Blob storage je skvělý a levný způsob, jak uložit dokumenty, obrázky, videa či jiné objekty a to zejména s integrací do vaší aplikace. Jakmile je aplikace nějak zpracuje, můžete na blob storage přímo přistuvat z nástrojů pro datavou analýzu. V nějaký okamžik tedy bude potřeba v tom množství najít konkrétní objekty a otázka je jak na to.
Výchozí stav je takový, že bloby obsahují metadata, můžete si k nim tedy dávat různé značky (autor, vlastník, rozlišení, kvalita, typ, kategorie, inventární číslo), jenže podle nich nemůžete vyhledávat. Můžete pouze vylistovat objekty (třeba v nějakém kontejneru), což vám vrátí stránku 5000 objektů (takže musíte stránkovat a opakovat, pokud jich je víc) a teprve v nich na straně aplikace filtrovat podle tagů. To není pro některé scénáře praktické, takže se obvykle používají dvě cesty:
- Možná je vaše potřeba prohledávání relativně jednoduchá a hierarchická. Pak si pro každou kategorii vytvořte kontejner a jeho obsah můžete jednoduše vypsat. To je fajn do doby, kdy začnete mít potřebu hledat podle různých dimenzí - jednou podle autora, jednou podle kategorii, jindy podle typu objektu (audio, video, text).
- Metadata si vyřešíte sami a uložíte si je třeba v Cosmos DB, která vám pak umožní efektivně vyhledávat a filtrovat. Tu ale musíte zaplatit, je to nějaká práce navíc a data a metadata jsou na různých místech, takže hrozí, že se “rozjedou”.
Novinkou v preview je Azure Blob Index - zabudovaná indexační služba, která vám umožní získat seznam blobů vyhovujících filtru podle nějakého tagu (je to jiné políčko než metadata - ta žijí spolu s blobem a počítají se do úložného prostoru, index tagy ne). Pojďme se na to podívat.
Preview - kde a za kolik
Tato funkce je v preview dostupná ve Francii nebo Kanadě, kde ji také vyzkoušíme. Finální cena není stanovena, ale dá se očekávat, že bude třeba na dvojnásobku preview ceny nebo alespoň kolem stejných řádů. Služba má zajímavý způsob financování. Za indexační službu jako takovou se neplatí, ale platí se za celkový počet značek (průměr) v daném měsíci a to tak, ze 10 000 značek stojí v preview 0,0195 USD. Za dva dolárky tedy máte zaindexováno 10 atributů na 100 000 objektech.
Nejprve si musíme funkci zaregistrovat (protože je v preview). Jakmile se vám ukáže jako Registered, přeregistrujte Storage providera.
az feature register --namespace Microsoft.Storage --name BlobIndex
az feature show --namespace Microsoft.Storage --name BlobIndex --query properties.state
az provider register --namespace 'Microsoft.Storage'
V rámci preview má technologie zatím nějaké nedostatky - například neobnoví tagy pokud se vrátíte k předchozí verzi objektu nebo nezajistí zkopírování tagů při kopírování objektu apod. Většina z těchto omezení ale bude předpokládám jen dočasná.
Blob index
Nejprve jsem si připravil storage account a do kontejneru nahrál dvacet souborů.
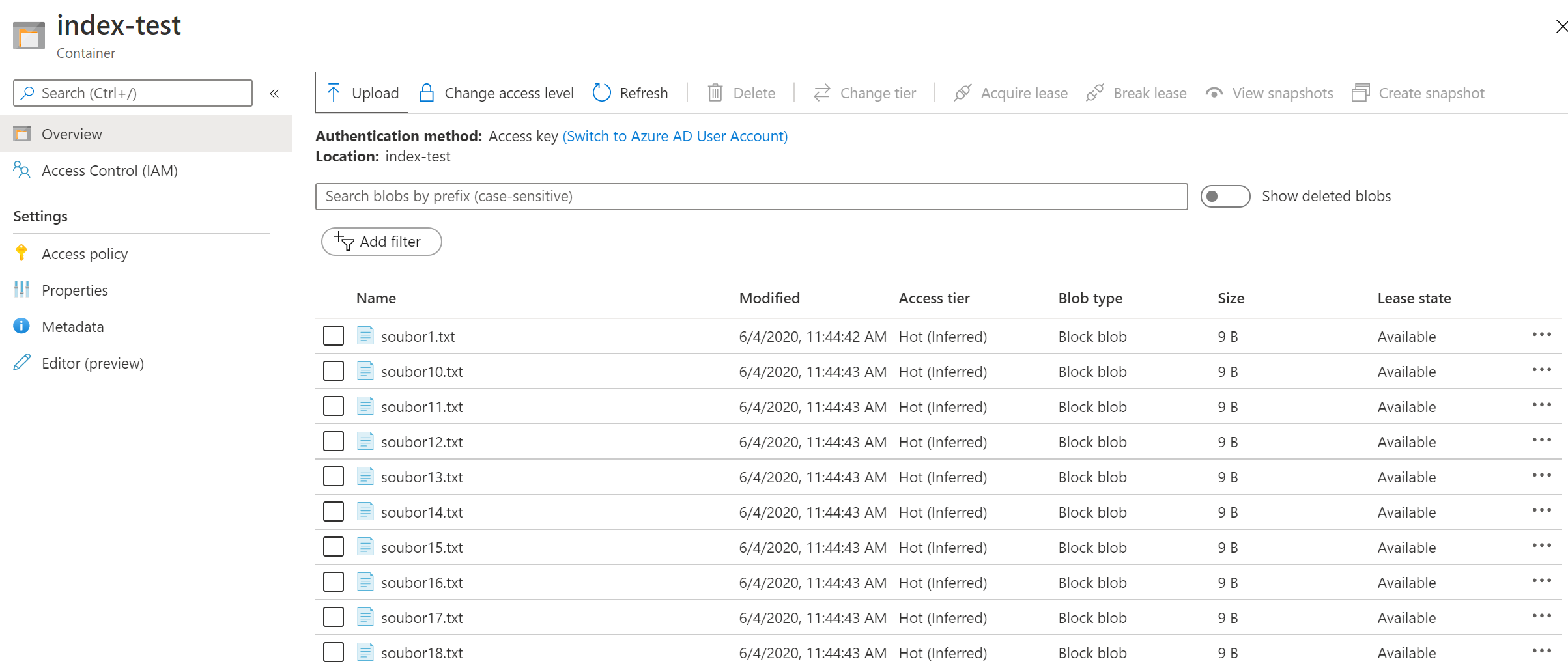
Otevřu si jeden objekt a vidím, že můžu editovat jak metadata, tak nově i index tagy.
Dám si k objektům následující značky:
- kategorie (naucna, beletrie, casopis)
- vek (doporučený věk čtenáře v letech)
- autor (Opicka, Omacka nebo Olihen)
Pojďme zkusit filtrovat. Jaké texty napsal pan Oliheň?
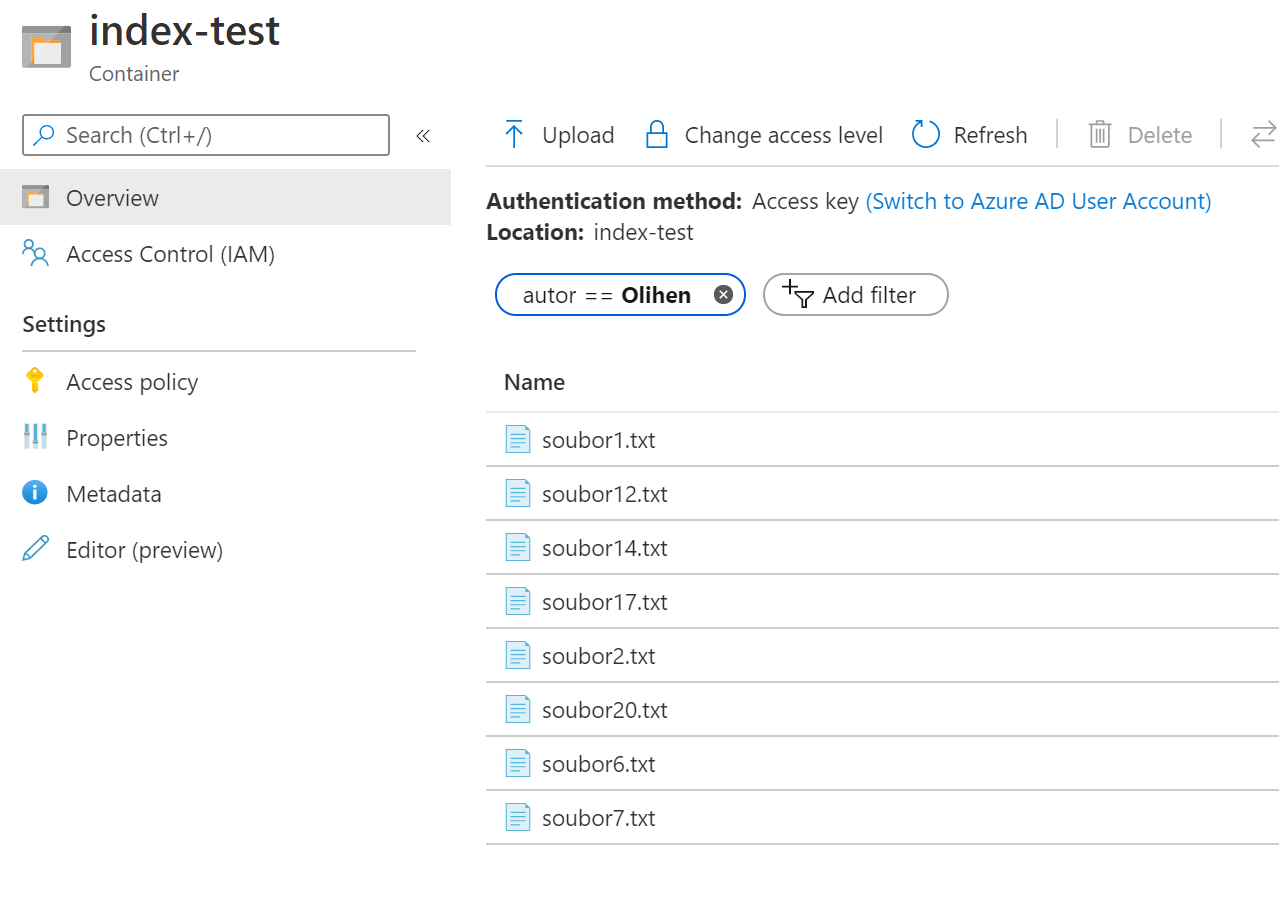
Napsal pan Oliheň nějakou beletrii?
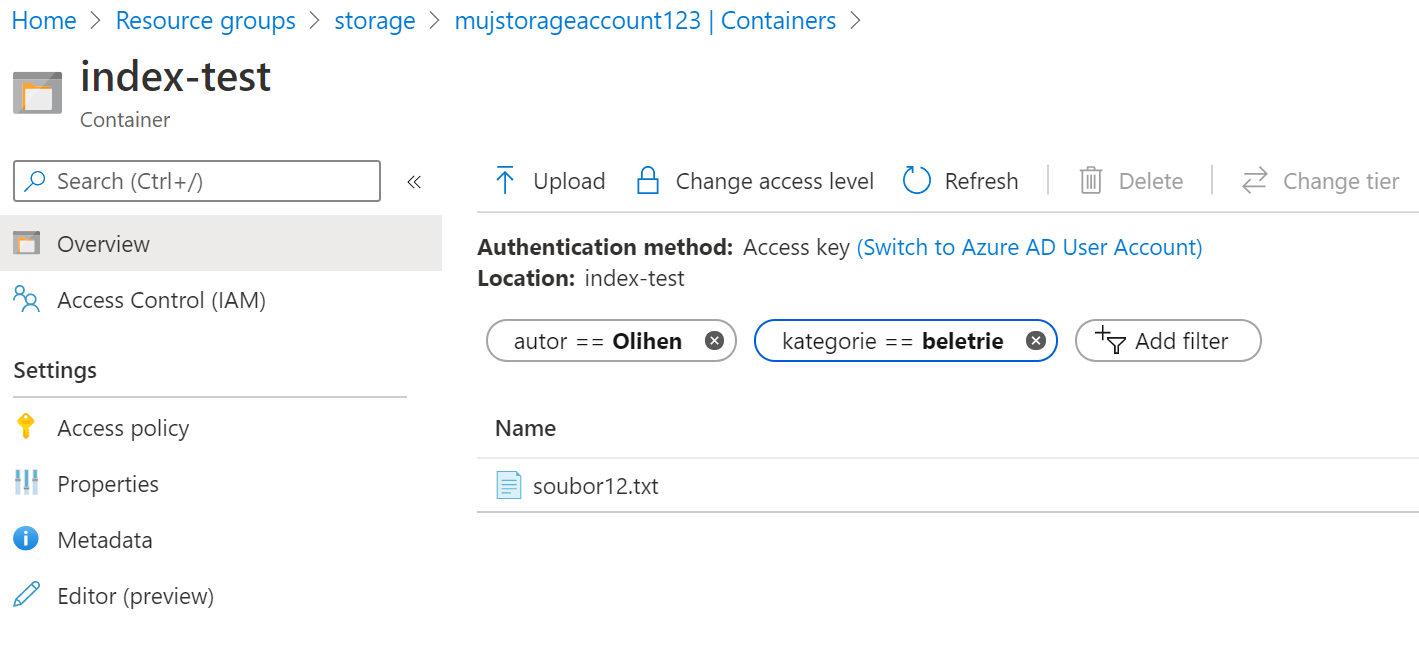
Vyhledávač v rámci kontejneru to zatím neumožňuje, ale při použití API přes celý account můžete použít i další operátory jako je >=, takže můžete vyhledat knížky určené pro dospělé a tak podobně (GUI aktuálně je pouze pro vyhledávání v rámci kontejneru).
Použití indexu v politikách
Ve virtuální knihovně se zjistilo, že zatímco beletrie a časopisy frčí, na naučnou literaturu se nikdo moc neptá. Bylo by tedy výhodnější ji přesunout do Cool tieru (přestože pro návštěvníky právě asi moc cool není). Politika pro automatický tiering může pracovat s index tagy.
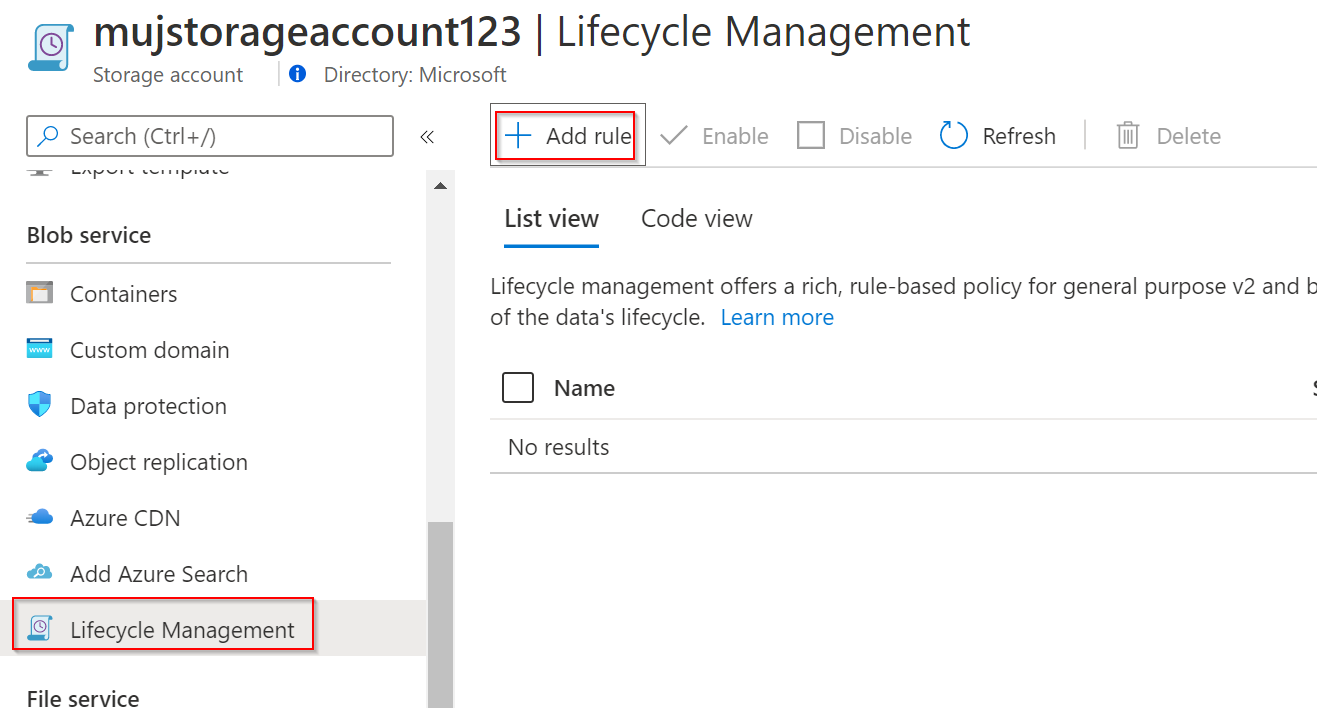
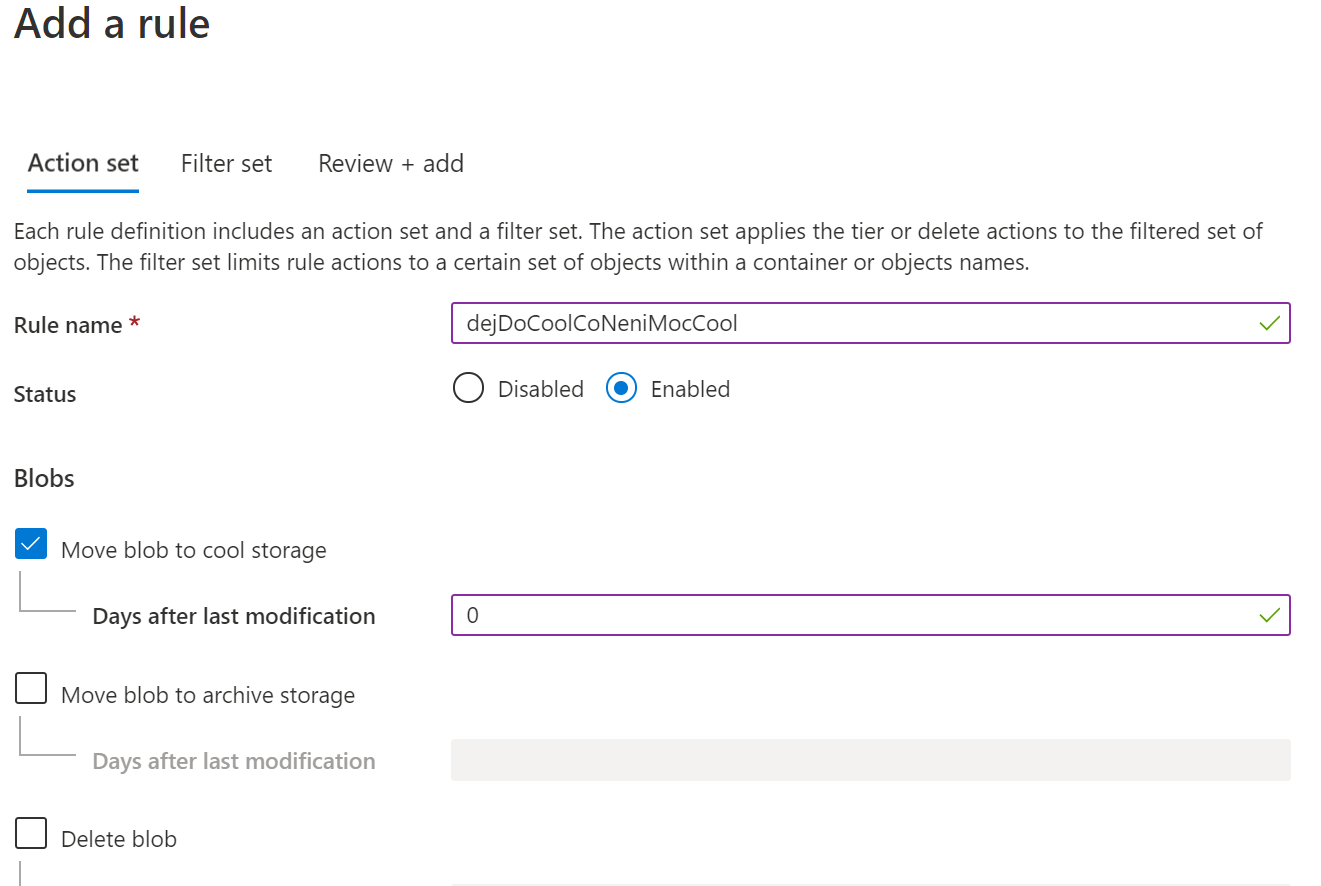
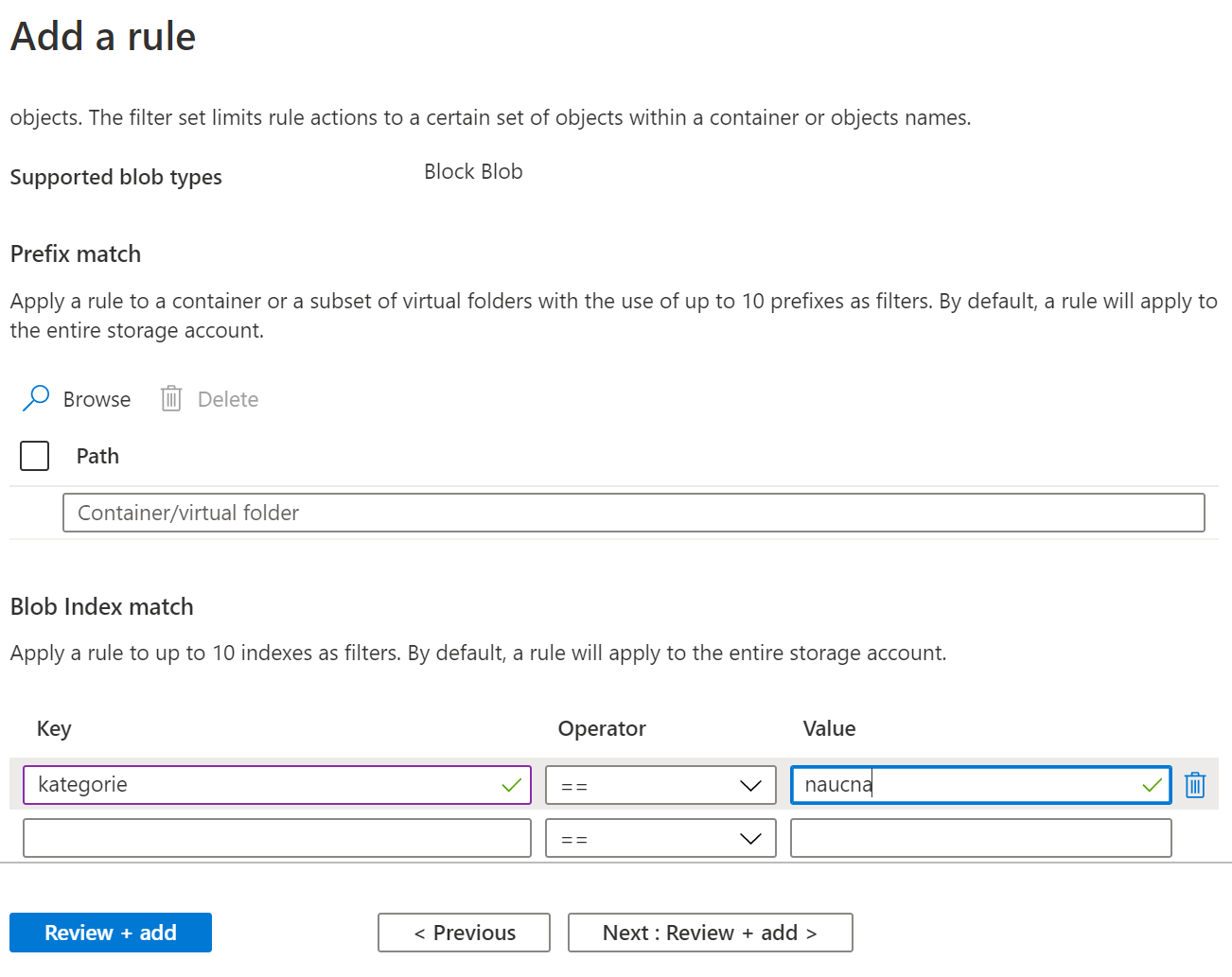
Teď zbývá jen počkat, až background job zařídí vše potřebné.
Mám použít blob index nebo ne?
Pokud to sedí do vašeho scénáře, tak určitě. Vidím tyto rozhodovací kritéria.
- Pokud potřebujete ukládat relativně hodně metadat (až 8KB dat) a nikdy podle nich nepotřebujete vyhledávat, stačí vám si je jen přečíst, když třeba vyvoláváte objekt, použijte metadata blobu.
- Pokud potřebujete podle značek vyhledávat a sháníte levné a jednoduché řešení, blob index je určitě ideální volba.
- Pokud hledáte složitější funkce typu agregační dotazy (jaká je průměrná doporučená věková kategorie textů autora Opičky), máte víc jak 10 atributů nebo indexujete i data mimo jeden account, vybudujte si řešení sami třeba s využitím Cosmos DB.
- Nestačí vám základní kategorie a vyhovuje vám spíše full text? Integrujte blob storage s Azure Cognitive Search - je to na to krásně připravené.
Tak co, zkusíte se preview ve Francii nebo v Kanadě?