Nejdřív si člověk kliká v GUI. Pak mu dojde, že je to obtížně opakovatelné a přenositelnost znalostí na kolegu je velmi obtížná (uděláte mu sérii 100 screenshotů?). V ten okamžik lidé sáhnou po skriptování - Bash či PowerShell. Dokážete tak z prázdnoty vytvořit prostředí a skript předat kolegům. Dalším krokem ale bude dost možná to, že zjistíte, že skript je fajn na začátek, ale pro úpravy existujícího prostředí ho musíte totálně předělat. Nebo když se rozhodnete udělat změnu, která ovlivňuje další sekvenci příkazů, znamená to hodně věcí upravit. A co když skript nedoběhne a zastaví se v půlce? A je váš skript idempotentní, takže se dá beztrestně spustit znovu, aniž by se něco rozbilo? Stalo se vám, že skript umí hezky přidávat, ale pro ubírání potřebujete udělat jiný, protože nestačí jen obrátit operaci bez změny pořadí (např. nemůžete vytvořit síťovku v síti, která ještě neexistuje a naopak nemůžete smazat síť, která ještě obsahuje nějakou síťovku)? V ten moment přijde na řadu to, co doporučuji mít jako preferovaný přístup k automatizaci - deklarativní desired state model.
Skriptování vs. Desired State
Běžné skriptování typicky vychází ze známého stavu, kterým je nejčastěji prázdnota. Představme si na chvilku, že pracujeme v MS-DOS a co se pustí po startu systému je obsaženo v autoexec.bat (no to byly časy - mě teda mohlo být tak 14, ale tohle si pamatuji). Uděláte skript, kterým vytvoříte autoexec.bat a bude spouštět service1. Pak vás napadne totéž pro service2 a zjistíte, že si vzájemně přemázávají soubor a nefunguje to. Tak to předěláte tak, že se to zapisuje na konec souboru, nic se nemaže. Váš skript ale slouží i pro nové verze a různé změny, například spuštění service3. Doplníte do skriptu a pustíte ho znova. No jo, ale teď vá autoexec.bat spouští service1, service2, service1, service2 a service3 - tedy některé 2x a to skončí chybovou hláškou. Váš skript totiž není idempotentní - když ho pustím víckrát, není to dobré. Představme si ještě, že skript přidává do souboru, protože ten v systému prostě je. Ale co když ne? V MS-DOS dost možná operace “open or create” není, takže pokud soubor není vytvořen, skript selže. Očekává nějaký výchozí stav (existenci souboru), ale když tam nebude, tak to selže. A co když skript v pohodě přidá service1, ale pak se stařičký FAT systém nějak zadýchá a při pokusu o zapsání service2 hodí chybu?
Řešení je vám určitě jasné - skript bude muset být chytřejší. Zjistí, jestli soubor existuje, a pokud ne, tak ho nejdřív vytvoří. Místo slepého zápisu na konec ho otevře a podívá se, jestli se v něm service1 spouští nebo ne. Pokud ano, nic dalšího nedělá, pokud ne, přidá to tam. Skript také bude reagovat na chybové stavy - možná se pokusí operaci opakovat nebo spadne způsobem, kdy bude uživateli zřejmé, že to nedoběhlo celé. Jasně, že to jde, ale začíná se to docela komplikovat a skript se stává zašmodrchaný a nečitelný pro kolegu. Přitom vlastně chceme stále se opakující základní vlastnosti:
- Zjisti, jestli to je ve stavu, co potřebujeme. Pokud ne, oprav to, pokud ano, nech to být.
- Pokud se něco nepovede, chci si definovat co se má dít. Zkusíme to znova? Ukončíme to celé chybou? Budeme chybu ignorovat a dojedeme zbytek?
- Celé to musí být dobře čitelné
- Ideálně bych měl mít nějaké parametry na vstupu a vytvářet nějaký výstup, který se použije třeba pro další zpracování
To co chceme je Desired State systém, který tyto základní vlastnosti má v sobě. Řekneme mu “nechť existuje VM s těmito parametry” a on to zajistí. Otázka ale je, jak moc mu musíme říkat, jak má stavu dosáhnout. Dáváme mu správně seřazenou sekvenci operací vedoucí k cíli nebo jen ukazujeme jak vypadá kýžený cílový stav? Je desired state model imperativní nebo deklarativní?
Imperativní vs. Deklarativní modely
Imperativní model obsahuje nějakou sekvenci nebo rozhodovací strom vedoucí k cíli. Tak například pokud potřebujete udržovat příjemnou teplotu v místnosti a máte takovou tu manuální hlavu na radiátoru, která jen ručně reguluje průtok teplé vody, dokážete svou logiku určitě popsat. Pokud je ráno brutální zima, pustíte to naplno. Pokud je lehce zima, trošku přitočíte. Když už je tak akorát, trochu uberete. Když to zapomenete zapnuté, přijdete z nákupu a je vedro jako blázen, zavřete přívod úplně. Nástroje jako Chef nebo Ansible playbooky (role ale ne, ty jsou deklarativní) jsou desired state (přináší idempotenci, error control apod.), ale jsou spíše imperativní - říkáte tam nechť existuje síť, nechť v ní existuje sťovka a nechť nad ní běží VMko. A co když potřebujete přesný opak, tedy tyto 3 zdroje smazat? Musíte to přepsat a změnit pořadí. Příkaz nechť neexistuje síť selže, protože v ní ještě existuje síťovka.
Deklarativní model je termostat. Nastavíte (deklarujete) požadovanou teplotu (desired state) na 22 stupnů a je to. Neřešíte, jak toho systém dosáhne. Je to daleko jednodušší a srozumitelnější, ale samozřejmě má to i limity. Tak například algoritmus pro vás počítá nějaký robot (sebedeklarativnější systém v konečném důsledku dělá imperativní příkazy, ale vy je nemusíte řešit), takže někdy jsou úkony, které tím nedosáhnete. Deklarativní model se týká obvykle jen jednoho systému, pro který je vytvořen. Není tak univerzální jako pouhá sekvence kroků. ARM je deklarativní model pro Azure infrastrukturu, ale neumí nasazovat kontejnery do Kubernetes, protože to je jiný desired systém se svým způsobem zápisu. Ani jeden z nich neumí řešit desired state klasické virtuální mašiny - na to je třeba Puppet nebo Ansible role. Nicméně z Bash či PowerShell uděláte klidně tohle všechno v jediném skriptu.
Výhody deklarativního modelu jsou naprosto zásadní. Je obvykle jednodušší na údržbu, proto bývá i spolehlivější. Většinou je také rychlejší, protože deklarativní systémy obvykle masivně paralelizují kdykoli to jde. Skript jede příkaz po příkazu a když chcete něco spouštět paralelně, musíte to tak přímo naprogramovat (což je komplexní).
Jaký systém na co vybrat
Rozdělme si to na různé oblasti řešení.
Infrastruktura
Ta je předmětem celé této série článků a mojí preferencí tady bude použití Azure Resource Manager jako nativního nástroje, na kterém stojí celý Azure. Mnoho položek v produktovém katalogu v GUI po dokončení průvodce pouští ARM šablony. Protože je nativní součástí Azure, je v něm všechno včetně těch nejnovějších novinek. Je konzistentní mezi Azure a Azure Stack.
Druhou variantou v pořadí mých preferencí je nástroj z dílny Hashicorp - Terraform. Má fantasticky udělaný výpočet stromu dependencies, je pekelně rychlý, má možnost speciálního DSL, který je pro provozáky trochu čitelnější, než JSON v ARMu. No a hlavně má schopnost ovládat nejen Azure, ale i jiné cloudy. Nicméně tuto jeho vlastnost nepřeceňujte, není to magický nástroj, kterému jen řeknete chci VM v cloudu x a on to magicky upraví pro daný cloud. Každý provider má v Terraform jiné objekty a pro každý cloud to píšete znova. Nicméně rozhodně platí, že svou znalost nástroje samotného a jeho DSL konstruktů můžete používat univerzálně. Tím, že není nativní mu občas mohou chybět některé novinky v Azure a musíte také vyřešit nějaký server, z kterého to budete spolehlivě pouštět. Terraform je ale rozhodně velmi dobrá volba.
Oba zmíněné postupy jsou čistě deklarativní. Velmi dobrou podporu cloudové infrastruktury má i Ansible. Tady už se ale pouštíte do imperativních vod. Můžete zdroje vytvořit imperativně a kolegům zabalit do deklarativní role, ale není to v případě infrastruktury zrovna jednoduché. Nicméně Ansible není jen o infrastruktuře, jeho doménou je configuration management. Na tom je vidět typická větší univerzálnost imperativních nástrojů. ARM ani Terraform není dělané na to, aby vytvořili VM a pak v ní nainstalovali nějaký balíček - na to běžně předávají práci jinému nástroji (třeba Ansible). Ansible ovšem dokáže udělat oboje. Nicméně pro jeho imperativnost ho odsuzuji na třetí místo.
No na závěr tu je moje oblíbené Azure CLI nebo PowerShell moduly. Rád CLI používám na jednoduché úkony typu konvertuj disky v resource group z Premium na Standard, protože VM mám vypnuté a potřebuji ušetřit za storage. K tomu “zapínadlo”, kdy řeknu nejdřív přehoď disky na Premium a pak nastartuj VM. V Azure CLI jsem rychlejší, než ve složitější ARM šabloně. Někdy prostě potřebuji někomu rychle předat nějaký postup a vím, že ARM šablona mi zabere víc času a příjemce s ní nemá zkušenost a bude mu skript příjemnější.
Configuration Management, například vnitřek VMka
Infrastrukturní nástroje, zejména ty deklarativní, nejsou určené na konfiguraci vnitřku nasazených zdrojů. Instalace něčeho do VM, export dat z databáze do CSV a tak podobně.
V této oblasti jsem si zvykl na Ansible. Je imperativní, takže v něm udělám s VM takřka cokoli, ale současně nabízí velkou plejádu hotových rolí, tedy připravených postupů pro instalaci například web serveru, které mohu použít deklarativně (tato VM nechť má roli apache). Pro složitější situace je to můj nástroj první volby. Někdy jsou situace kdy rád využiji připravenost Ansible zahrnout i infrastrukturní kroky, třeba nastartování VM v Azure.
Mému deklarativnímu přemýšlení nejvíc sedí Puppet. Jenže mi trochu vadilo, že vyžaduje agenta, takže před rozjetím Puppetu musím ještě vyřešit jak dostat agenta do VM. Další variantou rovněž s agentem je Chef. Vídám ho často u týmů s developerskými zkušenostmi. Na mne je jeho jazyk trochu moc programátorský a moc imperativní. Jsou lidé, kteří preferují SaltStack. Vypadá dobře, ale zkušenosti s ním nemám.
Pokud jde o Windows, ty nabízí PowerShell DSC - deklarativní verzi PowerShellu. Funguje velmi dobře a díky orchestračním možnostem v Azure Automation je to myslím velmi dobrá (a levná) volba pro Windows svět. Ostatní nástroje Windows obvykle umí, ale nativní DSC mi přijde velmi výhodné. Nicméně dost se mi nelíbí nutnost DSC předpisy nejdřív kompilovat. Proto bych do DSC šel jen s Azure Automation, kde se tyhle procesy dají dobře řídit. Pokud vím, tak ostatní nástroje pro ovládání Windows často používají DSC pod kapotou, takže vám příjemnou vrstvu abstrakce mohou taky zajistit. PowerShell DSC umí i Linux, ale tam bych raději Ansible, pokud ty Linuxy řeším ve velkém.
A co jednoduché situace? Co když nepotřebuji se průběžně o VM starat, jde mi jen o to při jejím vytvoření nainstalovat nějaké komponenty? Tady se dají použít startovací skripty. Cloud-init pro Linux nebo script VM extension v Azure. Tímto mechanismem v ARM šabloně řeknete, že až bude VM nahoře, má se spustit skript nebo cloud-init, který tam dovalí co potřebujete. Je to velmi oblíbený způsob jak tyto věci vyřešit tak, že z ARM šablony rovnou zavoláte a nasadíte. V Azure se používá poměrně často - například při instalaci Azure Kubernetes Service vám ARM vytvoří nody a následně na nich spustí skript, který konfiguraci “doklepne”. Upgrade se řeší nahrazení VMka jiným, takže nepotřebuji VM konfigurovat průběžně, čili složitějších nástrojů netřeba.
Kontejnerový orchestrátor
Samotné budování kontejnerů si vyřešíte imperativním Dockerfile nebo použijete nějaký build pack tak, jak to dělá třeba OpenShift nebo Cloud Foundry (vezmete kód, k němu dáte deklarativní manifest a nástroj vám vytvoří kontejnerový image). Následné umisťování kontejnerů do infrastruktury, nastavení sítě, balancování a tak podobně vyřešíte deklarativními prostředky orchestrátoru - já preferuji Kubernetes nebo Service Fabric. Oba mají deklarativní zápisy. U Kubernetes je to typicky struktura YAML souborů, u klasického Service Fabric jde o XML manifesty, u Service Fabric Mesh je to JSON postavený na ARM syntaxi.
CI/CD
A co buildovací řešení? Obvykle tohle mají na starost aplikační týmy a využívají svých nástrojů. Velmi dobře se sem hodí Azure Pipelines (Build) v rámci Azure DevOps nástroje nebo Jenkins. Zajímavou volbou pro build do kontejnerů je použít GitOps a buildovat prostředky Dockeru a kontejnerového registru (ACR). V Dockerfile můžete popsat různé fáze, tedy vzít base image, jiný image ve které zbuildujete kód a výsledek nakopírujete do finálního image (v kterém pak nepotřebujete plné SDK).
A nasazování? Mým favoritem tady je Azure Pipelines (Release) v rámci Azure DevOps. Pro Continuous Deployment je to výborná volba a dá se kombinovat nejen s buildováním v Azure DevOps, ale můžete jej navázat třeba na Jenkins, pokud nechcete měnit stávající nástroj na CI. Viděl jsem i kolegu předvádět využití nástroje Flux v rámci GitOps. Vypadá to skvěle a jednoduše, ale asi to nesedne každému. Plnohodnotný CI/CD nástroj dává určitě víc možností a je univerzálnější, ale někdy se určitě hodí proces zjednodušit tak, že tam žádný velký CI/CD systém vlastně ani není.
Chiméra potřeby jediného nástroje na všechno
Často se zejména u provozáků setkávám s názorem, že je nutné držet se jednoho univerzálního nástroje za každou cenu. Nebudou se jich přece učit víc! Takový přístup osobně považuji za chybu. Neříkám, že se má používat 100 nástrojů, ale používal bych prostředky optimalizované pro danou úlohu. Náklady na naučení se nového nástroje jsou obvykle podstatně menší, než náklady a vzniklá komplexita na znásilnění nástroje na dělání toho, v čem není nejlepší. Ono totiž samotný jazyk a architektura nástroje je méně důležitá, než schopnost ho efektivně používat a držet to čitelné.
Jinak řečeno můžu vzít Ansible a nasazovat s ním infrastrukturu, Windows i Linux a ve finále i releasovat aplikace. Jeden nástroj, skvělé ne? Neřekl bych. Infrastrukturu budu dělat ARMem. Linux mašiny dost možná s Ansible, Windows buď taky nebo s PowerShell DSC. Kontejnerový svět ošetřím kontejnerovými prostředky, nebudu tam rvát Ansible. A CI/CD? Použiji nástroj na to dělaný. Na druhou stranu mám pro svoje Linux používat někdy Ansible, někdy Chef a někdy Puppet? To už je možná zbytečná komplexita nástrojů, nevidím k tomu zásadní důvod.
Za mne - používejte nástroj optimální pro danou úlohu. Náklady na zavedení nástroje dost možná budou nižší, než honba za univerzálností, která skončí nepřiměřenou složitostí a znefunkčněním nástroje pro běžnou práci.
Azure Resource Manager (ARM) šablony
Azure nabízí deklarativní model ovládání jako svou nativní vlastnost. Není to přílepek, ale naopak základ Azure. Základem Azure je právě ARM a jeho API. Jednotlivé komponenty Azure, tedy Resource Provideři, jsou z pohledu administrátora ovládány výhradně přes Azure Resource Manager. Teprve nad ním jsou postaveny věci jako portál (GUI), Azure CLI nebo PowerShell moduly. Je jedno jakým způsobem Azure ovládáte, vždy to je řešeno konzistentním ARM API společným pro všechny metody. Můžete si všimnout, že zbrusu nové služby, které jsou třeba v privátní preview (dostupné pouze vybraným zákazníkům na vyzkoušení) jsou často nasaditelné jen přes ARM. V public preview (testování pro širokou veřejnost) už k nim existují třeba PowerShell příkazy, jindy zas jen Azure CLI - zkrátka výčet někdy není kompletní, například některá nastavení z GUI neuděláte. U finálního produktu obvykle všeho dosáhnete všemi způsoby, ale ukazuje to, že ARM je v srdci všech služeb, není to přílepek.
Podívejme se na prázdou ARM šablonu.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": { },
"variables": { },
"resources": [ ],
"outputs": { }
}
contentVersion můžete použít pro zaznamenání verze šablony. Oceníme to později, až budeme používat linkované šablony, tedy kdy si z master šablony kompletujeme řešení z podřízených šablon. Parameters jsou vstupní parametry, tedy něco, co očekáváme, že se bude měnit při zadávání deploymentu. Typicky nějaký sizing (protože dev, test a prod mají mít stejnou šablonu, ale levnější velikosti), názvy (prefixy), tagy či reference dalších objektů. Variables jsou proměnné. Kdykoli v šabloně opakujete něco častěji, rozhodně se vyplatí udělat si z toho variable. V případě nutnosti změny nechcete hledat všechny výskyty. Proč mít něco ve variable místo parameters? Variable nechci měnit mezi deploymenty, například mezi nasazením v testu a produkci - nechci měnit tělo šablony (tím bych mohl zavést chybu nebo nekonzistenci mezi prostředími). Nicméně v budoucnu se mohu rozhodnout, že šablona má fungovat jinak a chci ji změnit a pak mi variable pomůže, abych nemusel stejnou věc měnit na mnoha místech. Dále je tam sekce resources a to je to hlavní - tam jsou definované jednotlivé zdroje, například VNET, ip adresa apod. Sekce outputs umožňuje vypsat něco do výstupu šablony. To může být jednak vidět v GUI nebo na výstupu Azure CLI, ale také se to posílá mezi vnořenou a master šablonou (o tom jindy).
V dnešním díle si už toho moc vyzkoušet nestihneme, ale pošleme do Azure alespoň něco hodně jednoduchého.
Připravte si soubor třeba 01.json s tímto obsahem:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"variables": {},
"resources": [
{
"type": "Microsoft.Network/publicIPAddresses",
"name": "myIP",
"apiVersion": "2016-03-30",
"location": "West Europe",
"properties": {
"publicIPAllocationMethod": "Dynamic"
}
}
],
"outputs": {}
}
Můžeme začít v GUI. Klikněte na + a najděte Template Deployment.
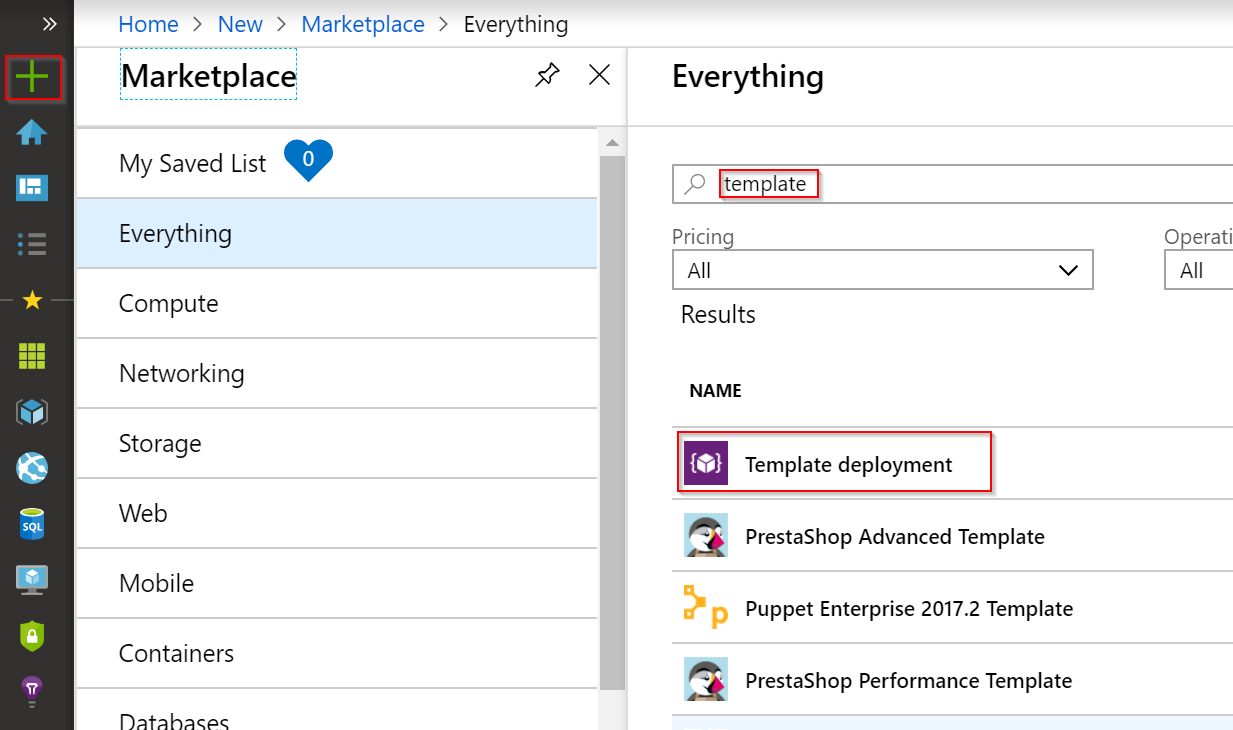
Vytvoříme si ji v editoru.
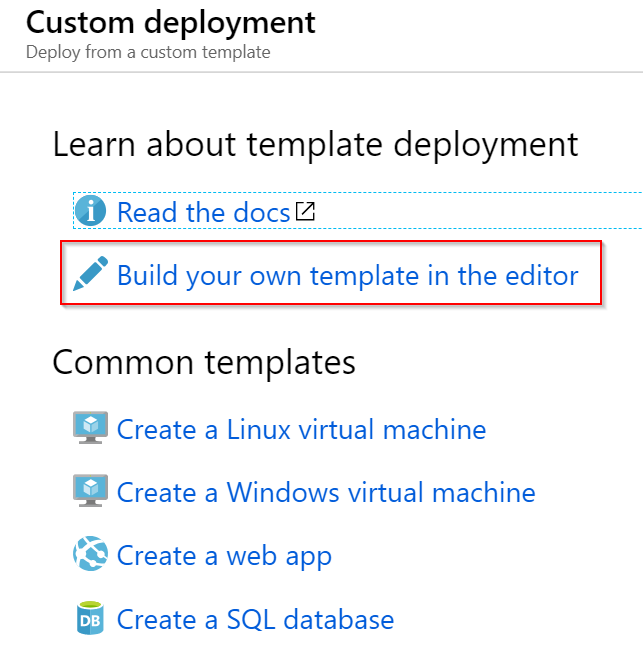
Načteme náš soubor.

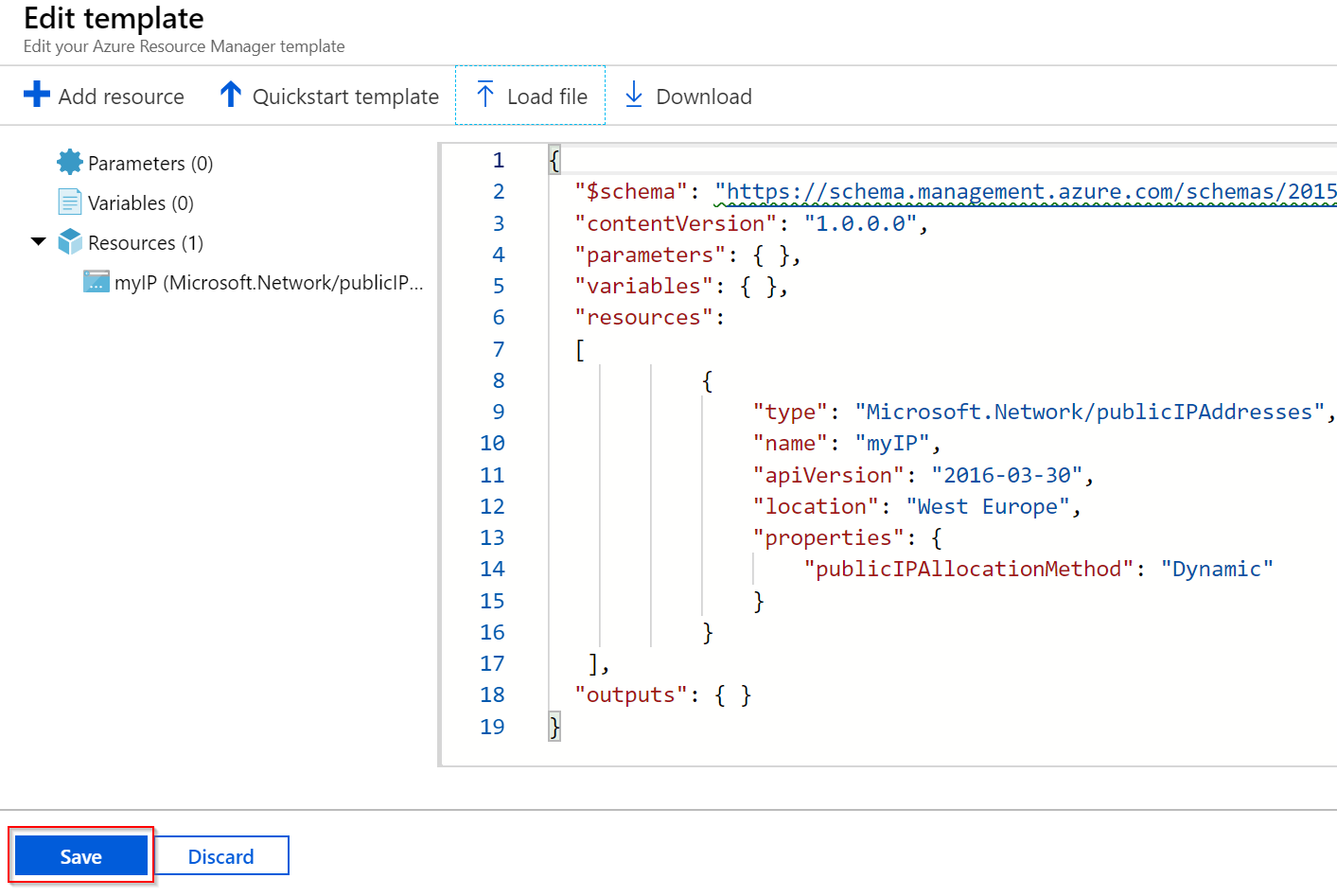
Pošlete do existující resource group nebo vytvořte novou a můžeme spustit.
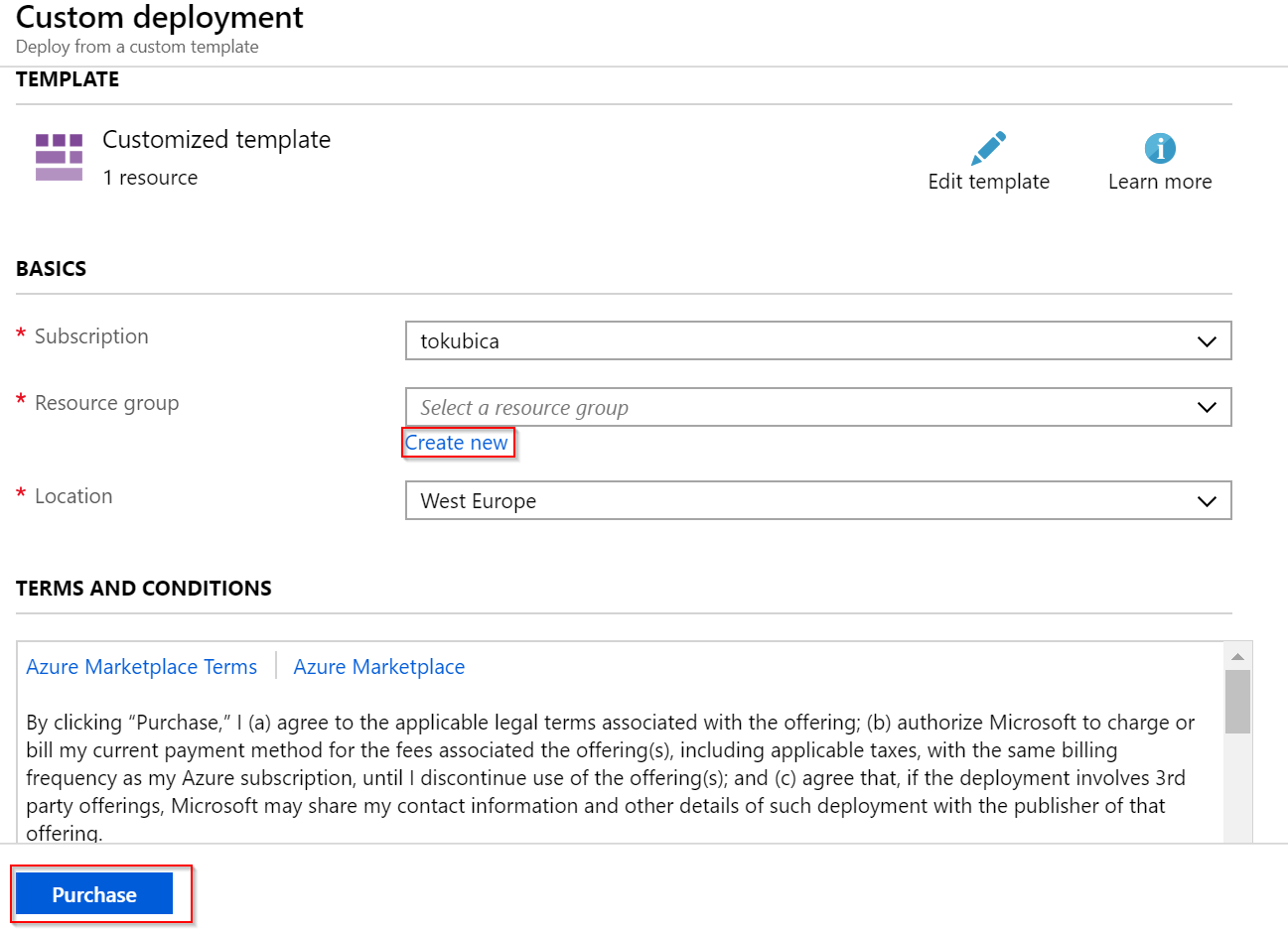
Otevřete si resource group a v ní najdete záložku Deployments. Tam můžete sledovat průběh a stav jednotlivých deploymentů. To je velmi důležitá věc - Azure pro vás zajišťuje deployment a odtud se podíváte jak jste na tom, kde jsou případné chyby. S jinými nástroji musíte mít místo, kde nástroj běží a to musí být dostupné v průběhu deploymentu (například pokud nasazujete z notebooku a ono to trvá, musíte zůstat připojeni a ne ho zaklapnout a jít domů). ARM šablonu “vložíte” do Azure a on zajistí deployment.
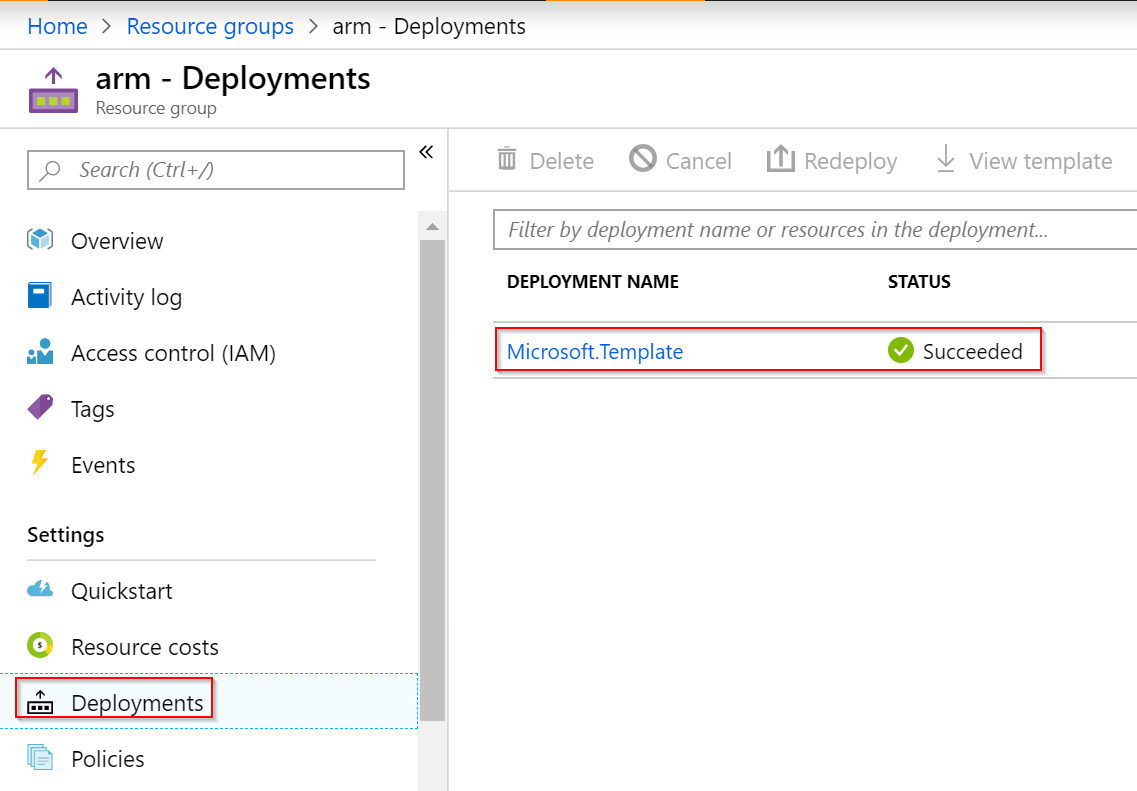
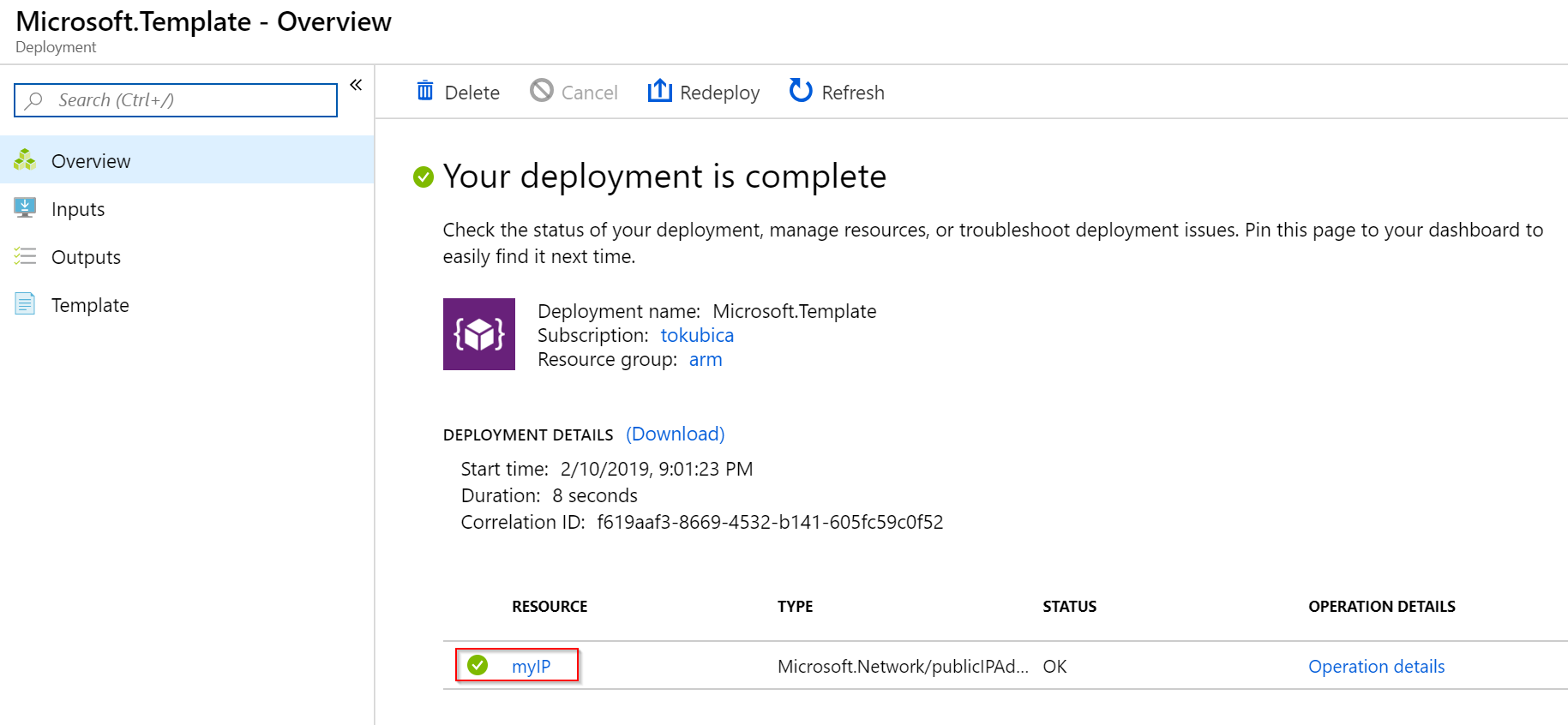
Tak vidíte - první zdroj jsme si nasadili.
Kam odsud dál
V této sérii článků si toho vyzkoušíte ještě hodně:
- Práce s variables a parameters, integrace s Key Vault
- Logické funkce, například práce s řetězci apod.
- Loop a generování vícero stejných objektů, práce s polem na vstupu
- Reference, složitější typy zdrojů, které jsou vnořené do jiných apod.
- Efektivní používání linkovaných šablon
- Nasazování ARM šablon přes Azure DevOps
- Použití ARM šablon v Logic Apps
- Využití ARM pro vytváření položek do Azure Marketplace nebo Azure Managed Applications (interní firemní katalog služeb)
Kromě toho najdete spoustu příkladů v Quickstart templates a v dokumentaci.