého a to je zásadní přínos. Na druhou stranu integrace je jen jednosměrná, takže je to strana vašich aplikací, která musí iniciovat spojení - tedy pull. Přes Private Link nemůžete komunikovat ze služby (Kafka clusteru) do sítě - například dělat push do jiného clusteru.
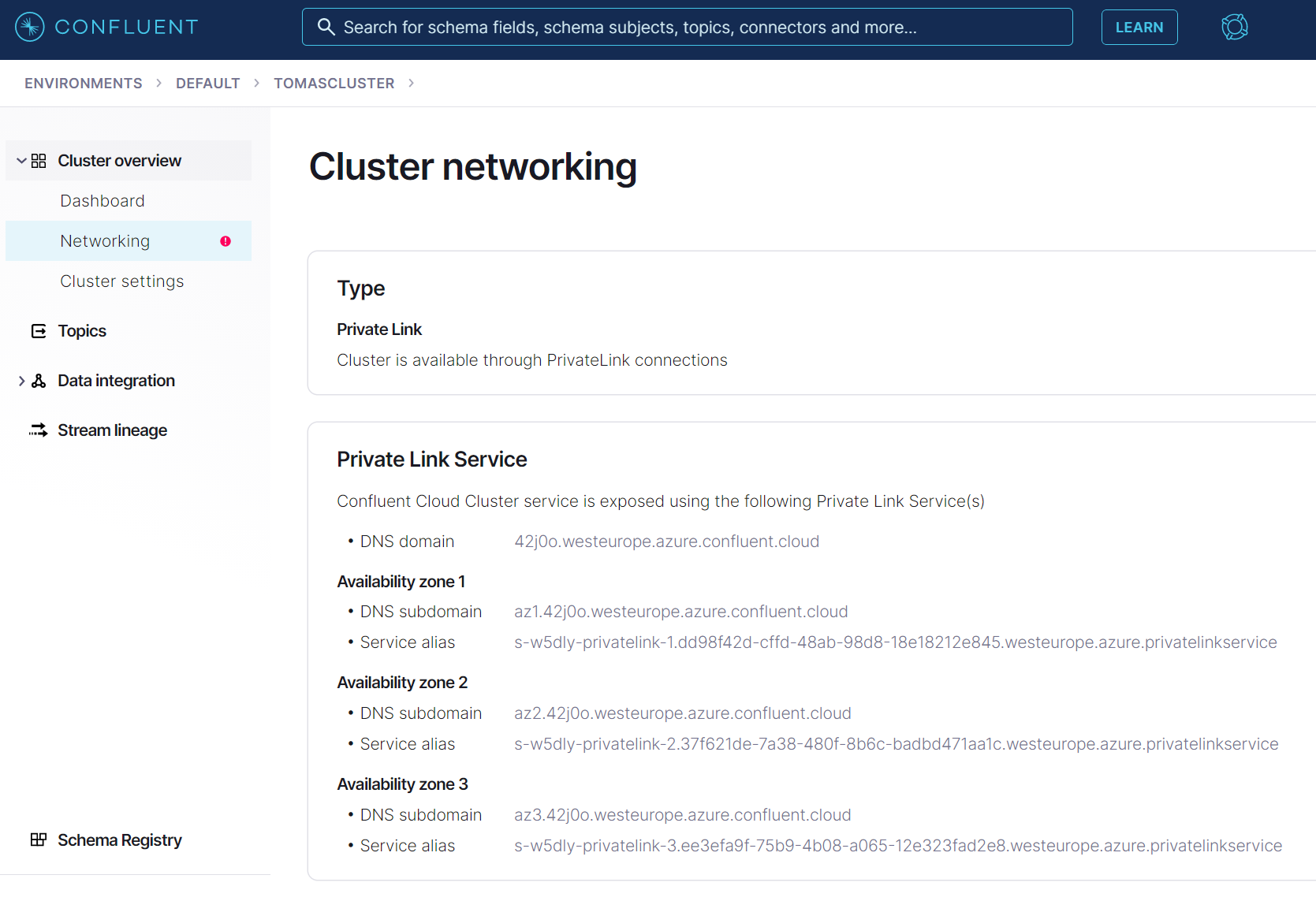
Poslední krok bude vyřešit DNS - musím zajistit, aby se FQDN clusteru překládalo na privátní adresu mého Private Endpoint (resp. trojice endpointů). Confluent Cloud na tohle vygeneruje FQDN specifické pro cluster a vyžaduje celou zónu, wildcard záznamy i záznamy pro jednotlivé zóny dostupnosti.
Integrace privátní DNS
V případě Private Endpoint s nativní platformní službou existuje koncept dnsGroup, kdy se pro vás automaticky vytvoří (či smažou) příslušné záznamy v DNS zóně. V případě integrace třetí strany tohle k dispozici není. Připravil jsem dvě metody DNS automatizace/integrace - plně centralizovanou a decentralizovanou, ale centrálně propagovanou.
Všechny potřebné objekty pro Terraform a politiky najdete na mém GitHubu
Varianta 0 - malá firma bez hub and spoke topologie
Zaměřil jsem se na enterprise scénáře, ale musím zmínit, že pokud váš tým má prostě a jednoduše svou VNETu, do on-prem připojenou třeba VPNkou a jako DNS server používá přímo Azure DNS, tak jednoduše vytvořte zónu a namapujte ji na tuto síť a to je celé. Složitější je to v případech hub and spoke topologie (nebo Azure Virtual WAN), kdy navíc spoke stroje využívají váš vlastní DNS server ve VM v hubu (ten pak dělá forwarding na on-prem DNS servery pro vaše vnitřní služby a do Azure DNS pro v něm spravované zóny private endpointů).
Varianta 1 - centrální DNS v hubu
První možnost je mít centrální DNS zónu v hubu: westeurope.azure.confluent.cloud. Vždy, když vytvoříte cluster v Confluent Cloud dostane svou vlastní doménu o řád delší, například 42j0o.westeurope.azure.confluent.cloud a v ní musíte vytvořit záznamy *.42j0o.westeurope.azure.confluent.cloud, *.az1.42j0o.westeurope.azure.confluent.cloud, *.az2.42j0o.westeurope.azure.confluent.cloud a *.az3.42j0o.westeurope.azure.confluent.cloud.
Jak záznamy centrálně spravovat? V enterprise určitě nedáte uživatelům ve spoke prostředích právo na modifikaci centrální DNS zóny, takže to bude dělat IT tým. Vyřešil bych to přes Infrastructure as Code a připravil jsem Terraform (nástroj, který zákazník, pro kterého jsem to zkoumal, používá). Udělal jsem to tak, že na vstupu je jednoduchý YAML soubor, ve kterém jsou potřebné clustery a IP adresy jeho Private Endpoint rozhraní.
42j0o:
description: Kafka cluster for team A
az1: 10.1.0.8
az2: 10.1.0.9
az3: 10.1.0.10
55f3s:
description: Kafka cluster for team B
az1: 10.0.1.10
az2: 10.0.1.11
az3: 10.0.1.12
Nevýhodou je, že samoobslužnost uživatelů ve spoke bude omezena. Málokdy bude centrální IT tak automatizované, že přes nějaký GitOps proces, rychlé schválení změny a automatický rollout přes třeba GitHub Actions bude vše vyřešeno za pár minut. Spíše tady bude potřeba udělat nějaký ticket. Na druhou stranu po technické stránce je to řešení celkem efektivní a nemá výrazné limity.
Varianta 2 - decentralizované zóny napojené do centrální sítě
Ve druhé variantě jsem se soustředil na samoobslužnost uživatelů ve spoke. Sami si založí nejen Private Endpoint, ale také DNS zónu a její záznamy. Finta je v tom, že Confluent Cloud přiděluje clusteru celou zónu, takže místo jedné westeurope.azure.confluent.cloud v hubu můžu mít ve spoke specifickou zónu 42j0o.westeurope.azure.confluent.cloud (konkrétní cluster) a její záznamy (například *.az1.42j0o.westeurope.azure.confluent.cloud). Ale to samo o sobě nebude fungovat, protože VM serverů ve spoke síti směřují na custom DNS server v hub VNETu, potřebujeme tedy tuto zónu ve spoke subskripci namapovat na hub VNET. Pokud existuje clusterů víc, tak to vůbec nevadí, protože každý má svou zónu a jak on-prem tak všechny subskripce se k překladům dostanou, protože kontaktují custom DNS server v hubu a ten to forwarduje do Azure DNS ve svém VNETu, no a na něj jsou všechny zóny namapované.
Jsou tam určité limity, například VNET může mít tuším asi jen 500 namapovaných zón, takže to s počtem nelze úplně přehánět, ale pro obvyklé nasazení je tohle číslo dostatečné. Horší může být, že v enterprise prostředí nebudou mít uživatelé ve spoke právo modifikovat zdroje v hubu. Tentokrát totiž nejde jen o právo join, ale zóna se musí namapovat na VNET a ten se jen tak bez práv nenechá. Řešením by bylo dát uživatelům taková práva, ale to nemusí vyhovovat bezpečnostním zvyklostem.
Tuto situaci jsem vyřešil přes Azure Policy. Ta má akci s názvem DeployIfNotExist a dokáže pod dedikovaným účtem (tedy ne účtem uživatele, ale svým vlastním, který může mít jiná práva) provést deployment. Můžete tak říct, že pokud se ve spoke objeví nová DNS zóna, má ji politika automaticky namapovat na síť v hubu. Dříve se na to muselo čekat asi 15 minut, ale dnes Azure Policy umí zahájit tento deployment hned po dokončení deploymentu sledovaného zdroje - jinak řečeno uživatel prostě zónu vytvoří ve spoke a politika ji do pár vteřin namapuje na hub VNET. Jednoduchá verze takové politiky je tady https://github.com/tkubica12/azure-paas-dns-integration/blob/master/Confluent-Cloud/option2-decentralized/policy.tf
Řešení potřebuje samozřejmě doladit - například chytat se pouze na určité zóny (třeba jen pro Confluent Cloud) a ověřit existenci linku, ať se deployment neprovede pokaždé znovu při změně na zóně (ačkoli to ničemu nevadí, deployment šablona je idempotentní - jen je to zbytečné).
Přestože bych jako první volbu upřednostnil nativní služby, které jsou přímo součástí Azure, někdy může služba třetí strany znamenat přínos ať už po stránce funkční nebo z pohledu univerzálnosti implementace napříč cloudy. Důležité je, že i takovou službu často můžete začlenit do virtuální sítě v Azure - Confluent Cloud je dobrým příkladem. A pokud jste firma, která chce svůj produkt nabízet jako SaaS nad Azure pro svoje uživatele, můžete se tady inspirovat. I k vaší službě lze vytvořit například Private Link a vaši enterprise zákazníci to jistě ocení.